如何理解過擬合、正則化和交叉驗證
機器學習中大家經常會遇到過擬合問題,過擬合就是模型在訓練集模型表現良好,但是在測試集就不行了。具體表現在訓練集為追求好的效果(經驗損失小,準確率高等),模型建立的過於複雜(下圖3),能夠很好反映已知資料,但泛化能力太差。學術點說就是empirical loss比較小,而Generalized loss比較大。
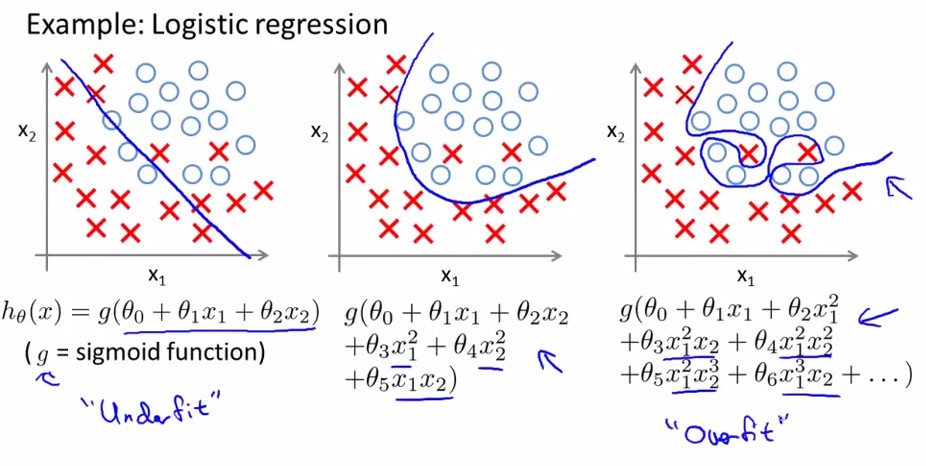
通常資料師在建模型時,基本都在遵循簡化原則,即在擬合效果差不多的情況下,模型越簡單則在測試集表現的越優(奧卡姆剃刀原理),這也就解釋了決策樹要“剪枝”的原因。但對於某些複雜問題,我們的模型相應的也會變得複雜,為解決因此帶來的過擬合問題,我們採用交叉驗證和正則化來解決。
交叉驗證:(Cross Validation)
在驗證模型時,我們會將訓練集分為兩部分,子訓練集和測試集,線下驗證模型優劣。通常採用7:3的劃分方法,但大家都知道不同的劃分策略,模型的準確性驗證會不同。所以為解決因人工劃分帶來的隨機性問題,選擇交叉驗證(CV),即不斷的劃分訓練集(比例上子訓練集大於測試集),反覆測試,從有限的資料中儘可能獲得多的有效資訊,返回模型準確率的均值。通過交叉驗證,如果模型的表現仍然很好,就認為該模型泛化能力也不差。
交叉驗證目的:選出最優引數的模型。模型建立後,調引數是個很費時的過程,通過交叉驗證我們可以得出最優引數的模型。
1.1 準備候選模型,M1,M2,M3,……(模型框架一致,只是引數不同)
1.2 對於每個模型,分別進行交叉驗證,返回該模型的準確率或者錯誤率等資訊(自己選擇是計算accuracy還是error),其返回應該是交叉驗證後得出的均值。
1.3 通過比較不同模型的accuracy或error,選擇最佳模型。交叉驗證分類:留P驗證(Leave-p-out Cross Validation)、k-fold交叉驗證(K-fold Cross Validation)等。
2.1 留p驗證(LpO CV)是指訓練集上隨機選擇p個樣本作為測試集,其餘作為子訓練集。時間複雜度為CpN C_N^p,是階乘的複雜度,不可取。
2.2 k-fold交叉驗證就是將資料集平均分割成k份,依次選擇一份作為測試集,其餘作為子訓練集,最後將得到的k個accuracy取平均。通常K取10,也就是經常聽到的10折交叉驗證。
正則化:
先給出知乎上一乎友的見解:
(https://www.zhihu.com/question/20700829/answer/21156998)
通俗解釋:讓模型引數不要在優化的方向上縱慾過度。
《紅樓夢》裡,賈瑞喜歡王熙鳳得了相思病,病榻中得到一枚風月寶鑑,可以進入和心目中的女神XXOO,它腦子裡的模型目標函式就是“最大化的爽”,所以他就反覆去擬合這個目標,多次XXOO,於是人掛掉了,如果給他加一個正則化,讓它爽,又要控制爽的頻率,那麼他可以爽得更久。
再補充一個角度:
正則化其實就是對模型的引數設定一個先驗,這是貝葉斯學派的觀點,不過我覺得也可以一種理解。
L1正則是laplace先驗,l2是高斯先驗,分別由引數sigma確定。
求不要追究sigma是不是也有先驗,那一路追究下去可以天荒地老。
相關文章
- 原理解析-過擬合與正則化
- 理解「交叉驗證」(Cross Validation)ROS
- Tensorflow-交叉熵&過擬合熵
- JS驗證URL正則JS
- 深度學習2.0-25.Train-Val-Test劃分檢測過擬合(交叉驗證)深度學習AI
- js正則驗證身份證號JS
- 什麼是機器學習迴歸演算法?【線性迴歸、正規方程、梯度下降、正則化、欠擬合和過擬合、嶺迴歸】機器學習演算法梯度
- 「機器學習速成」正則化:降低模型的複雜度以減少過擬合機器學習模型複雜度
- js正則驗證特殊字元JS字元
- JS 正則驗證數字JS
- jQuery正則驗證15/18身份證jQuery
- K重交叉驗證和網格搜尋驗證
- 《神經網路和深度學習》系列文章二十五:過擬合與正則化(2)神經網路深度學習
- Pytorch_第八篇_深度學習 (DeepLearning) 基礎 [4]---欠擬合、過擬合與正則化PyTorch深度學習
- TensorFlow筆記-08-過擬合,正則化,matplotlib 區分紅藍點筆記
- Javascript使用正則驗證身份證號(簡單)JavaScript
- 賬戶、密碼格式···正則驗證密碼
- php正則驗證手機、郵箱PHP
- 梯度下降、過擬合和歸一化梯度
- 今日面試題分享:如何理解模型的過擬合與欠擬合,以及如何解決?面試題模型
- js中使用正則驗證手機號JS
- 網路模型的交叉驗證模型
- Laravel的unique和exists驗證規則的優化Laravel優化
- swift 郵箱、密碼、手機號、身份證驗證正則Swift密碼
- 正則經驗
- 從線性迴歸來理解正則化
- 徹底理解正則
- 交叉驗證(Cross validation)總結ROS
- php開發中經常用到的正則驗證PHP
- 正則實現二代身份證號碼驗證詳解
- 如何解決過度擬合
- 機器學習之簡化正則化:L2 正則化機器學習
- 如何正確理解棧和堆?
- 如何建立和獲取正則物件?物件
- 模型評估與改進:交叉驗證模型
- 交叉驗證(Cross Validation)原理小結ROS
- 神經網路最佳化篇:為什麼正則化有利於預防過擬合呢?(Why regularization reduces overfitting?)神經網路
- 機器學習之稀疏性正則化:L1 正則化機器學習