語音識別的特徵提取中的相關引數
1.聲強和聲強級
在物理學中,把單位時間內通過垂直於聲波傳播方向的單位面積的平均聲能,稱為聲強。聲強用I表示,單位為瓦/平米。實驗的研究表明,人對聲音強弱的感覺並不是與聲強成正比,而是與其對數成正比的。所以一般聲強用聲強級來表示。
SIL=10lg[I/I’]=10lg(I/I’)
式中I為聲強,I’=10e-12瓦/平米稱為基準聲強,聲強級的常用單位是分貝(dB)。
2.響度
響度時一種主觀心理量,是人類主觀感覺到的聲音強弱程度。一般來說,聲音訊率一定時,聲強越強,響度也越大。但是響度與頻率有關,相同的聲強,頻率不同時,響度也可能不同。響度若用對數值表示,即為響度級,響度級的單位定義為方,符號為phon。根據國際協議規定,0dB聲級的1000Hz純音的響度級定義為0 phon,n dB聲級的1000Hz純音的響度級就是n phon。其它頻率的聲級與響度級的對應關係要從等響度曲線查出。
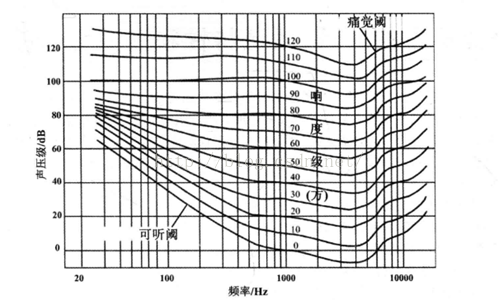
等響度曲線與聲強級的關係
3.音高
音高也是一種主觀心理量,是人類聽覺系統對於聲音訊率高低的感覺。音高的單位是美爾(Mel)。響度級為40 phon,頻率為1000Hz的聲音的音高定義為1000Mel。
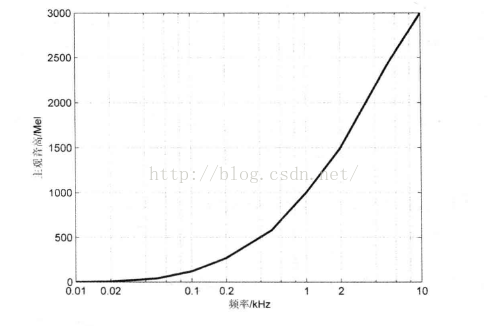
主觀音高與實際頻率的關係
4基音週期和基音訊率
4.1 基音週期的概念
人在發音時,聲帶振動產生濁音(清音由空氣摩擦產生)。濁音的發音過程是:來自肺部的氣流衝擊聲門,造成聲門的一張一合,形成一系列準週期的氣流脈衝,經過聲道(含口腔、鼻腔)的諧振及脣齒輻射最終形成語音訊號。故濁音波形呈現一定的準週期性。所謂基音週期,就是對這種準週期而言的。它反映了聲門相鄰兩次開閉之間的時間間隔或開閉的頻率。
基音週期是語音訊號最重要的引數之一,它描述了語音激勵源的一個重要特徵。基音週期資訊在語音識別、說話人識別、語音分析與語音合成,以及低位元速率語音編碼、發音系統疾病診斷、聽覺殘障者的語言指導等多個領域有著廣泛的應用。(因為女性基頻比男性高,所以有些演算法中使用基頻來區分性別,還挺準的)
4.2基音週期的估算方法
基音週期的估算方法很多,比較常用的有自相關法,倒譜法(我們提基頻用的倒譜法),平均幅度差函式法,線性預測法,小波—自相關函式法,譜減—自相關函式法等。下面簡單介紹用自相關法提取基頻。
預處理:
為了提高基音檢測的可靠性,有人提出了端點檢測和帶通數字濾波器兩種預處理方法對原始訊號進行預處理。在提取基頻時端點檢測比一般端點檢測更為嚴格(一般端點檢測會保留語音有話段的頭和尾,以避免把有用資訊當作噪聲濾除,但頭和尾不包括基頻資訊,所以在進行提取基音的端點檢測時閾值設定更為嚴格,濾去頭部和尾部)。用帶通濾波器預處理的目的是為了防止共振峰第一峰值的干擾,一般帶通濾波器的頻率範圍選為60~500Hz。
下圖給出青年男女的基頻範圍圖:

自相關法:
短時自相關函式的定義為 其中k是時間的延遲量,N為幀長,短時自相關函式具有以下重要性質。若當原訊號具有周期性,那麼它的自相關函式也具有周期性,並且週期性與原訊號的週期相同。且在K等於週期整數倍時會出現峰值。清音訊號無週期性,它的自相關函式會隨著K的增大呈衰減趨勢,濁音具有周期性,它的R(k)在基因週期整數倍上具有峰值,通常取第一最大峰值點作為基因週期點。自相關函式法基音檢測正是利用這一性質來進行基因週期檢查的。
5訊雜比
定義:
訊雜比的計量單位是dB,其計算方法是10lg(PS/PN),其中PS和PN分別代表訊號和噪聲的功率(用能量也是一樣的)。
計算方法:
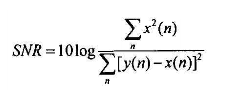
在噪聲和語音完全混雜的情況下訊雜比很難計算,在預知噪聲的情況下,可以用實際訊號(純語音+噪聲)減去噪聲,得到近似的純語音訊號。從而通過進一步計算求得訊雜比。
我們在實驗中所採集的訊號訊雜比低時在10幾dB,訊雜比高時在30dB以上。
以下4個特徵為醫學中常用的檢查嗓部病變的特徵。
6諧噪比:
HNR(Harmonics-to-Noise ratio)是語音中諧波成分和噪聲成分的比率。是檢測病態嗓音和評價嗓音素質的一個客觀指標,能有效地反應聲門閉合情況。需要注意的是這裡的噪聲不是環境噪聲,而是發聲時由於聲門非完全關閉引起的聲門噪聲。
7頻率微擾(jitter)
頻率微擾是描述相鄰週期之間聲波基本頻率變化的物理量。主要反映粗糙聲程度,其次反映嘶啞聲程度。
語音訊號中的頻率微擾與聲門區的功能狀態是一致的。正常嗓音週期間的頻率相同者較多,不同者甚少,因此頻率微擾值很小。當發生聲帶病變時,微擾值增大,使聲音粗糙。
8振幅微擾(shimmer)
振幅微擾描述相鄰週期之間聲波幅度的變化,主要反映嘶啞聲程度。Jitter和shimmer共同反映聲帶振動的穩定性,其值越小說明在發聲過程中聲學訊號出現的微小變化越少。
9規範化噪聲能量(NNE)
主要計算髮聲時由於聲門非完全關閉引起的聲門噪聲的能量。主要反映氣息聲程度,其次是嘶啞聲程度,一定程度上反映聲門的關閉程度,對由於聲帶器質性或功能性病變而產生的病理嗓音的分析很有價值。
10梅爾倒譜系數(Mel-scale Frequency CepstralCoefficients, MFCC)
10.1基本概念:
在語音識別(Speech Recognition)和話者識別(Speaker Recognition)方面,最常用到的語音特徵就是梅爾倒譜系數。梅爾倒譜系數是在Mel標度頻率域提取出來的倒譜引數,Mel標度描述了人耳頻率的非線性特性,它與頻率的關係可用下式近似表示:
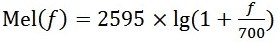
式中f為頻率,單位為Hz。
下圖給出Mel頻率與線性頻率的關係。
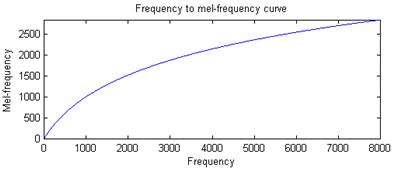
Mel頻率和線性頻率的關係
10.2計算方法:
基本步驟:
計算倒譜的流程圖
1.預加重
預加重處理其實是將語音訊號通過一個高通濾波器:
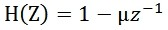
式中μ的值介於0.9-1.0之間,我們通常取0.96。預加重的目的是提升高頻部分,使訊號的頻譜變得平坦,移除頻譜傾斜,來補償語音訊號受到發音系統所抑制的高頻部分。同時,也是為了消除發生過程中聲帶和嘴脣的效應。(因為口脣輻射可以等效為一個一階零點模型)
2.分幀、加窗,快速傅立葉變換
因為語音訊號為短時平穩訊號,所以需要進行分幀處理,以便把每一幀當成平穩訊號處理。同時為了減少幀與幀之間的變化,相鄰幀之間取重疊。一般幀長取25ms,幀移取幀長的一半。
3.Mel濾波器組
在語音的頻譜範圍內設定若干帶通濾波器 ,M為濾波器的個數。每個濾波器具有三角形濾波器的特性,其中心頻率為 ,在Mel頻譜範圍內,這些濾波器是等頻寬的。每個帶通濾波器的傳遞函式為:
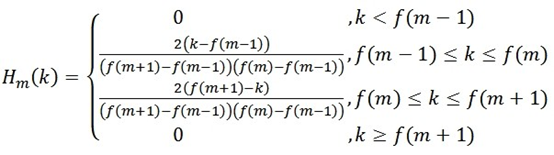
其中:
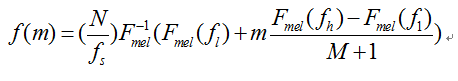
三角帶通濾波器有兩個主要目的:
對頻譜進行平滑化,並消除諧波的作用。此外還可以減少運算量。
在MATLAB的voicebox工具箱中有melbankm函式可用於計算Mel濾波器組。
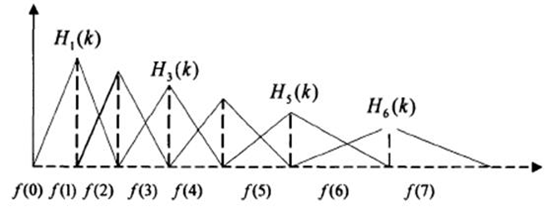
三角形濾波器的示意圖
4.計算每個濾波器組輸出的對數能量為:
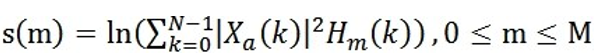
5.經離散餘弦變換(DCT)得到MFCC係數:
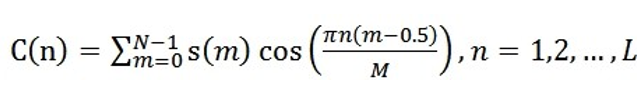
將上述的對數能量帶入離散餘弦變換,求出L階的Mel-scale Cepstrum引數。L階指MFCC係數階數,通常取12-16。這裡M是三角濾波器個數。
以下兩個特徵為能量特徵:
11短時能量
計算第i幀語音訊號 的短時能量的公式為
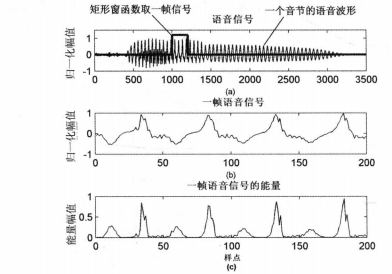
計算一幀語音訊號的短時能量
短時能量的計算方法比較簡單,即取一幀訊號,通過短時能量計算公式計算即可。
12短時平均幅度
語音訊號的短時平均幅度定義為:
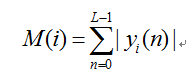
短時平均幅度也是一幀語音訊號能量大小的表徵,它與短時能量的區別在於計算時不論取樣值的大小,不會因為取二次方而造成較大的差異,在某些應用領域中會帶來一些好處。
短時能量和短時平均幅度的有作用主要是:作為區分清濁音,區分聲母韻母,區分有話段和無話段的指標。
13短時平均過零率
短時平均過零率表示一幀語音中語音訊號波形穿過橫軸(零電平)的次數。
其計算公式為:
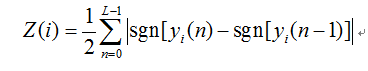
由於濁音具有較低的過零率而清音具有較高的過零率,過零率可以用來區分清音和濁音,在端點檢查中有一定的運用。
3.14共振峰
基本概念:
共振峰是指在聲音的頻譜中能量相對集中的一些區域,共振峰不但是音質的決定因素,而且反映了聲道(共振腔)的物理特徵。聲音在經過共振腔時,受到腔體的濾波作用,使得頻域中不同頻率的能量重新分配,一部分因為共振腔的共振作用得到強化,另一部分則受到衰減。由於能量分佈不均勻,強的部分猶如山峰一般,故而稱之為共振峰。在語音聲學中,共振峰決定著母音的音質。
共振峰是表徵語音訊號特徵的基本引數之一。它在語音訊號合成、語音識別和語音編碼等方面起著重要作用。共振峰可以等效為聲道系統函式的復極點對,由於人的聲道平均長度為17cm,而語音訊號的能量主要集中在0-5kHz。因此語音通常包含4到5個穩定的共振峰,一般只需要研究前三個共振峰。
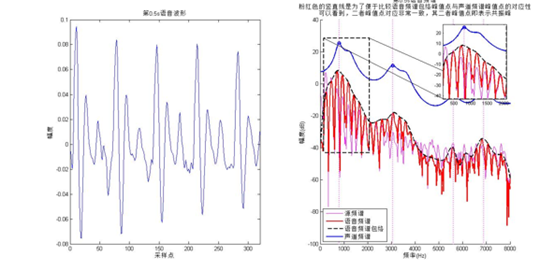
共振峰的一個示意圖
從圖中可以看到:1語音訊號的能量在頻率上存在頻譜傾斜;2共振峰位置與譜包絡位置很一致(這也是譜包絡法提取共振峰的原理)
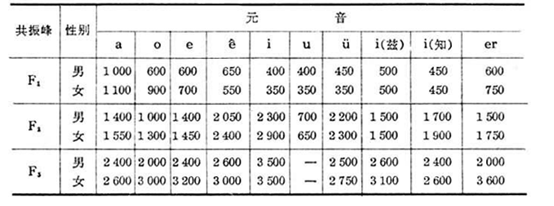
普通話10個母音共振峰均值資料表(Hz)
提取方法:
共振峰的提取方法較多,比較常見的有譜包絡法、倒譜法、LPC內插法、LPC求根法、希爾伯特變換法等,但以上方法都或多或少受,虛假峰值,共振峰合併,高音調語音(尤其是女性)的影響,針對單個母音以上方法可以較好的找到共振峰,但對於連續語音準確度較差。在噪聲背景下不具有很好的魯棒性。下面簡單介紹一種針對連續變化語音的魯棒性較好的共振峰追蹤演算法。
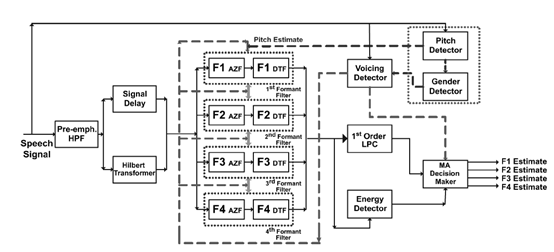
演算法示意圖
傳統的共振峰提取方法都是基於譜分析和峰值檢測技術。這些方法對於噪聲背景下共振峰的檢測,既不準確又不魯棒。圖示這種基於預濾波的方法,在進行譜峰檢測之前對每一個共振峰使用一個時變的自適應濾波器進行預濾波。預濾波限制了每個共振峰的頻譜範圍,因此減小了相鄰峰值之間的干擾和背景噪聲的干擾。
首先進行預加重,原因和MFCC中提到的相同,都是為了移除頻譜傾斜。
第二步是進行希爾伯特變換,得到原實值訊號的解析訊號,便於分析計算。
第三部分是四個自適應共振峰濾波器。每個濾波器由一個全零點濾波器和一個單極點的動態追蹤濾波器組成。這個濾波器的作用是在對每一個共振峰值進行估算之前,對其進行動態濾波,抑制相鄰共振峰的干擾和基頻干擾。
第四部分包括清濁音檢測,性別檢測(根據基頻),能量檢測。性別檢測的目的是針對男女共振峰的差異性給定不同的濾波初值。能量檢測是為了濾除無話段,類似於端點檢查,清濁音檢測是為了濾除清音,因為清音不含共振峰。
最後通過移動平均值作決策,符合條件的值作為共振峰估計值保留,不符合條件的值用其移動平均值代替。
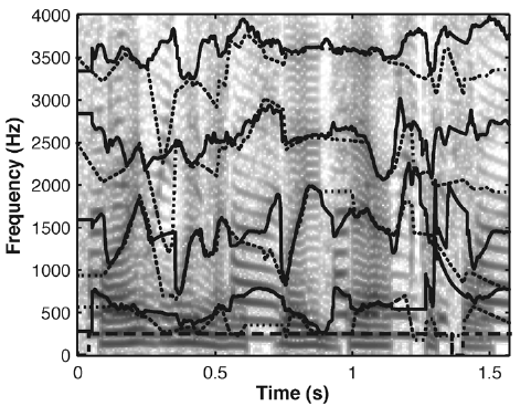
上圖是文章給出的共振峰估計和實際共振峰的圖形。該方法比之前我們採用的倒譜法和LPC法的準確度都要高,但其計算複雜度較高,算起來太慢了。
共振峰參考文獻:Robust Formant Tracking for Continuous
SpeechWith Speaker Variability
15 聲門波
按語言產生的線性模型, 語言訊號的頻譜為:
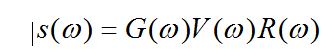
其中 是聲門波的頻譜, 是聲道脈衝響應的頻譜, 是口脣輻射效應的頻譜。在語音訊號的分析工作中,語音分析的一個主要任務是從訊號中獲得聲道響應的頻譜。口脣輻射的影響比較小, 容易作理論估計, 而聲門波的頻譜的關係比較複雜, 影響也較大。(以上是說為了得到準確的聲道響應需要估計聲門響應,這也是一些文獻研究聲門波的目的)。文獻指出,聲門波蘊含一定情感資訊,對壓力分類有一定作用。
下圖給出一個聲門波的模型:
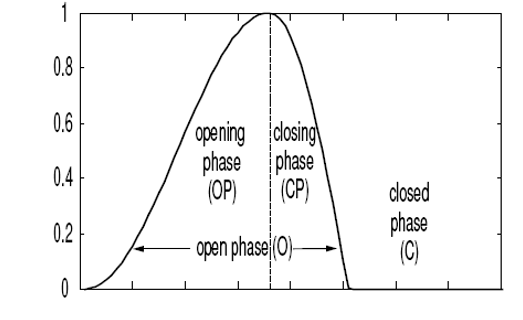
(可以看到這個和我之前給出的激勵模型相似)
聲門波的計算方法:
由式一可知,聲門 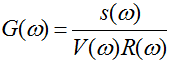
由於口脣輻射容易估計,所以計算聲門波的難點在於把聲門響應和聲道響應區分開。在closed phase,即圖中C區時,聲門和聲道之間的影響是最小的。這時候分析聲道引數時最合適的。這就需要從動態的聲訊號中找到聲門閉合的瞬間(也就是closed phase),很多研究者通過動態演算法,聲門輸入能量,共振峰穩定性,殘餘能量來尋找聲門的閉合瞬間。然而受到講話方式(比如壓力狀況下聲門閉合時間會變短等)和性別的影響(女性講話基頻比男性更高,聲門動作更快,聲門並不總是完成閉合),上述方法都很難準確找到聲門的閉合相。實際醫學中一般用EGG(舌動電流描記器)等其它外部感測器來觀察close phase,從而得到準確的聲門估計。
下面給出moore提出的一種聲門波演算法。
該演算法中把口脣輻射可以等效為一個一階零點模型。聲道響應用全極點模型來等效。根據式二,聲門的估計可以又聲門反濾波得到。
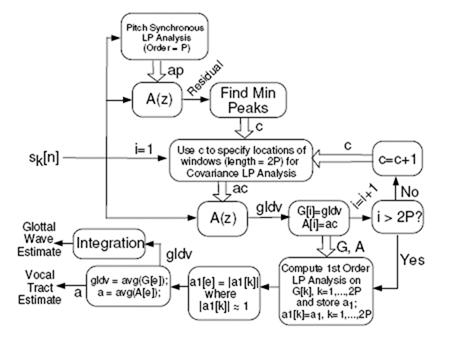
Moore提出的演算法圖示
1: 為輸入,表示一幀訊號,其長度為4-5個基音週期。
2:對原始訊號進行P階基音同步的線性預測分析,得到一組c初始的LPC引數(ap),用來產生殘差訊號,A(z)
3:找到殘差訊號的負峰值。它的負峰值的位置對應這聲門波出現最大負斜率的位置。closed phase一般在這個位置附近。峰值位置被作為迭代的中點,而迭代的起點用峰值位置減去LPC階數P得到。從c起取2P長度,做基於協方差的LPC,得到A(z)
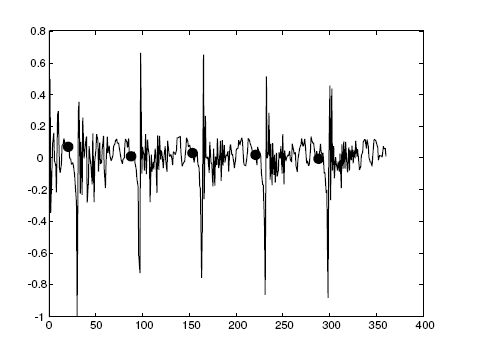
步驟3的一個示意圖
4: 將glottal derivative(gldv)和線性預測分析的引數儲存在矩陣中。進行迭代,迭代次數為2P。
5:後處理過程。
聲門參考文獻:ALGORITHM FOR AUTOMATIC GLOTTALWAVEFORM ESTIMATIONWITHOUT THE RELIANCE ON PRECISE GLOTTAL CLOSURE INFORMATION
16 其它特徵:
像語速,停頓等可以顧名思義,但我尚不瞭解計算方法的特徵文中沒有寫出。
相關文章
- 語音的關鍵聲學特徵(語音情感特徵提取)特徵
- JavaScript的語音識別JavaScript
- 怎麼關閉win10語音識別 win10如何關閉電腦的語音識別Win10
- 【機器學習PAI實踐十二】機器學習實現男女聲音識別分類(含語音特徵提取資料和程式碼)機器學習AI特徵
- Kaldi搭建語音識別系統—發音詞典相關檔案準備
- 網頁js版音訊數字訊號處理:H5錄音+特定頻率訊號的特徵分析和識別提取網頁JS音訊H5特徵
- librosa 音訊特徵提取的現成文件ROS音訊特徵
- Java用JSoup元件提取asp.net webform開發網頁的viewstate相關相關引數JavaJS元件ASP.NETWebORM網頁View
- 聊聊Oracle Optimizer相關的幾個引數(中)Oracle
- Spark的相關引數配置Spark
- 音訊相關知識音訊
- 語音識別----音高的處理
- 語音識別方向的資料
- MySQL中Redo Log相關的重要引數總結MySql
- MySQL中的統計資訊相關引數介紹MySql
- 開發智慧語音機器人所需要的Freesiwtch VAD識別模組引數機器人
- Android小知識-剖析Retrofit中的網路請求流程以及相關引數Android
- 論文筆記:語音情感識別(五)語音特徵集之eGeMAPS,ComParE,09IS,BoAW筆記特徵
- iframe相關的引數傳遞【Z】
- oracle相關的linux核心引數OracleLinux
- 語音特徵引數MFCC計算的詳細過程特徵
- 怎麼在aix中識別FAStT相關的裝置AIAST
- 語音識別技術
- 有關音訊編碼的知識與技術引數(轉載)音訊
- MySQL效能相關引數MySql
- 歸檔相關引數
- PostgreSQL AutoVacuum 相關引數SQL
- Linux的語音識別軟體(轉)Linux
- Android小知識-剖析Retrofit中ServiceMethod相關引數以及建立過程Android
- 一、Windows10平臺下Unity3d的語音識別——關鍵字識別WindowsUnity3D
- linux的vm相關引數介紹Linux
- 密碼相關的引數或事項密碼
- oracle sga配置相關的os 核心引數Oracle
- Oracle Lob型別相關引數以及效能影響Oracle型別
- Win10系統如何關閉語音識別Win10
- pg中與執行計劃相關的配置(ENABLE_*)引數
- 特徵提取之Haar特徵特徵
- MySQL 連線相關引數MySql