hadoop(2.x)以hadoop2.2為例完全分散式最新高可靠安裝文件
問題導讀:
1.如何配置各個節點之間無密碼互通?
2.啟動hadoop,看不到程式的原因是什麼?
3.配置hadoop的步驟是什麼?
4.有哪些配置檔案需要修改?
5.如果沒有配置檔案,該如何找到該配置檔案?
6.環境變數配置了,但是不生效的原因是什麼?





通過下面命令
1.export PATH=$PATH:/usr/java/jdk1.7.0_51/bin
通過cat命令,可以檢視

2.為了保證生效執行下面命令
二、CLASSTH配置
上面只是配置了PATH,還需在配置CLASSTH
export CLASSPATH=.:/usr/java/jdk1.7.0_51/jre/lib
執行配置完畢
如果不起作用,採用通過下面配置:
java.sh配置
因為重啟之後,很有會被還原,下面還需要配置java.sh
這裡可以通過
cd /etc/profile.d
vi java.sh
把下面兩行放到java.sh
export PATH=$PATH:/usr/java/jdk1.7.0_51/bin
export CLASSPATH=.:/usr/java/jdk1.7.0_51/jre/lib
儲存。這樣就配置完畢了。

一、需要注意的問題
上面講完,我們開始配置



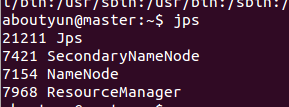
slave1有如下程式

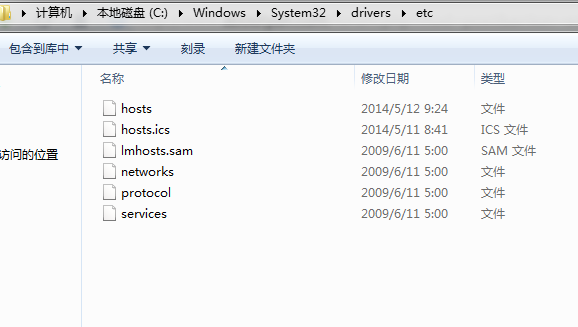
如何修改hosts:
win7 進入下面路徑:
找打hosts
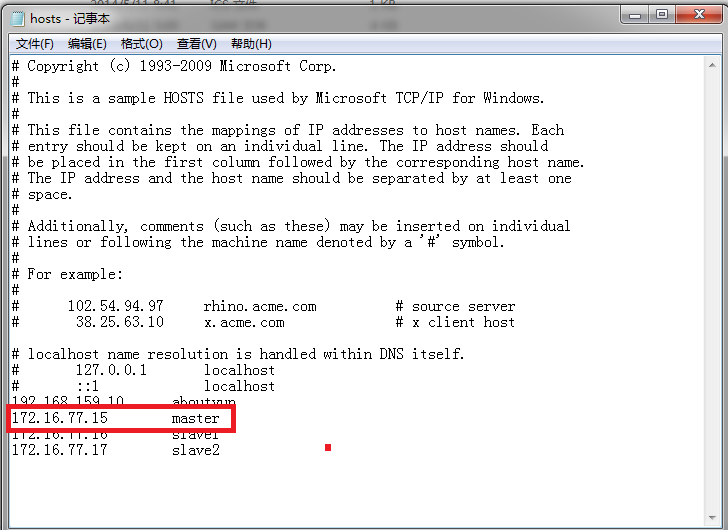
然後開啟,進行如下配置即可看到
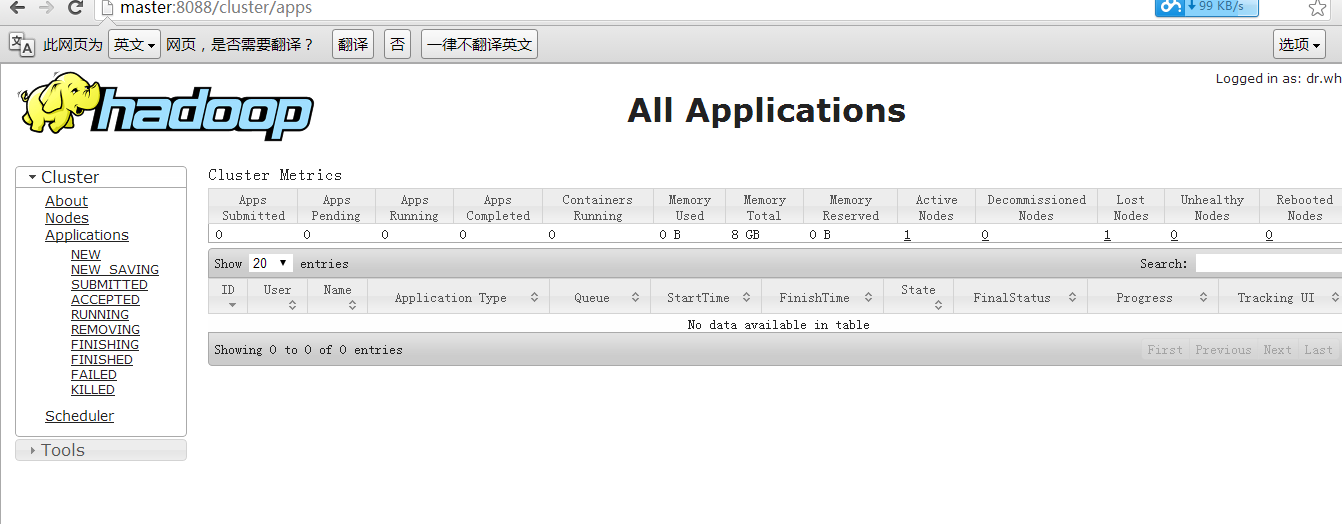
看到下圖:
到此全部完畢。
使用hadoop叢集,更詳細內容,可以檢視
hadoop2.X使用手冊1:通過web埠檢視主節點、slave1節點及叢集執行狀態
hadoop2.X使用手冊2:如何執行自帶wordcount
hadoop2.2執行mapreduce(wordcount)問題總結
本文原連結
http://www.aboutyun.com/thread-7684-1-1.html
下一篇:
hbase 0.96整合到hadoop2.2三個節點全分散式安裝高可靠文件
1.如何配置各個節點之間無密碼互通?
2.啟動hadoop,看不到程式的原因是什麼?
3.配置hadoop的步驟是什麼?
4.有哪些配置檔案需要修改?
5.如果沒有配置檔案,該如何找到該配置檔案?
6.環境變數配置了,但是不生效的原因是什麼?
7.如何檢視hadoop2監控頁面
首先說一下這個安裝過程需要注意的地方
一、使用新建使用者可能會遇到的問題
(1)許可權問題:對於新手經常使用root,剛開始可以使用,但是如果想真正的學習,必須學會使用其他使用者。也就是你需要學會新建使用者,但是新建使用者,並不是所有人都會的。具體可以參考ubuntu建立新使用者並增加管理員許可權,這裡面使用adduser是最方便的。也就是說你需要通過這裡,學會給Linux新增使用者,並且賦權,上面那篇文章會對你有所幫助。
(2)使用新建使用者,你遇到另外一個問題,就是檔案所屬許可權,因為新建的檔案,有的屬於root使用者,有的屬於新建使用者,例如下面情況,我們看到mv.sh是屬於root使用者,大部分屬於aboutyun使用者。所以當我們兩個不同檔案不能訪問的時候,這個可能是原因之一。也是在這裡,當你新建使用者的時候,可能會遇到的新問題。
(3)上面我們只是提出了問題,但是根本沒有解決方案,這裡在提出解決方案,我們如何改變檔案所屬使用者。
比如上圖中,mv.sh屬於root使用者,那麼我們怎麼讓他所屬about雲使用者。可以是下面命令:
解釋一下上面命令的含義:
------------------------------------------------------------------------------------------------------------------------------------------------------
1.sudo:如果不是root使用者,不帶上這個命令會經常遇到麻煩,所以需要養成習慣。至於sudo詳細解釋可以看下面。
2.chown-》change own的意思。即改變所屬檔案。對於他不瞭解的同學,可以檢視:讓你真正瞭解chmod和chown命令的用法
2.chown-》change own的意思。即改變所屬檔案。對於他不瞭解的同學,可以檢視:讓你真正瞭解chmod和chown命令的用法
3.aboutyun:aboutyun代表aboutyun使用者及aboutyun使用者組
4.即是被授權的檔案
------------------------------------------------------------------------------------------------------------------------------------------------------
上面是針對新手的一個解說,不是必須的,如果對Linux已經很熟悉,可以跳過上面步驟。下面我們開始首先要下載
(下載包為hadoop2.2)
下載完畢,我們就需要解壓
這裡是解壓到當前路徑。
這裡就開始動手了,下面也介紹一下整體的情況:
1、這裡我們搭建一個由三臺機器組成的叢集:
172.16.77.15 aboutyun/123456 master
172.16.77.16 aboutyun/123456 slave1
172.16.77.17 aboutyun/123456 slave1
1.1 上面各列分別為IP、user/passwd、hostname
1.2 Hostname可以在/etc/hostname中修改,hostname,hosts的修改詳細可以看ubuntu修改hostname
對於三臺機器都需要修改:
下面是master的修改:通過命令
然後對你裡面的內容修改:
下面修改hostname
修改為master即可
上面hosts基本都一樣,只不過hostname有所差別。
2、打通master到slave節點的SSH無密碼登陸
這裡面打通無密碼登入,很多新手遇到了問題,這裡安裝的時候,具體的操作,可以查閱其他資料:
這是個人總結的哦命令,相信對你有所幫助
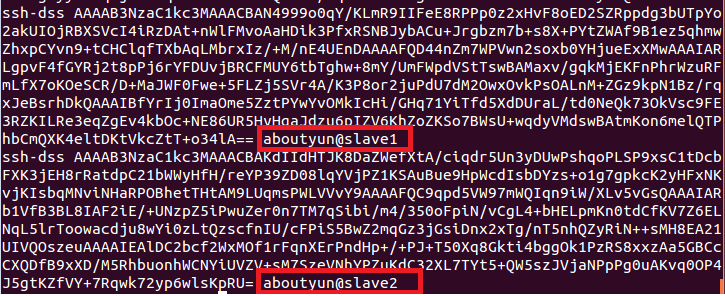
然後這裡在展示一下,authorized_keys是什麼樣子的:
上面的原理,就是我把工鑰放到裡面,然後本臺機器就可以ssh無密碼登入了。如果想彼此無密碼登入,那麼就需要把彼此的工鑰(*.pub)放到authorized_keys裡面
然後我們進行下面步驟:
3.1 安裝ssh
一般系統是預設安裝了ssh命令的。如果沒有,或者版本比較老,則可以重新安 裝:
sudo apt-get install ssh
3.2設定local無密碼登陸
具體步驟如下:
第一步:產生金鑰
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
第二部:匯入authorized_keys
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
第二部匯入的目的是為了無密碼等,這樣輸入如下命令:
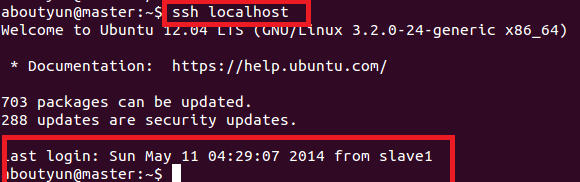
就可以無密碼登入了。
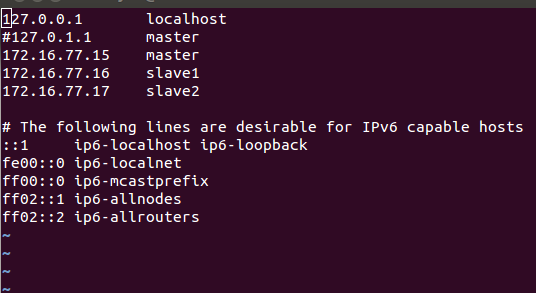
下面展示一下hosts的配置,及無密碼登入的效果
locahost的配置
無密碼登入效果:
3.3設定遠端無密碼登陸
進入master的.ssh目錄
scp authorized_keys aboutyun@slave1:~/.ssh/authorized_keys_from_master
進入slave1的.ssh目錄
cat authorized_keys_from_master >> authorized_keys
至此,可以在master上面ssh slave1進行無密碼登陸了。
【注意】:以上操作在每臺機器上面都要進行。
這裡在強調一下原理:
------------------------------------------------------------------------
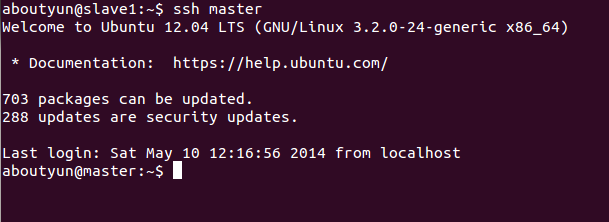
根據上面的資料相信你能得到互通,這裡展現一下效果:
上面是slave1無密碼登入master
這裡是master無密碼登入slave1
------------------------------------------------------------------------
4、安裝jdk
安裝JDK還是比較簡單的.
4.1、下載jdk
http://yunpan.cn/QiujtEVgRTJ4S 訪問密碼 b488
4.2、安裝jdk(這裡以.tar.gz版本,64位系統為例)
jdk的安裝可以參考Hadoop偽分佈安裝過程:Hadoop單機環境搭建指南(ubuntu)
這裡直接解壓到了/usr/jdk1.7下面:
上面首先第一步:
至此,jkd安裝完畢,下面配置環境變數
一、PATH配置
這裡提供一個簡單的方法:通過下面命令
1.export PATH=$PATH:/usr/java/jdk1.7.0_51/bin
通過cat命令,可以檢視
2.為了保證生效執行下面命令
二、CLASSTH配置
上面只是配置了PATH,還需在配置CLASSTH
export CLASSPATH=.:/usr/java/jdk1.7.0_51/jre/lib
執行配置完畢
如果不起作用,採用通過下面配置:
java.sh配置
因為重啟之後,很有會被還原,下面還需要配置java.sh
這裡可以通過
cd /etc/profile.d
vi java.sh
把下面兩行放到java.sh
export PATH=$PATH:/usr/java/jdk1.7.0_51/bin
export CLASSPATH=.:/usr/java/jdk1.7.0_51/jre/lib
儲存。這樣就配置完畢了。
執行下面命令:
現在在執行 java -version就ok了
【注意】每臺機器執行相同操作,最後將java安裝在相同路徑下
三、關閉每臺機器的防火牆
ufw disable (重啟生效)
第三部分 Hadoop 2.2安裝過程
一、需要注意的問題
hadoop2.2的配置還是比較簡單的,但是可能會遇到各種各樣的問題。最常講的就是看不到程式。
看不到程式大致有兩個原因:
1.你的配置檔案有問題。
對於配置檔案,主機名,空格之類的這些都不要帶上。仔細檢查
2.Linux的許可權不正確。
最常出問題的是core-site.xml,與hdfs-site.xml。
core-site.xml
說一下上面引數的含義,這裡是hadoop的臨時檔案目錄,file的含義是使用本地目錄。也就是使用的是Linux的目錄,一定確保下面目錄
的許可權所屬為你建立的使用者。並且這裡面我也要會變通,aboutyun,為我建立的使用者名稱,如果你建立了zhangsan或則lisi,那麼這個目錄就會變為
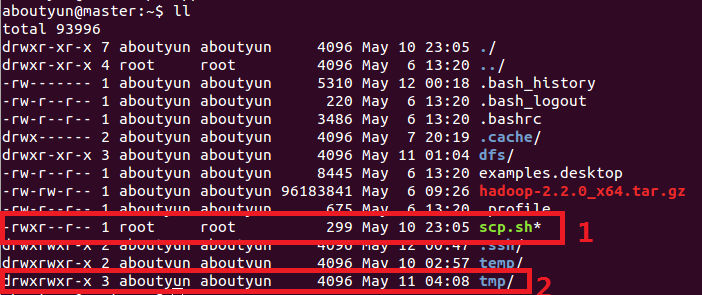
這裡不熟悉,是因為對Linux的不熟悉的原因。這裡在來張圖:
注意:1和2對比。如果你所建立的tmp屬於root,那麼你會看不到程式。
hdfs-site.xml
hdfs-site.xml
同樣也是:要注意下面,你是需要改成自己的使用者名稱的
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/aboutyun/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/aboutyun/dfs/data</value>
</property>
上面講完,我們開始配置
hadoop叢集中每個機器上面的配置基本相同,所以我們先在master上面進行配置部署,然後再複製到其他節點。所以這裡的安裝過程相當於在每臺機器上面都要執行。
【注意】:master和slaves安裝的hadoop路徑要完全一樣,使用者和組也要完全一致
1、 解壓檔案
將第一部分中下載的
解壓到/usr路徑下
解壓到/usr路徑下
並且重新命名,效果如下
2、 hadoop配置過程
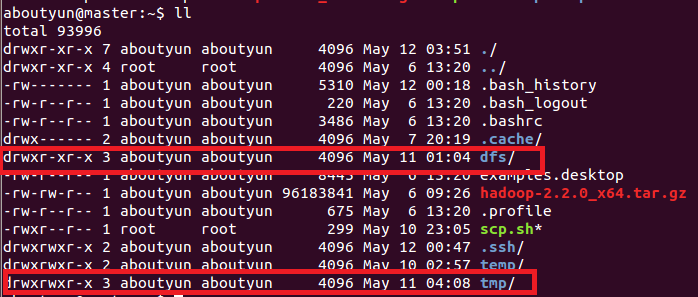
配置之前,需要在master本地檔案系統建立以下資料夾:
~/dfs/name
~/dfs/data
~/tmp
這裡檔案許可權:建立完畢,你會看到紅線部分,注意所屬使用者及使用者組。如果不再新建的使用者組下面,可以使用下面命令來修改:讓你真正瞭解chmod和chown命令的用法
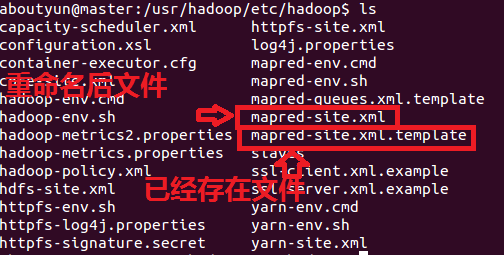
這裡要涉及到的配置檔案有7個:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上檔案預設不存在的,可以複製相應的template檔案獲得。下面舉例:
配置檔案1:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/jdk1.7)
配置檔案2:yarn-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/jdk1.7)
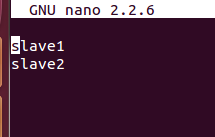
配置檔案3:slaves (這個檔案裡面儲存所有slave節點)
寫入以下內容:
配置檔案4:core-site.xml
配置檔案5:hdfs-site.xml
配置檔案6:mapred-site.xml
配置檔案7:yarn-site.xml
3、複製到其他節點
上面配置完畢,我們基本上完成了90%了剩下就是複製。我們可以把整個hadoop複製過去:使用如下命令:
這裡記得先複製到home/aboutyun下面,然後在轉移到/usr下面。
後面我們會經常遇到問題,經常修改配置檔案,所以修改完一個配置檔案後,其他節點都需要修改,這裡附上指令碼操作方便:
4.配置環境變數
第一步:
第二步:新增如下內容:記得如果你的路徑改變了,你也許需要做相應的改變。
4、啟動驗證
4.1 啟動hadoop
格式化namenode:
或則使用下面命令:
啟動hdfs:
此時在master上面執行的程式有:
namenodesecondarynamenode
slave節點上面執行的程式有:datanode
啟動yarn:
我們看到如下效果:
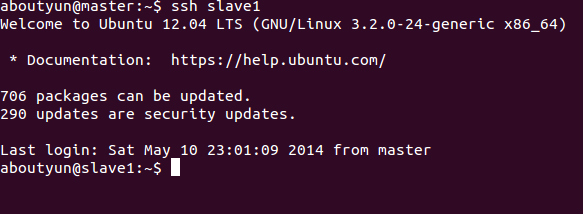
master有如下程式:
slave1有如下程式
此時hadoop叢集已全部配置完成!!!
【注意】:而且所有的配置檔案<name>和<value>節點處不要有空格,否則會報錯!
然後我們輸入:(這裡有的同學沒有配置hosts,所以輸出master訪問不到,如果訪問不到輸入ip地址即可)
如何修改hosts:
win7 進入下面路徑:
找打hosts
然後開啟,進行如下配置即可看到
看到下圖:
到此全部完畢。
使用hadoop叢集,更詳細內容,可以檢視
hadoop2.X使用手冊1:通過web埠檢視主節點、slave1節點及叢集執行狀態
hadoop2.X使用手冊2:如何執行自帶wordcount
hadoop2.2執行mapreduce(wordcount)問題總結
本文原連結
http://www.aboutyun.com/thread-7684-1-1.html
下一篇:
hbase 0.96整合到hadoop2.2三個節點全分散式安裝高可靠文件
相關文章
- CentOS6 hadoop2.4完全分散式安裝文件CentOSHadoop分散式
- hadoop2.4.1完全分散式安裝Hadoop分散式
- Hadoop yarn完全分散式安裝筆記HadoopYarn分散式筆記
- Hadoop完全分散式模式的安裝和配置Hadoop分散式模式
- 完全分散式Hadoop叢集的安裝部署步驟分散式Hadoop
- hadoop完全分散式搭建Hadoop分散式
- centos6下安裝部署hadoop2.2CentOSHadoop
- hadoop學習之hadoop完全分散式叢集安裝Hadoop分散式
- hadoop偽分散式安裝Hadoop分散式
- Storm-1.2.2完全分散式安裝ORM分散式
- 完全分散式模式hadoop叢集安裝與配置分散式模式Hadoop
- Hadoop3.0完全分散式叢集安裝部署Hadoop分散式
- 虛擬機器裝Hadoop叢集完全分散式虛擬機Hadoop分散式
- Hadoop完全分散式叢集配置Hadoop分散式
- Hadoop hdfs完全分散式搭建教程Hadoop分散式
- hadoop完全分散式環境搭建Hadoop分散式
- hadoop2.2.0偽分散式安裝Hadoop分散式
- [hadoop] hadoop-all-in-one-偽分散式安裝Hadoop分散式
- hadoop 2.8.5完全分散式環境搭建Hadoop分散式
- [hadoop]hadoop2.6完全分散式環境搭建Hadoop分散式
- Hadoop3偽分散式安裝指南Hadoop分散式
- Hadoop偽分散式安裝(MapReduce+Yarn)Hadoop分散式Yarn
- CentOS7 hadoop3.3.1安裝(單機分散式、偽分散式、分散式)CentOSHadoop分散式
- 生產環境Hadoop大叢集完全分散式模式安裝 NFS+DNS+awkHadoop分散式模式NFSDNS
- centOS 7-Hadoop3.3.0完全分散式部署CentOSHadoop分散式
- Hadoop--HDFS完全分散式(簡單版)Hadoop分散式
- Hadoop叢集完全分散式模式環境部署Hadoop分散式模式
- airflow2.0.2分散式安裝文件AI分散式
- Hadoop 2.6 叢集搭建從零開始之4 Hadoop的安裝與配置(完全分散式環境)Hadoop分散式
- hadoop 0.20.2偽分散式安裝詳解Hadoop分散式
- 分散式Hadoop1.2.1叢集的安裝分散式Hadoop
- Hadoop3.x完全分散式搭建(詳細)Hadoop分散式
- 以電商為例 讀懂分散式架構的前世今生分散式架構
- 分散式處理框架Hadoop的安裝與使用分散式框架Hadoop
- zabbix分散式監控環境完全編譯安裝部署分散式編譯
- 【Hadoop】 分散式Hadoop叢集安裝配置Hadoop分散式
- CentOS7下搭建hadoop2.7.3完全分散式CentOSHadoop分散式
- Hadoop 2.6 以WordCount為例理解Map ReduceHadoop