從hadoop發展角度徹底明白hadoop1.x與hadoop2.x的區別
1.hadoop1.x改造如果是兩個jobtraker,你認為解決了什麼問題?
2.hadoop1.x改造如果是兩個jobtraker,你認為未解決了什麼問題?
3.你如何看待hadoop2.x的yarn?
hadoop1.x與hadoop2.x的區別,在初學者看來,起始存在很多模糊的地方。如果看這篇文章,當然需要對hadoop有個基本的認識。
推薦參考:
零基礎學習hadoop到上手工作線路指導(初級篇) http://www.aboutyun.com/forum.php?mod=viewthread&tid=6780
我們知道hadoop是用來處理大資料的。hadoop1.x被不少公司使用,但是使用過程中存在不少問題。
hadoop1.x存在哪些問題
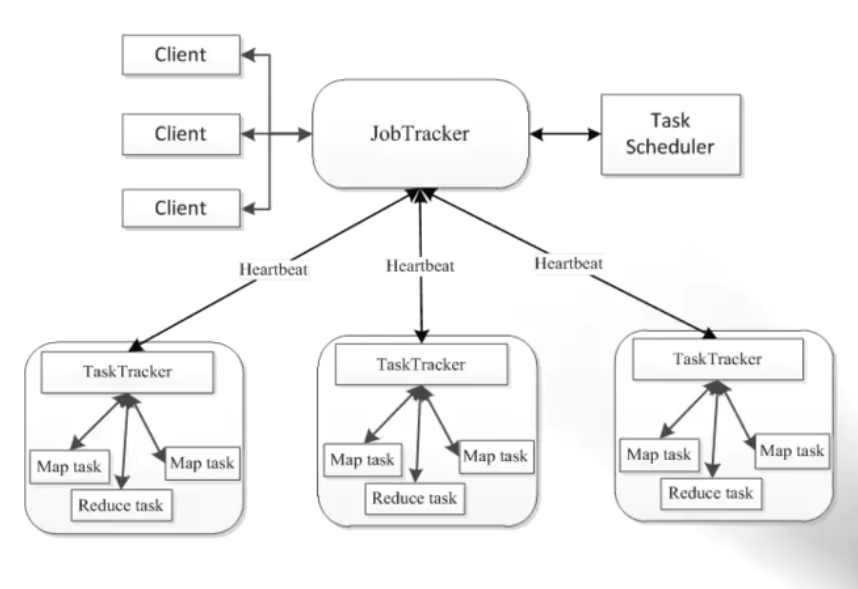
由於現在大家都接觸的是hadoop2.x。對於hadoop1.x瞭解還是比較少的。
很多人問,如果沒有1.x的基礎,能否學習hadoop2.x。答案是可以的。但是如果瞭解hadoop1.x有助於我們理解hadoop2.x。我們來看看hadoop1.x存在哪些問題。
hadoop有jobtracker,trasktracker.對於jobtracker,trasktracker剛接觸其實還是比較抽象的。可能多次遇到過。但是對於它的認識和理解還是比較模糊。
我們這裡打個比喻:在一個組織結構中,既有管理者,又有執行者。而jobtracker,trasktracker則是管理者,執行者是map task和reduce task。
trasktracker像是一箇中層管理者,既監控執行者--map task和reduce task,如果map任務或reduce任務有更新,會通過心跳(一般間隔是3秒)告訴TraskTracker,TraskTracker再通過心跳(一般至少5s,因為代價比較大)告訴JobTracker。
JobTracker是最高層管理者,它接受trasktracker的心跳,負責資源管理和job的排程。
上面如果你思維謹密,就能看出,如果一旦最高層管理JobTracker掛掉,那麼整個叢集就癱瘓了。為什麼那?
1.不能提交job。
2.不能分配資源
3.job無法排程
這就有點像一個國家的leader掛掉了,那麼誰會來負責國家的運轉。如果你瞭解執行機制,其實也是有方案的。而這個方案就是我們所熟悉的高可用方案。而如果JobTracker掛掉了,顯然hadoop叢集就掛掉了。所以顯然hadoop1.x是存在缺陷的。
既然存在缺陷,那麼我們該如何來彌補。如果還是在原先的框架上修改,弄兩個jobtracker是否可以。這肯定是一種方案。但是hadoop也是有野心的。作為大資料最初的開拓者,spark,storm都非常的活躍。
所以我們列出了,hadoop需改造的下面需求:
1.hadoop存在單點故障
2.hadoop能否統一spark,storm
從上面我們看到hadoop自身存在問題,需要改造,同時又想統一spark和storm。所以hadoop急切需要改造升級。
這裡想到了很多種解決方案。
方案1:兩個jobtraker
hadoop自身來講,既然存在單點故障,所以那麼我們可以建立兩個jobtraker,這是否可以。答案是可以的。因為一旦一個掛掉。我們啟用另外一個jobtraker,這也是合適的。但是還存在另外一個問題,就是該如何統一spark和storm。如果spark和storm執行的話,兩個jobtraker是否可以。答案是不行的,因為jobtraker其實還是沒有脫離他本身的框架,只能執行hadoop的map和reduce。spark的DAG和storm的拓撲,還是不能執行的。那如果你說我們在jobtraker中加入不就行了。可是這是相當麻煩的,jobtraker肯定會累死的,他的任務太多。顯然需要分離的職務。
方案2:Yarn
兩個jobtraker是不行了,那麼就從jobtraker職能分離並且解決存在的問題
1.效能問題
2.單點故障
3.能執行mapreduce,spark,storm。
所以這時候就產生了Yarn。
相關文章
- 從零自學Hadoop(10):Hadoop1.x與Hadoop2.xHadoop
- Hadoop1.x與Hadoop2的區別Hadoop
- Deno 正式釋出,徹底弄明白和 node 的區別
- hadoop之 Hadoop1.x和Hadoop2.x構成對比Hadoop
- Android原始碼角度分析事件分發消費(徹底整明白Android事件)Android原始碼事件
- 徹底明白ip地址,區分localhost、127.0.0.1和0.0.0.0localhost127.0.0.1
- 從IL角度徹底理解回撥_委託_指標指標
- hadoop1.x和2.x的一些主要區別Hadoop
- 【JavaScript】徹底明白this在函式中的指向JavaScript函式
- Android AsyncTask完全解析,帶你從原始碼的角度徹底理解Android原始碼
- 徹底搞懂Node.js中exports與module.exports的區別Node.jsExport
- Android事件分發機制完全解析,帶你從原始碼的角度徹底理解(上)Android事件原始碼
- 30分鐘,讓你徹底明白Promise原理Promise
- 徹底理解斜槓和反斜槓的區別
- Java 原始碼出發徹底搞懂String與StringBuffer和StringBuilder的區別Java原始碼UI
- 這麼講執行緒池,徹底明白了!執行緒
- 【安卓筆記】Volley全方位解析,帶你從原始碼的角度徹底理解安卓筆記原始碼
- Android ListView工作原理完全解析,帶你從原始碼的角度徹底理解AndroidView原始碼
- 【Hadoop】SNN與HA的區別Hadoop
- [Hadoop]chukwa與ganglia的區別Hadoop
- 徹底搞明白find命令的-mtime引數的含義
- 從區塊鏈底層技術開發角度闡述LikeLib技術區塊鏈
- 這一次,徹底幫你搞明白 ImageView ScaleTypeView
- Hadoop1.x MapReduce的Slot的理解Hadoop
- 徹底搞明白Spring中的自動裝配和AutowiredSpring
- [Hadoop]Pig與Hive的區別HadoopHive
- Redis-技術專區-幫從底層徹底吃透RDB技術原理Redis
- Redis-技術專區-幫從底層徹底吃透AOF技術原理Redis
- ClickHouse與Hive的區別,終於有人講明白了Hive
- 從OC角度思考OKR的底層邏輯OKR
- hadoop1.X學習筆記Hadoop筆記
- IL角度理解for 與foreach的區別——迭代器模式模式
- 徹底弄清楚session,cookie,WebStorage的區別及應用場景SessionCookieWeb
- 徹底弄懂C#中delegate、event、EventHandler、Action、Func的使用和區別C#
- hadoop發行版本之間的區別Hadoop
- Hadoop2.x 引數彙總Hadoop
- Hadoop2.x學習筆記Hadoop筆記
- ArrayList 從原始碼角度剖析底層原理原始碼