在caffe上跑自己的資料
【原文:http://blog.csdn.net/u012878523/article/details/41698209】
本文介紹如何使用caffe對自己的影象資料進行分類。
1 圖片資料庫準備
由於圖片資料收集比較費時,為了簡單說明,我用了兩類,dog和bird,每種約300張。train200張,val100張。
新建一個資料夾mine,放自己的資料,在mine資料夾下新建train和val資料夾,train資料夾下新建bird和dog兩個資料夾分別存放200張bird和200張dog,val資料夾裡存放其他的圖片用於驗證。注意,圖片的size要歸一到相同尺寸。(256*256)
2 轉換成leveldb格式
在mine資料夾下新建兩個txt檔案:train.txt和val.txt,列出對應圖片名及其標籤。
資料量較少的可以手動標籤,資料量較大的話,可以寫批處理命令,比較方便。

一定要注意,train列表中的圖片帶相對路徑名bird/*.jpg dog/*.jpg。標籤1代表bird,標籤2代表dog。
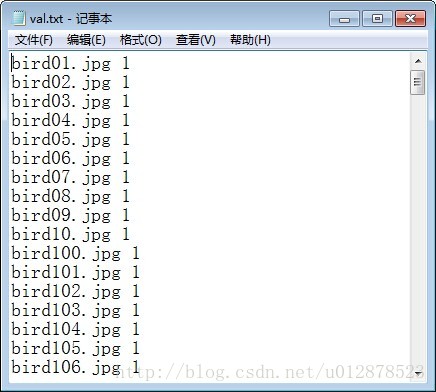
生成列表後,編譯convert_imageset.cpp.
在bin資料夾中將剛剛生成的MainCaller.exe重新命名為convert_imageset.exe。做一個批處理命令將圖片資料轉換成leveldb格式。
在caffe-windows資料夾下新建convertimage2ldb.bat。
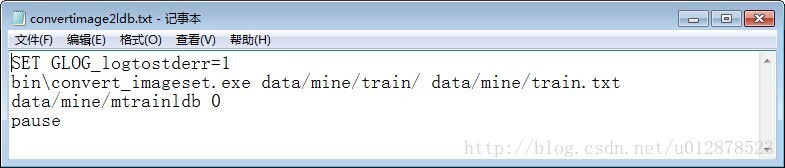
雙擊執行,在mine資料夾下就會出現mtrainldb資料夾。
同理可得到mvalldb。這兩個就是caffe需要的資料。
注意,我的mine資料夾是放在data資料夾下的,在寫convertimage2ldb.bat時注意你自己路徑。
3 計算mean
這個比較簡單,上篇文章也說了。編譯comput_image_mean.cpp
在bin資料夾中將剛剛生成的MainCaller.exe重新命名為comput_image_mean.exe。做一個computeMean.bat方便以後使用。
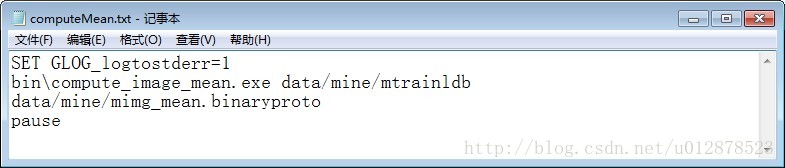
雙擊執行之後在mine裡面出現mimg_mean.binaryproto,這就是caffe需要的圖片均值檔案。
4 訓練自己的網路
資料集和均值檔案都生成之後,訓練和前面兩篇文章類似。這次我直接使用的是imagenet的網路結構,幾乎沒怎麼修改,所以我將imagenet裡面的imagenet_train.prototxt、imagenet_val.prototxt、imagenet_solver.prototxt直接拷過來修改一下。
imagenet_val.prototxt、imagenet_train.prototxt裡面的
source: "mtrainldb"
mean_file:"mimg_mean.binaryproto"
batch_size: 10
還有最後一層的output改為2,因為我只有兩類。
imagenet_solver.prototxt裡面的網路引數修改:
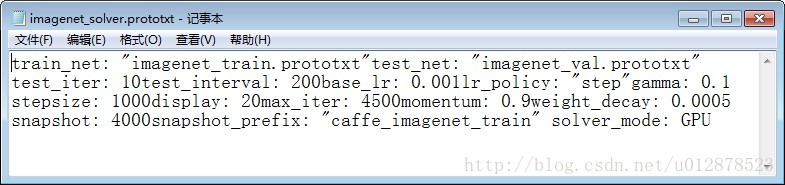
注意最後加上solver_mode:GPU。
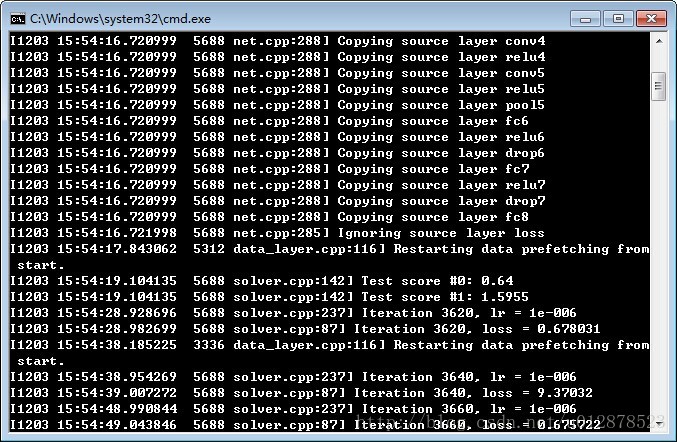
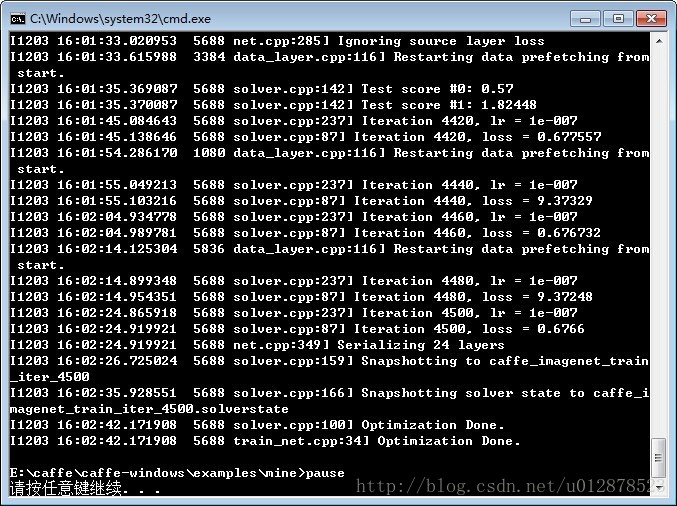
開始訓練:

5 實驗結果
由於資料量較小,訓練比較快。正確率最高能達到0.87。但是最後並不收斂,4500次迭代正確率時高時低。本文只是介紹方法,還有很多引數值得推敲。
相關文章
- 跑在檔案系統上的資料倉儲
- Caffe-SSD-Ubuntu16-04-訓練自己的資料集Ubuntu
- Caffe SSD Ubuntu16 04 訓練自己的資料集Ubuntu
- 跑在檔案系統上的資料倉儲,強!
- Laravel 跑在 swoole 上Laravel
- pfSense——跑在 Vmware 上的防火牆防火牆
- 你在跑馬拉松,人工智慧和大資料也在跑人工智慧大資料
- mmsegmentation中構造自己的資料集和資料載入部分,跑現有demoSegmentation
- 自己在mac上常用的命令Mac
- PHP 程式跑在 Windows 服務上PHPWindows
- 在Mac上搭建自己的伺服器——NginxMac伺服器Nginx
- (13)caffe總結之訓練和測試自己的圖片
- 在MongoDB資料庫中查詢資料(上)MongoDB資料庫
- 在 GitHub 上構建並存放自己的 npm packageGithubNPMPackage
- Caffe原始碼理解2:SyncedMemory CPU和GPU間的資料同步原始碼GPU
- 部門不開放自己的資料,到底在怕什麼?
- .NET Attribute在資料校驗上的應用
- MaxCompute在高德大資料上的應用大資料
- 教你在 C 語言上編寫自己的協程
- 資料探勘技術在軌跡資料上的應用實踐
- 在anlions os上安裝資料庫資料庫
- openGauss資料庫在CentOS上的安裝實踐資料庫CentOS
- IEEE802 11資料幀在Linux上的抓取Linux
- 深度學習 Caffe 初始化流程理解(資料流建立)深度學習
- 深度學習 Caffe 初始化流程理解(資料流建立)深度學習
- 在win10上按住mysql資料庫Win10MySql資料庫
- 在分頁物件資料上追加屬性物件
- 在 Android Studio 上除錯資料庫 ( SQLite )Android除錯資料庫SQLite
- 自己收集的部分Angular學習資料Angular
- 使用labelme標記自己的資料jsonJSON
- 在時間關係資料上AutoML:一個新的前沿TOML
- 想為Mac上的資料夾定義自己喜歡的顏色嗎?看這裡Mac
- mysql在linux上cmake安裝方法(自己安裝版)MySqlLinux
- 在雲上輕鬆部署達夢資料庫資料庫
- 為資料安全護航,袋鼠雲在資料分類分級上的探索實踐
- 【Caffe篇】--Caffe solver層從初始到應用
- 使用Map將資料變成自己想要的
- Mxnet R FCN 訓練自己的資料集
- MXnet轉caffe