從0到N建立高價效比的大資料平臺
宣告:本文為作者在CSDN技術公開課的分享原創整理,未經許可,禁止轉載。
作者:郭煒,易觀CTO,畢業於北京大學,曾任聯想大資料總監、萬達電商資料部總經理,曾在中金、IBM、Teradata公司擔任大資料方向重要崗位。在智慧硬體以及大資料分析領域具有豐富的理論和實踐經驗。
責編:錢曙光,關注架構和演算法領域,尋求報導或者投稿請發郵件qianshg@csdn.net,另有「CSDN 高階架構師群」,內有諸多知名網際網路公司的大牛架構師,歡迎架構師加微信qshuguang2008申請入群,備註姓名+公司+職位。
分享內容簡介
今天和大家分享的內容主要就是怎麼樣從0到N來建一個大資料平臺。其實,每一個大資料平臺都不是憑空而起的,每個企業剛剛開始資料分析的時候,也不是上來就是一個大資料開源平臺Hadoop、Spark這樣一個儲存的。今天分享的內容,其實是根據企業發展的不同階段,針對業務的需求來選擇不同的大資料架構,配置不同規模的資料處理人員,根據企業不同的時間點,幫助企業從0到N,建立高價效比的大資料平臺。
從0到N——資料大時代的劃分
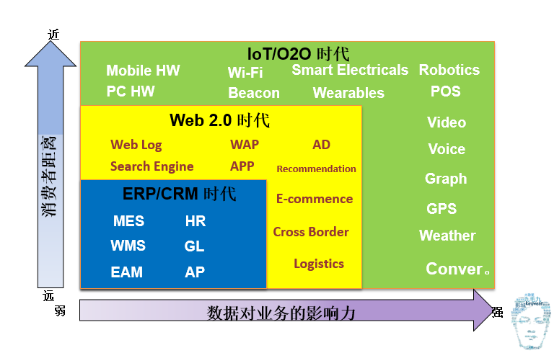
第一個先說從0到N大資料的時代劃分,其實大資料時代不是現在才開始的,它早在以前就開始了,只不過那時候不叫大資料,在最開始的時候叫資料倉儲。十年前,它在做企業內部的ERP、CRM的相對的一些整合。然後把裡面做一些BI的分析報表,做一些資料探勘。那個時候最著名的例子應該是啤酒和尿片的故事,就是關聯資料探勘能分析出來,週末男人經常去買尿片和啤酒故事。到後來網際網路的出現大資料進入了Web2.0時代。在過去大家只是拿到一些使用者結構化的交易資訊和使用者的聯絡資訊,現在可以獲得每一個人上網的點選流的資訊,根據你的點選的情況做一些推薦。包括一些現在的猜你喜歡和搜尋引擎排名,這些都是在Web2.0時候基於你在點選流的大資料的檢索和大資料的一些處理。第三個階段,現在我們所處的階段,我認為就是IoT O2O時代,現在大家一講到大資料,其實不僅僅包括了上網的行為日誌,還包括像現在智慧Wi-Fi與智慧POS(感知線上下,一個在逛商場的時候,你在哪裡停留了,停了多久,進了哪家店,吃了什麼東西,唱了什麼歌,看了什麼電影這樣的資料)把這些東西全部能收上來。還包括像現在的一些可穿戴的裝置,去檢測你的健康資訊,也包括圖象的識別、錄影的分析,這些都是在現在這個時代大資料囊括的內容。
大家能感覺到,隨著大資料時代的發展,從1.0,2.0到現在3.0,它離消費者的距離是越來越近了,過去原來都是高高在上,資料結果都是在相關的企業決策者的眼裡,而現在其實我們都可以把它穿戴在身上,從手機上就能看到一些相關的資料的分析和相關的結果,整個資料對業務的影響力也是由弱慢慢變強,現在基本上如果一個企業沒有一個資料決策,這個企業很難去運轉。
從0到N——大資料時代企業劃分
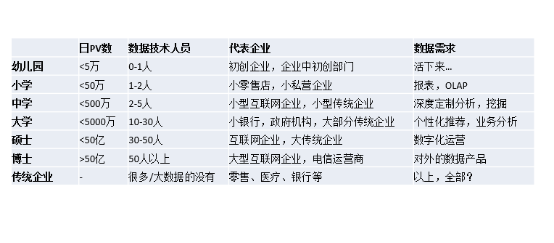
說過大資料時代的劃分,下面來給大家介紹下我定義的大資料時代的企業劃分,這裡面我做了一個小的比喻,我根據一個企業的數量量,然後根據它的技術人員的分佈,我去把它分成幼兒園、小學、中學、大學、碩士、博士等等。最後單獨拿一個模板給傳統企業。這裡面的提到的PV數,如果你不是網際網路的企業也沒關係,你可以用你的企業每天日增的資料的處理條數,因為資料量其實決定了企業的技術框架複雜度和你的處理的人員多少。這裡分別劃分了幾種:五萬、五十萬、五百萬、五千萬、五十億條,大於五十億條。資料技術人員的多少跟每一個企業發展階段都是有直接關係的,具體情況參見上圖,不再贅述。單獨把傳統企業拎出來,因為它稍微特殊,除了資料量的量級之外,傳統行業的技術人員做大資料的人一般都比較匱乏,現在像零售、醫療、銀行等等其實都是這個狀態,而它的資料需求特別多,既需要OLAP,又要做挖掘,還要做個性推薦,對資料還有做一些資料產品,想法非常多,我們到後面也討論一下,傳統企業做大資料的時候要注意什麼。
這個是我對不同資料階段的劃分,下面逐步介紹不同階段適合的框架。
大學之前的基本框架

先說說大學之前的框架,就是所有的這些資料處理的基本框架,在大學之前其實無外乎分為以下幾個模組:資料處理排程模組,資料展示工具,結構化資料儲存(非結構化處理後放入結構化儲存)。非結構化資料也可以用第三方的一些免費的分析工具,具體每個階段略有不同。
先說說大學之前的框架,就是所有的這些資料處理的基本框架,在大學之前其實無外乎分為以下幾個模組:資料處理排程模組,資料展示工具,結構化資料儲存(非結構化處理後放入結構化儲存)。非結構化資料也可以用第三方的一些免費的分析工具,具體每個階段略有不同。

先講講幼兒園階段,此時資料專職人員幾乎沒有,主要都是結構化的資料。結構化資料在這個量級的時候每天五萬條,用Mysql即可儲存,資料處理排程的時候,不用專門複雜的ETL工具,用Shell+JAVA處理即可(此時企業也沒有專職資料處理人員)。展示工具在這個階段的時候,不用買什麼工具,這裡我強烈推薦Excel,待會我給大家講講為什麼推薦它。對於非結構化資料,這個量級有很多第三方的免費工具,如果需要可以挑選一個使用。
幼兒園基本框架

Excel是小資料量最好分析工具
- 所見即所得。
- 產品使用方便,人員易上手
- 支援各種定製化展示
- 支援簡單的資料探勘
- 業務部門容易使用 無招勝有招 多少金融模型來自於Excel
為什麼推崇Excel?到目前為止,個人一直認為Excel是小資料量的最好的分析工具,沒有之一。第一,所見即所得,所有的資料處理和資料探勘工具沒有一個就像Excel一樣,簡單拖拖拽拽即可實現,旋轉透視表、關聯分析挖掘、或者回歸分析完全就在一個介面上就能處理好,沒有一個工具能比得上它。第二點是使用方便,人員易上手,對業務人員不用做什麼培訓,用Excel業務人員就能做出各種各樣的分析報表,非常高效。第三,支援各種個性化的展示。如右圖,在頁面上面能畫出來比較炫酷的這些圖,Excel基本都支援,包括支援地圖上展示熱區圖等,具體的方法,大家自行谷歌一下。第四,支援簡單的資料探勘。Excel支援大部分的基本資料探勘演算法,比如關聯分析,決策樹分類等,方法大家自行谷歌。 Excel我認為在資料量級不超過十萬條的時候是最好的分析工具。所以用Mysql把這個資料做一下彙總,Excel直接展示,這也是在幼兒園階段對你來講最好的一個分析框架了。有些人會說用Excel不是大資料,但是到現在為止,很多資料分析師還在用Excel,個人認為無招勝有招,不在乎工具是怎麼樣,而是在乎你背後分析思路和分析的經驗是如何。大家知道現在很多大家都說金融股票分析什麼這些都非常高深,用各種量化模型,但是大家知道,很多金融模型都是來自Excel的,對於最基本的分析工具Excel,我向大家強烈推薦一下,無論哪個階段一定要深學活用。
第三方分析——易觀方舟幫助你分析頁面流量
- 支援網頁和APP
- SDK只有66k
- 省去了各種資料加工的麻煩
- 基本指標一應俱全
- 目前開放的基本功能,永久免費
- 功能不斷在迭代
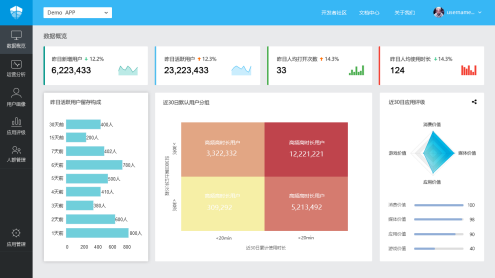
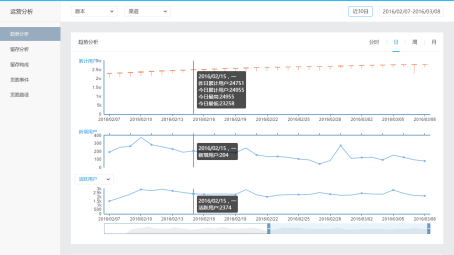
對於在這個階段,網際網路非結構化分析有很多像友盟和方舟這樣的免費分析工具。我在易觀就簡單說易觀的方舟,通過易觀的業界最小的SDK(Android只有66K)就可以看到各種基本的分析指標,儲存和處理都不用操心了。基本的這些指標一應俱全,而且永久免費,指標資料可以下載回本地,如果需要明細資料回傳服務也可以單聊。這個階段,最重要的是把企業把業務流程打通,先活下來,這是在幼兒園這個階段。

集美貌與智慧一身的“SQL Server”
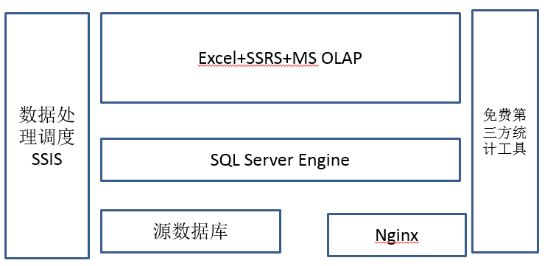
為什麼是SQL Server?
- 一個軟體覆蓋了這個階段資料處理的所有功能
- 支援各種資料來源的整合
- 支援ETL排程
- 支援報表展示
- 支援OLAP
- 資料量在幾億條之內(每天50萬,一年1.5億),查詢效
率OK,如果擴充套件cluster,支援更好。 小資料分析神器Excel,完美結合,擴充套件了資料探勘,展
現等功能缺點:資料量大以後,效率跟不上
在小學階段的企業基本上有一點資料了,每天大概有五十萬條這樣的資料,有一些資料的處理專職人員了,1到2個人。需要有ETL工具和一定資料量級的資料儲存。這個時候,向小企業隆重推薦一個繼承解決方案就是SQL Server。提到SQL Server其實也有很多人在鄙視,聽上去一點都不高大上,怎麼能叫大資料?但其實大家知道嗎?無論是現在已經火的京東,還是現在的美團,剛剛起步的時候都曾經經過SQL Server做資料分析的階段。我把SQL Server叫做“集美貌與智慧於一身”,為什麼這麼說?其實SQL Server其實是它目前唯一一款軟體,覆蓋了這個階段資料處理分析的所有功能,支援各種資料來源的支撐。因為企業在這個資料量級的時候,源資料庫有多個異構資料庫和異構資料來源,需要一個比較強大的ETL工具做集中資料儲存。在這個階段,可以利用SQL Server自身整合帶的一個東西叫SSIS,SSIS元件是一個簡化版的ETL處理工具,你購買了SQL Server,你不用再需要購買一個ETL工具。此外,SQL Server還整合SSRS,它是一個網頁報表系統,這個東西本身還支援OLAP引擎,你不需要再單獨買一套報表的展現工具,對於這個階段的企業來講,大部分需求也足夠使用。第四個是OLAP引擎,就是上鑽下鑽旋轉這些OLAP特性SQL Server全都支援,而且在資料量級在幾億條以內,資料查詢效率OK。當然,如果企業比較富裕,你去購買Cognos、Tablau這樣的產品的話,支援會更好一些。最關鍵的,完美結合剛才提到的小資料分析神器Excel。Excel直接連上SqlServer,那基本上就如虎添翼,原來Excel只能十萬條,SQL Server擴充套件到一億條。當然此時第三方的工具還可以繼續用,你用的像方舟這些繼續可以使。那方舟裡面,但這個階段除了剛才說PV、UV,現在可能就是分析一下這個頁面路徑了,就是這些人通過什麼樣的路徑點選進來,到你那觸達你的最終的購買路線的,這些人究竟它的轉化率怎麼樣。包括一些留存分析,就是哪些使用者是老使用者,這些使用者留存情況怎麼樣,是什麼活動促銷進來的等等。這個問題是在這個階段肯定有的,但是用的工具不一定是易觀的方舟也有其他的工具。

傳統資料倉儲+日誌分析工具
日增500萬,年度過5億以內,2-4個人,暫時還沒有人力搭建hadoop。
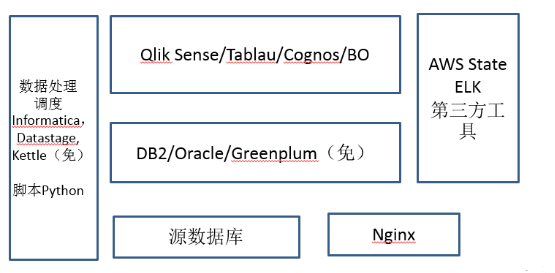
剛才講到了幼兒園小學,現在上中學了。為什此時我還在推薦商業元件而不是開源元件,是因為在此時,大部分企業還是以滿足企業內部需求為主,建立分析平臺的時間和效率往往比建立高大上的平臺有效切實的多,同時建立相關團隊也需要時間,使用商業元件可以提高整體的效率。在中學的時候,每日日增資料量基本上是五百萬量級,一般是小型的這些網際網路企業,或者小的傳統企業,此時,資料專職人員就有2到5個人了,這個資料量可能像一年下來可能要過十億條了,單機的SQL Server支援可能會有一些吃力。目前這個階段,我個人的建議還是你不要上Hapdoop這樣大的平臺,建立Hapdoop平臺一定要10人以上的團隊規模,這個其實是一個坎兒,在這個時間不要著急搭這種複雜的Hapdoop平臺,但是對於您目前的企業資料量來講,你需要一些專業的資料處理工具和展示工具了,就是你的小的企業可能剛才我說的SqlServer這個解決方案,已經不適合你了。那一般現在都有哪些?像資料處理排程的時候,因為剛才我提到說,SqlServer它自己整合,但是目前處理到SSIS,肯定是不能夠完全滿足你的要求了,於是就有比較專業的資料處理工具,有兩個比較商業上過去用的非常有名的,一個叫Informatica,另一個Datastage,這兩個其實都能滿足大部分的企業的資料處理的排程的需求,現在大部分銀行也在用。當然今天我們追求價效比,所以我給大家介紹常用開源的工具,叫做Kettle,目前大部分中小公司Kettle用的其實還是最多的,因為它的功能比Informatica、Datastage相比肯定要弱一些,但是比SSIS來講還是要更強一些,而且現在Kettle還支援了Hadoop、Spark等等任務排程和監控,還是擴充套件性在這個階段挺強的工具。
資料儲存在這裡也有一個升級,原先的儲存在這個資料量級每年在15-20億條,此時需要更大型的資料儲存,比如說DB2、Oracle,這兩個都是商業的,就是現在目前也是過去在商業資料倉儲驗證比較好的。我們追求價效比,也可以用去年開源的Greenplum。GP其實在大資料行業裡面還挺有名的,去年年底實現開源免費使用。GP是在上百億資料量級裡面,唯一一個MPP架構且開源的資料儲存平臺,它的處理效率和DB2、Oracle一點不落後。在展示方面,隨著業務量的增加,需求越來越多,也需要一些單獨的查詢展示工具。在這個環境下,資料量有一定資料量級了,但你的人不多,做自己的一些查詢工具可能還不行,你方式是買一些商用的工具來去做一個過渡,所以我在這裡推薦幾個現在比較火的。Qlik Sense/Tablau這兩個我用過都還不錯,屬於新一代的展現工具,當然還有老牌的Cognos和BO等表現都中規中矩,建議展示工具和業務需求部門一起評審,選一個合適的即可。選擇合適的展示工具可以節約建立大資料平臺的大量時間。
開源的ELK——簡易日誌分析平臺
ELK
- Logstash
- ElasticsSearch
- Kabana
優點
- 搭建簡易
- 迅速滿足日誌分析需求
- 自身具有多種展示方式
缺點
- 功能單一,只針對日誌
- 擴充套件性不強
在中小學的時候,非結構化資料可以通過程式轉換為結構化資料再存入傳統結構化資料資料庫的同時使用第三方免費工具來分析處理。在這個資料量級的時候,你會發現很多臨時性的新需求,第三方免費的這些工具不夠用,這時候ELK就派上用場了,ELK,就是Logstash、ElasticsSearch、Kabana縮寫。在這個時間點,其實如果你想要自己一些自主的,這種非結構化的日誌類的分析,可以使用ELK分析。
在這個時候如果你的公司還沒有使用Python處理資料的話,一定要求你的技術人員開始使用Python,前面其實都沒有單獨對資料處理的語言對大家做限制,特別人比較少的時候,在這個時間點,一定需要讓你的人員從JAVA轉到Python去。Python有幾個這樣的好處,第一資料處理簡潔明快,比Java針對資料開發效率高很多。過去有一個語言叫做Perl,現在Python已經取代了Perl的地位,成為一個資料處理的一個必會的語言。第二個好處是Python各種資料來源和各種環境都支援,它的延展性特別高。第三個是Python支援各種資料探勘的演算法庫,基本上各種在Python的這種庫是最多的,甚至比JAVA還多。第四個是支援各種流式計算系統的框架,就是你將來學了Python以後,你可以順利地從中學上大學。所以在這個階段,我建議每一個企業在這個時候,去把Python指令碼用起來。
第三方免費分析——易觀方舟的使用者畫像
- 人口屬性:裝置群體特徵
- 使用型別:都是使用什麼型別的應用
- 使用型別時段:什麼時間使用什麼型別的APP
- 使用關聯分析:從哪裡來,到哪裡去
- 使用者偏好:使用者標籤
當然,在這個階段,第三方的資料平臺依然可以幫你做一些事情,比如說方舟的使用者畫像。因為這些功能的背後需要有大量的資料和大量的資料分析演算法,來幫助你的企業告訴你,你的客戶它的裝置群體是什麼樣的,他們是在使用什麼樣型別的應用,這些應用在什麼時間段怎麼使用。也能告訴你做一些關聯分析,就是你這個客戶在使用應用之前,他從哪裡來到哪裡去,還給你很多的一些使用者標籤。這些其實是你在用ELK,這些統計的東西都是沒有的,目前這個功能也是免費對外開放的,大家歡迎去使一下。

開源平臺的引入與資料治理的加強
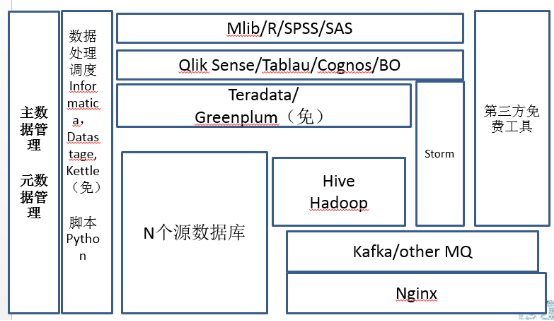
上完中學以後就要上大學了,包括小銀行、政府機構、大部分傳統機構,這個裡面它要求的東西就更多了。上大學以後,系統的結構一下就變複雜了,為什麼?除了非結構化資料的處理之外,在這個時候有兩個非技術模組很重要,一個叫做主資料管理,一個叫做後設資料管理,所有在這個階段的企業都做了類似這樣的專案。主資料是什麼?在企業裡面,各種各樣的系統裡面都有各種各樣的資料,對於某些特殊的資料的標準資料就是主資料。舉個例子,客戶資訊。你可能有CRM裡面有,ERP裡面有,可能生產排程系統裡面有,可能銷售的APP裡面也有,你的網站上面也有。對於每一個客戶來講,誰作為唯一確定的資料做黃金拷貝?這就是主資料管理的意義,你一定把主資料儲存獨立儲存,業務流程發生變更的時候,哪個系統有許可權去改主資料,是非常重要的,否則最後客戶的電話號碼天天變來變去,你也不知道它哪個是最終有的有效資料。所以在這個時間點你一定要做一個主資料的管理。第二個後設資料,後設資料的管理,到這個階段以後,表、儲存特別多了,這些資料怎麼能有效的管理。例如,後設資料當中的血緣分析,就是你這個表它的資料從哪裡來,到哪裡去,這個資料怎麼最後變成了指標展現出來,指標發生資料問題的時候,哪些資料處理過程可能存在一些故障可能,這些東西其實是在這個階段做的。
在這個階段開始要做真的開源平臺的引入了,開源平臺的引入和資料治理的加強,導致你的人員迅速地擴張。第一個這裡面引入了Hadoop,Hadoop我目前建議你還是先用Hive先用用,逐步轉為Map Reduce非結構化處理,通過Kafka,接入Storm也可以使用實時地流式計算,通過Storm直接反饋到前端的展現工具。在這個資料量級的時候,每天五千萬條左右的結構化資料的處理量,可以使用開源的Greenplum或者商業化的Teradata。Teradata目前還是在MPP架構業界最快的,但是賣的也是最貴的。展現工具,企業依然可以去買第三方工具,自己不用去開發。此時的企業,資料探勘的需求越來越多,使用資料探勘工具的時候,原來做的一些簡單的像Excel這樣的工具已經無法滿足個性化推薦、協同過濾這些演算法了。挖掘工具可以在R SPSS、SAS、或Mlib庫選一個。Mlib是Spark中的資料探勘庫,功能強大,處理速度快。不過此時我還不建議企業著急上Spark,因為大部分這些企業大資料投入還是有限的,Spark的使用會給人員帶來新的需求。如果人員有限,那麼可以選擇商業的資料探勘工具,如果人力比較富裕,可以使用開源的R結合python相關挖掘的類庫,能解決企業大部分的挖掘和推薦需求。這個時間點上有一個特點就是在大部分的這個企業處理的時候,大部分資料還是將非結構化資料處理之後,變為結構化資料再做相關處理,哪怕經過了MapReduce,經過挖掘線上模型,最終的資料還會回到這種結構化的資料庫裡面再去使用。或者有小部分地流式實時資料處理來做展示。絕大部分資料儲存還不是放在Hive和Hapdoop裡面的,你的大部分的資料其實還是在結構化的資料裡面。因為你的人員在這個階段,其實還是結構化資料處理人員比非結構化資料處理人員多,你的業務需求也是結構化資料需求最多。
中流砥柱——Kafka/HDFS/Hadoop/Hive
最皮實的組合
- 魯棒性
- 硬體相容性
- 資料處理穩定性
每個系統大資料儲存,都繞不開
缺點:慢!
分開來講,Kafka/HDFS/Mapreduce/Hive,我把它叫做最皮實的大資料組合,原因有幾個:第一就是穩定,無論你現在用的是Cloudera 還是Hortonworks,其實讓你的開發人員去安裝一套,安裝配置的時候可能中間有一些坑,但是你只要把它安上去轉起來一次以後,那後面基本上它的大部分問題幾乎就沒有了。不會像其他平臺,在執行時有時候會有一些詭異的問題。它的相容性也比較強,就是無論好硬體差硬體,它都能跑起來。資料處理的穩定性,資料處理是非常穩定的,你不用擔心資料量徒增會出什麼問題。所以現在目前為止,每一個大資料的儲存都繞不開這個組合。缺點也很明顯,就是慢。這個東西它是不會記憶體爆掉,不會當機, 但是它轉起來真的很慢,你想讓它跑快起來,這個事其實挺難的,因為這個整個結構其實就不是那樣的結構,經常你查一個SQL下去,你看著它先做map,然後再做reduce可能半個小時過去了。
貴族的開源——Greenplum
- MPP架構,查詢速度很快!
- 大資料量SQL查詢,除了Teradata,商業化使用最多
穩定性強
GPDB目前使用最多,HAWQ支援HDFS是未來
缺點:吃硬體,萬兆、多SAS盤、伺服器很貴…
剛才我提到了Greenplum, Greenplum這家公司其實也是一家老牌公司了,它其實現在有兩個開源的版本,一個以GPDB為核心,一個以HAWK位核心。GPDB是現在目前使用最多一個查詢的引擎,廣泛應用於銀行、電信等等很多的領域裡面,其實都是用了GPDB的SQL的查詢比較多。HAWK是新版的GP儲存引擎,現在支援HDFS,簡單來講它是底下儲存換為HDFS,它本身的查詢計劃和優化還是用的GP的這一套東西,所以它的速度基本上和GPDB是相同的,只不過現在剛剛推出來,還需要一些時間驗證和推廣。但是整個趨勢來看HAWK是未來,因為它支援的HDFS,對於資料的匯入匯出,磁碟的冗餘替換都是非常有利的。易觀作為GP開源以後第一個使用開源版本儲存處理大量資料的企業(日處理量在100億條左右),我們也遇到了一些坑。但是給我們帶來的優勢是查詢速度非常快,同樣的結構化資料的查詢,不誇張的講Hive需要1小時,GP 1分鐘就可以算出來。目前來講GP其實商業化用的是最多的,穩定性也是非常強,在大資料的類SQL這個領域裡還是比較好用的。當然,它也有缺點,就是非常吃硬體。普通的開源軟體我叫做屌絲開源,一般對硬體要求不高,而GP我管它叫貴族開源,它對網路和磁碟的IO要求極為苛刻,一旦你的網路和你的磁碟IO沒有配置均衡有效的時候,它會經常出現一些詭異的問題。所以基本的配置,單光口萬兆是最最基本的,沒有這個硬體投入你就不要想用GP了,一般它推薦的是雙萬兆卡,就是一定要有光交機,兩個萬兆給它,每一個機器的磁碟很多的SAS盤。所以,它要求的硬體,包括整個的伺服器,那你伺服器本身主機板其實這些要求全都規格都上去了。但是企業結構化資料到一定資料量級的時候,還是可以選它的,個人認為它還是比較靠譜的。
易觀方舟的轉化分析與應用評級
看自己產品轉化
- 營銷活動是否高轉化為下單支付?
- 行業平均轉化率如何?
- 什麼渠道使用者分享與傳播多?
看行業均值、TOP10
- 市場是否已被領頭羊蠶食?
- 長尾幾無生存空間?
看自己評級
- 易觀給你的第三方的評估
當然在這個階段,第三方的平臺依然可以給你一些幫助。例如,幫助你看你企業從廣告到瀏覽到下單,轉化率是如何的?行業均值差多遠?這些易觀都一些分行業的分析模板,只需要你簡單的做一些資料嵌入即可。能看看行業趨勢是怎麼樣,你自己看看這個行業的TOP10是怎麼樣。你的市場已經被領頭羊吃掉了,或者你自己生存空間怎麼樣。再看看你在這個行業裡排行如何?有沒有一些新的缺口?另外易觀給你做一個第三方的評估評級,給你的投資看下你的使用者的價值有多大。這些基本功能都是永久免費的,而將來基於這些基本功能的擴充套件分析是要收費的。

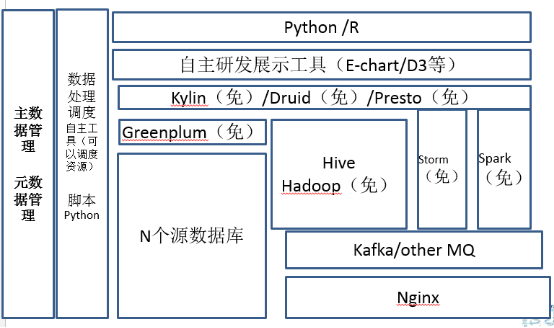
那剛才講完大學了,現在開始上研究生了,研究生每天的資料條數少於五十億,那現在到了這個量級的時候,基本上專職人員是30到50人了,這個時候關鍵詞就是一個字,開源。為什麼?在這個量級的時候,如果你不去用一些開源的一些工具投入已經超過了你對於人員僱傭的投入費用。那對於這個階段來講,除了Hadoop系列,會引入Spark、麒麟、Presto、Druid這樣的資料處理和儲存平臺。研發工具基本上原來的商業工具肯定是無法滿足需求了,可以引用百度的E-Chart或者D3。他們之間各有千秋,但是我是支援國產的開源的,所以我選了echarts。
資料量增加、實時計算的引入導致全面開源化
記憶體計算的翹楚——Spark
- 目前最火的大資料開源專案
- 華人貢獻佔52%
- 大資料下資料探勘必選項SparkR
- 即使使用磁碟,執行效率優於Hive幾倍
研究生大資料必修課
- 缺點:如果達到很高效,硬體要支援
- 資料量比較大,節點比較多,對Scala要求比較高
先說Spark,目前最火的大資料開源專案。它的開源的火爆程度目前超過了Hadoop一倍可能還得多,而且華人在裡面貢獻的人名數超過50%以上。在這個資料量級,會有大量的資料探勘模型和處理的需求,而Spark對於迭代式的資料探勘,特別大資料量的處理的時候。同時,它的記憶體計算及相關框架效率是Hadoop執行效率的幾倍,所以在研究生階段,大資料必修課就是Spark。但缺點也挺明顯,就是如果你想達到它的高效,因為它就是記憶體的計算,硬體整體環境需要支援。就是也許你現在不用萬兆,那你也得用雙網路卡或者四網路卡捆綁,你的網路IO得有保證,你的記憶體和CPU得能上來,這兩個是你在Spark的時候必用的。另外,大家知道Spark是用scala做的,你對scala的要求就比較高了,因為你結點多的時候,這點或者那點總有點小問題,所以研發的技術人員必須得對scala比較熟悉,可以簡單除錯相關的問題。相對於Hadoop,Spark穩定性還在逐步加強,它在流程裡會有一些小的bug出來,因為它雖然很火,但是它還會有各種各樣的小問題,需要你去修修補補的。所以這個是你在研究生的時候你再去學。
OLAP的利器——Kylin
- 解決了大資料多維度查詢速度慢,多維查詢資料返回丌及時的問題
- 開源MOLAP利器
- Apache金牌專案
- 源自Ebay內部大資料
- 利用Hbase,加速可以加速Hbase
中國人自己的開源專案!
- 缺點:預計算時間比較長
麒麟源自於e-Bay,現在它單獨從e-Bay獨立出來了,那它是Apache的金牌開源專案。麒麟是開源的MOlap的利器,解決了大資料多維查詢速度慢,多維查詢的反饋不及時的問題。目前麒麟底層主要是利用Hbase去做儲存和查詢,所以你要去想加快麒麟的速度的話,可以用增強磁碟和網路I/O的方式處理。麒麟目前國內很多大牌的地方也都用過了,包括像騰訊,美團都有使用,現在有很多經過實際的一些經驗,它是OK的。最重要的一點,它是中國自己開源的專案,中國人自己的,所以大家一定要支援它。但是麒麟也有它的缺點了,就是它的預載入時間比較長,因為它是用空間換時間的。在大資料架構裡,展示的時候如果想看到資料怎麼上鑽下鑽,然後做一些查詢,麒麟作為國產的開源的這樣一個軟體,我覺得還是強烈推薦的,這個大家可以去使用。
OLAP的生力軍——Druid
- 解決單表大資料查詢問題
- 支援實時增量的聚合
- 不支援查明細
正準POC,不亂評價
開源負責人是華人
- 缺點:未知,正在準備試用
Druid是最近比較火爆的查詢平臺,最近群裡也一直在討論,我正在做POC,暫時還不評論。試用以後再給大家做一個反饋。
內部SQL查詢工具——Presto
- Facebook開源記憶體SQL查詢
- 可以跨mysql,Hadoop, cassandra查詢
- 查詢效率進高於Hive
SQL支援比較好
缺點:記憶體吃的很厲害,而且大查詢出現詭異的異常
- 目前易觀用作內部查詢使用
Presto其實Facebook開源的,是一個記憶體式計算的框架,它比較牛的地方,它是一個能夠跨Mysql跨Hadoop,跨cassandra的查詢。支援跨庫查詢,可能主資料在Mysql,行為明細在Hive,使用者標籤在cassandra,一個語句可以解決所有問題。這件事情還是很牛逼的,但是現在它要支援很多新的資料庫的Adapter,但是據說新的adapter要收費,查詢效率也高於原生的Hive。我們原先也用 presto,美團也在使用。但是Presto的缺點也挺明顯,就是如果你數量不大的時候,原來我們拿presto串到整個資料處理流程也很好。但缺點也很明顯,Presto記憶體吃的很厲害,如果資料量級比較大的的查詢(超過20億左右,根據叢集大小不同),就會出現很詭異的異常,而且每次異常的點都不一樣。所以在這個情況下,就是我們現在易觀拿它做內部查詢使用,就是你不能把它串到資料處理流程裡。

對開源平臺的修改、對硬體的定製要求
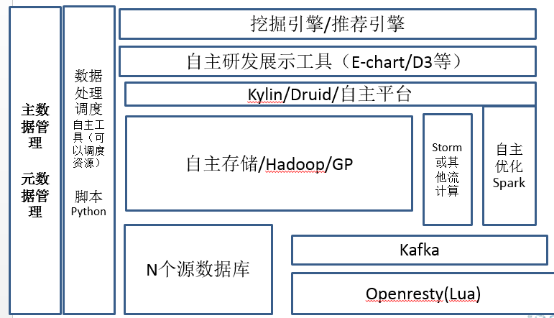
到博士生了,更多的技術人員集中到演算法層面,例如像知識庫或者知識圖譜的建立,或者線上推薦引擎和搜尋優化這樣。大資料平臺方面,其實每個不同的這個地方,其實都不太一樣。這個階段每個公司都是自主的一些儲存了,包括ETL的工具。在這個階段原先免費開源的ETL排程工具都不行了,這個工具需要結合任務去動態調整資源,像易觀自己做的EAMP,或者我在萬達時候e-horse,除了你排程ETL流程之外,因為你的資料量很多了,它得能夠去調動你的Hadoop的這些資源並處理一些特殊的業務情況。大資料儲存的時候在此時各顯神通,這個時候真的沒有一個統一地說完整的解決方案。這裡稍微提一點優化,就是需要將大資料分段處理了。因為這麼大量的資料,如果直接扔到後臺叢集,叢集壓力會超大,價效比也不是最高。所以在這裡舉例,在網際網路資料接收的時候,就開始做資料處理。例如,利用Lua在openresty去處理髒資料,分段優化整體的大資料處理流程。在這個階段,基本上所有的這些博士生的企業,都有修改開源平臺的能力,你的團隊得能去修理開源的平臺解決相關的問題。
價效比最高的定製化硬體
大資料叢集要什麼?不同場景不同
批量計算——高價效比的I/O,網路I/O,磁碟I/O
- 磁碟I/O,SSD?量大了用不起。
- 多磁碟,組Raid
- 網路I/O,光纖萬兆?價效比丌吅適
- 多網路卡捆綁,4塊放一起
實時計算——網路 I/O,CPU
- 大記憶體
- 萬兆
- 高CPU
- 磁碟?SSD,必須的
同時,你要對硬體做一些定製,就是如果你真的想做價效比最高,原來成型的這些機器不太好使了,其實有很多東西你得去配置什麼要下一些功夫。大資料叢集需要什麼?就是不同場景,不太一樣。批量計算,批量計算像Hadoop或者presto主要是高價效比的IO,指的是網路的IO,磁碟的IO。如果真的想框架不變,速度提升優化50%、70%,你想通過優化Hadoop這些優化,我覺得基本不太可能,你直接升SSD硬碟才是解決方案。如果價效比比較高的方案,優選的就是磁碟特別多的機器,在這個時候你去買更多的盤,比如說你的機器支援16塊盤,把這16塊盤,如果HDFS倍數是3的話,你組三個Raid,去處理,比你用8塊盤的機器用羅裸快得多。磁碟IO這件事是我覺得第一個優化的。
第二個網路IO,網路IO,我們要高價效比,網路IO萬兆當然是最好了但是價效比其實不合適,其實現在很多的這種多網路卡捆綁的方案了,就是你買四塊網路卡,費點交換機,你把四塊卡綁一起,其實它這個速度,雖然不是×4,但是基本上×2×3還可以。所以在這個時候也是一個廉價的解決方案,所以你的Hadoop叢集在配的時候,你就用這種多磁碟,多網路卡,CPU要不要高?其實我覺得不用。就是大部分的Hadoop出現的問題都不用在CPU上,都是在磁碟和網路IO上面的,就是你在這兩個IO上面提上去,你的查詢效率會高很多,而且也不用花太多錢。
對於時時計算來講,這個事其實如果你真的想做得比較好,那麼主要是網路IO和CPU,記憶體一定要大,你的網路,我覺得像GP、Spark這些你要想把它轉得非常好,速度非常快,那你還是上萬兆吧。如果你要想便宜的話,你就用四塊網路卡去捆綁,CPU,因為這個時候其實它是記憶體之間的互動,CPU如果不夠高,那你最後CPU就有瓶頸,磁碟直接上SSD即可,現在目前其實你要想定製比較價效比高的這些硬體,其實主要還是回到它原來處理平臺的時候,需要IO,需要CPU還是需要網路,從這幾個角度來看,不同場景其實還是不太一樣的。
當然,其實剛才講了一堆開源的工具,我們也在做一些有趣的測試,就是拿我們現在易觀處理完的,比如說一天大概五十億條的資料,拿這個資料做一下評測,在不同場景下,每個查詢效果怎麼樣,這個事其實我們現在正在做POC,做完以後,下次分享的時候,也跟大家去聊一聊。
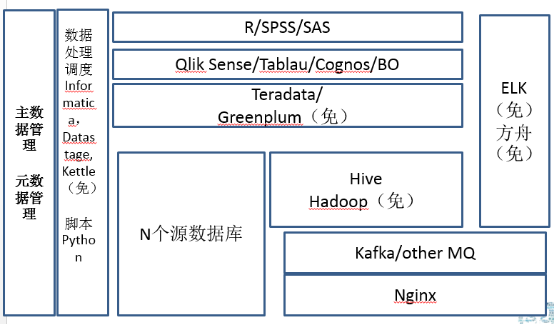
剛才也說了各個不同的,從幼兒園到博士生,其實跨度還是挺大的,講的從一開始的Mysql到最後整個完整的一個大資料平臺。傳統企業比較特殊,就是它大部分資料都是結構化資料,技術人員基本上不是特別多,要麼就是外包,要麼是自己內部人員。但大資料的這些演算法和大資料的非結構化的處理比較少。我這裡面關鍵詞其實就是建議傳統企業還是先建一個資料倉儲,然後把少量的非結構化的處理放到結構化裡面。
傳統企業模板
大資料雲化的觀點
大資料雲化是趨勢
小公司,全面雲化,借劣第三方雲化解決方案,端到端解決問題
- 核心資料選一家大的(阿里、騰訊、Ucloud等)
- 周邊方案丌一定只一家(多選幾家功能觸達為主)
大公司,大資料混吅雲是當前的最佳實踐
- 大資料叢集自主
- 相關元件不產品雲化
最後說說,大資料和雲化的問題。各家雲都上了各種大資料元件,這個東西可不可用?好不好用?該不該用?我的觀點是這樣的,就是大資料是雲化是未來的趨勢。目前在國內,如果你是小公司,那你就全面雲化吧,那借助第三方的雲化的解決方案,端到端解決問題,比如阿里、騰訊、Ucloud等等這個就不列了,這個感興趣大家可以看易觀的分析報告。周邊端到端的資料分析服務雲就不一定選一家,哪家能用它的一個優化的方案來解決你用哪家,對於移動網際網路來講,你可以選易觀,當然你也可以加上其他的友商,在這個階段對於中小公司來講,這就可以了。對於大公司來講,目前現在最佳的方案是混合雲,最終落到還是一個混合雲的方案。是為什麼?就剛才提到,大資料叢集從價效比來講,從穩定性來講,公有云都還有一段路要走。大資料叢集可以在自己的私有云裡面,那麼你的相關的這些產品可以放到公共雲上。
2016年8月12日-13日,由CSDN重磅打造的網際網路應用架構實戰峰會、運維技術與實戰峰會將在成都舉行,目前18位講師和議題已全部確認。兩場峰會大牛講師來自阿里、騰訊、百度、京東、小米、樂視、聚美優品、YY互娛、華為、360等知名網際網路公司,一線深度的實踐,共同探討高可用/高併發/高效能系統架構設計、電商架構、分散式架構、運維工具研發與實踐、運維自動化系統的構建、DevOps、雲上的運維案例分析、虛擬化技術、應用效能檢測與管理、遊戲行業的運維實踐等,將和與會嘉賓共同探討「構建更安全、更高效能、更穩定的架構和運維體系」等領域的話題與技術。【八折優惠中,點選這裡搶票,欲購從速。】
相關文章
- 易觀CTO郭煒:從0到N,建立高價效比大資料平臺大資料
- 從0到1搭建DeltaLake大資料平臺大資料
- 回顧·大資料平臺從0到1之後大資料
- 免費的雲渲染平臺有哪些?哪些平臺價效比較高?
- 論價效比,這家奧威BI大資料分析平臺很能打大資料
- 五個篇章講明白如何從0到1搭建大資料平臺大資料
- 華為雲大資料BI 解決方案的超高價效比大資料
- DNSLOG平臺搭建從0到1DNS
- 從0到1搭建自助分析平臺
- 2500元左右高價效比遊戲主機配置推薦 Intel與AMD雙平臺遊戲Intel
- 大資料治理平臺有哪些價值大資料
- 從linux平臺移值資料庫到windows平臺Linux資料庫Windows
- 如何選擇高價效比的報表工具
- 汽車之家資料庫服務化平臺從0到1的實踐過程資料庫
- 從難以普及的資料增強技術,看AI的價效比時代AI
- TURTLEBOT3 Burger 漢堡式堆疊平臺 好價格 價效比之王!
- 聯童科技基於incubator-dolphinscheduler從0到1構建大資料排程平臺之路BAT大資料
- 事實證明,國產BI軟體的財務資料分析價效比極高!
- 某二手交易平臺大資料平臺從 0 到 1 演進與實踐大資料
- 八月裝機高價效比主機板推薦 Intel和AMD雙平臺任選Intel
- CDGA|從平臺自治到規範化的資料治理
- 全A平臺筆記本開賣,玩家:毫無價效比定價太膨脹筆記
- 打造價效比3A平臺 CSOL2激戰正酣全體驗
- 編寫一個對n個資料從大到小的排序C…排序
- 資料平臺、大資料平臺、資料中臺……還分的清不?大資料
- 從0到1,資料治理一週年大紀實
- 從0到1,成為大資料行業領袖大資料行業
- trac 平臺從 PG 資料庫轉到sqlite 的指令碼。資料庫SQLite指令碼
- 資料湖+資料中臺,金山雲大資料平臺如何攻克資料價值落地難關大資料
- 工業大資料分析平臺的應用價值探討大資料
- 日媒披露:為什麼廉價智慧手機如此高價效比?
- 從“大資料”到“厚資料”大資料
- Litebook釋出高價效比筆記本Alpha Litebook筆記
- 大資料治理——搭建大資料探索平臺大資料
- 剖析大資料平臺的資料處理大資料
- 小專案從0到1之跨平臺方案選型
- 中原銀行如何從0到1建設敏捷BI平臺?敏捷
- CMR:印度高價效比智慧手機市場調查