dom4j 學習 -- 封裝dom4j工具類+如何使用dom4j解析
今天專案裡面用到dom4j解析xml資料,特地整理了一下封裝dom4j的工具方法,使用dom4j來解析xml文件.
首先是封裝了dom4j的工具類:
package myDOM4J;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.StringReader;
import java.io.StringWriter;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
/**
* 基於dom4j的工具包
*
* @author PengChan
*
*/
public class DOMUtils {
/**
* 通過檔案的路徑獲取xml的document物件
*
* @param path 檔案的路徑
* @return 返回文件物件
*/
public static Document getXMLByFilePath(String path) {
if (null == path) {
return null;
}
Document document = null;
try {
SAXReader reader = new SAXReader();
document = reader.read(new File(path));
} catch (Exception e) {
e.printStackTrace();
}
return document;
}
/**
* 通過xml字元獲取document文件
* @param xmlstr 要序列化的xml字元
* @return 返回文件物件
* @throws DocumentException
*/
public static Document getXMLByString(String xmlstr) throws DocumentException{
if(xmlstr==""||xmlstr==null){
return null;
}
Document document = DocumentHelper.parseText(xmlstr);
return document;
}
/**
* 獲取某個元素的所有的子節點
* @param node 制定節點
* @return 返回所有的子節點
*/
public static List<Element> getChildElements(Element node) {
if (null == node) {
return null;
}
@SuppressWarnings("unchecked")
List<Element> lists = node.elements();
return lists;
}
/**
* 獲取指定節點的子節點
* @param node 父節點
* @param childnode 指定名稱的子節點
* @return 返回指定的子節點
*/
public static Element getChildElement(Element node,String childnode){
if(null==node||null == childnode||"".equals(childnode)){
return null;
}
return node.element(childnode);
}
/**
* 獲取所有的屬性值
* @param node
* @param arg
* @return
*/
public static Map<String, String> getAttributes(Element node,String...arg){
if(node==null||arg.length==0){
return null;
}
Map<String, String> attrMap = new HashMap<String,String>();
for(String attr:arg){
String attrValue = node.attributeValue(attr);
attrMap.put(attr, attrValue);
}
return attrMap;
}
/**
* 獲取element的單個屬性
* @param node 需要獲取屬性的節點物件
* @param attr 需要獲取的屬性值
* @return 返回屬性的值
*/
public static String getAttribute(Element node,String attr){
if(null == node||attr==null||"".equals(attr)){
return "";
}
return node.attributeValue(attr);
}
/**
* 新增孩子節點元素
*
* @param parent
* 父節點
* @param childName
* 孩子節點名稱
* @param childValue
* 孩子節點值
* @return 新增節點
*/
public static Element addChild(Element parent, String childName, String childValue) {
Element child = parent.addElement(childName);// 新增節點元素
child.setText(childValue == null ? "" : childValue); // 為元素設值
return child;
}
/**
* DOM4j的Document物件轉為XML報文串
*
* @param document
* @param charset
* @return 經過解析後的xml字串
*/
public static String documentToString(Document document, String charset) {
StringWriter stringWriter = new StringWriter();
OutputFormat format = OutputFormat.createPrettyPrint();// 獲得格式化輸出流
format.setEncoding(charset);// 設定字符集,預設為UTF-8
XMLWriter xmlWriter = new XMLWriter(stringWriter, format);// 寫檔案流
try {
xmlWriter.write(document);
xmlWriter.flush();
xmlWriter.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
return stringWriter.toString();
}
/**
* 去掉宣告頭的(即<?xml...?>去掉)
*
* @param document
* @param charset
* @return
*/
public static String documentToStringNoDeclaredHeader(Document document, String charset) {
String xml = documentToString(document, charset);
return xml.replaceFirst("\\s*<[^<>]+>\\s*", "");
}
/**
* 解析XML為Document物件
*
* @param xml
* 被解析的XMl
* @return Document
* @throws ParseMessageException
*/
public final static Element parseXml(String xml) {
StringReader sr = new StringReader(xml);
SAXReader saxReader = new SAXReader();
Document document = null;
try {
document = saxReader.read(sr);
} catch (DocumentException e) {
e.printStackTrace();
}
Element rootElement = document != null ? document.getRootElement() : null;
return rootElement;
}
/**
* 獲取element物件的text的值
*
* @param e
* 節點的物件
* @param tag
* 節點的tag
* @return
*/
public final static String getText(Element e, String tag) {
Element _e = e.element(tag);
if (_e != null)
return _e.getText();
else
return null;
}
/**
* 獲取去除空格的字串
*
* @param e
* @param tag
* @return
*/
public final static String getTextTrim(Element e, String tag) {
Element _e = e.element(tag);
if (_e != null)
return _e.getTextTrim();
else
return null;
}
/**
* 獲取節點值.節點必須不能為空,否則拋錯
*
* @param parent 父節點
* @param tag 想要獲取的子節點
* @return 返回子節點
* @throws ParseMessageException
*/
public final static String getTextTrimNotNull(Element parent, String tag) {
Element e = parent.element(tag);
if (e == null)
throw new NullPointerException("節點為空");
else
return e.getTextTrim();
}
/**
* 節點必須不能為空,否則拋錯
*
* @param parent 父節點
* @param tag 想要獲取的子節點
* @return 子節點
* @throws ParseMessageException
*/
public final static Element elementNotNull(Element parent, String tag) {
Element e = parent.element(tag);
if (e == null)
throw new NullPointerException("節點為空");
else
return e;
}
/**
* 將文件物件寫入對應的檔案中
* @param document 文件物件
* @param path 寫入文件的路徑
* @throws IOException
*/
public final static void writeXMLToFile(Document document,String path) throws IOException{
if(document==null||path==null){
return;
}
XMLWriter writer = new XMLWriter(new FileWriter(path));
writer.write(document);
writer.close();
}
}
然後使用了dom4j來解析xml格式的資料,首先自己給自己寫了一個xml文件(文件內容略微隨意,不過不用在意這些細節,哈哈)
<?xml version="1.0" encoding="UTF-8"?>
<myfriend>
<xiaoxue>
<loc>小學</loc>
<list>
<stud>
<name>張三</name>
<gender>男</gender>
</stud>
<stud>
<name>小花</name>
<gender>女</gender>
</stud>
</list>
</xiaoxue>
<chuzhong>
<oc>初中</oc>
<list>
<stud>
<name>小明</name>
<gender>男</gender>
</stud>
<stud>
<name>小龍</name>
<gender>女</gender>
</stud>
</list>
<anlian>
<xihuan>
<list>
<stud>
<name>小娜</name>
<key>女</key>
</stud>
<stud>
<name>小齊</name>
<key>男</key>
</stud>
</list>
</xihuan>
<feichangxihuan>
<stud>
<name>哈哈</name>
<des>蒼老師</des>
</stud>
</feichangxihuan>
</anlian>
</chuzhong>
</myfriend>編寫測試類來解析這個xml格式的文件:
package myDOM4J.test;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.Element;
import org.junit.Test;
import myDOM4J.DOMUtils;
public class MyTest {
@SuppressWarnings("unchecked")
@Test
public void test(){
Document document = DOMUtils.getXMLByFilePath("I:/javaweb/MYWORKING_SPACE/myDOM4J/src/myDOM4J/test/friends.xml");
// 查詢我所有的小學的結點
Element root = document.getRootElement();
List<Element> elements = root.element("xiaoxue").elements();
System.out.println(elements.get(0).getText());
List<Element> studs = elements.get(1).elements();
for(Element stu:studs){
System.out.print("-->"+stu.element("name").getText()+" ");
System.out.println(stu.element("gender").getText());
}
for(Iterator iterator = root.element("chuzhong").elementIterator();iterator.hasNext();){
Element element = (Element) iterator.next();
if(element.getName().equals("oc")){
System.out.println(element.getText());
}else if(element.getName().equals("list")){
for(Iterator iterator2 = element.elements("stud").iterator();iterator2.hasNext();){
Element stuElement = (Element) iterator2.next();
System.out.print("-->"+stuElement.element("name").getText());
System.out.println(stuElement.element("gender").getText());
}
}else if(element.getName().equals("anlian")){
for(Iterator iterator2 = element.elementIterator();iterator2.hasNext();){
Element current = (Element) iterator2.next();
if(current.getName().equals("xihuan")){
for(Iterator iterator3 = current.element("list").elementIterator();iterator3.hasNext();){
Element sElement = (Element) iterator3.next();
System.out.print("-->"+sElement.element("name").getText());
System.out.println(sElement.element("key").getText());
}
}else if(current.getName().equals("feichangxihuan")){
Element element2 = current.element("stud");
System.out.print("-->"+element2.element("name").getText());
System.out.println(element2.element("des").getText());
}
}
}
}
}
}
執行的結果如下如:
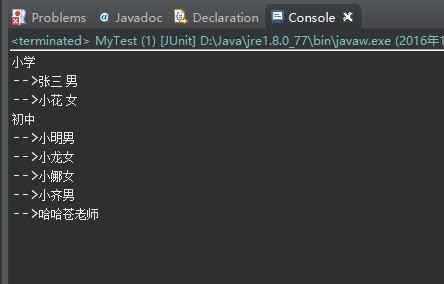
解析xml還是挺簡單的,不過有點繁瑣,是個體力活!一直好奇什麼時候出來一個框架,使得解析xml文件像,前端裡面jquery框架操作dom一樣方便就好了!
相關文章
- 使用dom4j 解析, 操作XMLXML
- 使用Dom4j解析XML案例XML
- dom4j解析xmlXML
- Dom4j解析XML資料XML
- 通過dom4j對xml文件的讀取操作工具類封裝XML封裝
- dom4j使用總結
- Dom4j框架的使用框架
- Dom4j解析【開發中常用】
- 【菜鳥學Java】9:使用dom4j解析jdbc.xmlJavaJDBCXML
- java學習:使用dom4j讀寫xml檔案JavaXML
- Dom4j 操作 XMLXML
- java的XML解析(DOM4J技術)JavaXML
- Java DOM4J 方式解析XML檔案JavaXML
- 用dom4j,解析xml 最好、最方便!XML
- DOM4J 解析 XML 之忽略轉義字元XML字元
- dom4j寫特殊字元字元
- 用dom4j SAXReader解析xml檔案及字串XML字串
- Java解析XML彙總(DOM/SAX/JDOM/DOM4j/XPath)JavaXML
- dom4j遍歷巢狀xml巢狀XML
- Dom4j 讀寫XML簡介XML
- dom4j讀寫xml檔案XML
- JAVA與DOM解析器提高(DOM/SAX/JDOM/DOM4j/XPath) 學習筆記二Java筆記
- dom4j 讀取網路的xmlXML
- 利用dom4j來生成xml檔案XML
- 菜鳥學Java(八)——dom4j詳解之讀取XML檔案JavaXML
- dom4j 與 w3c document的相互轉換
- 關於SAX,DOM,JAXP,JDOM,DOM4J的一些理解
- 四種操作xml的方式: SAX, DOM, JDOM , DOM4J的比較XML
- 扒一扒spring,dom4j實現模擬實現讀取xmlSpringXML
- 關於dom4j對xml檔案實現增刪改創的操作XML
- JAVA 利用Dom4j實現英語六級詞彙查詢 含演示地址Java
- Dom4j 讀 xml 時,遇到 xml 無效字元,報錯:An invalid XML characterXML字元
- 【超好用API推薦】用dom4j建立XML檔案並寫入節點APIXML
- java中四種操作(DOM、SAX、JDOM、DOM4J)xml方式詳解與比較JavaXML
- 單例設計模式中使用dom4j來完成(資料庫配置檔案)xml的解析,並完成資料庫的連線單例設計模式資料庫XML
- 封裝Date工具類封裝
- 封裝Redis工具類封裝Redis
- dom4j只認本地編碼的xml檔案而不認UTF-8編碼的嗎?XML