python用箱型圖進行異常值檢測
異常值檢測:資料探勘工作中的第一步就是異常值檢測,異常值的存在會影響實驗結果。異常值是指樣本中的個別值,也稱為離群點,其數值明顯偏離其餘的觀測值。常用檢測方法3
3
σ \sigma原則對資料分佈有一定限制,而箱型圖並不限制資料分佈,只是直觀表現出資料分佈的本來面貌。其識別異常值的結果比較客觀,而且判斷標準以四分位數和四分位間距為標準,多達25%的資料可以變得任意遠而不會擾動這個標準,魯棒性更強,所以更受大家親睞。箱型圖識別異常值標準: 異常值被定義為大於
QU+1.5IQR Q_U+1.5IQR或小於QL−1.5IQR Q_L-1.5IQR的值。QU Q_U是上四分位數,表示全部觀察值中有1/4的資料比他大,QL Q_L是下四分位數,表示全部資料中有1/4的資料比他小。IQR是四分位間距,是QU Q_U和QL Q_L的差,其間包含了觀察值的一半。

箱型圖檢測異常值實戰:
對10位歌手近6個月的播放量資料集進行異常值檢測. 資料集每一列表示歌手6個月的播放量,共10列.每一行表示每一天的播放量,共183天.
音樂播放量資料.
#-*- coding: utf-8 -*-
import pandas as pd
number = '../data/all_musicers.xlsx' #設定播放資料路徑,該路徑為程式碼所在路徑的上一個目錄data中.
data = pd.read_excel(number)
data1=data.iloc[:,0:10]#10位歌手的183天音樂播放量
#data2=data.iloc[:,10:20]
#data3=data.iloc[:,20:30]
#data4=data.iloc[:,30:40]
#data5=data.iloc[:,40:50]
import matplotlib.pyplot as plt #匯入影象庫
plt.rcParams['font.sans-serif'] = ['SimHei'] #用來正常顯示中文標籤
plt.rcParams['axes.unicode_minus'] = False #用來正常顯示負號
plt.figure(1, figsize=(13, 26))#可設定影象大小
#plt.figure() #建立影象
p = data1.boxplot() #畫箱線圖,直接使用DataFrame的方法.程式碼到這為止,就已經可以顯示帶有異常值的箱型圖了,但為了標註出異常值的數值,還需要以下程式碼進行標註.
#for i in range(0,4):
x = p['fliers'][0].get_xdata() # 'flies'即為異常值的標籤.[0]是用來標註第1位歌手的異常值數值,同理[i]標註第i+1位歌手的異常值.
y = p['fliers'][0].get_ydata()
y.sort() #從小到大排序
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱線圖
若想同時在一張圖上標註所有的歌手異常值的數值, 可以這樣做:
x0 = p[‘fliers’][0].get_xdata() # ‘flies’即為異常值的標籤.
y0= p[‘fliers’][0].get_ydata()
y0.sort() #從小到大排序
for i in range(len(x0)):
if i>0:
plt.annotate(y0[i], xy = (0x[i],y0[i]), xytext=(x0[i]+0.05 -0.8/(y0[i]-y0[i-1]),y0[i]))
else:
plt.annotate(y0[i], xy = (x0[i],y0[i]), xytext=(x0[i]+0.08,y0[i]))
上述程式碼將x0換成xi就表示給第i+1位歌手新增異常值標註. 在所有的歌手異常值都標註完後,執行plt.show() #展示所有異常值標註的箱型圖.
輸出結果如下:其中,+所表示的均是(統計學認為的)異常值.工作中,要結合資料應用背景, 距離箱型圖上下界很近的可歸為正常值.
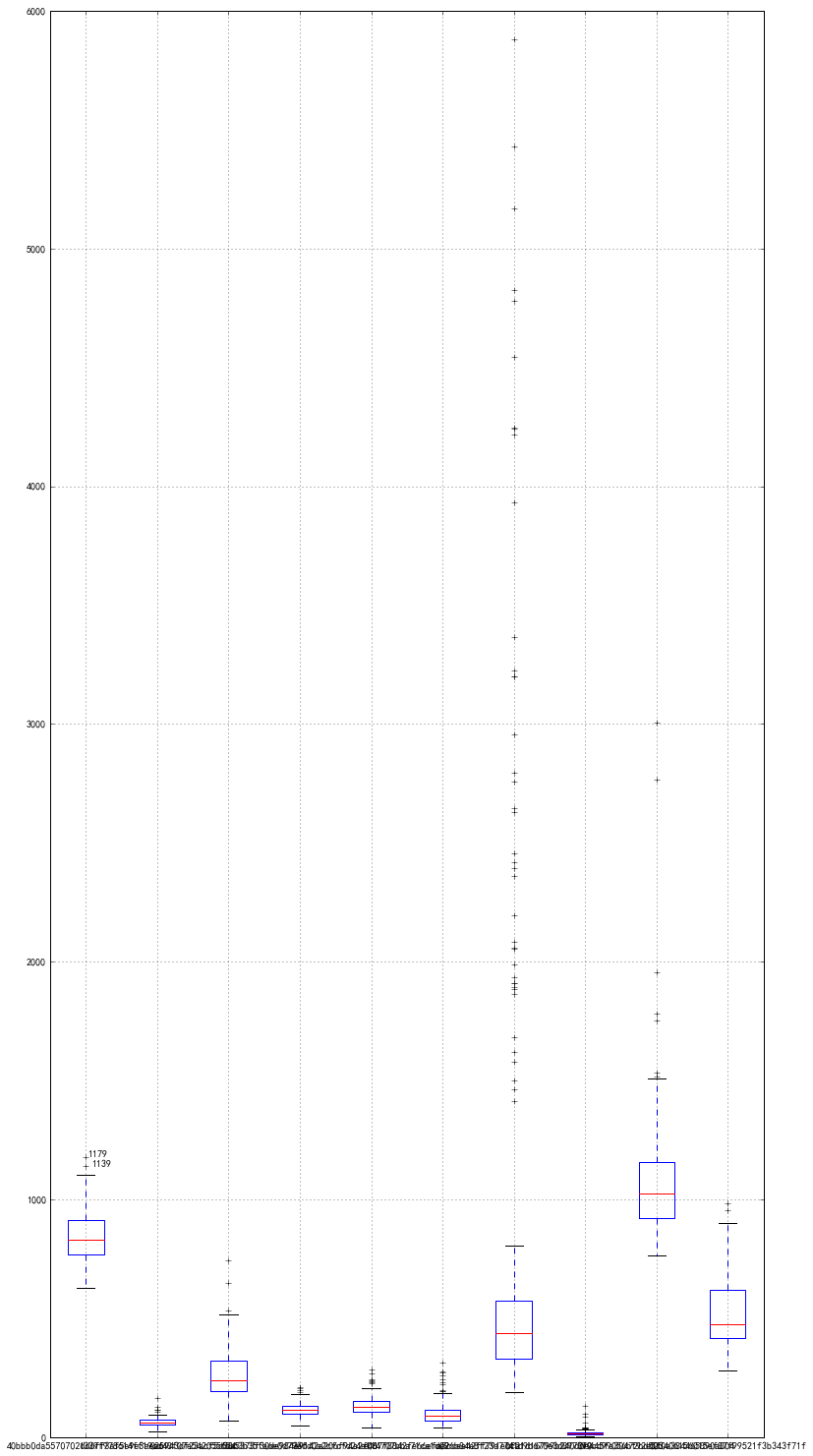
異常值處理:
- 刪除:對於資料量比較小的資料,刪除會造成樣本不足,減少有用資訊。
- 視為缺失值:用均值、插值等方法進行填補
- 不處理:將缺失值視為一種特徵,統計其缺失個數等資訊作為缺失特徵。
本文將異常值視為缺失值,並用前後值的均值來填補.程式碼如下:
for i in range(0,182):
if data1.iloc[:,1][i]>125:
data1.iloc[:,1][i]=(data1.iloc[:,1][i+1]+data1.iloc[:,1][i-1])/2
for i in range(0,182):
if data1.iloc[:,2][i]>600:
data1.iloc[:,2][i]=(data1.iloc[:,2][i+1]+data1.iloc[:,1][i-1])/2
for i in range(0,182):
if data1.iloc[:,4][i]>225:
data1.iloc[:,4][i]=(data1.iloc[:,4][i+1]+data1.iloc[:,4][i-1])/2
for i in range(0,182):
if data1.iloc[:,7][i]>60:
data1.iloc[:,7][i]=(data1.iloc[:,7][i+1]+data1.iloc[:,7][i-1])/2
for i in range(0,182):
if data1.iloc[:,8][i]>2500:
data1.iloc[:,8][i]=(data1.iloc[:,8][i+1]+data1.iloc[:,8][i-1])/2處理完異常值後,匯出資料,儲存:
#datan=pd.concat([data1,data2,data3,data4,data5],axis=1)
data1.to_csv("train_innoraml.csv") 儲存時有時會出現這種問題:
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 0-1: ordinal not in range(128)
解決方法,輸入以下程式碼:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
相關文章
- 個推異常值檢測和實戰應用
- 【Python資料分析基礎】: 異常值檢測和處理Python
- 異常值檢測!最佳統計方法實踐(程式碼實現)!⛵
- python-科研繪圖系列(7)-箱型圖(盒型圖)Python繪圖
- 用QTP進行GMail郵箱的自動化測試QTAI
- 用深度學習進行欺詐檢測深度學習
- javamail 配置多個郵箱進行傳送 異常JavaAI
- 如何從大量資料中找出異常值
- 箱形圖(python畫圖)Python
- 異常檢測
- 2020-12-18python中異常值處理中的程式碼不能執行Python
- php檢測郵箱密碼PHP密碼
- 【matplotlib 實戰】--箱型圖
- Python OpenCV 3 使用背景減除進行目標檢測PythonOpenCV
- Python Pandas 箱線圖Python
- 物體檢測實戰:使用 OpenCV 進行 YOLO 物件檢測OpenCVYOLO物件
- 序列異常檢測
- Springboot整合ElasticSearch進行簡單的測試及用Kibana進行檢視Spring BootElasticsearch
- 檢測郵箱是否是QQ郵箱並給出提示
- 用python進行應用程式自動化測試(uiautomation)PythonUI
- 異常檢測(Anomaly Detection)方法與Python實現Python
- React從入門到精通系列之(13)使用PropTypes進行型別檢測React型別
- 十行Python程式碼搞定圖片中的物體檢測Python
- 對大量ip:port進行批次telnet檢測的python指令碼Python指令碼
- 華為AGC提包檢測報告:檢測異常GC
- python檢測圖片是否存在指令碼Python指令碼
- 使用 YOLO 進行實時目標檢測YOLO
- 影像分析,使用Halcon進行缺陷檢測
- 利用python庫stats進行t檢驗Python
- 在Python中使用OpenCV進行人臉檢測PythonOpenCV
- 如何對Mac進行基礎檢測和速度測試Mac
- js 型別檢測JS型別
- JavaScript型別檢測JavaScript型別
- 【JS】型別檢測JS型別
- python-magic:檢測檔案的MIME型別Python型別
- [python] 基於PyOD庫實現資料異常檢測Python
- OpenCV讀入圖片序列進行HOG行人檢測並儲存為視訊OpenCVHOG
- 利用BLEU進行機器翻譯檢測(Python-NLTK-BLEU評分方法)Python