推薦演算法概覽
原文: Overview of Recommender Algorithms
作者: MAYA.HRISTAKEVA
譯者: 孫薇
責編: 錢曙光,關注架構和演算法領域,尋求報導或者投稿請發郵件qianshg@csdn.net,另有「CSDN 高階架構師群」,內有諸多知名網際網路公司的大牛架構師,歡迎架構師加微信qshuguang2008申請入群,備註姓名+公司+職位。
推薦演算法概覽(一)
為推薦系統選擇正確的推薦演算法非常重要,而可用的演算法很多,想要找到最適合所處理問題的演算法還是很有難度的。這些演算法每種都各有優劣,也各有侷限,因此在作出決策前我們應當對其做以衡量。在實踐中,我們很可能需要測試多種演算法,以便找出最適合使用者的那種;瞭解這些演算法的概念以及工作原理,對它們有個直觀印象將會很有幫助。
推薦演算法通常是在推薦模型中實現的,而推薦模型會負責收集諸如使用者偏好、物品描述這些可用作推薦憑藉的資料,據此預測特定使用者組可能感興趣的物品。
主要的推薦演算法系列有四個(表格1-4):
- 協同過濾(Collaborative Filtering)的推薦演算法
- 基於內容過濾(Content-based Filtering)的推薦演算法
- 混合型推薦演算法
- 流行度推薦演算法
此外,還有很多高階或非傳統的方式,可參見表格5。
本文是系列文中的第一篇,將會以表格形式來介紹推薦演算法的主要分類,包括演算法簡介、典型的輸入內容、常見的形式及其優劣。在系列文的第二與第三篇中,我們將會更詳細地介紹各種演算法的不同,以便讓大家更深入地理解其工作原理。本文的某些內容是基於一篇2014年的推薦演算法2014教程《推薦問題再探(Recommender Problem Revisited)》來撰寫的,該文的作者是Xavier Amatriain。
表格一:協同過濾推薦演算法概覽

表格二:基於內容過濾的推薦演算法概覽

表格三:混合方式的推薦演算法概覽

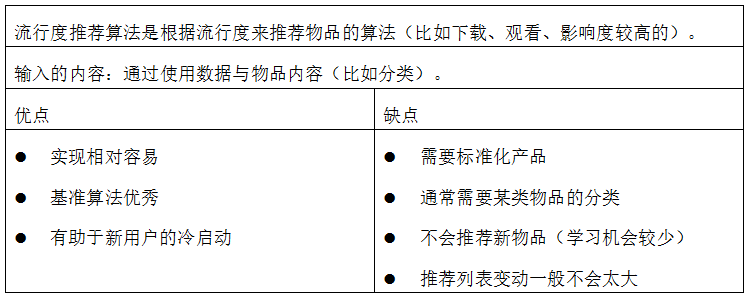
表格四:流行度推薦演算法概覽
表格五:高階或“非傳統”推薦演算法概覽

推薦演算法概覽(二)
本文是系列文中的第二篇,將會列出推薦演算法的備忘列表,介紹推薦演算法的主要分類。在本文中,我們會更詳細地介紹協同過濾推薦演算法,並討論其優劣,以便大家更深刻地理解其工作原理。
協同過濾(CF)推薦演算法會尋找使用者的行為模式,並據此建立使用者專屬的推薦內容。這種演算法會根據系統中的使用者使用資料——比如使用者對讀過書籍的評論來確定使用者對其喜愛程度。關鍵概念在於:如果兩名使用者對於某件物品的評分方式類似,那麼他們對於某個新物品的評分很可能也是相似的。值得注意的是:這種演算法無需再額外依賴於物品資訊(比如描述、後設資料等)或者使用者資訊(比如感興趣的物品、統計資料等)。協同過濾推薦演算法可分為兩類:基於鄰域的與基於模型的。在前一種演算法(也就是基於記憶體的協同過濾推薦演算法)中,使用者-物品評分可直接用以預測新物品的評分。而基於模型的演算法則通過評分來研究預測性的模型,再根據模型對新物品作出預測。大致理念就是通過機器學習演算法,在資料中找出模式,並將使用者與物品間的互動方式模式化。
基於鄰域的協同過濾則著眼於物品之間的關係(即基於物品的協同過濾)或者使用者之間的關係(基於使用者的協同過濾)。
基於使用者的協同過濾是探索對物品擁有相似品味的使用者,並基於彼此喜愛的物品來進行互推。
基於物品的協同過濾是使用者喜愛的物品,推薦類似的東西。而這種相似性建立在物品同時出現的基礎上,比如購買了x物品的使用者也購買了y物品。
首先,在執行基於物品的協同過濾前,我們先看一個基於使用者的協同過濾案例。
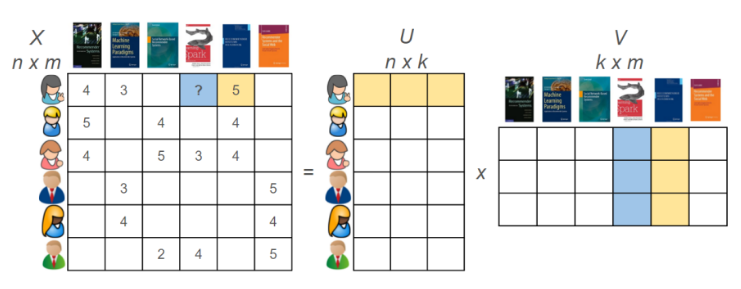
假設我們有一些使用者已經表達了他們對某些書籍的偏好,他們越喜歡某本書,對這本書的評分也越高(評分範圍是1分到5分)。我們可以在一個矩陣中重現他們的這種偏好,用行代表使用者,用列代表書籍。
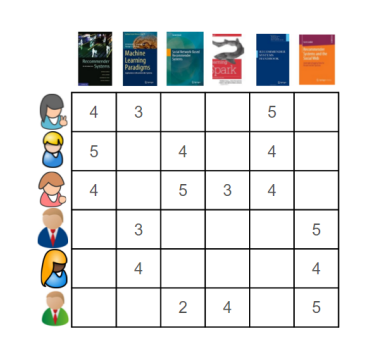
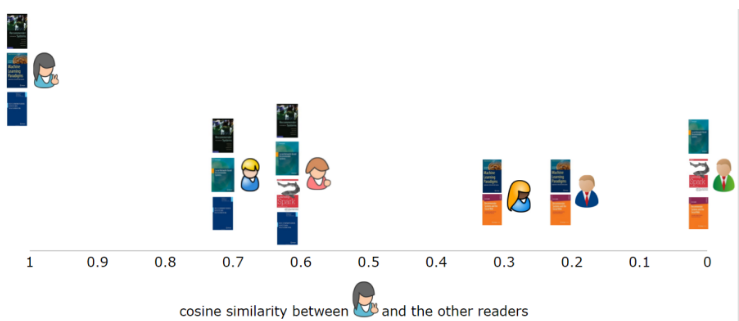
在基於使用者的協同過濾演算法中,我們要做的第一件事就是根據使用者對書籍的偏好,計算出他們彼此間的相似度。我們從某個單獨使用者的角度來看一下這個問題,以圖一中第一行的使用者為例。通常我們會將每個使用者都作為向量(或者陣列),其中包含了使用者對物品的偏好。通過多種類似的指標對使用者進行對比是相當直接的。在本例中,我們會使用餘弦相似點。我們將第一位使用者與其他五位相對比,可以發現第一位與其他使用者的相似度有多少(圖二)。就像大多相似度指標一樣,向量之間的相似度越高,彼此也就越相似。在本例中,第一位使用者與其中兩位有兩本相同的書籍,相似度較高;與另兩位只有一本相同書籍,相似度較低;與最後一位沒有相同書籍,相似度為零。
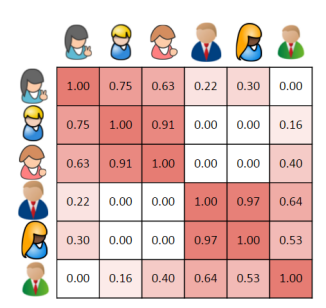
更常見的情況下,我們可以計算出每名使用者與所有使用者的相似程度,並在相似性矩陣中表現出來(圖三)。這是一個對稱矩陣,也就是說其中一些有用的屬性是可以執行數學函式運算的。單元格的背景色表明了使用者彼此間的相似程度,紅色越深則相似度越高。
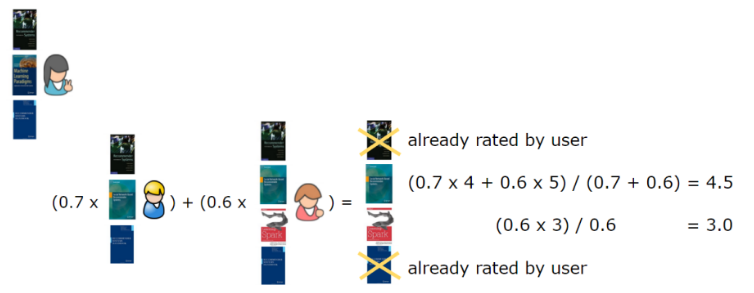
現在,我們準備使用基於使用者的協同過濾來生成給使用者的推薦。對於特定的使用者來說,這代表著找出與其相似性最高的使用者,並根據這些類似使用者喜愛的物品進行推薦,具體要參照使用者相似程度來加權。我們先以第一個使用者為例,為其生成一些推薦。首先我們找到與這名使用者相似程度最高的n名使用者,刪除這名使用者已經喜歡過的書籍,再對最相似使用者閱讀過的書籍進行加權,之後將所有結果加在一起。在本例中,我們假設n=2,也就是說取兩名與第一位使用者最相似的使用者,以生成推薦結果,這兩名使用者分別是使用者2及使用者3(圖四)。由於第一名使用者已經對書籍1和書籍5做出了評分,推薦結果生成書籍3(分數4.5)及書籍4(分數3)。
現在我們對基於使用者的協同過濾有了更深刻的理解,之後來看一個基於物品的協同過濾的案例。我們還是用同一組使用者(圖一)為例。
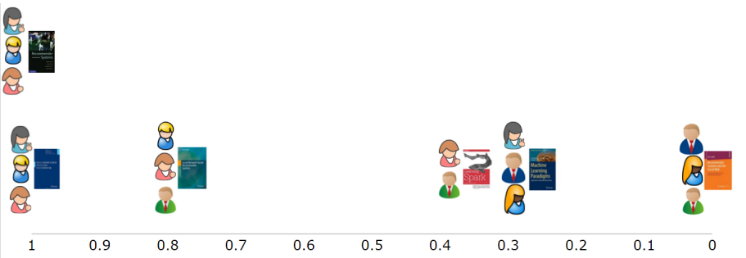
在基於物品的協同過濾中,與基於使用者的協同過濾類似,我們要做的第一件事就是計算相似度矩陣。但這一回,我們想要針對物品而非使用者來看看它們之間的相似性。與之前類似,我們以書籍作為喜愛者的向量(或陣列),將其與餘弦相似度函式相對比,從而揭示出某本書籍與其他書籍之間的相似程度。由於同一組使用者給出的評分大致類似,位於列1的第一本書與位於列5的第五本書相似度是最高的(圖五)。其次是相似度排名第三的書籍,有兩位相同的使用者喜愛;排名第四和第二的書籍只有一位共同讀者;而排名最後的書籍由於沒有共同讀者,相似度為零。
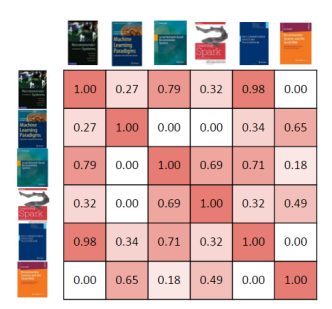
我們還可以在相似矩陣中展示出所有書籍彼此間的相似程度(圖六)。同樣以背景顏色區分了兩本書彼此間的相似程度,紅色越深相似程度也越高。
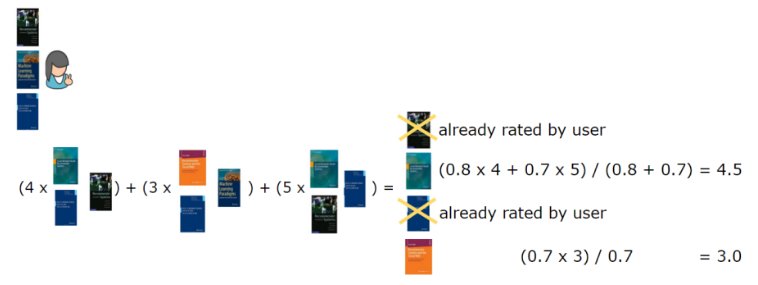
現在我們知道每本書彼此間的相似程度了,可以為使用者生成推薦結果。在基於物品的協同過濾中,我們根據使用者此前曾評過分的物品,推薦與其最為相似的物品。在案例中,第一位使用者獲得的推薦結果為第三本書籍,然後是第六本(圖七)。同樣地,我們只取與使用者之前評論過的書籍最相似的兩本書。
根據上述描述,基於使用者與基於物品的協同過濾似乎非常類似,因此能得出不同的結果這一點確實很有意思。即便在上例中,這兩種方式都能為同一名使用者得出不同的推薦結果,儘管兩者的輸入內容是相同的。在構建推薦時,這兩種形式的協同過濾方式都是值得考慮的。儘管在向外行描述時,這兩種方法看起來非常類似,但實際上它們能得出非常不同的推薦結果,從而為使用者帶來完全不同的體驗。
由於簡單高效,且生成的推薦結果準確、個性化,鄰域方法也是相當受歡迎的。但由於要計算(使用者或物品間的)相似度,隨著使用者或物品數量的增長,也會出現一些伸縮性方面的侷限。在最糟的情況下,需要計算O(m*n),但在現實中情況略好一些,只要計算O(m+n)即可,部分原因在於利用了資料的稀疏度。儘管稀疏度有助於擴充套件實現,但同時也為基於鄰域的方法提出了挑戰,因為在海量的物品中,僅有少量是有使用者評論過的。例如,Mendeley系統中有數百萬篇文章,而一名使用者也許只讀過其中幾百篇。兩名各讀過100篇文章的使用者具有相似度的可能性僅為0.0002(在5000萬篇文章的目錄中)。
基於模型的協同過濾方式可以克服基於鄰域方法的限制。與使用使用者-物品評分直接預測新物品評分的鄰域方式不同,基於模型的方法則使用評分來研究預測性模型,並根據模型來預測新物品。大致理念就是通過機器學習演算法,在資料中找出模式,並將使用者與物品間的互動方式模式化。總體來講,基於模型的協同過濾方式是構建協同過濾更高階的演算法。很多不同的演算法都能用來構建模型,以進行預測;例如貝葉斯網路、叢集、分類、迴歸、矩陣因式分解、受限波爾茲曼機等,這些技術其中有些在獲得Netflix Prize獎項時起到了關鍵性作用。Netflix在2006年到2009年間舉辦競賽,當時還為能夠生成準確度超過其系統10%的推薦系統製作團隊提供100萬美元的大獎。勝出的解決方案是一套綜合了逾100種不同演算法模型,並在生產環境中採用了矩陣因式分解與受限玻爾茲曼機的方法。
矩陣因式分解(比如奇異值分解、SVD++)將物品與使用者都轉化為同一個隱空間,表現了使用者與物品間的底層互動(圖八)。矩陣因式分解背後的原理在於:其潛在特性代表了使用者如何對物品進行評分。根據使用者與物品的潛在表現,我們就可以預測使用者對未評分的物品的喜愛程度。
在表一中,我們列出了鄰域演算法與基於模型的協同過濾演算法的關鍵優劣點。由於協同過濾演算法只依賴於使用者的使用資料,想要生成足夠優秀的推薦結果無需對技術工作有太多瞭解,但這種演算法也有其侷限。例如,CF更容易推薦流行物品,因此為品味獨特的使用者推薦物品時就會比較困難(即對其感興趣的物品可能不具有太多的使用資料),也就是流行度偏好的問題,這一點通常可以通過基於內容的過濾演算法解決。CF演算法更重要的一個限制就是所謂的“冷啟動問題”——系統無法為沒有或使用行為很少的使用者提供推薦(也就是新使用者的問題),也無法為沒有或使用行為很少的物品提供推薦(也就是新物品的問題)。新使用者的“冷啟動問題”可以通過流行度和混合演算法來解決,而新物品問題可以通過基於內容過濾或multi-armed bandit推薦演算法(即探索-利用)來解決。在下篇文章中我們會詳細討論其中一些演算法。
本文中,我們介紹了三種基本的協同過濾演算法實現。基於物品、基於使用者的協同過濾演算法,以及矩陣分解演算法之間的區別都很細微,通常很難簡單地解釋其差異。理解這些演算法間的差異有助於我們選擇推薦系統最適合的演算法。在下篇文章中,我們會繼續深入探討推薦系統的流行演算法。
推薦演算法概覽(三)
本文是系列文中的第三篇。第一篇文章通過列表形式介紹了推薦演算法的主要分類,第二篇文章介紹了不同型別的協同過濾演算法,強調了其間的一些細微差別。在本文中,我們將會更加詳細地介紹基於內容的過濾演算法並討論其優缺點,以更好地理解其工作原理。
基於內容的過濾演算法會推薦與使用者最喜歡的物品類似的那些。但是,與協同過濾演算法不同,這種演算法是根據內容(比如標題、年份、描述),而不是人們使用物品的方式來總結其類似程度的。例如,如果某個使用者喜歡電影《魔戒》的第一部和第二部,那麼推薦系統會通過標題關鍵字向使用者推薦《魔戒》的第三部。在基於內容的過濾演算法中,會假設每個物品都有足夠的描述資訊可作為特徵向量(y)(比如標題、年代、描述),而這些特徵向量會被用來建立使用者偏好模型。各種資訊檢索(比如tf-idf)以及機器學習技術(比如樸素貝葉斯演算法、支援向量機、決策樹等)都可用於生成使用者模型,之後再根據模型來進行推薦。
假設我們有一些使用者已經表達了他們對某些書籍的偏好,他們越喜歡某本書,對這本書的評分也越高(評分範圍是1分到5分)。我們可以在一個矩陣中重現他們的這種偏好,用行代表使用者,用列代表書籍。

在基於內容的協同過濾演算法中,我們要做的第一件事就是根據內容,計算出書籍之間的相似度。在本例中,我們使用了書籍標題中的關鍵字(圖二),這只是為了簡化而已。在實際中我們還可以使用更多的屬性。
首先,通常我們要從內容中刪除停止詞(比如語法詞、過於常見的詞),然後用代表出現哪些詞彙的向量(或陣列)對書籍進行表示(圖三),這就是所謂的向量空間表示。
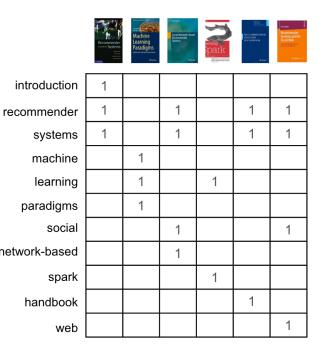
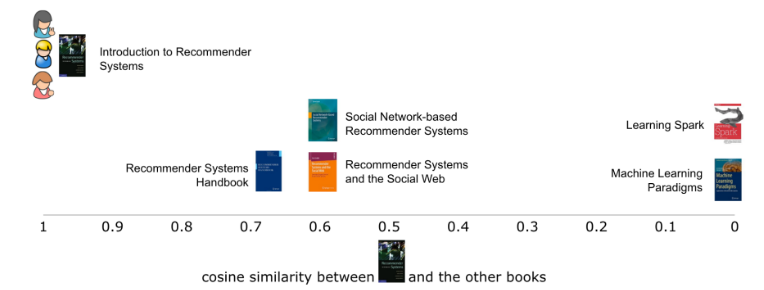
有了這個表格,我們就可以使用各種相似指標直接對比各本書籍。在本例中,我們會使用餘弦相似點。當我們使用第一本書籍,將其與其他五本書籍對比時,就能看到第一本書籍與其他書籍的相似程度(圖四)。就像大多相似度指標一樣,向量之間的相似度越高,彼此也就越相似。在本例中,第一本書與其他三本書都很類似,都有兩個共同的詞彙(推薦和系統)。而標題越短,兩本書的相似程度越高,這也在情理之中,因為這樣一來,不相同的詞彙也就越少。鑑於完全沒有共同詞彙,第一本書與其他書籍中的兩本完全沒有類似的地方。
我們還可以在相似矩陣中展示出所有書籍彼此間的相似程度(圖五)。單元格的背景色表明了使用者彼此間的相似程度,紅色越深相似度越高。
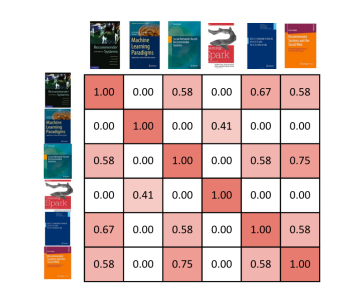
現在我們知道每本書彼此間的相似程度了,可以為使用者生成推薦結果。與基於物品的協同過濾方式類似,我們在之前的文章中也介紹過,推薦系統會根據使用者之前評價過的書籍,來推薦其他書籍中相似度最高的。區別在於:相似度是基於書籍內容的,準確來說是標題,而不是根據使用資料。在本例中,系統會給第一個使用者推薦第六本書,之後是第四本書(圖六)。同樣地,我們只取與使用者之前評論過的書籍最相似的兩本書。
基於內容的演算法解決了協同過濾演算法的某些限制,尤其能協助我們克服流行度偏見,以及新物品的冷啟動問題,而這些我們已經在協同過濾的部分中討論過了。然而,值得注意的是:純粹基於內容的推薦系統通常在執行時效果不如那些基於使用資料的系統(比如協同過濾演算法)。基於內容過濾的演算法也會有過度專業化的問題,系統可能會向使用者推薦過多相同型別的物品(比如獲得所有《魔戒》電影的推薦),而不會推薦那些雖然型別不同,但是使用者也感興趣的物品。最後,基於內容的演算法在實現時只會使用物品後設資料中所含的詞彙(比如標題、描述年份),更容易推薦更多相同的內容,限制了使用者探索發現這些詞彙之外的內容。關於基於內容過濾的優劣總結見表二。
推薦演算法概覽(四)
本文是系列文中的第四篇。第一篇文章通過列表形式介紹了推薦演算法的主要分類,第二篇文章介紹了不同型別的協同過濾演算法,強調了其間的一些細微差別,在第三篇中我們詳細介紹了基於內容的過濾演算法。本文將會討論基於之前提過演算法而形成的混合型推薦系統,也會簡單討論如何利用流行度來解決一些協同過濾演算法與基於內容過濾演算法的限制。
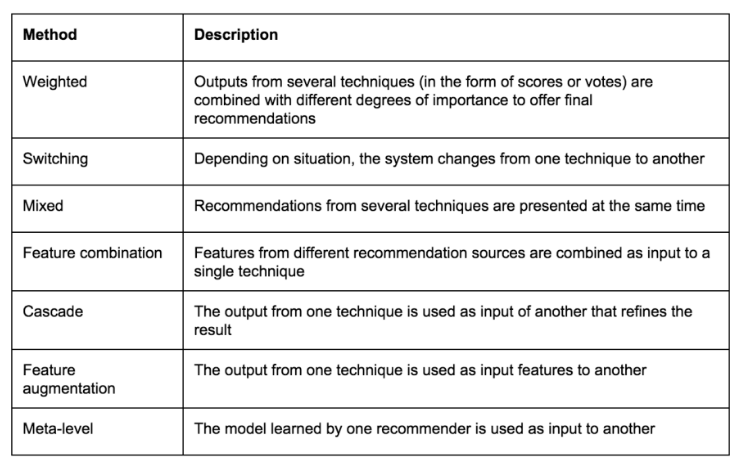
混合演算法結合了使用者及物品的內容特性以及使用資料,以利用這兩類資料的優點。結合了A演算法與B演算法的某個混合型推薦系統會嘗試利用A演算法的優點以解決B演算法的缺點。例如,協同過濾演算法存在新物品的問題,也就是說這種演算法無法推薦使用者未評價或使用過的物品。因為是基於內容(特性)預測的,這一點並不會對基於內容的演算法產生限制。而結合了協同過濾與基於內容過濾演算法的混合型推薦系統能夠解決單個演算法中的一些限制,比如冷啟動的問題與流行度偏好的問題。表一列出了一些不同的方法,包括如何結合兩種甚至更多基礎推薦系統技術,以建立新的混合型系統。
假設我們有一些使用者已經表達了他們對某些書籍的偏好,他們越喜歡某本書,對這本書的評分也越高(評分級別分別為1-5)。我們可以在一個矩陣中重現他們的這種偏好,用行代表使用者,用列代表書籍。

在本文所屬系列的第二篇中,我們給出了兩個案例,包括如何使用基於物品及基於使用者的協同過濾演算法來計算推薦結果;在本文所屬系列的第三篇中,我們演示瞭如何使用基於內容的過濾演算法來生成推薦結果。現在我們將這三種不同的演算法結合起來,生成一種全新的混合型推薦結果。我們會使用加權法(表一)結合多種技術得出的結果,之後這三種演算法便可按照不同的權值(根據重要性不同)結合得出一組新的推薦結果。
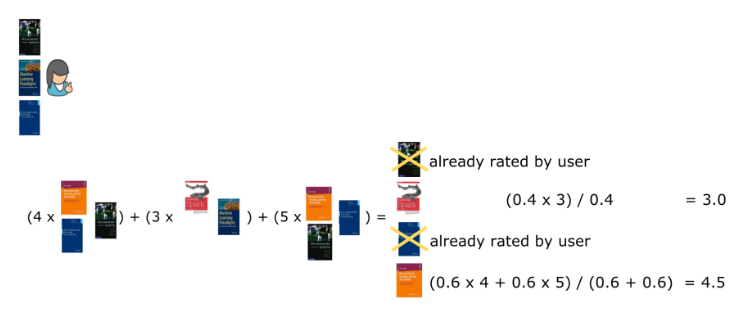
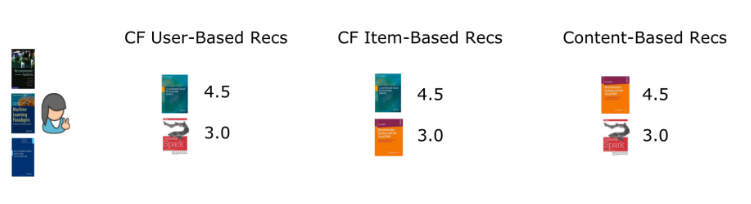
我們先以第一個使用者為例,為其生成一些推薦。首先我們會根據第二篇中的基於使用者的協同過濾演算法,基於物品的協同過濾演算法,以及第三篇中基於內容過濾的演算法,各自生成推薦結果。值得注意的是,在這個小案例中,這三種方法為同一名使用者生成的推薦結果有著輕微的差異,儘管輸入的內容是完全相同的。
下一步,我們使用加權混合推薦演算法為指定使用者生成推薦結果,加權值分別為:基於使用者的協同過濾演算法40%,基於物品的協同過濾演算法30%,基於內容過濾的演算法30%(圖三)。在這個案例中,系統會向使用者推薦他們從未看過的所有三本書,而使用單個演算法只會推薦其中兩本。
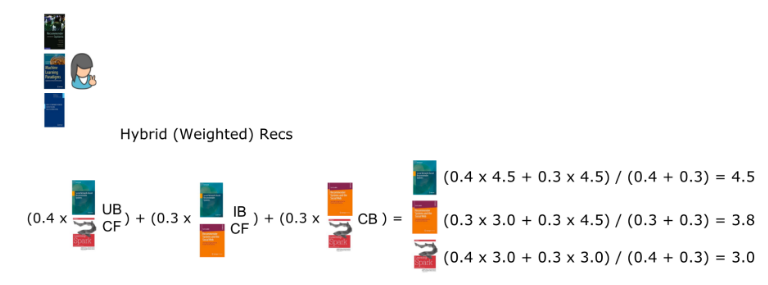
儘管混合型演算法解決了CF與CB演算法的一些重大挑戰與限制(見圖三),但在系統中平衡不同的演算法也需要很多工作量。另一種結合單個推薦演算法的方式是使用整合方法,關於如何結合不同演算法得出的結果,我們研究得出了一個函式。值得注意的是:通常整合演算法不僅結合了不同的演算法,還結合了根據同一種演算法得出的不同變體與模型。例如:獲得Netflix Prize獎項的解決方案包含了從10多種演算法(流行度、鄰域演算法、矩陣分解演算法、受限波爾茲曼機、迴歸等等)得出的100多種不同的模型,並通過迭代決策樹(GBDT)將這些演算法與模型結合在一起。
另外,基於流行度的演算法對於新使用者的冷啟動問題來說也是一個優秀的解決方案。這些演算法通過某些流行度的測量標準,比如下載最多的或者購買最多的,來對物品進行排名,並將這些流行度最高的物品推薦給新使用者。當擁有合適的流行度衡量指標時,這個辦法雖然基礎卻很有效,通常可以為其他演算法提供很好的基線標準。流行度演算法也可以單獨作為演算法使用,以引導推薦系統在換到其他更切合使用者興趣點的演算法(比如協同過濾演算法以及基於內容過濾的演算法)前獲得足夠的活躍度與使用量。流行度模型也可以引入混合演算法中,從而解決新使用者的冷啟動問題。
推薦演算法概覽(五)
本文是推薦演算法系列文中的第五篇。第一篇文章通過列表形式介紹了推薦演算法的主要分類,第二篇文章介紹了不同型別的協同過濾演算法,強調了其間的一些細微差別,在第三篇中我們詳細介紹了基於內容的過濾演算法,在第四篇中我們講解了混合型推薦系統以及基於流行度的演算法。在本篇中,我們會對簡單瞭解一下如何對一些高階的推薦演算法做以選擇,再回顧一下基礎演算法得出的推薦結果差異有多大,以便本系列完美收官。
除了我們截至目前提到的一些更為傳統的推薦系統演算法之外(比如流行度演算法、協同過濾演算法、基於內容過濾的演算法、混合型演算法),還有許多其他演算法也可用於加強推薦系統的功能,包括有:
- 深度學習演算法
- 社會化推薦
- 基於機器學習的排序方法
- Multi-armed bandits推薦演算法(探索/利用)
- 情景感知推薦(張量分解&分解機)
這些更為高階的非傳統演算法對於將現有推薦系統的質量推向更高層次很有好處,但理解起來也更困難,推薦工具的支援上也不夠。在實踐中,我們總要權衡實現高階演算法的代價與對基礎演算法的增益相比較是否值得。根據經驗來看,基礎演算法還能使用很久,為一些很優秀的產品提供服務。
在本系列文中,我們希望介紹一些常見的推薦模組演算法,包括基於使用者的協同過濾演算法,基於物品的協同過濾演算法,基於內容的過濾演算法,以及混合型演算法。我們使用了一個案例,說明了這四種不同演算法在輸入資料相同時,應用於同一個案例時,為同一個使用者生成的不同推薦結果(圖一)。當應用於真實世界的大型資料時,這樣的效應依然存在,因此決定使用哪種演算法時,需要考慮相關的優缺點以及執行效果。

在實踐中,一般如果在推薦模型中使用協同過濾演算法,就不會犯太大錯誤。協同過濾演算法似乎比其他演算法更優秀,但在冷啟動使用者及物品方面會有問題,因此通常會使用基於內容的演算法作為輔助。如果有時間的話,使用混合型演算法就可以結合協同過濾及基於內容過濾演算法優勢了。將這些基礎演算法放在一起當然是個好辦法,甚至比高階演算法還要更好。
最後這一點值得牢記:推薦模型只是五個推薦系統元件中的一個。與所有元件類似,正確設定並努力建立模型非常重要,不過選擇資料集、處理、後處理、線上模組及使用者介面也同樣重要。正如我們再三強調的那樣,演算法只是推薦系統的一部分,整個產品應當將你的決策納入考量。
相關文章
- 推薦系統技術概覽
- 【方法論】機器學習演算法概覽機器學習演算法
- 演算法推薦演算法
- 概覽
- Physic Design:Floorplan演算法概覽演算法
- 機器學習概覽機器學習
- 精簡推薦演算法演算法
- 演算法好書推薦演算法
- 推薦演算法的精髓演算法
- Babel 社群概覽Babel
- Hooks概覽(譯)Hook
- 推理框架概覽框架
- Flutter框架概覽Flutter框架
- Java NIO 概覽Java
- 學習概覽
- IT專案概覽
- 圖解抖音推薦演算法圖解演算法
- 推薦演算法的“前世今生”演算法
- 微博推薦演算法簡述演算法
- 推薦演算法(二)--演算法總結演算法
- 推薦系統一——深入理解YouTube推薦系統演算法演算法
- 雲音樂推薦系統(二):推薦系統的核心演算法演算法
- PyQt5 概覽QT
- Dart語言概覽Dart
- React Hooks-概覽ReactHook
- Flutter技術概覽Flutter
- HTTP報文 概覽HTTP
- Redis分散式概覽Redis分散式
- BIO,NIO,AIO概覽AI
- Vuex - 原始碼概覽Vue原始碼
- 概覽【JavaScript那些事】JavaScript
- 編譯原理概覽編譯原理
- Goolge AppEngine概覽GoAPP
- SOE開發概覽
- redis基本操作概覽Redis
- REST SOE模板概覽REST
- 設計模式概覽設計模式
- YouTube視訊的推薦演算法演算法