大資料專案-資料立方體


如上圖所示,這是由三個維度構成的一個OLAP立方體,立方體中包含了滿足條件的cell(子立方塊)值,這些cell裡面包含了要分析的資料,稱之為度量值。顯而易見,一組三維座標唯一確定了一個子立方。
多位模型的基本概念介紹:
- 立方體:由維度構建出來的多維空間,包含了所有要分析的基礎資料,所有的聚合資料操作都在立方體上進行。
- 維度:就是觀察資料的一種角度。在這個例子中,路線,源,時間都是維度,
- 這三個維度構成了一個立方體空間。維度可以理解為立方體的一個軸。要注意的是有一個特殊的維度,即度量值維度。
- 維度成員:構成維度的基本單位。對於時間維,它的成員分別是:第一季度、第二季度、第三季度、第四季度。
- 層次:維度的層次結構,要注意的是存在兩種層次:自然層次和使用者自定義層次。對於時間維而言,(年、月、日)是它的一個層次,(年、季度、月)是它的另一個層次,一個維可以有多個層次,層次可以理解為單位資料聚合的一種路徑。
- 級別:級別組成層次。對於時間維的一個層次(年、月、日)而言,年是一個級別,月是一個級別,日是一個級別,顯然這些級別是有父子關係的。
- 度量值:要分析展示的資料,即指標。如圖1中一個cell中包含了兩個度量值:裝箱數和截至時間,可以對其進行多維分析。
- 事實表:存放度量值的表,同時存放了維表的外來鍵。所有的分析用的資料最終都是來自與事實表。
- 維表:一個維度對應一個或者多個維表。一個維度對應一個維表時資料的組織方式就是採用的星型模式,對應多個維表時就是採用雪花模式。雪花模式是對星型模式的規範化。簡言之,維表是對維度的描述。
- MDX查詢:多維模型的查詢語言MDX(MDX是微軟釋出的多維查詢語言標準),它的語法與SQL有很多相似之處:select {[Measures].[Salary]} on columns, {[Employee].[employeeId].members} on rows from CubeTest對於這條語句,COLUMNS 和 ROWS都代表查詢軸,其中COLUMNS代表列軸,ROWS代表行軸。COLUMNS又可以寫成0,ROWS又可以寫成1,當只有兩個查詢軸時,可以理解為結果的展現格式是一個平坦二維表。這條語句的含義就是查詢名字為CubeTest的立方體,列顯示Measures維度的salary,行顯示 Employee維度employeeId級別的所有成員,那麼得出的結果就是employeeId所有成員的salary,也就是所有員工的薪酬。具體語法規範和幫助文件可以參考微軟的使用者文件。
多維資料模型是為了滿足使用者從多角度多層次進行資料查詢和分析的需要而建立起來的基於事實和維的資料庫模型,其基本的應用是為了實現OLAP(Online Analytical Processing)。
其中,每個維對應於模式中的一個或一組屬性,而每個單元存放某種聚集度量值,如count或sum。資料立方體提供資料的多維檢視,並允許預計算和快速訪問彙總資料。
《資料探勘:概念與技術》中例舉如下模型

資料立方體允許以多維資料建模和觀察。它由維和事實定義。 維是關於一個組織想要記錄的視角或觀點。每個維都有一個表與之相關聯,稱為維表。 事實表包括事實的名稱或度量以及每個相關維表的關鍵字。
在資料倉儲的研究文獻中,一個n維的資料的立方體叫做基本方體。給定一個維的集合,我們可以構造一個方體的格,每個都在不同的彙總級或不同的資料子集顯示資料,方體的格稱為資料立方體。0維方體存放最高層的彙總,稱為頂點方體;而存放最底層彙總的方體稱為基本方體。
資料倉儲的概念模型 最流行的資料倉儲概念是多維資料模型。這種模型可以以星型模式,雪花模式,或事實星座模式的形式存在。
1.星型模式(Star schema):事實表在中心,周圍圍繞地連線著維表(每維一個),事實表包含有大量資料,沒有冗餘。

2.雪花模式(Snowflake schema):是星型模式的變種,其中某些維表是規範化的,因而把資料進一步分解到附加表中。結果,模式圖形成類似雪花的形狀。

雪花模型相較於星座模型,是把維表進行了規範化。
事實星座(Fact constellations):多個事實表共享維表,這種模式可以看作星座模式集,因此稱作星系模式(galaxy schema),或者事實星座(fact constellation)

事實星座模式是把事實間共享的維進行合併。
對概念進行分層,有利於資料的彙總。
資料立方體
關於資料立方體(Data Cube),這裡必須注意的是資料立方體只是多維模型的一個形象的說法。立方體其本身只有三維,但多維模型不僅限於三維模型,可以組合更多的維度,但一方面是出於更方便地解釋和描述,同時也是給思維成像和想象的空間;另一方面是為了與傳統關係型資料庫的二維表區別開來,於是就有了資料立方體的叫法。所以本文中也是引用立方體,也就是把多維模型以三維的方式為代表進行展現和描述,其實上Google圖片搜尋“OLAP”會有一大堆的資料立方體圖片,這裡我自己畫了一個:

OLAP
OLAP(On-line Analytical Processing,聯機分析處理)是在基於資料倉儲多維模型的基礎上實現的面向分析的各類操作的集合。可以比較下其與傳統的OLTP(On-line Transaction Processing,聯機事務處理)的區別來看一下它的特點:
OLAP與OLTP
| 資料處理型別 | OLTP | OLAP |
| 物件導向 | 業務開發人員 | 分析決策人員 |
| 功能實現 | 日常事務處理 | 面向分析決策 |
| 資料模型 | 關係模型 | 多維模型 |
| 資料量 | 幾條或幾十條記錄 | 百萬千萬條記錄 |
| 操作型別 | 查詢、插入、更新、刪除 | 查詢為主 |
OLAP的型別
首先要宣告的是這裡介紹的有關多維資料模型和OLAP的內容基本都是基於ROLAP,因為其他幾種型別極少接觸,而且相關的資料也不多。
MOLAP(Multidimensional)
即基於多維陣列的儲存模型,也是最原始的OLAP,但需要對資料進行預處理才能形成多維結構。
ROLAP(Relational)
比較常見的OLAP型別,這裡介紹和討論的也基本都是ROLAP型別,可以從多維資料模型的那篇文章的圖中看到,其實ROLAP是完全基於關係模型進行存放的,只是它根據分析的需要對模型的結構和組織形式進行的優化,更利於OLAP。
HOLAP(Hybrid)
介於MOLAP和ROLAP的型別,我的理解是細節的資料以ROLAP的形式存放,更加方便靈活,而高度聚合的資料以MOLAP的形式展現,更適合於高效的分析處理。
另外還有WOLAP(Web-based OLAP)、DOLAP(Desktop OLAP)、RTOLAP(Real-Time OLAP),具體可以參開維基百科上的解釋——OLAP。
OLAP的基本操作
我們已經知道OLAP的操作是以查詢——也就是資料庫的SELECT操作為主,但是查詢可以很複雜,比如基於關聯式資料庫的查詢可以多表關聯,可以使用COUNT、SUM、AVG等聚合函式。OLAP正是基於多維模型定義了一些常見的面向分析的操作型別是這些操作顯得更加直觀。
OLAP的多維分析操作包括:鑽取(Drill-down)、上卷(Roll-up)、切片(Slice)、切塊(Dice)以及旋轉(Pivot),下面還是以上面的資料立方體為例來逐一解釋下:

鑽取(Drill-down):在維的不同層次間的變化,從上層降到下一層,或者說是將彙總資料拆分到更細節的資料,比如通過對2010年第二季度的總銷售資料進行鑽取來檢視2010年第二季度4、5、6每個月的消費資料,如上圖;當然也可以鑽取浙江省來檢視杭州市、寧波市、溫州市……這些城市的銷售資料。
上卷(Roll-up):鑽取的逆操作,即從細粒度資料向高層的聚合,如將江蘇省、上海市和浙江省的銷售資料進行彙總來檢視江浙滬地區的銷售資料,如上圖。
切片(Slice):選擇維中特定的值進行分析,比如只選擇電子產品的銷售資料,或者2010年第二季度的資料。
切塊(Dice):選擇維中特定區間的資料或者某批特定值進行分析,比如選擇2010年第一季度到2010年第二季度的銷售資料,或者是電子產品和日用品的銷售資料。
旋轉(Pivot):即維的位置的互換,就像是二維表的行列轉換,如圖中通過旋轉實現產品維和地域維的互換。
OLAP的優勢
首先必須說的是,OLAP的優勢是基於資料倉儲面向主題、整合的、保留歷史及不可變更的資料儲存,以及多維模型多視角多層次的資料組織形式,如果脫離的這兩點,OLAP將不復存在,也就沒有優勢可言。
資料展現方式
基於多維模型的資料組織讓資料的展示更加直觀,它就像是我們平常看待各種事物的方式,可以從多個角度多個層面去發現事物的不同特性,而OLAP正是將這種尋常的思維模型應用到了資料分析上。
查詢效率
多維模型的建立是基於對OLAP操作的優化基礎上的,比如基於各個維的索引、對於一些常用查詢所建的檢視等,這些優化使得對百萬千萬甚至上億數量級的運算變得得心應手。
分析的靈活性
我們知道多維資料模型可以從不同的角度和層面來觀察資料,同時可以用上面介紹的各類OLAP操作對資料進行聚合、細分和選取,這樣提高了分析的靈活性,可以從不同角度不同層面對資料進行細分和彙總,滿足不同分析的需求。
SSAS中Cube的結構
在SSAS(SQL Server Analysis Services)中構建Cube和編寫MDX的時候,我們很容易被一些名詞弄糊塗,比如:Dimension(維度),Measures Dimension(度量維度),Measure(度量),Hierarchy(層次結構),Attribute hierarchy(屬性層次結構),Level(級別),Cell(單元),Member(成員),Member
Property(成員屬性),Set(集),Turple(元組)等等。要想弄清楚這些名詞,就必須理解Cube的結構。
上述名詞的解釋詳見:http://msdn2.microsoft.com/en-us/library/ms144884.aspx Cube、Dimension和Measure Cube就象一個座標系,每一個Dimension代表一個座標軸,要想得到一個點,就必須在每一個座標軸上取的一個值,而這個點就是Cube中的Cell。見下圖(來源於http://msdn2.microsoft.com/zh-
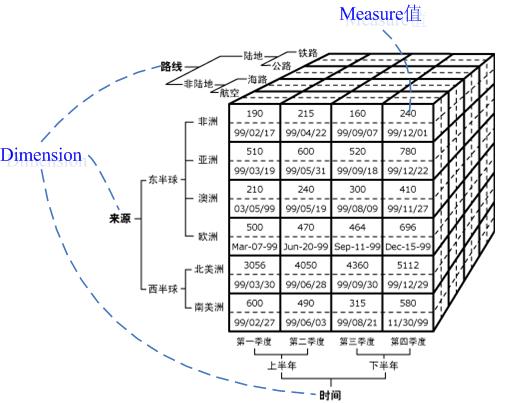
上圖很好的說明了Cube、Dimension、Measure之間的關係。這裡需要注意的是:其實Measure也屬於一個維度,即Measures Dimension。所有的Measure構成了Measures Dimension,這個維度的只有一個Hierarchy,而且這個Hierarchy只有一個層次(Level)。
Hierarchy、Level和Memeber 在上節的圖中,每個Dimension只有一個Hierarchy,而在實際的環境中,一個Dimension往往有很多Hierarchy。因此,上一小節中關於“Cube就象一個座標系,每一個Dimension代表一個座標軸”這句話其實不夠準確,準確的說應該是每一個Hierarchy代表了一個座標軸,而Hierarchy中每一個Member代表了座標軸上的一個值。下圖以時間維度為例展示了Dimension的內部結構。
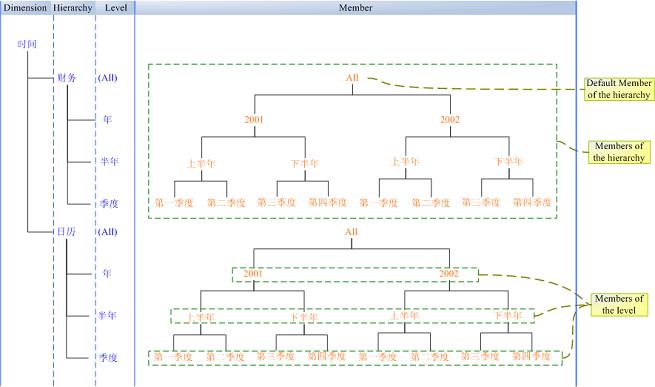
此外,我們需要說明的是:
1) 上圖中說明的是一般Dimension的結構,在實際的模型中,其實可以做很多自定義的工作。比如:我們可以修改Hierarchy的預設Member。
2) 一般情況下,SSAS中Hierarchy的預設Member是All(在你的模型中,可能叫其他名稱)。換句話說在MDX中[時間].[財政]等價於[時間].[財政].[All],[時間].[財政].Children等價於[時間].[財政].[All].Children。
3) Dimension_Name.Hierarchy_Name.Level_Name等價於Dimension_Name.Hierarchy_Name.Level_Name.Members。比如:[時間].[財政].[半年]等價於[時間].[財政].[半年].Members。Level的Members是該級別的所有元素(對於[時間].[財政].[半年].Members={[上半年],[下半年],[上半年],[下半年]},其中前兩個是2001年下的,後兩個屬於2002年),而Hierarchy的Members包含了該Hierarchy下所有的內容。
4) 當且僅當一個Dimension下只有一個Hierarchy,則Dimension_Name等價於Dimension_Name.Hierarchy_Name緯度。比方說:時間維度只有一個財務Hierarchy,則[時間]等價[時間].[財務]。
5) Attribute Hierarchy中Members的層次是兩層(MSDN的說法更加準確,這裡簡化了一些):第一層:All,第二層:葉子節點。也就是說它和多層的Hierarchy相比,兩者結構完全相同,這是統一維度模型(Unified
Dimensional Model)一個方面的體現。
注意:採用Attribute Hierarchy能夠使編寫MDX更加容易,但同時也增加了Cube的容量,加大了Cells的個數,對效能有負面影響。因此,在建模的時候,我們可以把一些Attribute Hierarchy的AttributeHierarchyEnabled屬性設定成False,同時在編寫MDX時,以Member
Property的方式來引用,這樣可以在滿足需求的前提下提高效能。
6) Measures Dimension是一個特殊的維度,它的Members中沒有All這個成員,它的預設Member可以在建模時指定。
7)對於一般的維度,其第一層Level的預設是“(All)”。
Turple和Set 如果說Cube好像一個座標系,那麼Turple、Set的關係就好比點和麵的關係。Turple由Cube中每個Hierarchy的一個Member組成。由於Hierarchy的個數非常多,所以一般不可能在Turple表示式中把所有的Member都明確指定,故此,為了簡化開發,所有沒有明確指定Member的Hierarchy,用該Hierarchy的預設Member代替。也就是說:([時間].[財政].[2001].[上半年])
等價於([時間].[財政].[2001].[上半年],[時間].[日曆].[All])。另外我們需要注意的:
1) 有的說法認為:Turple是“Cube 上的一個子集(不斷開的子Cube),這個看法是不準確的,因為Turple只是一個點,不是面,它僅僅由每個Hierarchy的一個Member組成的。
2) 外面()起來的表示式不一定是Turple。比如:([時間].[財政].[半年].Members,[時間].[日曆].[2001].[上半年])就不是一個Turple,而是一個Set,其原因在於,Turple是點,它僅僅由每個Hierarchy的一個Member組成,如果在任何一個Hierarchy上有兩個成員,則其就變成Set了。
注意:([時間].[財政].[半年].Members,[時間].[日曆].[2001].[上半年])等價於Crossjoin([時間].[財政].[半年].Members,[時間].[日曆].[2001].[上半年])或{[時間].[財政].[半年].Members}*{[時間].[日曆].[2001].[上半年]},在SSAS的MDX中,我們可以在()中定義多個用逗號分隔開的表示式,編譯器會進行分析,如果發現是Set的話,就把它轉化成多個Set相乘的形式。
3) Set中的Turple可以重複。比如:{[時間].[日曆].[2001].[上半年],[時間].[日曆].[2001].[上半年]}並不等於{[時間].[日曆].[2001].[上半年]},因為前者有兩個Turple,後者只有一個。
4) SSAS能夠根據上下文的需要,自動把Turple變成Set,單個Member變成Turple,多個Member變成Set。這也是我們常常混淆Turple和Set的原因。詳細的例子如下:
總結 總體來看,SSAS中的Cube的內部結構非常的清晰,在實際開發中,只要多注意一下預設的一些轉化,使用起來是很容易的。a)上下文需要Set時,([時間].[日曆].[2001].[上半年])自動轉化成{[時間].[日曆].[2001].[上半年]}。 b)上下文需要Turple時,[時間].[日曆].[2001].[上半年]自動轉化成([時間].[日曆].[2001].[上半年])。 c)上下文需要Set時,[時間].[日曆].[2001].Children自動轉化成{[時間].[日曆].[2001].Children}。
維(Dimension)
維是用於從不同角度描述事物特徵的,一般維都會有多層(Level),每個Level都會包含一些共有的或特有的屬性(Attribute),可以用下圖來展示下維的結構和組成:

以時間維為例,時間維一般會包含年、季、月、日這幾個Level,每個Level一般都會有ID、NAME、DESCRIPTION這幾個公共屬性,這幾個公共屬性不僅適用於時間維,也同樣表現在其它各種不同型別的維。其中ID一般被視為代理主鍵(Agent),它只被用於作為唯一性標誌,並且是多維模型中關聯關係的代理者,在業務層面並不具有任何意義;NAME一般是業務主鍵(Business),在業務層面限制唯一性,一般作為資料裝載(Load)時的關聯鍵;而DESCRIPTION則記錄了詳細描述資訊,在多維展示和分析時我們都會選擇使用DESCRIPTION來表述具體含義。這3個屬性一般是所有Level都會共用的,而比如用於描述星期幾的屬性weekid可能只會用於“日期”這層,因為年月都不具備這一資訊。所以圖中我將Attributes放到了一個層面上,就如同是不同的Level從底層的多個Attributes中選取自身所需的屬性,Attributes層是包含著各個Level的共有和特有屬性的集合。
Hierarchy
因為不知道怎麼翻譯好,所以還是用英文吧。Hierarchy(等級、層級的意思),中文的OLAP相關文件中普遍翻譯為“層次”,而上面的Level被普遍翻譯為“級別”,我經常會被這樣的翻譯搞混淆,所以我上面也一直用Level,至少對我來說這樣看起來反而清晰點 ![]() 。
。
因為上面這個結構的維是無法直接應用於OLAP的,我前面的文章有介紹,其實OLAP需要基於有層級的自上而下的鑽取,或者自下而上地聚合。所以每一個維必須有Hierarchy,至少有一個預設的,當然可以有多個,見下圖:

有了Hierarchy,維裡面的Level就有了自上而下的樹形結構關係,也就是上層的每一個成員(Member)都會包含下層的0個或多個成員,也就是樹的分支節點。這裡需要注意的是每個Hierarchy樹的根節點一般都設定成所有成員的彙總(Total),當該維未被OLAP中使用時,預設顯示的就是該維上的彙總節點,也就是該維所有資料的聚合(或者說該維未被用於細分)。Hierarchy中的每一層都會包含若干個成員(Member),還是以時間維,假設我們建的是2006-2015這樣一個時間跨度的時間維,那麼最高層節點僅有一個Total的成員,包含了所有這10年的時間,而年的那層Level中包含2006、2007…2015這10個成員,每一年又包含了4個季度成員,每個季度包含3個月份成員……這樣似乎順理成章多了,我們就可以基於Hierarchy做一些OLAP操作了。
每個Hierarchy都包含了一個樹形結構,但維中也可以包含多個Hierarchy,正如上圖所示,維中的Hierarchy相互獨立地構建了自己的樹形結構。還是以時間維為例,時間維可以根據日曆(Calendar)時間組建日曆的Hierarchy,也可以根據財務(Fiscal)時間組建財務的Hierarchy,而其中財務季度的劃分可能並不與日曆一致,基於這種多樣的Hierarchy,我們在組建多維模型時可以按需選擇合適的,比如給財務部的資料分析模型選用財務Hierarchy,而其他部門的分析人員顯然希望看到日曆樣式的Hierarchy,這樣就完美地滿足了不同的需求。多種的Hierarchy劃分同樣適用於產品維,根據產品型別、產品規格等劃分 Hierarchy,對於按多種條件的產品篩選和檢索是十分有效的,例項可以參見淘寶搜尋商品介面和太平洋電腦中產品報價介面分類篩選模組,這裡不再截圖了。
立方(Cube)
這裡所說的立方其實就是多維模型中間的事實表(Fact Table),它會引用所有相關維的維主鍵作為自身的聯合主鍵,加上度量(Measure)和計算度量(Calculated Measure)就組成了立方的結構:

度量是用於描述事件的數字尺度,比如網站的瀏覽量(Pageviews)、訪問量(Visits),再如電子商務的訂單量、銷售額等。度量是實際儲存於物理表中的,而計算度量則沒有,計算度量是通過度量計算得到的,比如同比(如去年同期的月利潤)、環比(如上個月的利潤)、利率(如環比利潤增長率)、份額(如該月中某類產品利潤所佔比例)、累計(如從年初到當前的累加利潤)、移動平均(如最近7天的平均利潤額)等,這些計算度量在Oracle中都可以藉助分析函式直接計算得到,相信大部分的OLAP元件都會提供類似在時間序列上的分析功能。而這些計算度量往往對於分析而言更具意義,立方中藉助與各個維的關聯關係從不同的角度和層面來展現這些度量。
相關文章
- 資料立方體簡介
- 資料倉儲建設-OLAP和資料立方體
- mysql資料庫的檔案建立方式MySql資料庫
- OpenStack大資料專案Sahara概述大資料
- 客快物流大資料專案(五十一):資料庫表分析 物流專案 資料庫表設計大資料資料庫
- 資料護航 安全立方—海泰方圓資料安全治理立體式框架框架
- 大資料,大資料,大資料大資料
- 大資料專家:大資料7大最奇特應用大資料
- 大資料爬蟲專案實戰教程大資料爬蟲
- 專案資料整理
- 決戰今晚!直擊水立方資料大屏秘密部隊
- 大資料入門指南(GitHub開源專案)大資料Github
- 大資料專案實踐(五)——Hue安裝大資料
- 大資料技術體系1(清華:大資料技術體系)大資料
- 資料治理--房產專案
- 大資料專案實戰之 --- 使用者畫像專案分析大資料
- 大資料【學習必看】入門+提升+專案=高薪大資料高薪
- TED:一個攝影師的大資料專案大資料
- Gartner:2013年大資料調查:64%的企業正在考慮大資料專案大資料
- 大資料專家Bernard Marr:大資料是如何對抗癌症的?大資料
- 大資料資料收集大資料
- Traveller專案技術資料
- 大資料重構體育大資料
- 華為雲大資料輕模式體驗:忘掉底層煩惱,專注資料開發大資料模式
- 大資料國家工程專案001號主資料國標平臺與工具大資料
- 走進大資料,感受大資料大資料
- 面試大資料再也不怕沒專案可說了面試大資料
- 大資料專案實踐(一)——之HDFS叢集配置大資料
- 3.0 阿里雲大資料專案實戰開發阿里大資料
- 掰一掰GitHub上優秀的大資料專案Github大資料
- 拉鉤專案(一)--專案流程+資料提取
- 大資料如何採集資料?大資料的資料從何而來?大資料
- 大資料hadoop資料大資料Hadoop
- 大資料學習資料大資料
- 大資料的資料模型大資料模型
- 為什麼學習大資料,大資料專家寫給大資料分析學習者的10個理由大資料
- 想學習大資料?這才是完整的大資料學習體系大資料
- 大資料專家教你用資料模型來找女朋友大資料模型