[python爬蟲] 招聘資訊定時系統 (一).BeautifulSoup爬取資訊並儲存MySQL
這系列文章主要講述,如何通過Python爬取招聘資訊,且爬取的日期為當前天的,同時將爬取的內容儲存到資料庫中,然後製作定時系統每天執行爬取,最後是Python呼叫相關庫傳送簡訊到手機。
最近研究了資料庫的定時計劃備份,聯絡爬蟲簡單做了這個實驗,雖然方法是基於單機,比較落後,但可行,創新也比較好。整個系列主要分為五部分,共五篇文章:
1.Python爬取招聘資訊,並且儲存到MySQL資料庫中;
2.呼叫pyinstaller包將py檔案打包成exe可執行檔案;
3.設定Windows系統的計劃,製作定時任務,每天早上定時執行exe爬蟲;
4.結合PHP(因畢業設計指導學生的是PHP系統)簡單實現前端招聘資訊介面;
5.補充知識:Python呼叫簡訊貓傳送招聘簡訊到客戶手機,研究ing。
文章比較基礎好玩,希望對您有所幫助,如果文章中存在錯誤或不足之處。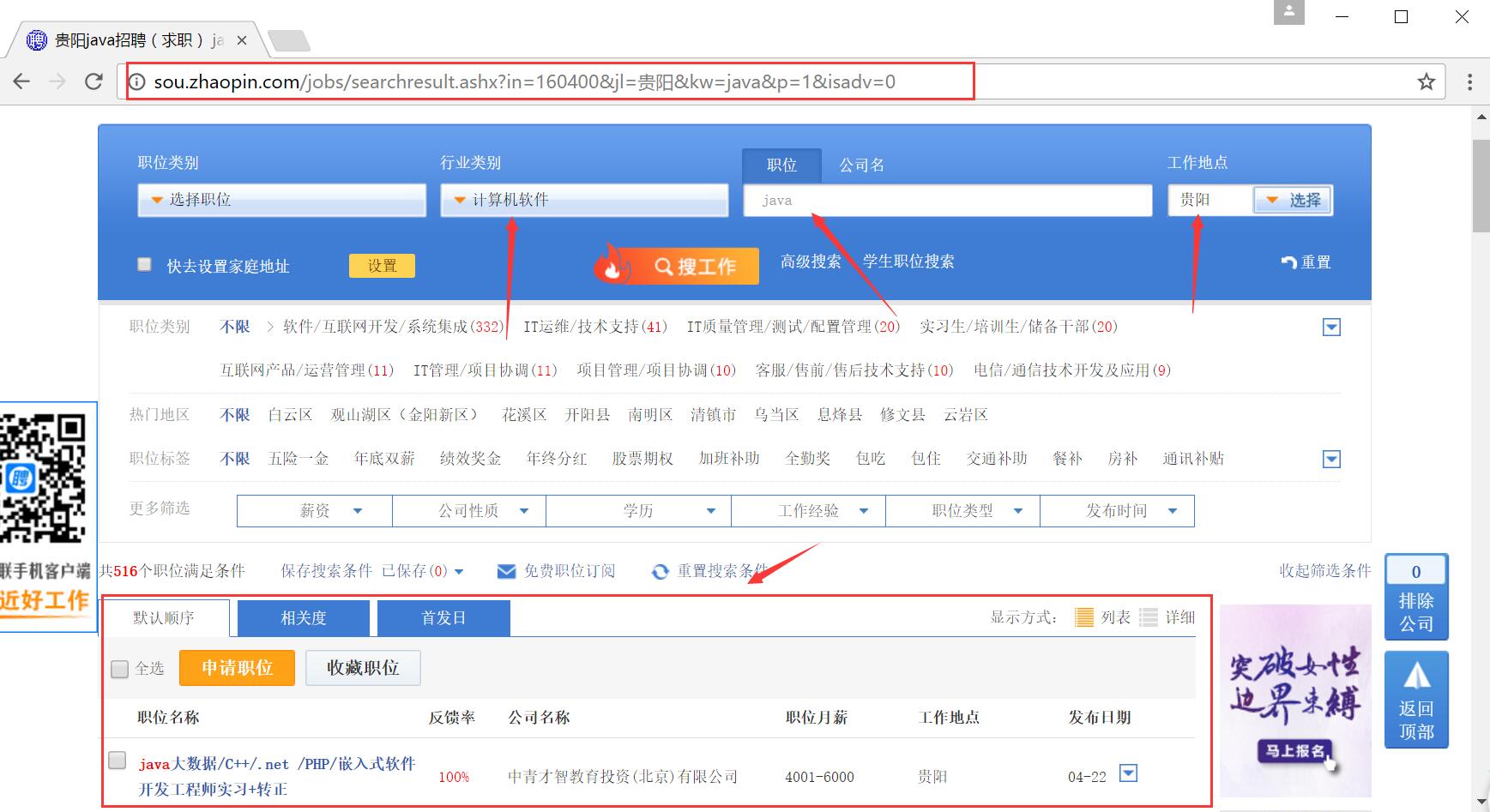
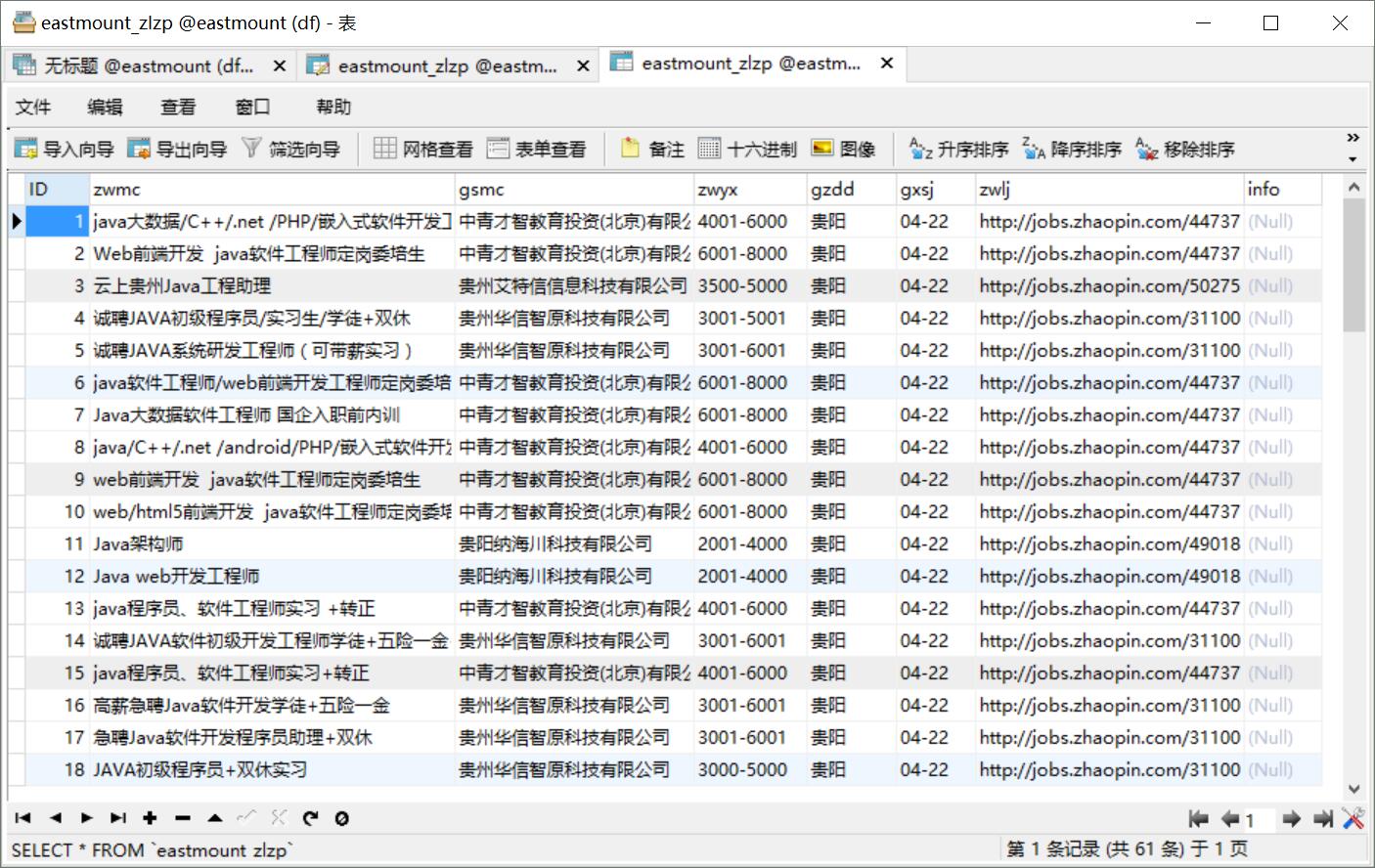
爬取結果儲存至MySQL資料庫如下圖所示,注意只有4月22日的資訊。
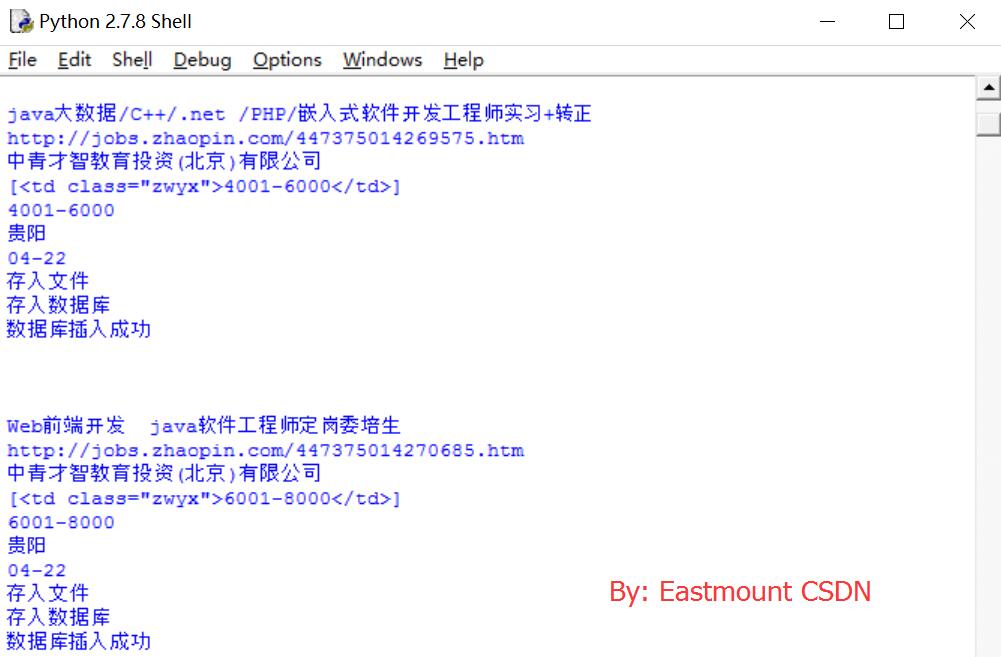
執行結果及儲存TXT檔案如下所示:
重點是分析智聯招聘的DOM樹結構。
1.分析URL
URL為:http://sou.zhaopin.com/jobs/searchresult.ashx?in=160400&jl=%E8%B4%B5%E9%98%B3&kw=java&p=2&isadv=0
其中,"in=160400" 表示 "行業類別" 選擇"計算機軟體"(可以多選);"jl=貴陽" 表示工作地點選擇貴陽市;"kw=java" 表示職位選擇Java相關專業;"p=2" 表示頁碼,main函式通過迴圈分析爬取。
2.分析DOM樹節點
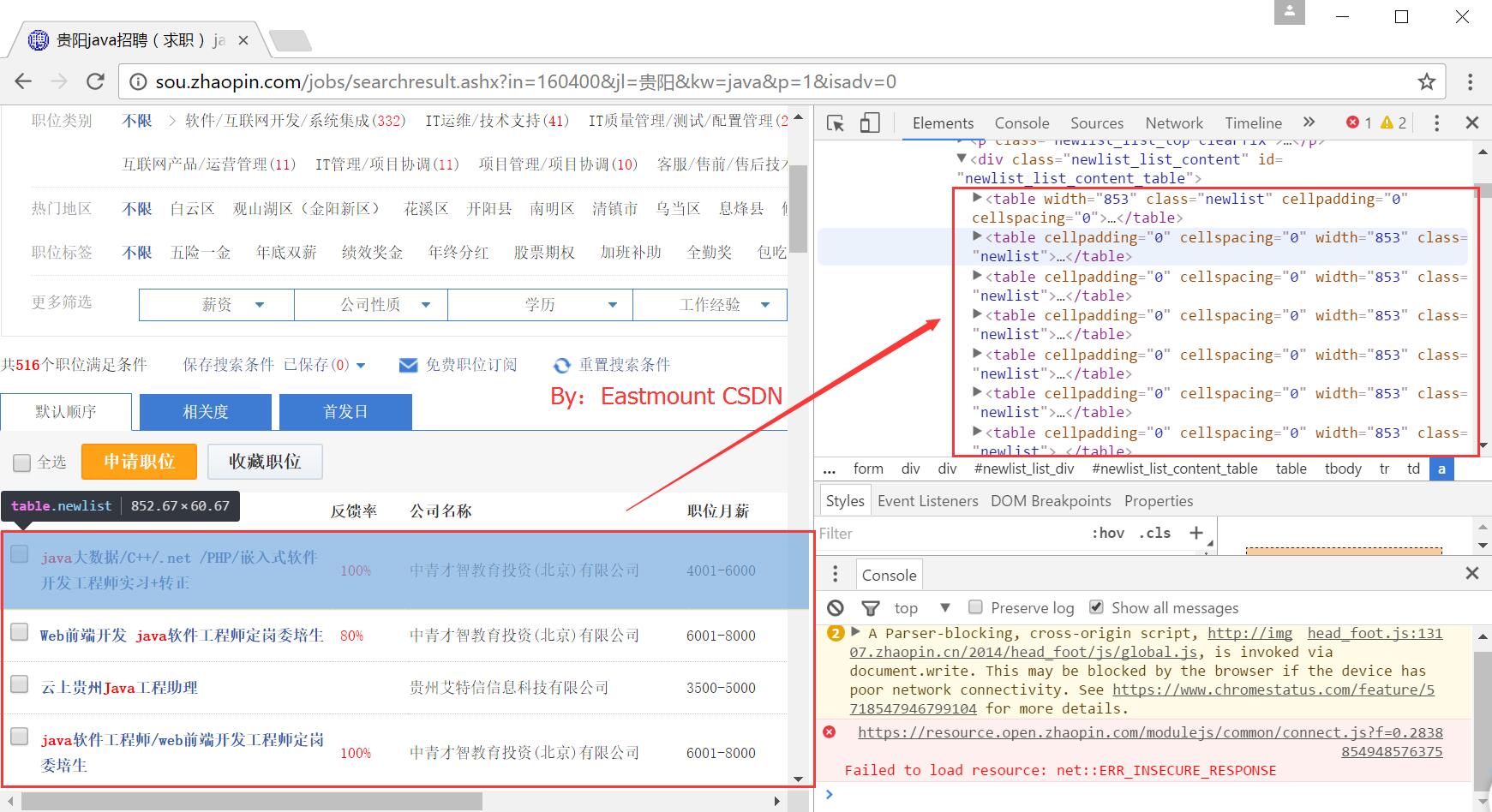
然後瀏覽器右鍵審查元素,可以看到每行職位資訊都是在HTML中都是一個<table></table>,其中class為newlist。
核心程式碼:for tag in soup.find_all(attrs={"class":"newlist"}):
定位該節點後再分別爬取內容,並賦值給變數,儲存到MySQL資料庫中。
3.具體內容分析
獲取職位名稱程式碼如下:
zwmc = tag.find(attrs={"class":"zwmc"}).get_text()
print zwmc
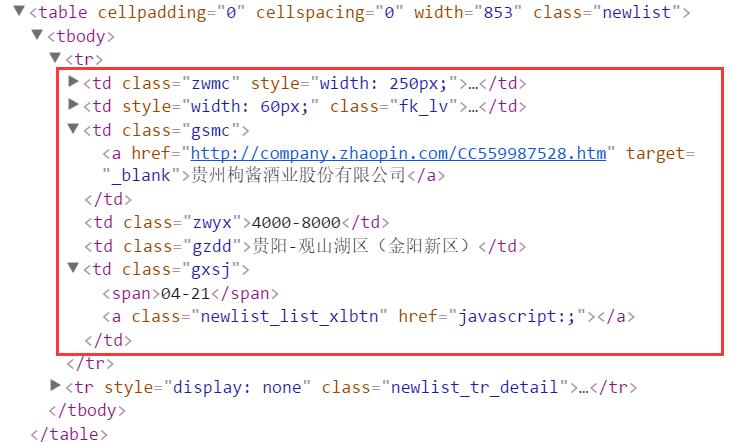
另一段程式碼,會輸出節點資訊,如:
zz = tag.find_all('td', {"class":"zwyx"})
print zz
#<td class="zwyx">8000-16000</td>
對應的HTML DOM樹分析如下圖所示。
4.判斷為當前日期則儲存到TXT和MySQL中,這是為了後面方便,每天爬取最新的資訊並週期執行,然後傳送簡訊給手機。我也是佩服自己的大腦,哈哈~
參考前文,並推薦官網。
Python爬蟲之Selenium+BeautifulSoup+Phantomjs專欄
[python知識] 爬蟲知識之BeautifulSoup庫安裝及簡單介紹
[python爬蟲] BeautifulSoup和Selenium對比爬取豆瓣Top250電影資訊
後面還將繼續探尋、繼續寫文,寫完這種單擊版的定時傳送功能,後面研究Python伺服器的相關功能。最後希望文章對你有所幫助,如果文章中存在錯誤或不足之處,還請海涵~
太忙了,但是年輕人忙才好,多經歷多磨礪多感悟;想想自己都是下班在學習,配女神的時候學習,真的有個好賢內助。鬍子來省考,晚上陪他們吃個飯。感覺人生真的很奇妙,昨天加完班走了很遠給女神一個91禮物和一個拼圖,感覺挺開心的。生活、教學、程式設計、愛情,最後獻上一首最近寫的詩,每句都是近期一個故事。
風雪交加雨婆娑,
琴瑟和鳴淚斑駁。
披星戴月輾轉夢,
娜璋白首愛連綿。
同時準備寫本python書給我的女神,一直沒定下來,唯一要求就是她的署名及支援。
(By:Eastmount 2017-04-22 下午4點 http://blog.csdn.net/eastmount/)
最近研究了資料庫的定時計劃備份,聯絡爬蟲簡單做了這個實驗,雖然方法是基於單機,比較落後,但可行,創新也比較好。整個系列主要分為五部分,共五篇文章:
1.Python爬取招聘資訊,並且儲存到MySQL資料庫中;
2.呼叫pyinstaller包將py檔案打包成exe可執行檔案;
3.設定Windows系統的計劃,製作定時任務,每天早上定時執行exe爬蟲;
4.結合PHP(因畢業設計指導學生的是PHP系統)簡單實現前端招聘資訊介面;
5.補充知識:Python呼叫簡訊貓傳送招聘簡訊到客戶手機,研究ing。
文章比較基礎好玩,希望對您有所幫助,如果文章中存在錯誤或不足之處。
一. 執行結果
爬取地址為智聯招聘網站:http://sou.zhaopin.com/
爬取結果儲存至MySQL資料庫如下圖所示,注意只有4月22日的資訊。
執行結果及儲存TXT檔案如下所示:
二. BeautifulSoup爬蟲詳解
完整程式碼如下所示:
# -*- coding: utf-8 -*-
"""
Created on 2017-04-22 15:10
@author: Easstmount
"""
import urllib2
import re
from bs4 import BeautifulSoup
import codecs
import MySQLdb
import os
#儲存資料庫
#引數:職位名稱 公司名稱 職位月薪 工作地點 釋出時間 職位連結
def DatabaseInfo(zwmc, gsmc, zwyx, gzdd, gxsj, zwlj):
try:
conn = MySQLdb.connect(host='localhost',user='root',
passwd='123456',port=3306, db='eastmount')
cur=conn.cursor() #資料庫遊標
#報錯:UnicodeEncodeError: 'latin-1' codec can't encode character
conn.set_character_set('utf8')
cur.execute('SET NAMES utf8;')
cur.execute('SET CHARACTER SET utf8;')
cur.execute('SET character_set_connection=utf8;')
#SQL語句 智聯招聘(zlzp)
sql = '''insert into eastmount_zlzp
(zwmc,gsmc,zwyx,gzdd,gxsj,zwlj)
values(%s, %s, %s, %s, %s, %s)'''
cur.execute(sql, (zwmc, gsmc, zwyx, gzdd, gxsj, zwlj))
print '資料庫插入成功'
#異常處理
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])
finally:
cur.close()
conn.commit()
conn.close()
#爬蟲函式
def crawl(url):
page = urllib2.urlopen(url)
contents = page.read()
soup = BeautifulSoup(contents, "html.parser")
print u'貴陽JAVA招聘資訊: 職位名稱 \t 公司名稱 \t 職位月薪 \t 工作地點 \t 釋出日期 \n'
infofile.write(u"貴陽JAVA招聘資訊: 職位名稱 \t 公司名稱 \t 職位月薪 \t 工作地點 \t 釋出日期 \r\n")
print u'爬取資訊如下:\n'
i = 0
for tag in soup.find_all(attrs={"class":"newlist"}):
#print tag.get_text()
i = i + 1
#職位名稱
zwmc = tag.find(attrs={"class":"zwmc"}).get_text()
zwmc = zwmc.replace('\n','')
print zwmc
#職位連結
url_info = tag.find(attrs={"class":"zwmc"}).find_all("a")
#print url_info
#url_info.get(href) AttributeError: 'ResultSet' object has no attribute 'get'
for u in url_info:
zwlj = u.get('href')
print zwlj
#公司名稱
gsmc = tag.find(attrs={"class":"gsmc"}).get_text()
gsmc = gsmc.replace('\n','')
print gsmc
#find另一種定位方法 <td class="zwyx">8000-16000</td>
zz = tag.find_all('td', {"class":"zwyx"})
print zz
#職位月薪
zwyx = tag.find(attrs={"class":"zwyx"}).get_text()
zwyx = zwyx.replace('\n','')
print zwyx
#工作地點
gzdd = tag.find(attrs={"class":"gzdd"}).get_text()
gzdd = gzdd.replace('\n','')
print gzdd
#釋出時間
gxsj = tag.find(attrs={"class":"gxsj"}).get_text()
gxsj = gxsj.replace('\n','')
print gxsj
#獲取當前日期並判斷寫入檔案
import datetime
now_time = datetime.datetime.now().strftime('%m-%d') #%Y-%m-%d
#print now_time
if now_time==gxsj:
print u'存入檔案'
infofile.write(u"[職位名稱]" + zwmc + "\r\n")
infofile.write(u"[公司名稱]" + gsmc + "\r\n")
infofile.write(u"[職位月薪]" + zwyx + "\r\n")
infofile.write(u"[工作地點]" + gzdd + "\r\n")
infofile.write(u"[釋出時間]" + gxsj + "\r\n")
infofile.write(u"[職位連結]" + zwlj + "\r\n\r\n")
else:
print u'日期不一致,當前日期: ', now_time
#####################################
# 重點:寫入MySQL資料庫
#####################################
if now_time==gxsj:
print u'存入資料庫'
DatabaseInfo(zwmc, gsmc, zwyx, gzdd, gxsj, zwlj)
print '\n\n'
else:
print u'爬取職位總數', i
#主函式
if __name__ == '__main__':
infofile = codecs.open("Result_ZP.txt", 'a', 'utf-8')
#翻頁執行crawl(url)爬蟲
i = 1
while i<=2:
print u'頁碼', i
url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?in=160400&jl=%E8%B4%B5%E9%98%B3&kw=java&p=' + str(i) + '&isadv=0'
crawl(url)
infofile.write("###########################\r\n\r\n\r\n")
i = i + 1
infofile.close()
重點是分析智聯招聘的DOM樹結構。
1.分析URL
URL為:http://sou.zhaopin.com/jobs/searchresult.ashx?in=160400&jl=%E8%B4%B5%E9%98%B3&kw=java&p=2&isadv=0
其中,"in=160400" 表示 "行業類別" 選擇"計算機軟體"(可以多選);"jl=貴陽" 表示工作地點選擇貴陽市;"kw=java" 表示職位選擇Java相關專業;"p=2" 表示頁碼,main函式通過迴圈分析爬取。
然後瀏覽器右鍵審查元素,可以看到每行職位資訊都是在HTML中都是一個<table></table>,其中class為newlist。
核心程式碼:for tag in soup.find_all(attrs={"class":"newlist"}):
定位該節點後再分別爬取內容,並賦值給變數,儲存到MySQL資料庫中。
3.具體內容分析
獲取職位名稱程式碼如下:
zwmc = tag.find(attrs={"class":"zwmc"}).get_text()
print zwmc
另一段程式碼,會輸出節點資訊,如:
zz = tag.find_all('td', {"class":"zwyx"})
print zz
#<td class="zwyx">8000-16000</td>
對應的HTML DOM樹分析如下圖所示。
4.判斷為當前日期則儲存到TXT和MySQL中,這是為了後面方便,每天爬取最新的資訊並週期執行,然後傳送簡訊給手機。我也是佩服自己的大腦,哈哈~
參考前文,並推薦官網。
Python爬蟲之Selenium+BeautifulSoup+Phantomjs專欄
[python知識] 爬蟲知識之BeautifulSoup庫安裝及簡單介紹
[python爬蟲] BeautifulSoup和Selenium對比爬取豆瓣Top250電影資訊
三. 資料庫操作
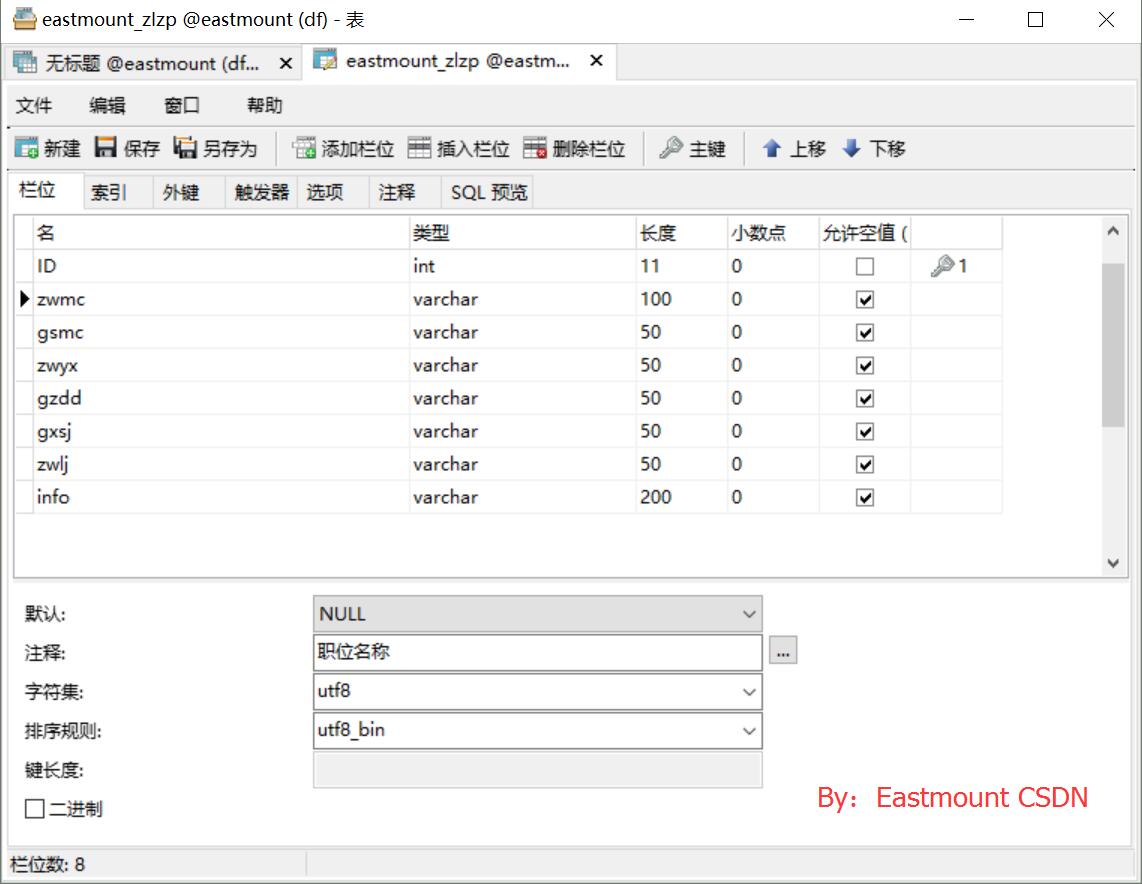
SQL語句建立表程式碼如下:
CREATE TABLE `eastmount_zlzp` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`zwmc` varchar(100) COLLATE utf8_bin DEFAULT NULL COMMENT '職位名稱',
`gsmc` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '公司名稱',
`zwyx` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '職位月薪',
`gzdd` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '工作地點',
`gxsj` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '釋出時間',
`zwlj` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '職位連結',
`info` varchar(200) COLLATE utf8_bin DEFAULT NULL COMMENT '詳情',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; 其中,Python呼叫MySQL推薦下面這篇文字。
[python] 專題九.Mysql資料庫程式設計基礎知識
核心程式碼如下所示:
# coding:utf-8
import MySQLdb
try:
conn=MySQLdb.connect(host='localhost',user='root',passwd='123456',port=3306, db='test01')
cur=conn.cursor()
#插入資料
sql = '''insert into student values(%s, %s, %s)'''
cur.execute(sql, ('yxz','111111', '10'))
#檢視資料
print u'\n插入資料:'
cur.execute('select * from student')
for data in cur.fetchall():
print '%s %s %s' % data
cur.close()
conn.commit()
conn.close()
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])後面還將繼續探尋、繼續寫文,寫完這種單擊版的定時傳送功能,後面研究Python伺服器的相關功能。最後希望文章對你有所幫助,如果文章中存在錯誤或不足之處,還請海涵~
太忙了,但是年輕人忙才好,多經歷多磨礪多感悟;想想自己都是下班在學習,配女神的時候學習,真的有個好賢內助。鬍子來省考,晚上陪他們吃個飯。感覺人生真的很奇妙,昨天加完班走了很遠給女神一個91禮物和一個拼圖,感覺挺開心的。生活、教學、程式設計、愛情,最後獻上一首最近寫的詩,每句都是近期一個故事。
風雪交加雨婆娑,
琴瑟和鳴淚斑駁。
披星戴月輾轉夢,
娜璋白首愛連綿。
同時準備寫本python書給我的女神,一直沒定下來,唯一要求就是她的署名及支援。
(By:Eastmount 2017-04-22 下午4點 http://blog.csdn.net/eastmount/)
相關文章
- python爬蟲--招聘資訊Python爬蟲
- python爬蟲——爬取大學排名資訊Python爬蟲
- python爬蟲--爬取鏈家租房資訊Python爬蟲
- 利用Python爬蟲獲取招聘網站職位資訊Python爬蟲網站
- 小白學 Python 爬蟲(25):爬取股票資訊Python爬蟲
- python爬蟲58同城(多個資訊一次爬取)Python爬蟲
- Python爬蟲爬取淘寶,京東商品資訊Python爬蟲
- Java爬蟲-爬取疫苗批次資訊Java爬蟲
- python 爬蟲 5i5j房屋資訊 獲取並儲存到資料庫Python爬蟲資料庫
- Python爬蟲實戰:爬取淘寶的商品資訊Python爬蟲
- 爬蟲系列:使用 MySQL 儲存資料爬蟲MySql
- 爬蟲實戰(二):Selenium 模擬登入並爬取資訊爬蟲
- [python爬蟲] BeautifulSoup設定Cookie解決網站攔截並爬取螞蟻短租Python爬蟲Cookie網站
- Python爬蟲訓練:爬取酷燃網視訊資料Python爬蟲
- Python爬蟲抓取股票資訊Python爬蟲
- Python爬蟲之BeautifulSoupPython爬蟲
- Python爬蟲實戰之(二)| 尋找你的招聘資訊Python爬蟲
- Python爬蟲之小說資訊爬取與資料視覺化分析Python爬蟲視覺化
- 爬蟲實戰(一):爬取微博使用者資訊爬蟲
- Python爬蟲之使用MongoDB儲存資料Python爬蟲MongoDB
- 利用requests+BeautifulSoup爬取網頁關鍵資訊網頁
- python爬取北京租房資訊Python
- 爬蟲學習整理(3)資料儲存——Python對MySql操作爬蟲PythonMySql
- Python爬蟲之BeautifulSoup庫Python爬蟲
- python爬蟲小專案--飛常準航班資訊爬取variflight(上)Python爬蟲
- 爬蟲Selenium+PhantomJS爬取動態網站圖片資訊(Python)爬蟲JS網站Python
- [python應用案例] 一.BeautifulSoup爬取天氣資訊併傳送至QQ郵箱Python
- Python爬取天氣資訊並語音播報Python
- 爬蟲01:爬取豆瓣電影TOP 250基本資訊爬蟲
- Python爬蟲教程-23-資料提取-BeautifulSoup4(一)Python爬蟲
- (詳細)python爬取網頁資訊並儲存為CSV檔案(後面完整程式碼!!!)Python網頁
- Python爬蟲入門教程 50-100 Python3爬蟲爬取VIP視訊-Python爬蟲6操作Python爬蟲
- Python爬取股票資訊,並實現視覺化資料Python視覺化
- python爬蟲,獲取中國工程院院士資訊Python爬蟲
- Python 爬蟲獲取網易雲音樂歌手資訊Python爬蟲
- python爬蟲抓取哈爾濱天氣資訊(靜態爬蟲)Python爬蟲
- python網路爬蟲_Python爬蟲:30個小時搞定Python網路爬蟲視訊教程Python爬蟲
- python 小爬蟲 DrissionPage+BeautifulSoupPython爬蟲
- [爬蟲] 利用 Python 的 Selenium 庫爬取極客時間付費課程並儲存為 PDF 檔案爬蟲Python