MemCached Cache Java Client封裝優化歷程
Email: wenchu.cenwc@alibaba-inc.com
Blog: http://blog.csdn.net/cenwenchu79/
MemCached Cache在大型網站被應用得越來越廣泛,不同語言的客戶端也都在官方網站上有提供,但是Java的選擇並不多。由於現在的MemCached Cache服務端是用C寫的,因此我這個C不太熟悉的人也就沒有辦法去優化它,當然對於它的記憶體分配機制等細節還是有所瞭解,因此在使用的時候也會十分注意,這些文章Google一把應該也有很多了。這裡就說說對於MemCache Java客戶端的優化的兩個階段。
First Stage
我也和其他使用Memcached Cache的同學一樣,看了官方網站的內容,然後去下載了whalin memcached Client,後來Stat的時候遇到問題,就給作者發了郵件說明了情況,作者讓我下載 2.0.1 版本,這個版本也是比較不錯的一個版本,後續的封裝也是基於這個版本之上。
第一階段主要是在whalin的客戶端作了再次封裝。
1. Cache服務介面化。
定義了IMemCache介面,在應用部分僅僅只是使用介面,為將來替換Cache服務實現提供基礎。
2. 使用配置代替程式碼初始化客戶端。
通過配置客戶端和SocketIO Pool屬性,直接交管由CacheManager來維護Cache Client Pool的生命週期,方便實用以及單元測試。
3. KeySet的實現。
對於MemCached來說本身是不提供KeySet的方法的,在介面封裝初期,同事向我提出這個需求的時候,我個人覺得也是沒有必要提供,因為Cache輪詢是比較低效的,同時這類場景,往往可以去資料來源獲取KeySet,而不是從MemCached去獲取。但是SIP的一個場景的出現,讓我不得不去實現了KeySet。
SIP在作服務訪問頻率控制的時候需要記錄在控制間隔期內的訪問次數和流量,此時由於是叢集,因此資料必須放在集中式的儲存或者快取中,資料庫肯定是撐不住這樣大資料量的更新頻率的,因此考慮使用Memcached的很出彩的操作,全域性計數器(storeCounter,getCounter,inc,dec),但是在檢查計數器的時候如何去獲取當前所有的計數器,曾考慮使用DB或者檔案,但是效率還是問題,同時如果放在一個欄位中併發還是有問題。因此不得不實現了KeySet,在使用KeySet的時候有一個引數,型別是Boolean,這個欄位的存在是因為,在Memcached中資料的刪除並不是直接刪除,而是標註一下,這樣會導致實現keySet的時候取出可能已經刪除的資料,如果對於資料嚴謹性要求低,速度要求高,那麼不需要再去驗證key是否真的有效,如果要求key必須正確存在,就需要再多一次的輪詢查詢。
4. Cluster的實現。
Memcached作為集中式Cache,就存在著集中式的致命問題:單點問題,Memcached支援多Instance分佈在多臺機器上,僅僅只是解決了資料全部丟失的問題,但是當其中一臺機器出錯以後,還是會導致部分資料的丟失,一個籃子掉在地上還是會把部分的雞蛋打破。
因此就需要實現一個備份機制,能夠保證Memcached在部分失效以後,資料還能夠依然使用,當然大家很多時候都用Cache不命中就去資料來源獲取的策略,但是在SIP的場景中,如果部分資訊找不到就去資料庫查詢,那麼要把SIP弄垮真的是很容易,因此SIP對於Memcached中的資料認為是可信的,因此做Cluster也是必要的。
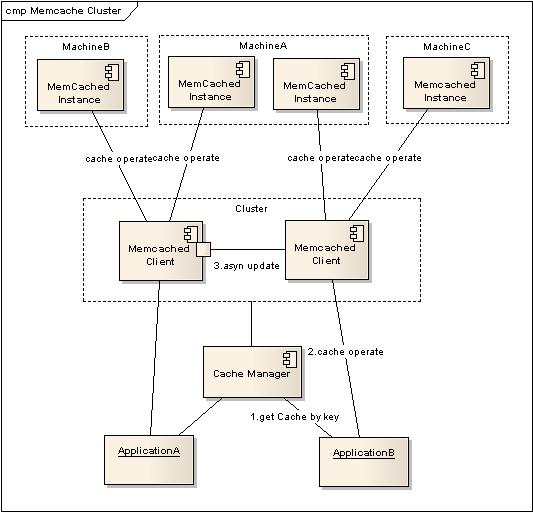
(1) 應用傳入需要操作的key,通過CacheManager獲取配置在Cluster中的客戶端。
(2) 當獲得Cache Client以後,執行Cache操作。
(3) A.如果是讀取操作,當不能命中時去叢集其他Cache客戶端獲取資料,如果獲取到資料,嘗試寫入到本次獲得的Cache客戶端,並返回結果。(達到資料恢復的作用)
B.如果是更新操作,在本次獲取得Cache客戶端執行更新操作以後,立即返回,將更新叢集其他機器命令提交給客戶端的非同步更新執行緒對列去非同步執行。(由於如果是根據key來獲取Cache,那麼非同步執行不會影響到此主鍵的查詢操作)
存在的問題:如果是設定了Timeout的資料,那麼在丟失以後被複制的過程中就會變成永久有效的內容。
5. LocalCache結合Memcached使用,提高資料獲取效率。
在第一次壓力測試過程中,發現和原先預料的一樣,Memcached並不是完全無損失的,Memcached是通過Socket資料互動來進行通訊的,因此機器的頻寬,網路IO,Socket連線數都是制約Memcached發揮其作用的障礙。Memcache的一個突出優點就是Timeout的設定,也就是放入進去的資料可以設定有效期,自動會失效,這樣對於一些不敏感的資料就可以在一定的容忍時間內不去更新,提高效率。根據這個思想,其實在叢集中的每一個Memcached客戶端也可以使用本地的Cache,來快取獲取過的資料,設定一定的失效時間,來減少對於Memcached的訪問次數,提高整體效能。
因此,在每一個客戶端中內建了一個有超時機制的本地快取(採用lazy timeout機制),在獲取資料的時候,首先在本地查詢資料是否存在,如果不存在則再向Memcache發起請求,獲得資料以後,將其快取在本地,並設定有效時間。方法定義如下:
/**
* 降低memcache的互動頻繁造成的效能損失,因此採用本地cache結合memcache的方式
* @param key
* @param 本地快取失效時間單位秒
* @return
*/
public Object get(String key,int localTTL);
Second Stage
第一階段的封裝基本上已經可以滿足現有的需求,也被自己的專案和其他產品線使用,但是不經意的一句話,讓我開始了第二階段的優化。單位裡面有個同學說Memcache客戶端裡面在SocketIO程式碼裡面有太多的synchronized,多多少少會影響效能。雖然過去看過這部分程式碼,但是當時只是關注裡面的Hash演算法,那天回去後一看,果然有不少的synchronized,可能是與客戶端當時寫的時候Jdk版本較早的緣故造成的,現在Concurrent包被廣泛應用,因此優化並不是一件很難的事情。但是由於原有whalin沒有提供擴充套件的介面,因此不得不將whalin除了SockIO部分全部納入到封裝過的客戶端中,然後改造SockIO部分。
因此也有了這個放在Google上的
open source: http://code.google.com/p/memcache-client-forjava/
一. 優化synchronized部分。在原有程式碼中SockIO的資源池分成三個池(普通Map實現),Free,Busy,Dead,然後根據SockIO使用情況來維護這三個資源池。
優化方式,首先簡化資源池,只有一個資源池,設定一個狀態池,在變更資源狀態的過程時僅僅變更資源池中的內容。再次,用ConcurrentMap來替代Map,同時使用putIfAbsent方法來簡化Synchronized,具體的程式碼可以看open source的程式碼部分。
二. 原以為這優化後,效率應該會有很大的提高,但是在初次壓力測試後發現,並沒有明顯的提高,看來有其他地方的耗時遠遠大於連線池資源維護,因此用JProfiler作了效能分析,發現了最大的一個瓶頸:read資料部分,原有設計中讀取資料是按照單位元組讀取,然後逐步分析,為的僅僅就是遇到協議中的分割符可以識別,但是迴圈read單位元組和批量分頁read效能相差很大,因此內建了讀入快取頁(可設定大小),然後再按照協議的需求去讀取和分析資料,效率得到了很大的提高。具體的看最後部分的壓力測試結果。
上面兩部分的工作不論是否提升了效能,但是對於客戶端本身來說都是有意義的,當然提升效能給應用帶來的吸引力更大。這部分細節內容可以參看程式碼實現部分,對於呼叫者來說完全沒有任何功能影響,僅僅只是效能。
壓力測試
在這個壓力測試之前,其實已經做過很多次壓力測試了,測試中的資料本身並沒有衡量Memcached的意義,因為測試是使用我自己的機器,效能,頻寬,記憶體,網路IO都不是伺服器級別的,這裡僅僅是將使用原有的第三方客戶端和改造後的客戶端作一個比較。場景就是模擬多使用者多執行緒在同一時間發起Cache操作,然後記錄下操作的結果。
Client版本在測試中有兩個:2.0和2.2。2.0是封裝呼叫whalin memcached Client 2.0.1版本的客戶端實現。2.2是使用了新SockIO的無第三方依賴的客戶端實現。
checkAlive指的是在使用連線資源以前是否需要驗證連線資源有效(傳送一次請求並接受響應),因此開啟對於效能來說會有不少的影響,不過建議還是使用這個檢查。
One Cache Server instance各種配置和操作下比較:
|
Cache配置 |
User |
操作 |
Client版本 |
總耗時(ms) |
單執行緒耗時(ms) |
提高處理能力百分比 |
|
checkAlive |
100 |
1000 put simple obj 1000 get simple obj |
2.0 |
13242565 |
132425 |
+41.3% |
|
2.2 |
7772767 |
77727 |
||||
|
No checkAlive |
100 |
1000 put simple obj 1000 get simple obj |
2.0 |
7200285 |
72002 |
+35.2% |
|
2.2 |
4667239 |
46672 |
||||
|
checkAlive |
100 |
1000 put simple obj 2000 get simple obj |
2.0 |
20385457 |
203854 |
+43.6% |
|
2.2 |
11494383 |
114943 |
||||
|
No checkAlive |
100 |
1000 put simple obj 2000 get simple obj |
2.0 |
11259185 |
112591 |
+35.6% |
|
2.2 |
7256594 |
72565 |
||||
|
checkAlive |
100 |
1000 put complex obj 1000 get complex obj |
2.0 |
15004906 |
150049 |
+36.7% |
|
2.2 |
9501571 |
95015 |
||||
|
No checkAlive |
100 |
1000 put complex obj 1000 get complex obj |
2.0 |
9022578 |
90225 |
+24.9% |
|
2.2 |
6775981 |
67759 |
從上面的壓力測試可以看出這麼幾點,首先優化SockIO提升了不少效能,其次SockIO優化的是get的效能,對於put沒有太大的作用。原本以為獲取資料越大效能效果提升越明顯,但結果並不是這樣,這部分在這幾天在看看是否還有更加耗時的部分存在。
One Cache instance 和Two Cache instance的測試比較:
|
Cache配置 |
User |
操作 |
Client 版本 |
總耗時(ms) |
單執行緒耗時(ms) |
提高處理能力百分比 |
|
One Cache instance checkAlive |
100 |
1000 put simple obj 1000 get simple obj |
2.0 |
13242565 |
132425 |
+41.3% |
|
2.2 |
7772767 |
77727 |
||||
|
Two Cache instance checkAlive |
100 |
1000 put simple obj 1000 get simple obj |
2.0 |
13596841 |
135968 |
+43.4% |
|
2.2 |
7696684 |
76966 |
單個客戶端對應多個服務端例項效能提升略高於單客戶端對應單服務端例項。
Cache Cluster的測試比較:
|
Cache配置 |
User |
操作 |
Client 版本 |
總耗時(ms) |
單執行緒耗時(ms) |
提高處理能力百分比 |
|
No Cluster checkAlive |
100 |
1000 put simple obj 1000 get simple obj |
2.0 |
13242565 |
132425 |
+41.3% |
|
2.2 |
7772767 |
77727 |
||||
|
Cluster checkAlive |
100 |
1000 put simple obj 1000 get simple obj |
2.0 |
25044268 |
250442 |
+66.5% |
|
2.2 |
8404606 |
84046 |
這部分和SocketIO優化無關。2.0採用的是向叢集中所有Client更新成功以後才返回的策略,2.2採用了非同步更新,並且是分散式Client Node獲取的方式來分散壓力,因此提升效率很多。
開源:
其實封裝後的客戶端一直在內部使用,現在作了二次優化以後,覺得應該Open出來,一來可以完善自己的客戶端程式碼,二來也可以和更多的同學交流使用心得。
在Google Code上傳了這應用的程式碼,範例,說明,有興趣的同學可以下載下來測試一下,比較一下現在用的Java Memcached客戶端的使用方便程度以及效能。
open source: http://code.google.com/p/memcache-client-forjava/
相關文章
- Flutter視訊播放封裝歷程Flutter封裝
- RecyclerView使用封裝與優化View封裝優化
- Memcached Client 使用手冊client
- Java 歷程Java
- 通過Cache::Memcached::Fast方式AST
- java封裝Java封裝
- java 封裝Java封裝
- Java 學習歷程Java
- JavaScript 模組化歷程JavaScript
- Java(三)封裝Java封裝
- hbase大規模資料寫入的優化歷程優化
- EventBus的優雅封裝封裝
- AppDelegate模組化歷程APP
- Java學習-封裝Java封裝
- C# PLINQ 記憶體列表查詢優化歷程C#記憶體優化
- 安裝 Memcached
- memcached 安裝
- memcached安裝
- Client Side Cache 和 Server Side Cache 的區別clientIDEServer
- Android記憶體優化之封裝九宮格Android記憶體優化封裝
- Laravel 效能優化實踐:在 Auth 中用 Cache 排程快取的 User 模型Laravel優化快取模型
- java list最優遍歷Java
- java Map遍歷最優Java
- 優秀程式設計師的優秀歷程程式設計師
- Shared Pool優化和Library Cache Latch衝突優化優化
- 通過Cache::Memcached方式 例項物件應用物件
- memcached的學習過程
- javascript模組化發展歷程JavaScript
- iOS專案元件化歷程iOS元件化
- Lua OpenResty容器化(考古歷程)REST
- 前端模組化發展歷程 (-)前端
- java三大特性-封裝Java封裝
- Java 封裝 SDK 以及使用Java封裝
- Chapter10 Java封裝APTJava封裝
- Java提高篇(1)封裝Java封裝
- Java 封裝 HDFS API 操作Java封裝API
- latch:cache buffers chains的優化思路AI優化
- Buffer cache 的調整與優化(二)優化