深度學習近期的一個趨勢是使用注意機制(Attention Mechanism),OpenAI研究負責人Ilya Sutskever在最近的一次採訪中提到了注意機制是最令人激動的進步之一,而且它們將就此紮根下來。這聽起來令人興奮不已,但注意機制到底是什麼?
神經網路中的注意機制大體是基於從人類視覺中發現的注意機制。對人類視覺注意力的研究較為透徹,目前存在幾個不同模型,但歸根結底,它們在本質上都是能夠聚焦於影像中「高解析度」的特定區域,同時又可以感知到周圍的「低解析度」區域,然後不斷的調整焦點。
注意機制在神經網路中的使用由來已久,特別是用在影像識別中。例如,Hugo Larochelle和Geoffrey E. Hinton於2010年發表的論文《Examples include Learning to combine foveal glimpses with a third-order Boltzmann machine》,以及Misha Denil2011年的論文《Learning where to Attend with Deep Architectures for Image Tracking》。但直到最近,外界才將注意機制應用在一些遞迴神經網路架構(尤其是用於自然語言處理,對於視覺的應用也在增加)上。這就是本文所關注的重點。
注意機制可以解決哪些問題?
為了更好的理解注意機制的作用,我們以神經機器翻譯(NMT)為例。傳統的機器翻譯系統通常都是依靠複雜的基於文字統計屬性的特徵工程。簡單來說,這些系統非常複雜,建造它們需要在工程上付諸大量努力。神經機器翻譯系統的工作原理有些不同,我們會將一個句子的含義對映到一個固定長度的向量表示上,然後基於那個向量再進行翻譯。NMT系統不是依賴於文法計數,而是試圖獲取更加高階的文字含義,這樣就可以比其他方法更好的概括出新句子。更加重要的是,NMT系統在建造和訓練方面更加容易,它們不需要人工新增特徵。事實上,Tensorflow中的一個簡單應用已經都不會超過100行程式碼了。
大多數NMT系統的工作原理是通過遞迴神經網路將源句子(比如說一句德語)編碼成向量,然後同樣使用遞迴神經網路將這個向量解碼成一句英語。

在上圖中,單詞「Echt」、「Dicke」和「Kiste」被輸入進編碼器,經過一個特殊的訊號(圖中未顯示)之後,解碼器開始生成翻譯完成的句子。解碼器持續不斷的生成詞彙,直到遇到一個特殊的代表句子結束的符號。在這裡,向量表現出了編碼器的內部狀態。
如果你看的足夠仔細,你會發現,解碼器是被用來基於編碼器中的最後一個隱狀態來單獨完成翻譯的。這個向量必須將我們所需要了解的源句子的一切都進行編碼,它必須能夠完全捕捉到句子的含義。用個技術術語來表示,那個向量是在進行句式嵌入(sentence embedding)。事實上,你如果使用PCA或t-SNAE等降維方法將不同句式嵌入繪製出來的話,你會發現最終語義相似的句子會離得比較近。這令人非常驚奇。
上文提到,我們可以將一個非常長的句子的所有資訊都編碼成單一向量,然後解碼器僅基於這個向量就能完成一次很好的翻譯,但這個假設看起來還有些不夠合理。讓我們拿一個由50個單片語成的源句子舉例。英語翻譯的第一個詞可能和源句子的第一個詞高度相關。但這意味著解碼器不得不考慮50步之前的資訊,以及需要在這個向量中進行解碼的資訊。我們都知道,遞迴神經網路在處理這類遠端依賴性時會遇到問題。理論上來說,類似於長短時記憶模型(LSTMs)的架構應該可以應對這些問題,但事實上遠端依賴性依然會存在問題。例如,研究者已經發現,顛倒源句子的順序(將它逆向輸入編碼器)能夠產生更好的結果,因為這縮短了從解碼器到編碼器相關部分的路徑。同樣的,將一個順序輸入兩次也可能幫助神經網路更好的進行記憶。
我認為這種顛倒句子順序的方法屬於「hack」。這在實際應用中更有效,但卻不是一種從根本上出發的解決方案。大部分翻譯基準是基於法語和德語所做出來的,它們和英語比較類似。但在某些語言(例如日語)的英語翻譯中,一句話的最後一個詞有可能是第一個詞的預測因子。在這種情況下,逆向輸入就會使結果變的更差。對此,還有什麼可選方案?答案就是注意機制。
有了注意機制,我們不再試圖將一個完整的源句子編碼成一個固定長度的向量。相反,我們在形成輸出的每一步都允許解碼器「關注」到源句子的不同部分。重要的是,我們會讓這個模型基於輸入的句子以及到目前為止產生的結果去學習應該「關注」什麼。因此,在那些高度一致的語言(例如英語和德語)中,解碼器將可能選擇按照順序進行「關注」。如果需要翻譯第一個英語單詞,就「關注」第一個單詞,等等。這就是神經機器翻譯中藉助於對匹配和翻譯的聯合學習所獲得的成果。

這裡,y'是解碼器翻譯出來的dan ci,x'是源句子的單詞。上圖用了一個雙向的遞迴網路,但這個不重要,你可以忽視反向部分。重要的部分在於,解碼器輸出的每一個單詞y都依賴於所有輸入狀態的加權組合,而不僅是最後一個狀態。a'是權重,用來定義對於每一個輸出值,每個輸入狀態應該被考慮的程度。因此,如果a(3,2)很大,則意味著解碼器在生成目標句子第三個單詞的翻譯結果時,應該更多的「注意」源句子的第二個狀態。
注意力的一大優點是它使我們能夠解釋和想象出模型的工作狀態。例如,當一個句子正在被翻譯時,我們可以將注意力權重矩陣進行視覺化處理,因此,就能理解這個模型是怎樣進行翻譯的。

這裡我們看到,當從法語翻譯成英語時,神經網路按照順序「關注」了每一個輸入狀態,但有時它會一次性「關注」兩個單詞,比如在將「la Syrie」翻譯成「Syria」(敘利亞)時。
注意機制的代價
如果我們更仔細地觀察注意機制的方程,我們會發現它是有代價的。我們需要結合每個輸入和輸出的單詞來計算注意值。如果你輸入50個詞,輸出50個詞,那麼注意值將會是2500。這還不算糟,但是如果你做字元級的計算,處理由數以百計的標記組成的序列,那麼上述注意機制的代價將變得過於昂貴。
事實上,這是反直覺的。人類的注意力是節省計算資源的。當我們專注於一件事時,會忽略許多其他事。但那不是我們上述模型所真正做的事。在我們決定關注什麼之前,必須確定每一個細節。直覺上等效輸出一個翻譯的單詞,要通過所有內在記憶中的文字來決定下一步生成什麼單詞,這似乎是一種浪費,完全不是人類所擅長的事情。事實上,它更類似於記憶的使用,而不是注意,這在我看來有點用詞不當。然而,這並不影響注意機制變得非常流行,而且在許多工中表現良好。
另一種注意機制的方法是使用強化學習來預測一個需要專注的近似位置。這聽起來更像人類的注意力,這就是視覺注意遞迴模型( Recurrent Models of Visual Attention)所完成的事情。然而,強化學習模型不能用反向傳播進行首尾相連的訓練,因此它們並不能廣泛應用於NLP問題中。
超越機器翻譯的注意機制
目前我們看到了注意機制應用於機器翻譯中,但它可以用於任意遞迴模型,讓我們看更多的例子。
如圖所示,在《Attend and Tell:Neural Image Caption Generation with Visual Attention》論文中,作者使用了注意機制來解決影像描述生成問題。他們用卷積神經網路來「編碼」影像,然後用帶有注意機制的遞迴神經網路來生成描述。通過將注意權重視覺化,我們來解釋一下,模型在生成一個單詞時所表現出來的樣子:
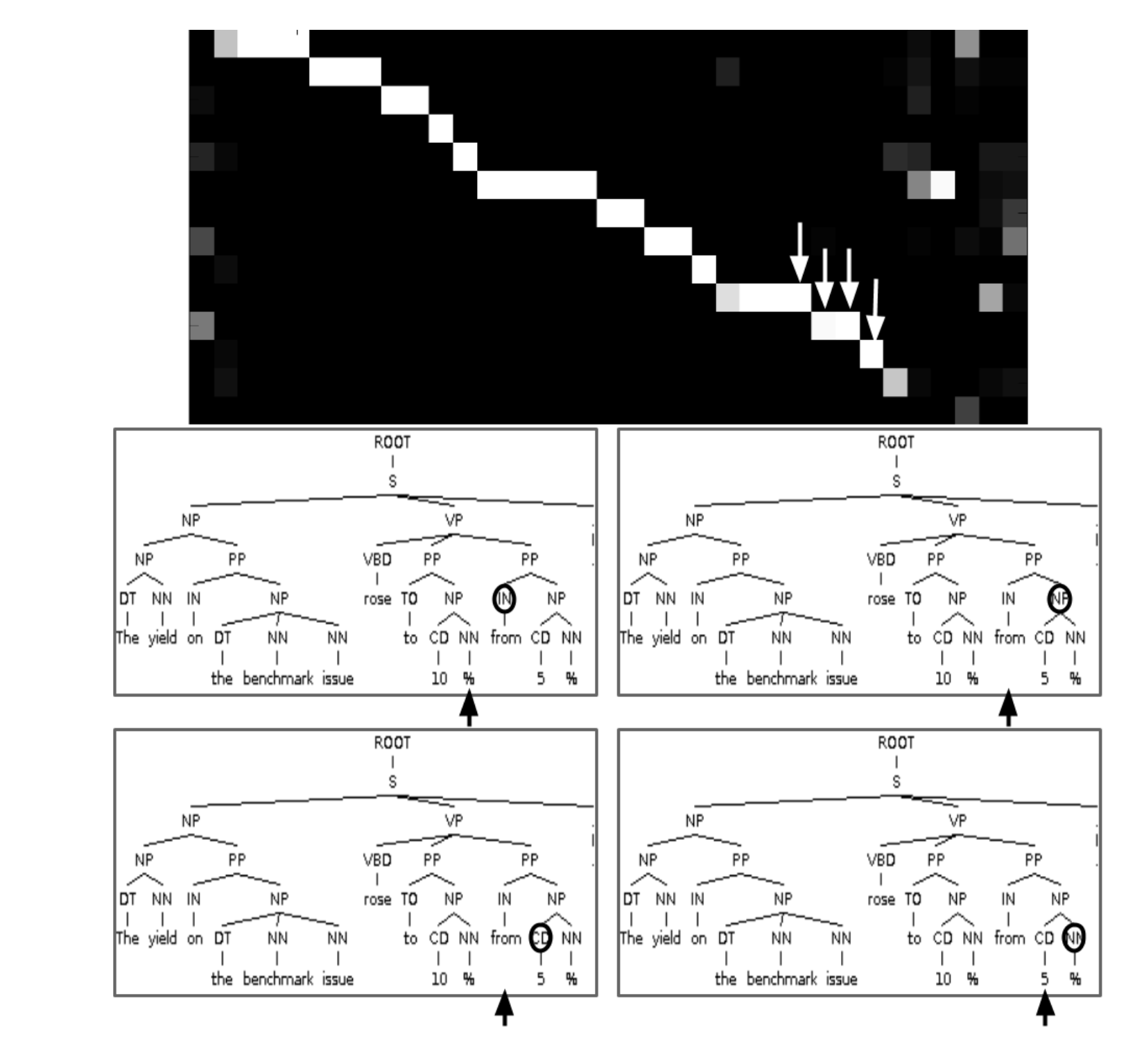
 在論文《Grammar as a Foreign Language》中,作者用帶有注意機制的遞迴神經網路生成句子分析樹。將注意矩陣視覺化,可以讓我們洞悉神經網路是如何生成這個分析樹的:
在論文《Grammar as a Foreign Language》中,作者用帶有注意機制的遞迴神經網路生成句子分析樹。將注意矩陣視覺化,可以讓我們洞悉神經網路是如何生成這個分析樹的:
 在論文《Teaching Machines to Read and Comprehend》中,作者使用RNN來閱讀文字和(合成的)問題,然後輸出答案。通過將注意矩陣視覺化,我們能看到,當神經網路試圖尋找答案時,它在「看」什麼:
在論文《Teaching Machines to Read and Comprehend》中,作者使用RNN來閱讀文字和(合成的)問題,然後輸出答案。通過將注意矩陣視覺化,我們能看到,當神經網路試圖尋找答案時,它在「看」什麼:

注意力=(模糊的)記憶?
注意機制所解決的基本問題是允許神經網路參考輸入序列,而不是專注於將所有資訊編碼為固定長度的向量。正如我上面提到的,我認為注意力有點用詞不當。換句話說,注意機制是簡單的讓神經網路使用其內部記憶(編碼器的隱狀態)。在這個解釋中,不是選擇去「關注」什麼,而是讓神經網路選擇從記憶中檢索什麼。不同於傳統的記憶,這裡的記憶訪問機制更加靈活,這意味著神經網路根據所有記憶的位置賦予其相應的權重,而不是從單個離散位置得出某個值。讓記憶的訪問更具靈活性,有助於我們用反向傳播對神經網路進行首尾相連的訓練(雖然有非模糊的方法,即使用抽樣方法來代替反向傳播進行梯度計算。)
記憶機制有著更長的歷史。標準遞迴神經網路的隱狀態就是一種內部記憶。梯度消失問題使RNNs無法從遠端依賴性中進行學習。長短時記憶模型通過使用允許明確記憶刪除和更新)改善了上述情況。
形成更加複雜記憶結構的趨勢仍在繼續。論文《End-to-End Memory Networks》中可以(End-to-End Memory Networks)使神經網路先多次讀取相同的輸入序列,然後再進行輸出,每一個步驟都更新記憶內容。例如,通過對輸入內容進行多次推理從而回答某個問題。但是,當神經網路引數的權重以一種特定方式聯絡在一起時,端對端記憶網路中的記憶機制等同於注意機制,這在記憶中創造了多重躍點(因為它試圖從多個句子中整合資訊)。
在論文《神經圖靈機》中使用了和記憶機制類似的形式,但有著更加複雜的訪問型別,後者既使用了基於內容的訪問,又使用了基於位置的訪問,從而使神經網路可以學習訪問模式來執行簡單的計算機程式,例如排序演算法。
在不久的將來,我們非常有可能看到對記憶和注意機制的更加清晰的區分,它可能會沿著「強化學習神經圖靈機」(正試著學習訪問模式來處理外部介面)的路線發展下去。
文章所提及的所有論文下載地址。
本文來源wildml,機器之心趙雲峰、孟婷編譯。