CentOS6.6-DRBD安裝配置實驗
DRBD+heartbeat實現檔案伺服器雙機熱備和高可用
1 需求
目前公司內部有一臺檔案伺服器,它是一個單節點,如果該節點出現意外當機,將會嚴重影響業務。
因此,本文用了drbd+heartbeat實現雙機熱備高可用。
2 架構拓撲
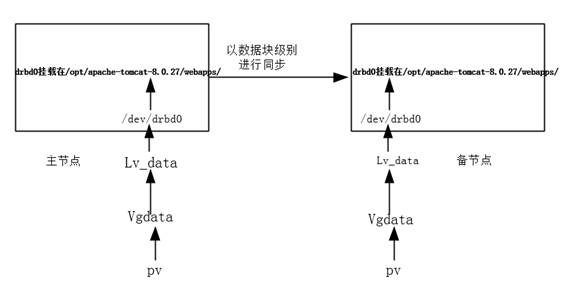
3 系統環境
1、作業系統:CentOS 6.6
2、相關軟體:drbd-8.4.8-1、drbd-utils-8.9.6
3、網路要求:/etc/hosts檔案新增雙方主機名列表。
4、兩臺機器的分割槽最好大小一致,至少要保證備節點的分割槽尺寸大於主節點的,以避免後期因空間不足而出現難以預見的問題
5、為了高效率,可以把drbd對外提供服務的網路和drbd資料同步網路分開,這樣可以使業務和資料同步互不影響。
6、規劃兩臺主機之間的心跳線為兩根以上,這樣能保證不會因為某一線路故障而產生切換 工作。在高可用方案中,一般需要用三根以上心跳線進行心跳檢測,以減少誤切換和腦裂問題,同時要確認上層交換機是否禁止ARP廣播。
7、只有保證兩臺機器型號或效能一樣好,才能保證在切換後備節點能完成原來主節點承擔的業務負載。
4 地址規劃
浮動 VIP : 172.16.22.9
主機名:drbd1
eth0:172.16.22.7 業務ip----)不配置閘道器
eth1:172.16.1.71 心跳線 ---->配置閘道器,我們透過該ip進行ssh登入管理
eth2:2.2.2.10 DRBD千兆資料傳輸----->不配置閘道器
主機名:drbd2
eth0:172.16.22.8 業務ip----)不配置閘道器
eth1:172.16.1.72 心跳線---->配置閘道器,我們透過該ip進行ssh登入管理
eth2:2.2.2.11 DRBD千兆資料傳輸 ----->不配置閘道器
5 安裝軟體
1、安裝支援軟體
#在編譯安裝之前,必須安裝核心開發包,以及支援庫
[shell]# yum -y install gcc kernel-devel kernel-headers
[shell]# yum -y install perl perl-libs
[shell]# yum -y install flex libxslt libxslt-devel
drbd官網下載地址:
編譯安裝drbd (drbd1和drbd2兩個伺服器都安裝)
2.1、安裝drbd核心模組
## Linux Kernel 2.6.33 起已包含DRBD核心模組,無需再安裝。核心版本與DRBD版本對應關係詳情參見:
[shell]# tar -xvzf drbd-8.4.8-1.tar.gz -C /usr/local/src
[shell]# cd /usr/local/src/drbd-8.4.8-1
[shell]# cd drbd
[shell]# make KDIR=/usr/src/kernels/2.6.32-504.23.4.el6.x86_64
[shell]# cp drbd.ko /lib/modules/`uname -r`/kernel/lib/
[shell]# depmod ## 更新核心包關聯檔案modules.dep
[shell]# modprobe drbd ## 安裝核心模組
[shell]# modinfo drbd ## 檢視drbd核心模組是否載入成功
[shell]#lsmod|grep drbd # 檢查drbd是否被正確的載入到核心
drbd 385827 0
libcrc32c 1246 1 drbd
## KDIR= 指定的系統核心原始碼路徑,根據實際情況設定
2.2、安裝drbd管理工具
[shell]# tar -xvzf drbd-utils-8.9.6.tar.gz -C /usr/local/src
[shell]# cd /usr/local/src/drbd-utils-8.9.6
[shell]# ./configure --prefix=/usr/local/drbd --sysconfdir=/etc/ --localstatedir=/var/ --with-heartbeat
[shell]# make && make install
##--with-heartbeat 支援heartbeat
3、超連結配置檔案、啟動指令碼
[shell]# ln -s /usr/local/drbd/sbin/drbdadm /usr/sbin/drbdadm
[shell]# ln -s /usr/local/drbd/sbin/drbdmeta /usr/sbin/drbdmeta
[shell]# ln -s /usr/local/drbd/sbin/drbdsetup /usr/sbin/drbdsetup
4、啟動軟體
[shell]# /etc/rc.d/init.d/drbd start
以上步驟在drbd1和drbd2兩個節點都執行。
6 軟體配置
1、 修改DRBD配置檔案: drbd1&&drbd2節點上都如下操作
a) 編輯主配置檔案 /etc/drbd.conf
drbd.conf描述了drbd裝置與硬碟分割槽的對映關係和一些配置引數
[shell]# vi /etc/drbd.conf
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "/etc/drbd.d/global_common.conf";
include "/etc/drbd.d/*.res";
## global_common.conf檔案包含global和common的DRBD全域性配置部分;
## *.res檔案包含DRBD資源的配置資訊。
b) 編輯全域性配置檔案(global_common.conf):
[shell]# vi /etc/drbd.d/global_common.conf
# DRBD is the result of over a decade of development by LINBIT.
# In case you need professional services for DRBD or have
# feature requests visit
global {
usage-count no; # 是否加入DRBD官方統計
}
common {
handlers {
# 定義處理機制程式,/usr/lib/drbd/ 裡有大量的程式指令碼。
}
startup {
# 定義啟動超時時間等
}
options {
# cpu-mask on-no-data-accessible
}
disk {
# 磁碟相關公共設定,比如I/O、資料狀態
on-io-error detach; #發生i/o錯誤的處理方法,detach將映象磁碟直接拔除
}
net {
# 設定DRBD同步時使用的驗證方式和密碼資訊。
cram-hmac-alg sha1;
shared-secret "drbd";
}
syncer {
verify-alg sha1;
# 定義主備節點同步時的網路傳輸速率最大值,一般傳輸速度的30%
rate 50M;
}
}
########
備註:對於rate引數,一般是用千兆網路的同步速率和磁碟寫入速率(hdparm -Tt /dev/drbd0測試結果)中最小者的30%頻寬來設定rate的值,這也是官方的建議。
例如千兆網路的的同步速率為125M/s,磁碟寫入速率為110m/s(hdparm –Tt /dev/drbd0測試結果)
那rate設定為33m/s。這樣設定的原因是,drbd同步由兩個不同的程式來負責:一個replication程式用來同步block的更新,這個值就受限於rate引數的設定;一個syncchribuzatuib程式用來同步後設資料資訊,這個值不受rate引數的限制。如果寫入了非常大,設定的rate引數超過磁碟寫入速度,後設資料的同步速率就會受干擾,傳輸進度變慢,導致機器負載非常高,效能下降得非常厲害,所以這個值應該根據實際環境來進行設定。如果設定的太大,會把所有的頻寬佔滿了,導致replication程式沒有可用頻寬,最終導致I/O停止,出現資料不同步的現象。
###################
c) 建立資源配置檔案(/etc/drbd.d/r0.res)
[shell]# vi /etc/drbd.d/r0.res
resource r0 {
# 公用相同部分可以放到頂部,各節點會自動繼承
protocol C; # 使用drbd的第三種同步協議,表示收到遠端主機的寫入確認後,則認為寫入完成
device /dev/drbd0; # DRBD邏輯裝置的路徑
meta-disk internal; # drbd的後設資料存放方式,DRBD磁碟內部。
# 每個主機的說明以"on"開頭,後面是主機名.在後面的{}中為這個主機的配置.
on drbd1 { # 此處是節點的主機名‘uname -n’
address 192.168.10.11:7788; # 設定DRBD的監聽埠
disk /dev/vg_drbd/drbd_data; # 節點物理裝置,用的未格式化的lvm
}
on drbd2 {
address 192.168.10.12:7788;
disk /dev/vg_drbd/drbd_data; #節點物理裝置,用的未格式化的lvm
}
}
2、啟用DRBD資源
## 建立裝置後設資料。這一步必須僅在建立初始化裝置時完成。它初始化DRBD後設資料。
[shell]# drbdadm create-md r0 #drbd1&&drbd2上都執行
這裡也可以使用drbdadm create-md all來代替drbadmin create-md r0,r0就是上面r0.res檔案裡面建立的資源名稱
備註:這裡面有可能出現建立不成功的現象,
如出現zreo out the device ,shrink that filesystem first,user external meta data這樣的錯誤,說明drbd0這個裝置裡面有已經存在的資料,這時需要使用如下命令覆蓋檔案系統中的裝置塊資訊,操作時確認此分割槽上的資料已經備份過
dd if=/dev/zero of=/dev/drbd0 bs=1M count=128
執行完dd後,再執行drbdadmin create-md all命令
## 啟用資源
[shell]# drbdadm up r0
## 啟動初始完全同步,設定主節點。
[shell]# drbdadm primary --force r0 #只在主節點drbd1上執行即可
當執行完上面一條命令後初始完全同步就開始了,可以透過cat /proc/drbd來監控同步程式。
[shell]# cat /proc/drbd
3、建立檔案系統(僅在drbd1執行)
## 把/dev/drbd0格式化成ext4格式的檔案系統。
[shell]# mkfs -t ext4 /dev/drbd0
## 將/dev/drbd0掛載到資料目錄
[shell]# mount /dev/drbd0 /opt/apache-tomcat-8.0.27/webapps/
設定drbd開機自啟動
[shell]# chkconfig drbd on
7 監控
可以透過/proc/drbd來監控同步程式。
[shell]# cat /proc/drbd
1、ds:UpToDate/Diskless表示其中一個節點沒有初始化,
[root@drbd1 ~]# cat /proc/drbd
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@drbd21, 2015-06-16 15:37:24
0: cs:Connected ro:Primary/Secondary ds:UpToDate/Diskless C r-----
ns:0 nr:0 dw:0 dr:664 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:20970844
2、ds:UpToDate/Inconsistent表示節點已開始同步,
[root@drbd1 ~]# cat /proc/drbd
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@drbd21, 2015-06-16 15:37:24
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:925056 nr:0 dw:0 dr:925720 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:20045788
[>....................] sync'ed: 1.4% (19572/19836)M #從這可以看到同步進度為%1.4
finish: 0:24:57 speed: 13,380 (10,784) K/sec #從這可以看出同步速度為10m/s
3、節點同步完成,ds:UpToDate/UpToDate
[root@drbd21 ~]# cat /proc/drbd
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@drbd21, 2015-06-16 15:37:24
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:20970844 nr:0 dw:0 dr:20971508 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
備註:
ro是角色資訊
ds:是磁碟狀態,UpToDate/UpToDate表示同步狀態沒有延時
ns是網路傳送的包,以k為單位
dw是磁碟寫操作
dr是磁碟讀操作
8 測試主節點寫入,備節點是否能同步
drbd1端:
[root@drbd1 ~]#tocuch /opt/apache-tomcat-8.0.27/webapps/1.txt
[root@drbd1 ~]#umount /opt/apache-tomcat-8.0.27/webapps/
[root@drbd1 ~]#drbdadm down r0 # 關閉名字為drbd的資源
drbd2端:
[root@drbd2 ~]#cat /proc/drbd # 主節點關閉資源之後,檢視備節點的資訊,可以看到主節點的角色已經變為UnKnown
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by root@M2.redhat.sx, 2014-11-11 16:25:08
0: cs:WFConnection ro:Secondary/Unknown ds:UpToDate/DUnknown C r-----
ns:0 nr:136889524 dw:136889524 dr:0 al:0 bm:8156 lo:0 pe:0 ua:0 ap:0 ep:1 wo:d oos:0
[root@drbd2 ~]#drbdadm primary drbd # 確立自己的角色為primary,即主節點
[root@drbd2 ~]#mount /dev/drbd0 /opt/apache-tomcat-8.0.27/webapps/
[root@drbd2 ~]# cd /opt/apache-tomcat-8.0.27/webapps/
[root@drbd2 ~]# ls # 發現資料還在
lost+found 1.txt
[root@drbd2 ~]# cat /proc/drbd # 檢視當前 drbd 裝置資訊
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by root@M2.redhat.sx, 2014-11-11 16:25:08
0: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r-----
ns:0 nr:136889524 dw:136889548 dr:1045 al:3 bm:8156 lo:0 pe:0 ua:0 ap:0 ep:1 wo:d oos:24
9 heartbeat 實現高可用
上面我們可以看到,如果我們只安裝drbd,發現主節點故障後,我們需要手工來切換drbd的主備角色,比較不夠智慧。
那有沒有自動切換drbd的方法呢,答案是有,這就需要用heartbeat了。
9.1 安裝heartbeat
drbd1&&drbd2兩個節點上都安裝heartbeat
用epel源安裝heartbeat。
wget
rpm -ivh epel-release-6-8.noarch.rpm
yum –y install heartbeat
9.2 heartbeat配置檔案
[root@DRBD1 yum.repos.d]# cd /usr/share/doc/heartbeat-3.0.4/
[root@DRBD1 heartbeat-3.0.4]# ll |egrep 'ha.cf|authkeys|haresources'
-rw-r--r--. 1 root root 645 Dec 3 2013 authkeys # heartbeat服務的認證檔案,也就是心跳線連線加密檔案
-rw-r--r--. 1 root root 10502 Dec 3 2013 ha.cf # heartbeat服務主配置檔案,也就是監控檔案
-rw-r--r--. 1 root root 5905 Dec 3 2013 haresources # heartbeat資源管理檔案
[root@DRBD1 heartbeat-3.0.4]# cp ha.cf authkeys haresources /etc/ha.d/
[root@DRBD1 heartbeat-3.0.4]# cd /etc/ha.d/
[root@DRBD1 ha.d]# ls
authkeys ha.cf harc haresources rc.d README.config resource.d shellfuncs
下面我列出這三個檔案的配置資訊。
drbd1節點:
a)、ha.cf 檔案
debugfile /var/log/ha-debug #開啟錯誤日誌報告
logfile /var/log/ha-log
logfacility local0
keepalive 1 #一秒檢測一次心跳線連線
deadtime 5 #5 秒測試不到主伺服器心跳線為有問題出現
warntime 5 #警告時間(最好在 2 ~ 10 之間)
initdead 10 #初始化啟動時 10 秒無連線視為正常,或指定heartbeat,也就是說在啟動時,需要等待10秒才去啟動任何資源。
udpport 694 #用 udp 的 694 埠連線
ucast eth1 172.16.1.71 #單播方式連線(主從都寫對方的 ip 進行連線)
ucast eth0 172.16.22.8 #單播方式連線(主從都寫對方的 ip 進行連線),寫兩個心跳是為了安全,其實寫一個就行
node drbd1 #宣告主服(注意是主機名uname -n不是域名)
node drbd2 #宣告備服(注意是主機名uname -n不是域名)
auto_failback off #自動切換(主服恢復後可自動切換回來)這個不要開啟
respawn hacluster /usr/lib64/heartbeat/ipfail #監控ipfail程式是否掛掉,如果掛掉就重啟它
b、authkeys 檔案
[root@drbd1 ha.d]# cat authkeys
auth 1 # 採用何種加密方式
1 crc # 無加密
#2 sha1 HI! # 啟用sha1的加密方式
#3 md5 Hello! # 採用md5的加密方式
[root@drbd1 ha.d]# chmod 600 authkeys # 該檔案必須設定為600許可權,不然heartbeat啟動會報錯
c、haresources
[root@drbd1 ha.d]# vi haresources
drbd1 drbddisk::r0 Filesystem::/dev/drbd0::/opt/apache-tomcat-8.0.27/webapps IPaddr::172.16.22.9/24/eth0 tomcat
heartbeat就按照上述順序掛載資源。
註釋:
drbd1表示主節點的主機名。
IPaddr::172.16.22.9/24/eth0設定虛擬ip
drbddisk::r0 表示管理資源r0,就是在/etc/drbd.d/r0.res裡面定義的資源r0
Filesystem::/dev/drbd0::/opt/apache-tomcat-8.0.27/webapps/::ext4表示執行umount和mount時的操作
tomcat是必須有/etc/init.d/tomcat指令碼。
drbd2節點上的配置和drbd1的基本一致,只是標黃色的不一樣。
drbd2節點:
a)、ha.cf 檔案
debugfile /var/log/ha-debug #開啟錯誤日誌報告
logfile /var/log/ha-log
logfacility local0
keepalive 1 #1秒檢測一次心跳線連線
deadtime 5 #5 秒測試不到主伺服器心跳線為有問題出現
warntime 5 #警告時間(最好在 2 ~ 10 之間)
initdead 10 #初始化啟動時 10 秒無連線視為正常,或指定heartbeat,在啟動時,需要等待10秒才去啟動任何資源。
udpport 694 #用 udp 的 694 埠連線
ucast eth1 172.16.1.72 #單播方式連線(主從都寫對方的 ip 進行連線)
ucast eth0 172.16.22.7 #單播方式連線(主從都寫對方的 ip 進行連線)
node drbd1 #宣告主服(注意是主機名uname -n不是域名)
node drbd2 #宣告備服(注意是主機名uname -n不是域名)
auto_failback off #自動切換(主服恢復後可自動切換回來)這個不要開啟
respawn hacluster /usr/lib64/heartbeat/ipfail #監控ipfail程式是否掛掉,如果掛掉就重啟它
b、authkeys 檔案
[root@drbd2 ha.d]# cat authkeys
auth 1 # 採用何種加密方式
1 crc # 無加密
#2 sha1 HI! # 啟用sha1的加密方式
#3 md5 Hello! # 採用md5的加密方式
c、haresources
[root@drbd2ha.d]# vi haresources
drbd2 drbddisk::r0 Filesystem::/dev/drbd0::/opt/apache-tomcat-8.0.27/webapps IPaddr::172.16.22.9/24/eth0 tomcat
備註:172.16.22.9是vip
9.3 測試主節點當機後,備節點是否自動掛載drbd
a)、首先把drbd1主節點給當機,執行reboot
b)、然後到備節點drbd2上檢視vip(透過命令 ip addr show檢視)已經獲取,透過df –h命令檢視/dev/drbd0已經掛載到相應目錄下面
c)如果主節點drbd1恢復好後,該節點會置為備,並且設定為不會奪回vip。
如果想切換回原來的主備狀態,只需要把drbd2的heartbeat服務重啟一下就行了(/etc/init.d/heartbeat restart),檢視到drbd1上檢視vip已經出現,drbd0掛載到了相應的目錄下面。
至此,heartbeat +drbd配置成功。
10 ·LVM下增加drbd裝置容量
如果發現drbd管理的磁碟邏輯卷空間不足時,可以給該邏輯捲動態增加容量。
如果容量過大,想減小容量也是可以的。不過擴容容易,回收空間就容易出問題了。
不建議收回空間。
假設drbd resource資源r0 對應的media為drbd0,邏輯卷為/dev/vg_drbd/drbd_data
掛載的目錄為/data。則擴容步驟:
1. 備份檔案並解除安裝邏輯卷(只需在primary主機上執行)
[root@DRBD1 conf]# cp -r /data /backup
[root@DRBD1 conf]# umount /data
2. 給邏輯卷擴容20G空間(在primary和secondary主機上都要執行)
[root@DRBD1 conf]# lvresize -L +20G /dev/vg_drbd/drbd_data
3. 重置drdb resource資源 r0。因為drbd服務沒有停止,因此不需要執行e2fsck了。
(只需在primary主機上執行)
[root@DRBD1 conf]# drbdadm resize r0
4. 掛在邏輯卷(只需在primary主機上執行)
[root@DRBD1 conf]# mount /dev/drbd0 /data
5. 重置檔案系統容量
[root@DRBD1 conf]# resize2fs /dev/drbd0
[root@DRBD1 conf]#
到這裡,drbd擴容已經完成。其實第1和第4步可以不用執行的。
減小空間類似操作,將+20G變為-20G就是減少20G空間。
11 錯誤處理
11.1 軟體編譯時,錯誤解決辦法:
1、configure: error: Cannot build utils without flex, either install flex or pass the --without-utils option.
解決方式:yum install flex
11.2 軟體執行時,錯誤解決辦法:
1、[shell]# /etc/rc.d/init.d/drbd start
Starting DRBD resources: no resources defined!
解決辦法:沒有配置DRBD資源,或編譯時沒指定配置檔案路徑(/etc/drbd.conf)。
2、當執行命令”drbdadm create-md r0”時,出現以下錯誤資訊。
Device size would be truncated, which would corrupt data and result in
'access beyond end of device' errors.
You need to either
* use external meta data (recommended)
* shrink that filesystem first
* zero out the device (destroy the filesystem)
Operation refused.
Command 'drbdmeta 0 v08 /dev/xvdb internal create-md' terminated with exit code 40
drbdadm create-md r0: exited with code 40
解決辦法:初始化磁碟檔案格式, dd if=/dev/zero of=/dev/sdXYZ bs=1M count=1
11.3 drbd腦裂手動恢復過程
drbd出現腦裂的幾種情況:
a)備節點長期不線上
其實drbd的對等節點如果不線上的話,即主節點的資料更改如果無法及時傳送到備節點達到一定時間,會造成資料不一致,即使故障節點在長時間離線後恢復,drbd可能也不能正常同步了。或者另外一種情況,主備都線上,但心跳網路斷了而出現腦裂,兩個節點都認為自己是主節點,也會造成兩個節點的資料不一致,這樣需要人工干預,告訴drbd以哪個節點為主節點,或者在drbd配置腦裂的行為。下面是長時間備節點不線上後出現的情況:
b)主節點意外當機
思想:(以drbd1的資料位主,放棄drbd2不同步資料):
1)將Drbd1設定為主節點並掛載測試,r0為定義的資源名
[shell]# drbdadm primary r0
[shell]# mount /dev/drbd0 /mnt/drbd0
[shell]# ls -lh /mnt/drbd0 檢視檔案情況
2)將Drbd2設定為從節點並丟棄資源資料
[shell]# drbdadm secondary r0
[shell]# drbdadm -- --discard-my-data connect r0 #從主節點同步資料,並且discard自己的資料
3)在Drbd1主節點上手動連線資源
[shell]# drbdadm connect r0
4)最後檢視各個節點狀態,連線已恢復正常
[shell]# cat /proc/drbd
案例:
drbd1為主,drbd2為輔;我個人覺得這個DRBD腦裂的行為,也應該是前期人為或是故障切換造成的,
如HA。 上次跟一朋友去一客戶那裡,他那就是屬於使用HA做故障切換,最後不知道他們咋搞,在一臺機上把DRBD的服務給掛了,因為該伺服器非常重要,他們對HA及DRBD架構不太熟,在一次HA切換測試過程中出現了問題,在此模擬一下這個問題吧。
1、斷開primary
down機或是斷開網線
2、檢視secondary機器的狀態
[root@drbd2 ~]# drbdadm role r0
Secondary/Unknown
[root@drbd2 ~]# cat /proc/drbd
version: 8.3.11 (api:88/proto:86-96)
GIT-hash: 0de839cee13a4160eed6037c4bddd066645e23c5 build by root@drbd2.localdomain, 2011-07-08 11:10:20
#注意下drbd2的cs狀態
1: cs:WFConnection ro:Secondary/Unknown ds:UpToDate/DUnknown C r-----
ns:567256 nr:20435468 dw:21002724 dr:169 al:229 bm:1248 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
因為drbd1當機了,假如drbd1無法啟動,這時就需要手動將drbd2提升為,如下:
將secondary配置成primary角色
[root@drbd2 ~]# drbdadm primary r0
[root@drbd2 ~]# drbdadm role r0
Primary/Unknown
[root@drbd2 ~]# cat /proc/drbd
version: 8.3.11 (api:88/proto:86-96)
GIT-hash: 0de839cee13a4160eed6037c4bddd066645e23c5 build by root@drbd2.localdomain, 2011-07-08 11:10:20
1: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r-----
ns:567256 nr:20435468 dw:21002724 dr:169 al:229 bm:1248 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
#掛載
[root@drbd2 ~]# mount /dev/drbd0 /mnt/
[root@drbd2 ~]# cd /mnt/
[root@drbd2 mnt]# ll
total 102524
-rw-r--r-- 1 root root 104857600 Jul 8 12:35 100M
drwx------ 2 root root 16384 Jul 8 12:33 lost+found
#如果原來的primary機器好了,會出現腦裂。
[root@drbd1 ~]# tail -f /var/log/messages
Jul 8 13:14:01 localhost kernel: block drbd1: helper command: /sbin/drbdadm initial-split-brain minor-1 exit code 0 (0x0)
Jul 8 13:14:01 localhost kernel: block drbd1: Split-Brain detected but unresolved, dropping connection!
Jul 8 13:14:01 localhost kernel: block drbd1: helper command: /sbin/drbdadm split-brain minor-1
Jul 8 13:14:01 localhost kernel: block drbd1: helper command: /sbin/drbdadm split-brain minor-1 exit code 0 (0x0)
Jul 8 13:14:01 localhost kernel: block drbd1: conn( NetworkFailure -> Disconnecting )
Jul 8 13:14:01 localhost kernel: block drbd1: error receiving ReportState, l: 4!
Jul 8 13:14:01 localhost kernel: block drbd1: Connection closed
Jul 8 13:14:01 localhost kernel: block drbd1: conn( Disconnecting -> StandAlone )
Jul 8 13:14:01 localhost kernel: block drbd1: receiver terminated
Jul 8 13:14:01 localhost kernel: block drbd1: Terminating receiver thread
[root@drbd1 ~]# drbdadm role r0
Primary/Unknown
[root@drbd2 mnt]# drbdadm role r0
Primary/Unknown
#drbd1現在是standalone,這個時候,主跟輔是不會相互聯絡的。
[root@drbd1 ~]# cat /proc/drbd
version: 8.3.11 (api:88/proto:86-96)
GIT-hash: 0de839cee13a4160eed6037c4bddd066645e23c5 build by root@drbd1.localdomain, 2011-07-08 11:10:38
1: cs:StandAlone ro:Primary/Unknown ds:UpToDate/DUnknown r-----
ns:20405516 nr:567256 dw:567376 dr:20405706 al:2 bm:1246 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
[root@drbd1 /]# service drbd status
drbd driver loaded OK; device status:
version: 8.3.11 (api:88/proto:86-96)
GIT-hash: 0de839cee13a4160eed6037c4bddd066645e23c5 build by root@drbd1.localdomain, 2011-07-08 11:10:38
m:res cs ro ds p mounted fstype
1:fs StandAlone Primary/Unknown UpToDate/DUnknown r----- ext3
這個時候,如果使用者有嘗試把drbd2的drbd服務重啟的話,你就會發現根本無法起來!
[root@drbd2 /]# service drbd start
Starting DRBD resources: [ ]..........
***************************************************************
DRBD's startup script waits for the peer node(s) to appear.
- In case this node was already a degraded cluster before the
reboot the timeout is 120 seconds. [degr-wfc-timeout]
- If the peer was available before the reboot the timeout will
expire after 0 seconds. [wfc-timeout]
(These values are for resource 'fs'; 0 sec -> wait forever)
To abort waiting enter 'yes' [ -- ]:[ 13]:[ 15]:[ 16]:[ 18]:[ 19]:[ 20]:[ 22]:
在drbd2處理方法:
[root@drbd2 /]# drbdadm disconnect r0
[root@drbd2 /]# drbdadm secondary r0
[root@drbd2 /]# drbdadm connect --discard-my-data r0 #這句話表示從主節點同步資料,並且discard自己節點的資料
做完以上三步,你發現你仍然無法啟動drbd2上的drbd服務;上次一客戶我個人估計就是這個問題,把DRBD重啟後,無法啟動DRBD。
把他們DBA急的要死。呵呵
需要在drbd1上重連線資源:
[root@drbd1 ~]# drbdadm connect r0
再次啟動drbd2上的drbd服務,成了。
[root@drbd2 /]# service drbd start
Starting DRBD resources: [ ].
再看看資源同步:
[root@drbd2 /]# cat /proc/drbd
version: 8.3.11 (api:88/proto:86-96)
GIT-hash: 0de839cee13a4160eed6037c4bddd066645e23c5 build by root@drbd2.localdomain, 2011-07-08 11:10:20
1: cs:SyncTarget ro:Secondary/Primary ds:Inconsistent/UpToDate C r-----
ns:0 nr:185532 dw:185532 dr:0 al:0 bm:15 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:299000
[======>.............] sync'ed: 39.5% (299000/484532)K
finish: 0:00:28 speed: 10,304 (10,304) want: 10,240 K/sec
大夥來拍磚吧!
補充:雖然是手工模擬但在故障切換時也會出一樣的問題。
1、DRBD的資源只能在或主或輔的一臺機器上掛載。
2、在做主輔的手工切換時的步驟:
a、先將原來掛載的東西進行解除安裝,這個時候你的應用會停,不建議手工切換主輔
b、將原來的主設定成輔 #drbdadm secondary r0
c、將原來的輔設定成主 #drbdadm primary r0
d、掛載資源
12 附件


13 參考資料
--這個文件重點看
附件列表
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/28916011/viewspace-2124621/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- heartbeat安裝配置實驗
- OVS + dpdk 安裝與實驗環境配置
- 安裝配置驗證COST(orapki)APK
- SAP安裝實驗
- Flutter安裝、配置、初體驗 windows 版FlutterWindows
- Zabbix安裝實驗報告
- [實踐]wireguard安裝和配置
- 解除安裝oracleasm實驗模擬OracleASM
- 【11g 單庫解除安裝、靜默安裝】實驗
- 本地windows搭建spark環境,安裝與詳細配置(jdk安裝與配置,scala安裝與配置,hadoop安裝與配置,spark安裝與配置)WindowsSparkJDKHadoop
- Kafka 簡單實驗一(安裝Kafka)Kafka
- 安信實驗室教你如何實現Windows自動安裝!Windows
- zabbix安裝—–nginx安裝和配置Nginx
- 實驗5.OSPF配置實驗
- OCM實驗-grid control安裝
- 【實驗】【STATSPACK】Statspack 安裝、測試與使用
- Perl的NT安裝實驗報告(轉)
- Zookeeper 安裝配置
- 【mongodb安裝配置】MongoDB
- ceph安裝配置
- ELK 安裝配置
- Prometheus安裝配置Prometheus
- MySQL安裝配置MySql
- SwitchOmega 安裝配置
- Hive安裝配置Hive
- JWT安裝配置JWT
- oracle安裝配置Oracle
- VNC安裝配置VNC
- rlwrap 安裝配置
- otrs安裝配置
- Sybase安裝配置
- memcache安裝配置
- mfs安裝配置
- storm安裝配置ORM
- Mysql 安裝 配置MySql
- memcached 安裝配置
- Mycat 安裝配置
- ANT安裝、配置