Python pyocr和Tesseract-OCR的安裝以及使用
歡迎加入學習交流QQ群:657341423
PyOCR是一個用於python的光學字元識別(OCR)工具包裝器。也就是說,它有助於使用Python程式中的OCR工具。
安裝:pip install pyocr
還需安裝PIL:pip install Pillow
PIL主要用於開啟圖片以及一些處理
此外最重要需要安裝OCR引擎,官網原文:PyOCR可以用作google的Tesseract-OCR或Cuneiform 的包裝器 。它可以讀取Pillow支援的所有影象型別 ,包括jpeg,png,gif,bmp,tiff和其他。它還支援邊界框資料。
下載Tesseract-OCR引擎,注意要3.0以上才支援中文哦,按照提示安裝就行(window下安裝)
Tesseract直接網上搜EXE安裝包直接安裝即可。
注意在 “Language data” 那個選項裡,預設是隻勾選了英文的,如果需要進行其他語言的識別,記得勾選對應的語言。
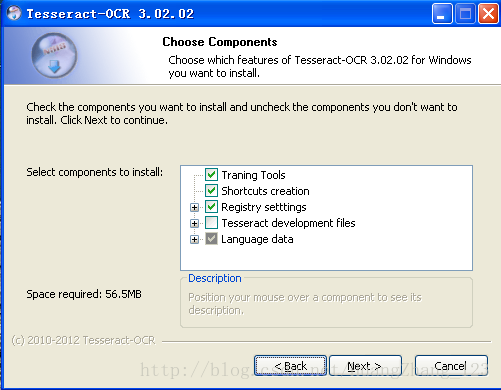
再一個是,如果需要進行相應的開發工作,建立把 “Tesseract development files” 這個選項也勾選。不過這個需要連結谷歌網址下載檔案的。需跳牆。
識別中文,下載chi_sim.traineddata,然後直接放到C:\Program Files (x86)\Tesseract-OCR\tessdata資料夾下。
然後在chi_sim.traineddata(注意版本)檔案目錄下(…/Tesseract-OCR/tessdata),使用命令列執行:
combine_tessdata -e chi_sim.traineddata chi_sim.config
執行完後,在目錄下出現chi_sim.config的檔案,開啟該檔案;
在allow_blob_division F這一行的前面加#,註釋掉
即:# allow_blob_division F
然後,在執行命令列:
combine_tessdata -o chi_sim.traineddata chi_sim.config
Python程式碼:
# coding=utf-8
import sys
import os
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
try:
from pyocr import pyocr
from PIL import Image
except ImportError:
raise SystemExit
#匯入庫
tools = pyocr.get_available_tools()[:]
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
#查詢OCR引擎
print ("Using '%s'" % (tools[0].get_name()))
print (tools[0].image_to_string(Image.open('E:\\bb.png'),lang='chi_sim'))
#lang='chi_sim'為OCR的識別語言庫。C:\Program Files (x86)\Tesseract-OCR\tessdata
由於中文識別效果不太理想,可以通過中文訓練,具體參考:
http://www.cnblogs.com/wzben/p/5930538.html
參考資料:pyocr:https://github.com/jflesch/pyocr
歡迎加入學習交流QQ群:657341423
相關文章
- Python的安裝和使用Python
- mongodb的安裝以及使用MongoDB
- github的安裝以及使用Github
- Genymotion的安裝以及使用
- CentOSmysql安裝以及使用CentOSMySql
- python中的pip的安裝以及通過pip命令對selenium進行解除安裝和安裝Python
- python下redis安裝和使用PythonRedis
- SublimeText3 安裝和配置,以及配置 Python 環境Python
- 二、python安裝和基礎使用Python
- python3安裝和使用virtualenvPython
- webStorm安裝以及整合git使用!WebORMGit
- linuxwget安裝以及使用Linuxwget
- 為什麼學習Python以及Python的安裝Python
- Python的安裝與使用Python
- Python 庫/模組的pip安裝和IPython的使用Python
- git 的安裝使用以及協作流程Git
- RabbitMQ Centos7 安裝以及使用MQCentOS
- Sublime的安裝、新增外掛以及其的使用
- Go的安裝和使用Go
- yarn的安裝和使用Yarn
- CMake的安裝和使用
- azkaban的安裝和使用
- FTP的安裝和使用FTP
- jdk安裝以及JAVA_HOME和CLASSPATH以及Path的含義JDKJava
- python Mqtt 的安裝及使用PythonMQQT
- 安裝pygame和pip的問題以及過程GAM
- MySQL的安裝以及基本的管理命令和設定MySql
- 伺服器安裝docker 以及使用docker安裝mysql及svn伺服器DockerMySql
- 安裝python並使用Python
- kaldi上使用gpu以及如何安裝cudaGPU
- GitLab 的安裝和使用Gitlab
- webpack的安裝和基本使用Web
- geoserver PostGIS的安裝和使用Server
- VMware Workstation 的安裝和使用
- Jetty的安裝、配置和使用Jetty
- oswatch的安裝和使用
- LOGMNR的安裝和使用
- LogMiner的安裝和使用