簡單說下需求:
統計各個省份的 3大運營商的介面訪問成功率,繪圖展示
資料格式
{"mobile" : "15812345608", "province": "廣東", "isp": "中國電信","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : "false"} 最終入庫(influxdb)的日誌
示例資料:(influxdb的sql)
INSERT crawl_result,isp=中國移動,province=上海,mobile=15912345678 success="1"
INSERT crawl_result,isp=中國移動,province=上海,mobile=15912345678 success="1"
INSERT crawl_result,isp=中國移動,province=上海,mobile=15912345678 success="1"
INSERT crawl_result,isp=中國移動,province=上海,mobile=15912345678 success="1"
INSERT crawl_result,isp=中國移動,province=上海,mobile=15912345678 success="1"
INSERT crawl_result,isp=中國移動,province=上海,mobile=15912345678 success="1"
INSERT crawl_result,isp=中國移動,province=上海,mobile=15912345678 fail="0"
INSERT crawl_result,isp=中國移動,province=上海,mobile=15912345678 fail="0"
INSERT crawl_result,isp=中國聯通,province=上海,mobile=15912345678 fail="0"說下方案

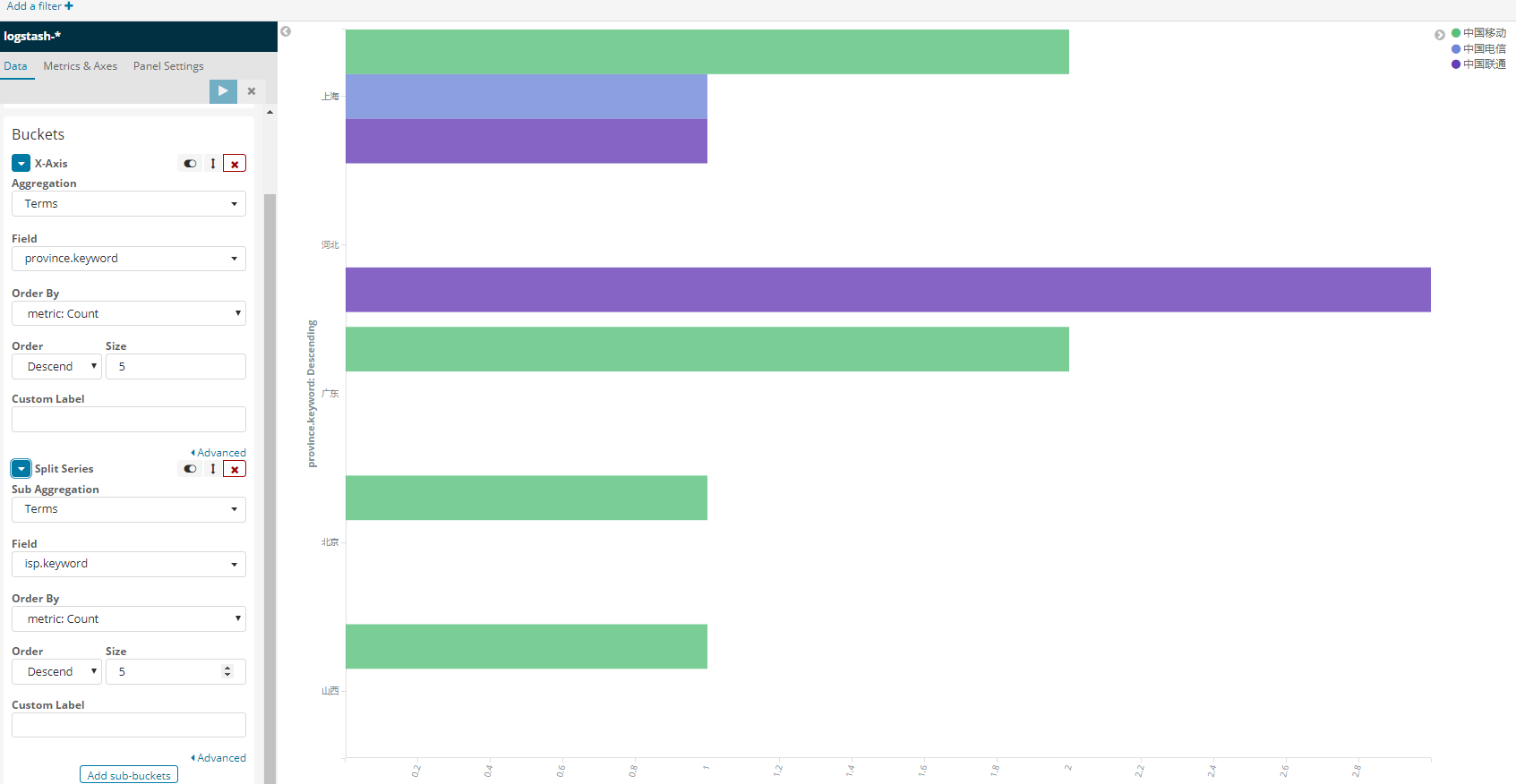
第二種方案: influxdb+grafana, 好處是可靈活計算比例.表格少一些.
這個毛病在於sql語句. grafana模板有點難,如果沒玩過的話. grafana需要多點點就會了,
grafana對接influxdb,無需多寫什麼sql.
vm 下載安裝grafana
參考: 普羅+grafana監控mysql: https://segmentfault.com/a/1190000007040144
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.6.2-1.x86_64.rpm
yum localinstall grafana-4.6.2-1.x86_64.rpm -y配置grafana匯入dashboard
修改配置
cd /etc/grafana/grafana.ini
cp grafana.ini grafana.ini.default
vim grafana.ini
...
370 [dashboards.json]
371 ;enabled = false
372 enabled = true
373 path = /var/lib/grafana/dashboards
...匯入dashboard
cd /var/lib/grafana/dashboards外掛目錄: /var/lib/grafana/plugins
dashboard目錄: /var/lib/grafana/dashboards
日誌目錄: /var/log/grafana/grafana.log
啟動並訪問:
systemctl restart grafana-server
http://monitor_host:3000訪問Grafana網頁介面(預設的帳號/密碼為admin/admin)influxdb安裝
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.4.2.x86_64.rpm
sudo yum localinstall influxdb-1.4.2.x86_64.rpm當然也可以容器啟動 grafana和influxdb
參考: https://hub.docker.com/r/grafana/grafana/
docker run \
-d \
-p 3000:3000 \
--name=grafana \
-e "GF_SERVER_ROOT_URL=http://grafana.server.name" \
-e "GF_SECURITY_ADMIN_PASSWORD=secret" \
grafana/g最終實現:

連庫:
定義模板變數
配置左半部分的
配置有半部分的
SELECT count("success") FROM "crawl_result" WHERE ("isp" = '中國移動' AND "province" =~ /^$china_mobile$/) AND $timeFilter GROUP BY "isp","province" fill(null) ORDER BY time DESC
SELECT count("success"),count("fail"),count("success")/(count("success")+count("fail")) FROM "crawl_result" WHERE ("isp" = '中國移動' AND province=~ /^$china_mobile$/) AND $timeFilter GROUP BY "isp","province" fill(null)最終模板效果:
sql的groupby
按照isp分類
SELECT isp,province,mobile,success,fail FROM "crawl_result" GROUP BY "isp""

先按照isp分類,後按照province分類
SELECT isp,province,mobile,success,fail FROM "crawl_result" GROUP BY "isp","province"

參考別人的模板是怎麼做的:
Graphite Templated Dashboard: http://play.grafana.org/dashboard/db/graphite-templated-nested
Elasticsearch Templated Dashboard: http://play.grafana.org/dashboard/db/elasticsearch-templated
InfluxDB Templated Dashboard: http://play.grafana.org/dashboard/db/influxdb-templated-queries
InfluxDB Templated Dashboard
grafana不需要寫特別的語法,按照它給的sql語句器實現group by分類和order by,完全ok.




