這篇文章會非常詳細的分析 iOS 介面構建中的各種效能問題以及對應的解決思路,同時給出一個開源的微博列表實現,通過實際的程式碼展示如何構建流暢的互動。
Index
演示專案
螢幕顯示影像的原理
卡頓產生的原因和解決方案
CPU 資源消耗原因和解決方案
GPU 資源消耗原因和解決方案
AsyncDisplayKit
ASDK 的由來
ASDK 的資料
ASDK 的基本原理
ASDK 的圖層預合成
ASDK 非同步併發操作
Runloop 任務分發
微博 Demo 效能優化技巧
預排版
預渲染
非同步繪製
全域性併發控制
更高效的非同步圖片載入
其他可以改進的地方
如何評測介面的流暢度
演示專案
在開始技術討論前,你可以先下載我寫的 Demo 跑到真機上體驗一下:https://github.com/ibireme/YYKit。 Demo 裡包含一個微博的 Feed 列表、釋出檢視,還包含一個 Twitter 的 Feed 列表。為了公平起見,所有介面和互動我都從官方應用原封不動的抄了過來,資料也都是從官方應用抓取的。你也可以自己抓取資料替換掉 Demo 中的資料,方便進行對比。儘管官方應用背後的功能更多更為複雜,但不至於會帶來太大的互動效能差異

這個 Demo 最低可以執行在 iOS 6 上,所以你可以把它跑到老裝置上體驗一下。在我的測試中,即使在 iPhone 4S 或者 iPad 3 上,Demo 列表在快速滑動時仍然能保持 50~60 FPS 的流暢互動,而其他諸如微博、朋友圈等應用的列表檢視在滑動時已經有很嚴重的卡頓了。
微博的 Demo 有大約四千行程式碼,Twitter 的只有兩千行左右程式碼,第三方庫只用到了 YYKit,檔案數量比較少,方便檢視。好了,下面是正文。
螢幕顯示影像的原理
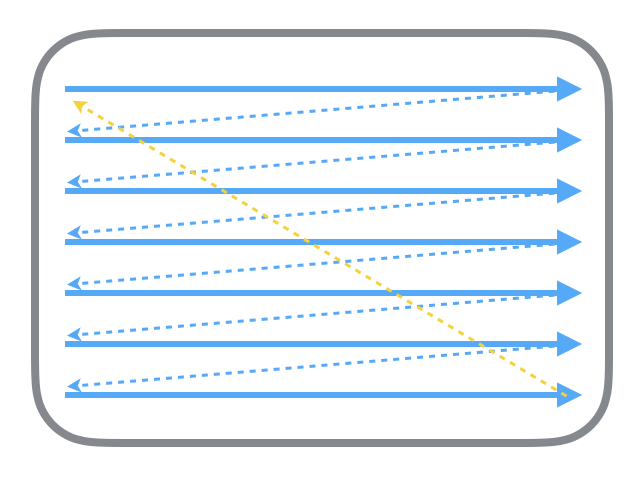
首先從過去的 CRT 顯示器原理說起。CRT 的電子槍按照上面方式,從上到下一行行掃描,掃描完成後顯示器就呈現一幀畫面,隨後電子槍回到初始位置繼續下一次掃描。為了把顯示器的顯示過程和系統的視訊控制器進行同步,顯示器(或者其他硬體)會用硬體時鐘產生一系列的定時訊號。當電子槍換到新的一行,準備進行掃描時,顯示器會發出一個水平同步訊號(horizonal synchronization),簡稱 HSync;而當一幀畫面繪製完成後,電子槍回覆到原位,準備畫下一幀前,顯示器會發出一個垂直同步訊號(vertical synchronization),簡稱 VSync。顯示器通常以固定頻率進行重新整理,這個重新整理率就是 VSync 訊號產生的頻率。儘管現在的裝置大都是液晶螢幕了,但原理仍然沒有變。
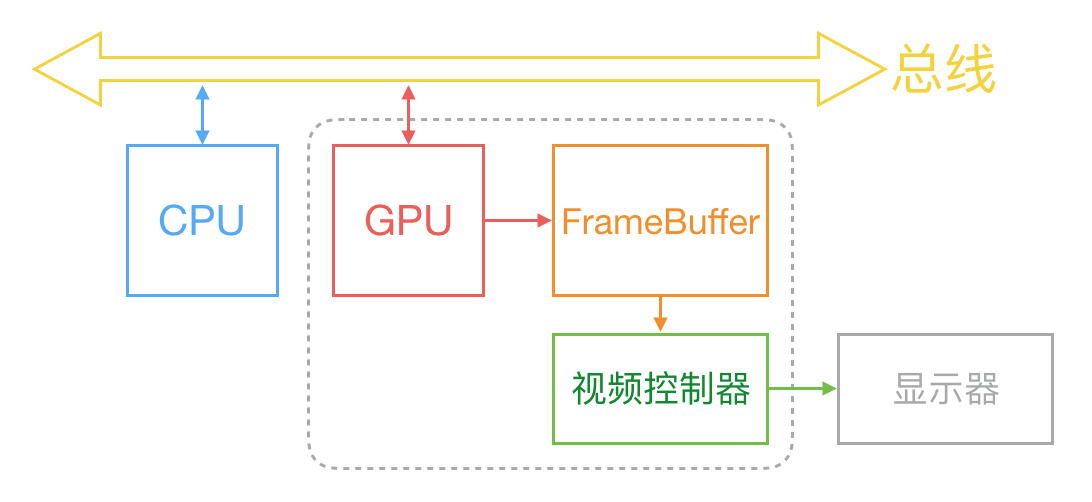
通常來說,計算機系統中 CPU、GPU、顯示器是以上面這種方式協同工作的。CPU 計算好顯示內容提交到 GPU,GPU 渲染完成後將渲染結果放入幀緩衝區,隨後視訊控制器會按照 VSync 訊號逐行讀取幀緩衝區的資料,經過可能的數模轉換傳遞給顯示器顯示。
在最簡單的情況下,幀緩衝區只有一個,這時幀緩衝區的讀取和重新整理都都會有比較大的效率問題。為了解決效率問題,顯示系統通常會引入兩個緩衝區,即雙緩衝機制。在這種情況下,GPU 會預先渲染好一幀放入一個緩衝區內,讓視訊控制器讀取,當下一幀渲染好後,GPU 會直接把視訊控制器的指標指向第二個緩衝器。如此一來效率會有很大的提升。
雙緩衝雖然能解決效率問題,但會引入一個新的問題。當視訊控制器還未讀取完成時,即螢幕內容剛顯示一半時,GPU 將新的一幀內容提交到幀緩衝區並把兩個緩衝區進行交換後,視訊控制器就會把新的一幀資料的下半段顯示到螢幕上,造成畫面撕裂現象,如下圖:

為了解決這個問題,GPU 通常有一個機制叫做垂直同步(簡寫也是 V-Sync),當開啟垂直同步後,GPU 會等待顯示器的 VSync 訊號發出後,才進行新的一幀渲染和緩衝區更新。這樣能解決畫面撕裂現象,也增加了畫面流暢度,但需要消費更多的計算資源,也會帶來部分延遲。
那麼目前主流的移動裝置是什麼情況呢?從網上查到的資料可以知道,iOS 裝置會始終使用雙快取,並開啟垂直同步。而安卓裝置直到 4.1 版本,Google 才開始引入這種機制,目前安卓系統是三快取+垂直同步。
卡頓產生的原因和解決方案
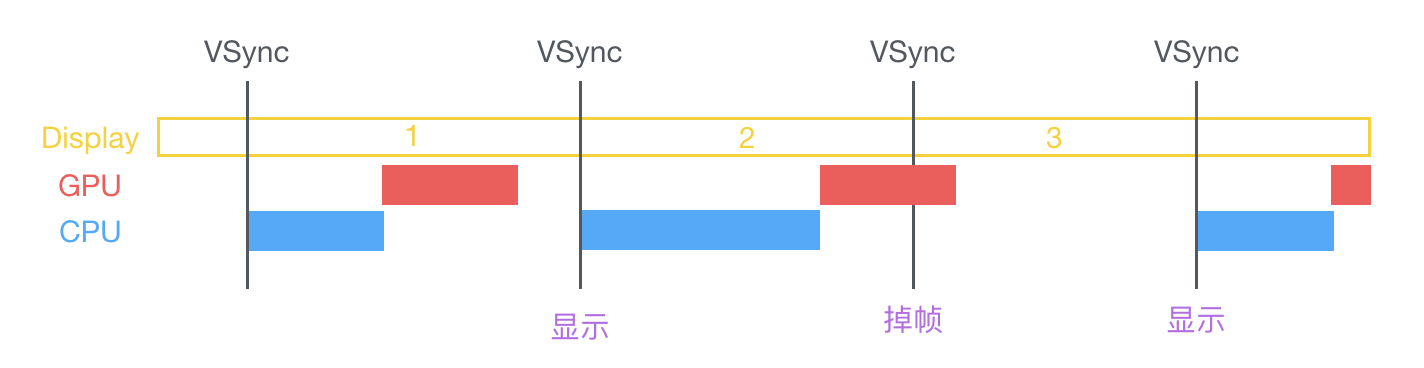
在 VSync 訊號到來後,系統圖形服務會通過 CADisplayLink 等機制通知 App,App 主執行緒開始在 CPU 中計算顯示內容,比如檢視的建立、佈局計算、圖片解碼、文字繪製等。隨後 CPU 會將計算好的內容提交到 GPU 去,由 GPU 進行變換、合成、渲染。隨後 GPU 會把渲染結果提交到幀緩衝區去,等待下一次 VSync 訊號到來時顯示到螢幕上。由於垂直同步的機制,如果在一個 VSync 時間內,CPU 或者 GPU 沒有完成內容提交,則那一幀就會被丟棄,等待下一次機會再顯示,而這時螢幕會保留之前的內容不變。這就是介面卡頓的原因。
從上面的圖中可以看到,CPU 和 GPU 不論哪個阻礙了顯示流程,都會造成掉幀現象。所以開發時,也需要分別對 CPU 和 GPU 壓力進行評估和優化。
CPU 資源消耗原因和解決方案
物件建立
物件的建立會分配記憶體、調整屬性、甚至還有讀取檔案等操作,比較消耗 CPU 資源。儘量用輕量的物件代替重量的物件,可以對效能有所優化。比如 CALayer 比 UIView 要輕量許多,那麼不需要響應觸控事件的控制元件,用 CALayer 顯示會更加合適。如果物件不涉及 UI 操作,則儘量放到後臺執行緒去建立,但可惜的是包含有 CALayer 的控制元件,都只能在主執行緒建立和操作。通過 Storyboard 建立檢視物件時,其資源消耗會比直接通過程式碼建立物件要大非常多,在效能敏感的介面裡,Storyboard 並不是一個好的技術選擇。
儘量推遲物件建立的時間,並把物件的建立分散到多個任務中去。儘管這實現起來比較麻煩,並且帶來的優勢並不多,但如果有能力做,還是要儘量嘗試一下。如果物件可以複用,並且複用的代價比釋放、建立新物件要小,那麼這類物件應當儘量放到一個快取池裡複用。
物件調整
物件的調整也經常是消耗 CPU 資源的地方。這裡特別說一下 CALayer:CALayer 內部並沒有屬性,當呼叫屬性方法時,它內部是通過執行時 resolveInstanceMethod 為物件臨時新增一個方法,並把對應屬性值儲存到內部的一個 Dictionary 裡,同時還會通知 delegate、建立動畫等等,非常消耗資源。UIView 的關於顯示相關的屬性(比如 frame/bounds/transform)等實際上都是 CALayer 屬性對映來的,所以對 UIView 的這些屬性進行調整時,消耗的資源要遠大於一般的屬性。對此你在應用中,應該儘量減少不必要的屬性修改。
當檢視層次調整時,UIView、CALayer 之間會出現很多方法呼叫與通知,所以在優化效能時,應該儘量避免調整檢視層次、新增和移除檢視。
物件銷燬
物件的銷燬雖然消耗資源不多,但累積起來也是不容忽視的。通常當容器類持有大量物件時,其銷燬時的資源消耗就非常明顯。同樣的,如果物件可以放到後臺執行緒去釋放,那就挪到後臺執行緒去。這裡有個小 Tip:把物件捕獲到 block 中,然後扔到後臺佇列去隨便傳送個訊息以避免編譯器警告,就可以讓物件在後臺執行緒銷燬了。
|
1 2 3 4 5 |
NSArray *tmp=self.array; self.array=nil; dispatch_async(queue,^{ [tmp class]; }); |
佈局計算
檢視佈局的計算是 App 中最為常見的消耗 CPU 資源的地方。如果能在後臺執行緒提前計算好檢視佈局、並且對檢視佈局進行快取,那麼這個地方基本就不會產生效能問題了。
不論通過何種技術對檢視進行佈局,其最終都會落到對 UIView.frame/bounds/center 等屬性的調整上。上面也說過,對這些屬性的調整非常消耗資源,所以儘量提前計算好佈局,在需要時一次性調整好對應屬性,而不要多次、頻繁的計算和調整這些屬性。
Autolayout
Autolayout 是蘋果本身提倡的技術,在大部分情況下也能很好的提升開發效率,但是 Autolayout 對於複雜檢視來說常常會產生嚴重的效能問題。隨著檢視數量的增長,Autolayout 帶來的 CPU 消耗會呈指數級上升。具體資料可以看這個文章:http://pilky.me/36/。 如果你不想手動調整 frame 等屬性,你可以用一些工具方法替代(比如常見的 left/right/top/bottom/width/height 快捷屬性),或者使用 ComponentKit、AsyncDisplayKit 等框架。
文字計算
如果一個介面中包含大量文字(比如微博微信朋友圈等),文字的寬高計算會佔用很大一部分資源,並且不可避免。如果你對文字顯示沒有特殊要求,可以參考下 UILabel 內部的實現方式:用 [NSAttributedString boundingRectWithSize:options:context:] 來計算文字寬高,用 -[NSAttributedString drawWithRect:options:context:] 來繪製文字。儘管這兩個方法效能不錯,但仍舊需要放到後臺執行緒進行以避免阻塞主執行緒。
如果你用 CoreText 繪製文字,那就可以先生成 CoreText 排版物件,然後自己計算了,並且 CoreText 物件還能保留以供稍後繪製使用。
文字渲染
螢幕上能看到的所有文字內容控制元件,包括 UIWebView,在底層都是通過 CoreText 排版、繪製為 Bitmap 顯示的。常見的文字控制元件 (UILabel、UITextView 等),其排版和繪製都是在主執行緒進行的,當顯示大量文字時,CPU 的壓力會非常大。對此解決方案只有一個,那就是自定義文字控制元件,用 TextKit 或最底層的 CoreText 對文字非同步繪製。儘管這實現起來非常麻煩,但其帶來的優勢也非常大,CoreText 物件建立好後,能直接獲取文字的寬高等資訊,避免了多次計算(調整 UILabel 大小時算一遍、UILabel 繪製時內部再算一遍);CoreText 物件佔用記憶體較少,可以快取下來以備稍後多次渲染。
圖片的解碼
當你用 UIImage 或 CGImageSource 的那幾個方法建立圖片時,圖片資料並不會立刻解碼。圖片設定到 UIImageView 或者 CALayer.contents 中去,並且 CALayer 被提交到 GPU 前,CGImage 中的資料才會得到解碼。這一步是發生在主執行緒的,並且不可避免。如果想要繞開這個機制,常見的做法是在後臺執行緒先把圖片繪製到 CGBitmapContext 中,然後從 Bitmap 直接建立圖片。目前常見的網路圖片庫都自帶這個功能。
影像的繪製
影像的繪製通常是指用那些以 CG 開頭的方法把影像繪製到畫布中,然後從畫布建立圖片並顯示這樣一個過程。這個最常見的地方就是 [UIView drawRect:] 裡面了。由於 CoreGraphic 方法通常都是執行緒安全的,所以影像的繪製可以很容易的放到後臺執行緒進行。一個簡單非同步繪製的過程大致如下(實際情況會比這個複雜得多,但原理基本一致):
|
GPU 資源消耗原因和解決方案
相對於 CPU 來說,GPU 能幹的事情比較單一:接收提交的紋理(Texture)和頂點描述(三角形),應用變換(transform)、混合並渲染,然後輸出到螢幕上。通常你所能看到的內容,主要也就是紋理(圖片)和形狀(三角模擬的向量圖形)兩類。
紋理的渲染
所有的 Bitmap,包括圖片、文字、柵格化的內容,最終都要由記憶體提交到視訊記憶體,繫結為 GPU Texture。不論是提交到視訊記憶體的過程,還是 GPU 調整和渲染 Texture 的過程,都要消耗不少 GPU 資源。當在較短時間顯示大量圖片時(比如 TableView 存在非常多的圖片並且快速滑動時),CPU 佔用率很低,GPU 佔用非常高,介面仍然會掉幀。避免這種情況的方法只能是儘量減少在短時間內大量圖片的顯示,儘可能將多張圖片合成為一張進行顯示。
當圖片過大,超過 GPU 的最大紋理尺寸時,圖片需要先由 CPU 進行預處理,這對 CPU 和 GPU 都會帶來額外的資源消耗。目前來說,iPhone 4S 以上機型,紋理尺寸上限都是 4096×4096,更詳細的資料可以看這裡:iosres.com。所以,儘量不要讓圖片和檢視的大小超過這個值。
檢視的混合 (Composing)
當多個檢視(或者說 CALayer)重疊在一起顯示時,GPU 會首先把他們混合到一起。如果檢視結構過於複雜,混合的過程也會消耗很多 GPU 資源。為了減輕這種情況的 GPU 消耗,應用應當儘量減少檢視數量和層次,並在不透明的檢視裡標明 opaque 屬性以避免無用的 Alpha 通道合成。當然,這也可以用上面的方法,把多個檢視預先渲染為一張圖片來顯示。
圖形的生成
CALayer 的 border、圓角、陰影、遮罩(mask),CASharpLayer 的向量圖形顯示,通常會觸發離屏渲染(offscreen rendering),而離屏渲染通常發生在 GPU 中。當一個列表檢視中出現大量圓角的 CALayer,並且快速滑動時,可以觀察到 GPU 資源已經佔滿,而 CPU 資源消耗很少。這時介面仍然能正常滑動,但平均幀數會降到很低。為了避免這種情況,可以嘗試開啟 CALayer.shouldRasterize 屬性,但這會把原本離屏渲染的操作轉嫁到 CPU 上去。對於只需要圓角的某些場合,也可以用一張已經繪製好的圓角圖片覆蓋到原本檢視上面來模擬相同的視覺效果。最徹底的解決辦法,就是把需要顯示的圖形在後臺執行緒繪製為圖片,避免使用圓角、陰影、遮罩等屬性。
AsyncDisplayKit
AsyncDisplayKit 是 Facebook 開源的一個用於保持 iOS 介面流暢的庫,我從中學到了很多東西,所以下面我會花較大的篇幅來對其進行介紹和分析。
ASDK 的由來

ASDK 的作者是 Scott Goodson (Linkedin),
他曾經在蘋果工作,負責 iOS 的一些內建應用的開發,比如股票、計算器、地圖、鐘錶、設定、Safari 等,當然他也參與了 UIKit framework 的開發。後來他加入 Facebook 後,負責 Paper 的開發,建立並開源了 AsyncDisplayKit。目前他在 Pinterest 和 Instagram 負責 iOS 開發和使用者體驗的提升等工作。

ASDK 自 2014 年 6 月開源,10 月釋出 1.0 版。目前 ASDK 即將要釋出 2.0 版。
V2.0 增加了更多佈局相關的程式碼,ComponentKit 團隊為此貢獻很多。
現在 Github 的 master 分支上的版本是 V1.9.1,已經包含了 V2.0 的全部內容。
ASDK 的資料
想要了解 ASDK 的原理和細節,最好從下面幾個視訊開始:
2014.10.15 NSLondon – Scott Goodson – Behind AsyncDisplayKit
2015.03.02 MCE 2015 – Scott Goodson – Effortless Responsiveness with AsyncDisplayKit
2015.10.25 AsyncDisplayKit 2.0: Intelligent User Interfaces – NSSpain 2015
前兩個視訊內容大同小異,都是介紹 ASDK 的基本原理,附帶介紹 POP 等其他專案。
後一個視訊增加了 ASDK 2.0 的新特性的介紹。
除此之外,還可以到 Github Issues 裡看一下 ASDK 相關的討論,下面是幾個比較重要的內容:
關於 Runloop Dispatch
關於 ComponentKit 和 ASDK 的區別
為什麼不支援 Storyboard 和 Autolayout
如何評測介面的流暢度
之後,還可以到 Google Groups 來檢視和討論更多內容:
https://groups.google.com/forum/#!forum/asyncdisplaykit
ASDK 的基本原理
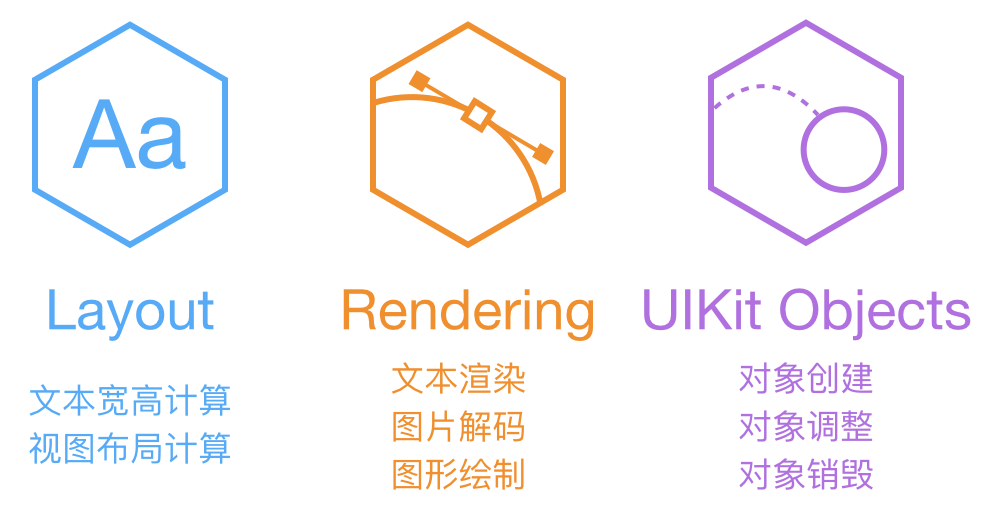
ASDK 認為,阻塞主執行緒的任務,主要分為上面這三大類。文字和佈局的計算、渲染、解碼、繪製都可以通過各種方式非同步執行,但 UIKit 和 Core Animation 相關操作必需在主執行緒進行。ASDK 的目標,就是儘量把這些任務從主執行緒挪走,而挪不走的,就儘量優化效能。
為了達成這一目標,ASDK 嘗試對 UIKit 元件進行封裝:
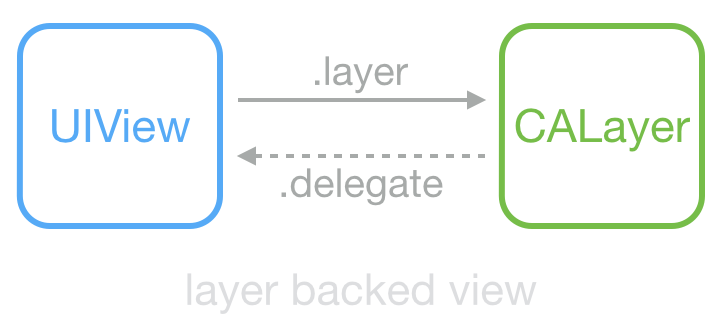
這是常見的 UIView 和 CALayer 的關係:View 持有 Layer 用於顯示,View 中大部分顯示屬性實際是從 Layer 對映而來;Layer 的 delegate 在這裡是 View,當其屬性改變、動畫產生時,View 能夠得到通知。UIView 和 CALayer 不是執行緒安全的,並且只能在主執行緒建立、訪問和銷燬。
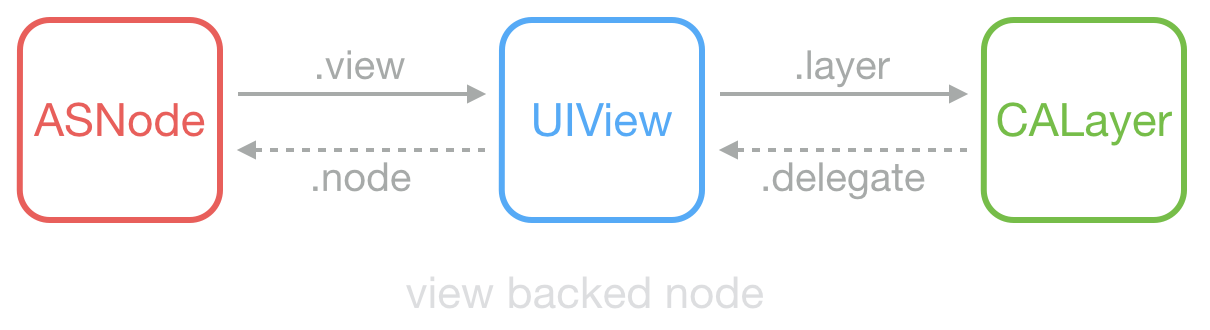
ASDK 為此建立了 ASDisplayNode 類,包裝了常見的檢視屬性(比如 frame/bounds/alpha/transform/backgroundColor/superNode/subNodes 等),然後它用 UIView->CALayer 相同的方式,實現了 ASNode->UIView 這樣一個關係。
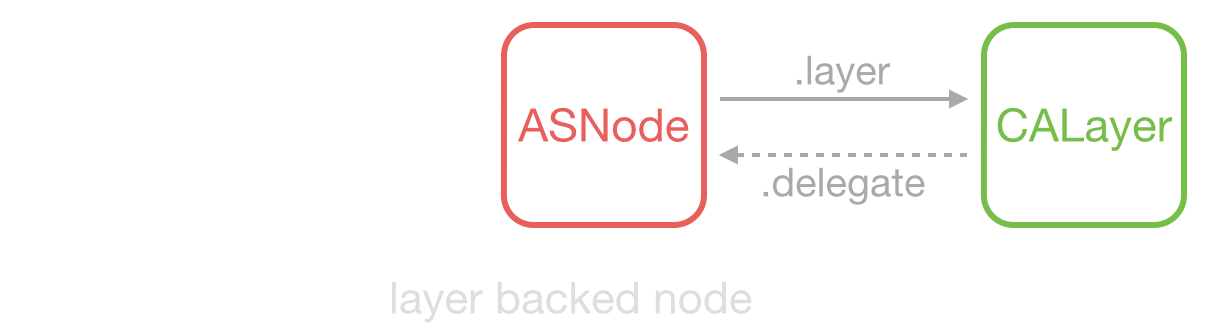
當不需要響應觸控事件時,ASDisplayNode 可以被設定為 layer backed,即 ASDisplayNode 充當了原來 UIView 的功能,節省了更多資源。
與 UIView 和 CALayer 不同,ASDisplayNode 是執行緒安全的,它可以在後臺執行緒建立和修改。Node 剛建立時,並不會在內部新建 UIView 和 CALayer,直到第一次在主執行緒訪問 view 或 layer 屬性時,它才會在內部生成對應的物件。當它的屬性(比如frame/transform)改變後,它並不會立刻同步到其持有的 view 或 layer 去,而是把被改變的屬性儲存到內部的一箇中間變數,稍後在需要時,再通過某個機制一次性設定到內部的 view 或 layer。
通過模擬和封裝 UIView/CALayer,開發者可以把程式碼中的 UIView 替換為 ASNode,很大的降低了開發和學習成本,同時能獲得 ASDK 底層大量的效能優化。為了方便使用, ASDK 把大量常用控制元件都封裝成了 ASNode 的子類,比如 Button、Control、Cell、Image、ImageView、Text、TableView、CollectionView 等。利用這些控制元件,開發者可以儘量避免直接使用 UIKit 相關控制元件,以獲得更完整的效能提升。
ASDK 的圖層預合成

有時一個 layer 會包含很多 sub-layer,而這些 sub-layer 並不需要響應觸控事件,也不需要進行動畫和位置調整。ASDK 為此實現了一個被稱為 pre-composing 的技術,可以把這些 sub-layer 合成渲染為一張圖片。開發時,ASNode 已經替代了 UIView 和 CALayer;直接使用各種 Node 控制元件並設定為 layer backed 後,ASNode 甚至可以通過預合成來避免建立內部的 UIView 和 CALayer。
通過這種方式,把一個大的層級,通過一個大的繪製方法繪製到一張圖上,效能會獲得很大提升。CPU 避免了建立 UIKit 物件的資源消耗,GPU 避免了多張 texture 合成和渲染的消耗,更少的 bitmap 也意味著更少的記憶體佔用。
ASDK 非同步併發操作

自 iPhone 4S 起,iDevice 已經都是雙核 CPU 了,現在的 iPad 甚至已經更新到 3 核了。充分利用多核的優勢、併發執行任務對保持介面流暢有很大作用。ASDK 把佈局計算、文字排版、圖片/文字/圖形渲染等操作都封裝成較小的任務,並利用 GCD 非同步併發執行。如果開發者使用了 ASNode 相關的控制元件,那麼這些併發操作會自動在後臺進行,無需進行過多配置。
Runloop 任務分發
Runloop work distribution 是 ASDK 比較核心的一個技術,ASDK 的介紹視訊和文件中都沒有詳細展開介紹,所以這裡我會多做一些分析。如果你對 Runloop 還不太瞭解,可以看一下我之前的文章 深入理解RunLoop,裡面對 ASDK 也有所提及。
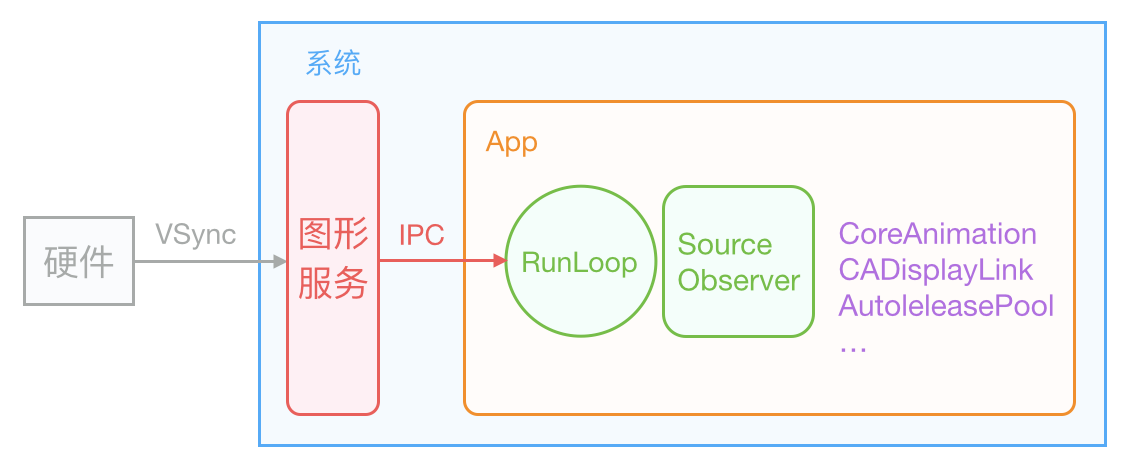
iOS 的顯示系統是由 VSync 訊號驅動的,VSync 訊號由硬體時鐘生成,每秒鐘發出 60 次(這個值取決裝置硬體,比如 iPhone 真機上通常是 59.97)。iOS 圖形服務接收到 VSync 訊號後,會通過 IPC 通知到 App 內。App 的 Runloop 在啟動後會註冊對應的 CFRunLoopSource 通過 mach_port 接收傳過來的時鐘訊號通知,隨後 Source 的回撥會驅動整個 App 的動畫與顯示。
Core Animation 在 RunLoop 中註冊了一個 Observer,監聽了 BeforeWaiting 和 Exit 事件。這個 Observer 的優先順序是 2000000,低於常見的其他 Observer。當一個觸控事件到來時,RunLoop 被喚醒,App 中的程式碼會執行一些操作,比如建立和調整檢視層級、設定 UIView 的 frame、修改 CALayer 的透明度、為檢視新增一個動畫;這些操作最終都會被 CALayer 捕獲,並通過 CATransaction 提交到一箇中間狀態去(CATransaction 的文件略有提到這些內容,但並不完整)。當上面所有操作結束後,RunLoop 即將進入休眠(或者退出)時,關注該事件的 Observer 都會得到通知。這時 CA 註冊的那個 Observer 就會在回撥中,把所有的中間狀態合併提交到 GPU 去顯示;如果此處有動畫,CA 會通過 DisplayLink 等機制多次觸發相關流程。
ASDK 在此處模擬了 Core Animation 的這個機制:所有針對 ASNode 的修改和提交,總有些任務是必需放入主執行緒執行的。當出現這種任務時,ASNode 會把任務用 ASAsyncTransaction(Group) 封裝並提交到一個全域性的容器去。ASDK 也在 RunLoop 中註冊了一個 Observer,監視的事件和 CA 一樣,但優先順序比 CA 要低。當 RunLoop 進入休眠前、CA 處理完事件後,ASDK 就會執行該 loop 內提交的所有任務。具體程式碼見這個檔案:ASAsyncTransactionGroup。
通過這種機制,ASDK 可以在合適的機會把非同步、併發的操作同步到主執行緒去,並且能獲得不錯的效能。
其他
ASDK 中還有封裝很多高階的功能,比如滑動列表的預載入、V2.0新增的新的佈局模式等。ASDK 是一個很龐大的庫,它本身並不推薦你把整個 App 全部都改為 ASDK 驅動,把最需要提升互動效能的地方用 ASDK 進行優化就足夠了。
微博 Demo 效能優化技巧
我為了演示 YYKit 的功能,實現了微博和 Twitter 的 Demo,併為它們做了不少效能優化,下面就是優化時用到的一些技巧。
預排版
當獲取到 API JSON 資料後,我會把每條 Cell 需要的資料都在後臺執行緒計算並封裝為一個佈局物件 CellLayout。CellLayout 包含所有文字的 CoreText 排版結果、Cell 內部每個控制元件的高度、Cell 的整體高度。每個 CellLayout 的記憶體佔用並不多,所以當生成後,可以全部快取到記憶體,以供稍後使用。這樣,TableView 在請求各個高度函式時,不會消耗任何多餘計算量;當把 CellLayout 設定到 Cell 內部時,Cell 內部也不用再計算佈局了。
對於通常的 TableView 來說,提前在後臺計算好佈局結果是非常重要的一個效能優化點。為了達到最高效能,你可能需要犧牲一些開發速度,不要用 Autolayout 等技術,少用 UILabel 等文字控制元件。但如果你對效能的要求並不那麼高,可以嘗試用 TableView 的預估高度的功能,並把每個 Cell 高度快取下來。這裡有個來自百度知道團隊的開源專案可以很方便的幫你實現這一點:FDTemplateLayoutCell。
預渲染
微博的頭像在某次改版中換成了圓形,所以我也跟進了一下。當頭像下載下來後,我會在後臺執行緒將頭像預先渲染為圓形並單獨儲存到一個 ImageCache 中去。
對於 TableView 來說,Cell 內容的離屏渲染會帶來較大的 GPU 消耗。在 Twitter Demo 中,我為了圖省事兒用到了不少 layer 的圓角屬性,你可以在低效能的裝置(比如 iPad 3)上快速滑動一下這個列表,能感受到雖然列表並沒有較大的卡頓,但是整體的平均幀數降了下來。用 Instument 檢視時能夠看到 GPU 已經滿負荷運轉,而 CPU 卻比較清閒。為了避免離屏渲染,你應當儘量避免使用 layer 的 border、corner、shadow、mask 等技術,而儘量在後臺執行緒預先繪製好對應內容。
非同步繪製
我只在顯示文字的控制元件上用到了非同步繪製的功能,但效果很不錯。我參考 ASDK 的原理,實現了一個簡單的非同步繪製控制元件。這塊程式碼我單獨提取出來,放到了這裡:YYAsyncLayer。YYAsyncLayer 是 CALayer 的子類,當它需要顯示內容(比如呼叫了 [layer setNeedDisplay])時,它會向 delegate,也就是 UIView 請求一個非同步繪製的任務。在非同步繪製時,Layer 會傳遞一個 BOOL(^isCancelled)() 這樣的 block,繪製程式碼可以隨時呼叫該 block 判斷繪製任務是否已經被取消。
當 TableView 快速滑動時,會有大量非同步繪製任務提交到後臺執行緒去執行。但是有時滑動速度過快時,繪製任務還沒有完成就可能已經被取消了。如果這時仍然繼續繪製,就會造成大量的 CPU 資源浪費,甚至阻塞執行緒並造成後續的繪製任務遲遲無法完成。我的做法是儘量快速、提前判斷當前繪製任務是否已經被取消;在繪製每一行文字前,我都會呼叫 isCancelled() 來進行判斷,保證被取消的任務能及時退出,不至於影響後續操作。
目前有些第三方微部落格戶端(比如 VVebo、墨客等),使用了一種方式來避免高速滑動時 Cell 的繪製過程,相關實現見這個專案:VVeboTableViewDemo。它的原理是,當滑動時,鬆開手指後,立刻計算出滑動停止時 Cell 的位置,並預先繪製那個位置附近的幾個 Cell,而忽略當前滑動中的 Cell。這個方法比較有技巧性,並且對於滑動效能來說提升也很大,唯一的缺點就是快速滑動中會出現大量空白內容。如果你不想實現比較麻煩的非同步繪製但又想保證滑動的流暢性,這個技巧是個不錯的選擇。
全域性併發控制
當我用 concurrent queue 來執行大量繪製任務時,偶爾會遇到這種問題:

大量的任務提交到後臺佇列時,某些任務會因為某些原因(此處是 CGFont 鎖)被鎖住導致執行緒休眠,或者被阻塞,concurrent queue 隨後會建立新的執行緒來執行其他任務。當這種情況變多時,或者 App 中使用了大量 concurrent queue 來執行較多工時,App 在同一時刻就會存在幾十個執行緒同時執行、建立、銷燬。CPU 是用時間片輪轉來實現執行緒併發的,儘管 concurrent queue 能控制執行緒的優先順序,但當大量執行緒同時建立執行銷燬時,這些操作仍然會擠佔掉主執行緒的 CPU 資源。ASDK 有個 Feed 列表的 Demo:SocialAppLayout,當列表內 Cell 過多,並且非常快速的滑動時,介面仍然會出現少量卡頓,我謹慎的猜測可能與這個問題有關。
使用 concurrent queue 時不可避免會遇到這種問題,但使用 serial queue 又不能充分利用多核 CPU 的資源。我寫了一個簡單的工具 YYDispatchQueuePool,為不同優先順序建立和 CPU 數量相同的 serial queue,每次從 pool 中獲取 queue 時,會輪詢返回其中一個 queue。我把 App 內所有非同步操作,包括影像解碼、物件釋放、非同步繪製等,都按優先順序不同放入了全域性的 serial queue 中執行,這樣儘量避免了過多執行緒導致的效能問題。
更高效的非同步圖片載入
SDWebImage 在這個 Demo 裡仍然會產生少量效能問題,並且有些地方不能滿足我的需求,所以我自己實現了一個效能更高的圖片載入庫。在顯示簡單的單張圖片時,利用 UIView.layer.contents 就足夠了,沒必要使用 UIImageView 帶來額外的資源消耗,為此我在 CALayer 上新增了 setImageWithURL 等方法。除此之外,我還把圖片解碼等操作通過 YYDispatchQueuePool 進行管理,控制了 App 匯流排程數量。
其他可以改進的地方
上面這些優化做完後,微博 Demo 已經非常流暢了,但在我的設想中,仍然有一些進一步優化的技巧,但限於時間和精力我並沒有實現,下面簡單列一下:
列表中有不少視覺元素並不需要觸控事件,這些元素可以用 ASDK 的圖層合成技術預先繪製為一張圖。
再進一步減少每個 Cell 內圖層的數量,用 CALayer 替換掉 UIView。
目前每個 Cell 的型別都是相同的,但顯示的內容卻各部一樣,比如有的 Cell 有圖片,有的 Cell 裡是卡片。把 Cell 按型別劃分,進一步減少 Cell 內不必要的檢視物件和操作,應該能有一些效果。
把需要放到主執行緒執行的任務劃分為足夠小的塊,並通過 Runloop 來進行排程,在每個 Loop 裡判斷下一次 VSync 的時間,並在下次 VSync 到來前,把當前未執行完的任務延遲到下一個機會去。這個只是我的一個設想,並不一定能實現或起作用。
如何評測介面的流暢度
最後還是要提一下,“過早的優化是萬惡之源”,在需求未定,效能問題不明顯時,沒必要嘗試做優化,而要儘量正確的實現功能。做效能優化時,也最好是走修改程式碼 -> Profile -> 修改程式碼這樣一個流程,優先解決最值得優化的地方。
如果你需要一個明確的 FPS 指示器,可以嘗試一下 KMCGeigerCounter。對於 CPU 的卡頓,它可以通過內建的 CADisplayLink 檢測出來;對於 GPU 帶來的卡頓,它用了一個 1×1 的 SKView 來進行監視。這個專案有兩個小問題:SKView 雖然能監視到 GPU 的卡頓,但引入 SKView 本身就會對 CPU/GPU 帶來額外的一點的資源消耗;這個專案在 iOS 9 下有一些相容問題,需要稍作調整。
我自己也寫了個簡單的 FPS 指示器:FPSLabel 只有幾十行程式碼,僅用到了 CADisplayLink 來監視 CPU 的卡頓問題。雖然不如上面這個工具完善,但日常使用沒有太大問題。
最後,用 Instuments 的 GPU Driver 預設,能夠實時檢視到 CPU 和 GPU 的資源消耗。在這個預設內,你能檢視到幾乎所有與顯示有關的資料,比如 Texture 數量、CA 提交的頻率、GPU 消耗等,在定位介面卡頓的問題時,這是最好的工具。