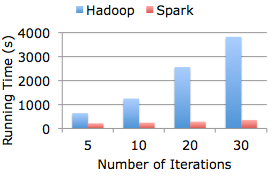
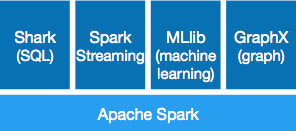
Spark 是一種與 Hadoop 相似的開源叢集計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了記憶體分佈資料集,除了能夠提供互動式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程式框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密整合,其中的 Scala 可以像操作本地集合物件一樣輕鬆地操作分散式資料集。
儘管建立 Spark 是為了支援分散式資料集上的迭代作業,但是實際上它是對 Hadoop 的補充,可以在 Hadoo 檔案系統中並行執行。通過名為 Mesos 的第三方叢集框架可以支援此行為。Spark 由加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發,可用來構建大型的、低延遲的資料分析應用程式。
相關連結
相關閱讀
評論(1)