Native accessors(原生訪問器)
-
原生 Python 物件為索引資料提供了很好的方法。Pandas 繼承了所有這些方法,這有助於輕鬆上手。
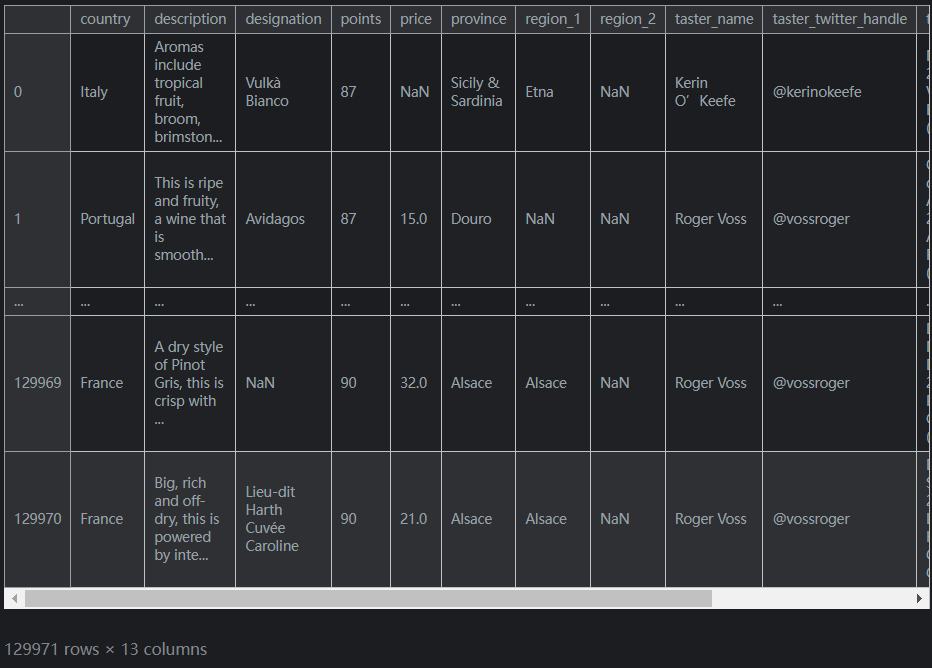
考慮這個DataFramereviews輸出如下(未截全):
-
在Python中,我們可以透過將物件作為屬性訪問來訪問它的屬性。例如,book物件可能有一個title屬性,我們可以透過呼叫book. title來訪問它。DataFrame中的列的工作方式大致相同。
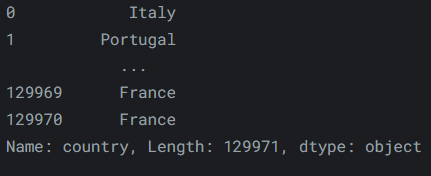
因此,要訪問“reviews”的“country”屬性,我們可以使用:reviews.country輸出如下:
-
如果我們有Python字典,我們可以使用索引運算子
[]運算子訪問它的值。我們可以對DataFrame中的列執行相同的操作:reviews['country']輸出如下:
-
這些是從
DataFrame中選擇特定序列的兩種方法。它們在語法上沒有誰比誰更正確,但是索引運算子[]確實有一個優勢,即它可以處理包含保留字元的列名(例如,如果我們有一個“country providence”列,“reviews.country providence”將不起作用)。
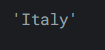
- pandas看起來是不是有點像花哨的字典?幾乎是這樣,所以毫不奇怪,要深入到一個特定的值,我們只需要再次使用索引運算子
[]:
輸出如下:reviews['country'][0]
-
Indexing in pandas(pandas 中的索引)
- 索引運算子和屬性選擇很不錯,因為它們的工作方式與 Python 生態系統中的其他部分一樣。對於新手來說,這使得它們易於掌握和使用。然而,Pandas 有自己的訪問器運算子
loc和iloc。對於更高階的操作,這些是應該使用的運算子。
Index-based selection(基於索引的選擇)
- Pandas索引工作在兩種正規化之一。第一個是基於索引的選擇:根據資料中的數字位置選擇資料。
iloc遵循這個正規化。-
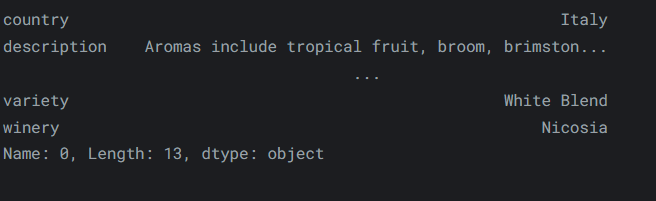
要選擇
DataFrame中的第一行資料,我們可以使用以下方法:reviews.iloc[0]輸出如下:
-
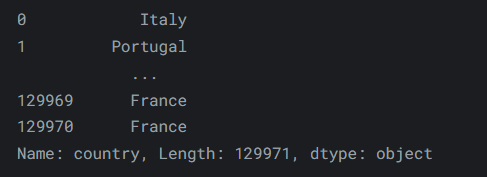
loc和iloc都是先行後列。這與我們在原生 Python 中的做法相反,原生 Python 是先列後行。這意味著檢索行稍微容易一些,而檢索列稍微困難一些。要使用iloc獲取一列,我們可以執行以下操作:reviews.iloc[:, 0]輸出如下:
-
單獨來看,同樣來自原生 Python 的“:”運算子表示“所有內容”。然而,當與其他選擇器結合使用時,它可以用於表示一系列值。
-
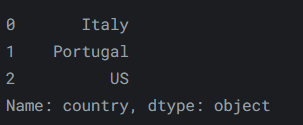
例如,要僅從第一行、第二行和第三行中選擇“country”列,我們可以這樣做:
reviews.iloc[:3, 0]輸出如下:
-
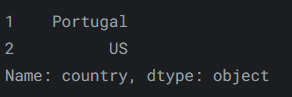
或者,若僅選擇第二個和第三個條目,我們可以這樣做:
reviews.iloc[1:3, 0]輸出如下:
-
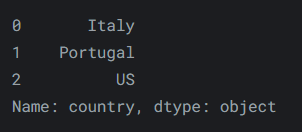
也可以傳遞一個列表。
reviews.iloc[[0, 1, 2], 0]輸出如下:
-
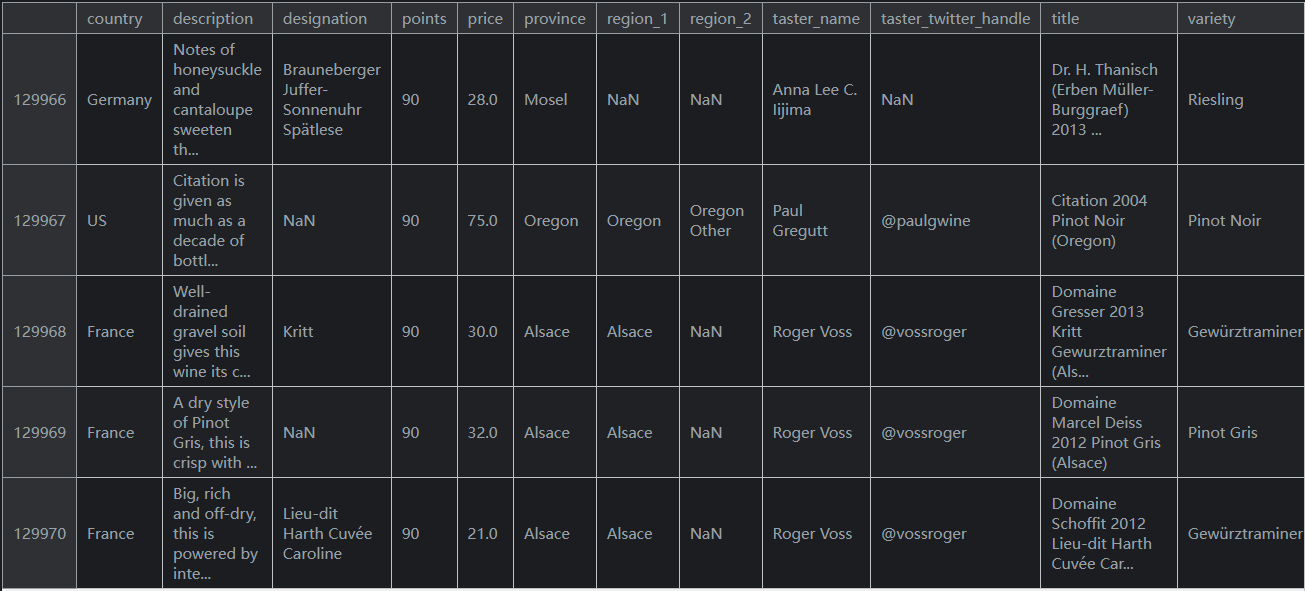
最後,值得知道的是負數可以用於選擇。這將從值的末尾開始向前計數。例如,這是資料集的最後五個元素。
reviews.iloc[-5:]輸出如下(列方面沒截全):
-
-
Label-based selection(基於標籤的選擇)
- 屬性選擇的第二個範例是
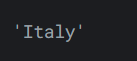
loc運算子遵循的範例:基於標籤的選擇。在這個範例中,重要的是資料索引值,而不是它的位置。- 例如,要獲取 reviews 中的第一個條目,我們現在可以按如下方式進行:
輸出如下:reviews.loc[0, 'country']
- 例如,要獲取 reviews 中的第一個條目,我們現在可以按如下方式進行:
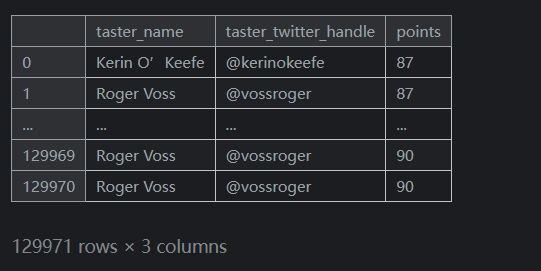
iloc在概念上比loc簡單,因為它忽略了資料集的索引。當我們使用iloc時,我們將資料集視為一個大矩陣(列表的列表),我們必須按位置索引。相比之下,loc使用索引中的資訊來完成其工作。由於您的資料集通常具有有意義的索引,因此使用loc通常更容易做事。例如,這裡有一個使用loc更容易的操作:
輸出如下:reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
Choosing between loc and iloc(在loc和iloc之間選擇)
-
在
loc和iloc之間選擇或轉換時,有一個“明白”值得記住,那就是這兩種方法使用略有不同的索引方案。 -
iloc使用 Python 標準庫的索引方案,範圍的第一個元素被包含在內,而最後一個元素被排除在外。所以 0:10 將選擇條目 0,……,9。同時,loc是包含性索引。所以 0:10 將選擇條目 0,……,10。 -
為什麼會有這種變化呢?請記住,
loc可以對任何標準庫型別進行索引,例如字串。如果我們有一個DataFrame,其索引值為Apples, ..., Potatoes, ...,並且我們想要選擇“在‘Apples’和‘Potatoes’之間所有按字母順序排列的水果選項”,那麼使用df.loc['Apples':'Potatoes']進行索引比使用類似df.loc['Apples', 'Potatoet'](在字母表中t在s之後)要方便得多。 -
當
DataFrame的索引是一個簡單的數字列表時,這尤其令人困惑,例如 0,…,1000。在這種情況下,df.iloc[0:1000]將返回 1000 個條目,而df.loc[0:1000]將返回 1001 個條目!要使用loc獲取 1000 個元素,你需要將範圍縮小一個,請求df.loc[0:999]。
Manipulating the index(操縱索引)
- 基於標籤的選擇依靠索引中的標籤。關鍵是,我們使用的索引並非不可變的。我們可以以任何我們認為合適的方式操作索引。
set_index()方法可用於完成這項工作。以下是當我們將索引設定為“title”欄位時會發生的情況:
輸出如下:reviews.set_index("title")
如果您能為資料集提出比當前索引更好的索引,這將很有用。
Conditional selection(條件選擇)
- 到目前為止,我們一直在使用
DataFrame本身的結構屬性索引各種資料。然而,要對資料做有趣的事情,我們經常需要根據條件提出問題。-
例如,假設我們特別對義大利生產的高於平均水平的葡萄酒感興趣。
-
我們可以先檢查每一種葡萄酒是否是義大利產的:
reviews.country == 'Italy'輸出如下:
-
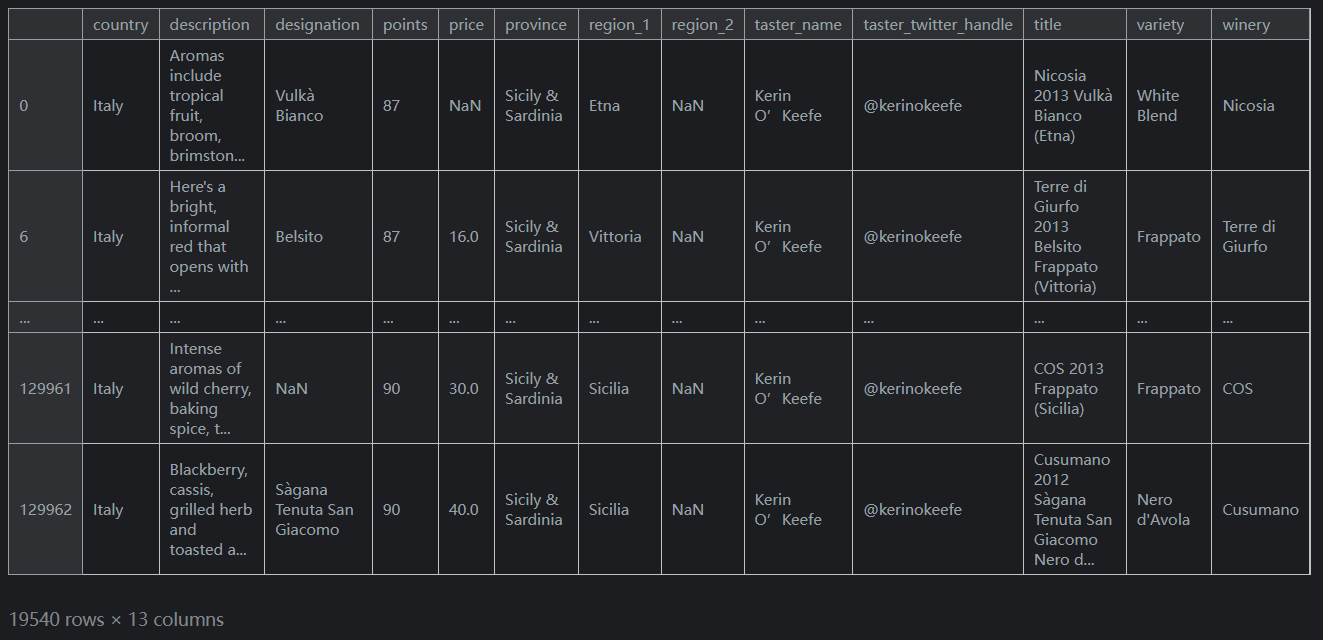
此操作根據每條記錄的國家/地區生成一系列
True/False布林值。然後可以在loc內部使用此結果來選擇相關資料:reviews.loc[reviews.country == 'Italy']輸出如下:
-
這個
DataFrame有大約20,000行。原來有大約130,000行。這意味著大約15%的葡萄酒來自義大利。
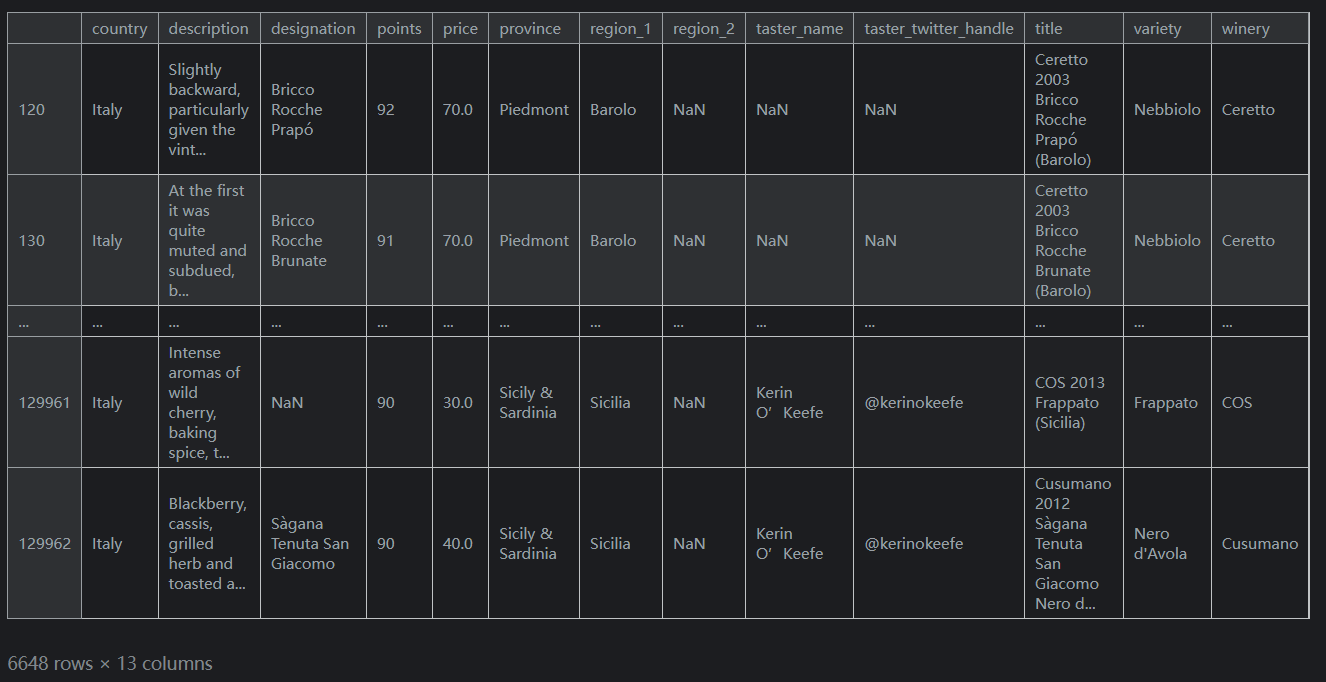
我們也想知道哪些葡萄酒比平均水平更好。葡萄酒的評分範圍是 80 到 100 分,所以這可能意味著至少獲得 90 分的葡萄酒。
我們可以使用&符號將這兩個問題結合起來。reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)]輸出如下:
-
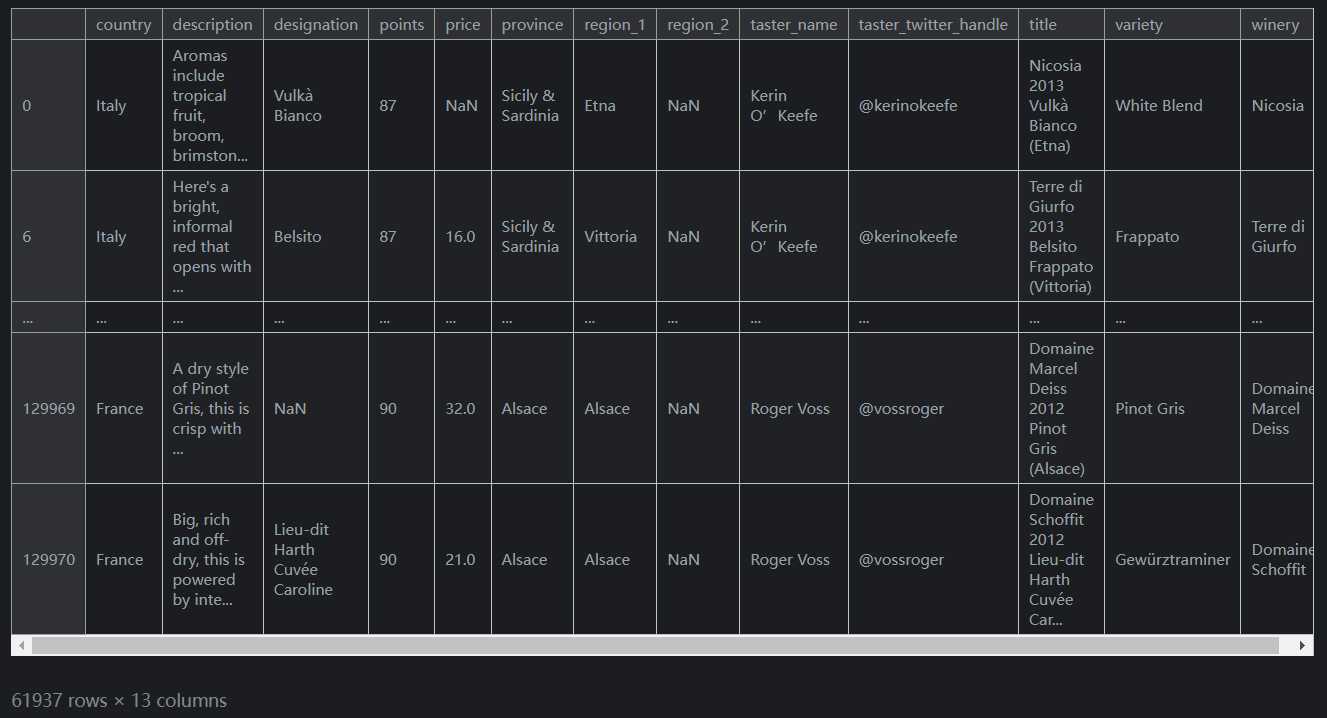
假設我們將購買任何義大利製造的葡萄酒或評級高於平均水平的葡萄酒。為此,我們使用
|符號:reviews.loc[(reviews.country == 'Italy') | (reviews.points >= 90)]輸出如下:
-
-
Pandas 帶有一些內建的條件選擇器,我們將在這裡重點介紹其中兩個。
-
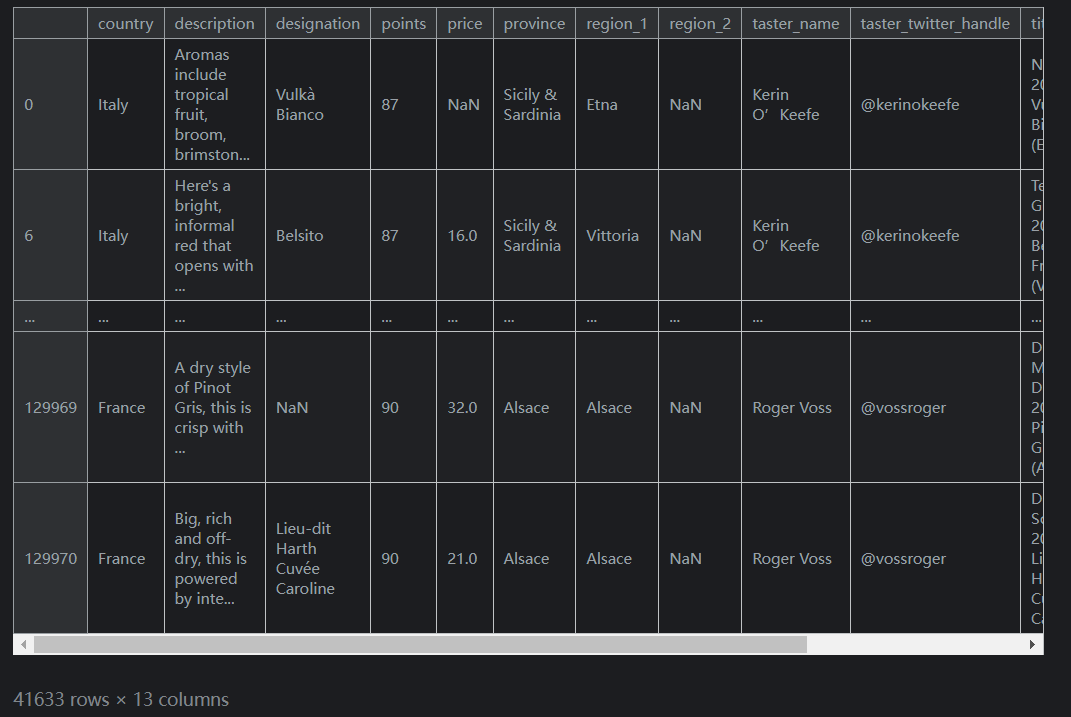
第一個是
isin。isin允許您選擇其值“在”值列表中的資料。例如,以下是我們如何使用它來選擇僅來自義大利或法國的葡萄酒:reviews.loc[reviews.country.isin(['Italy', 'France'])]輸出如下(列未截全):
-
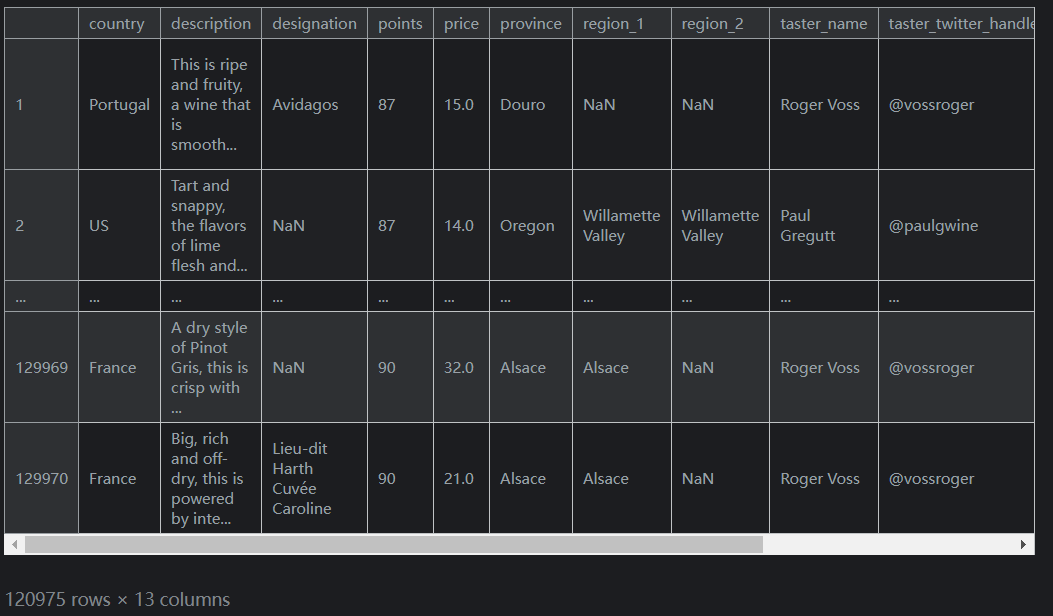
第二個是
isnull(及其配套的notnull)。這些方法允許您突出顯示為(或不為)空(NaN)的值。例如,要過濾掉資料集中沒有價格標籤的葡萄酒,我們會這樣做:reviews.loc[reviews.price.notnull()]輸出如下(列未截全):
-
-
Assigning data(分配資料)
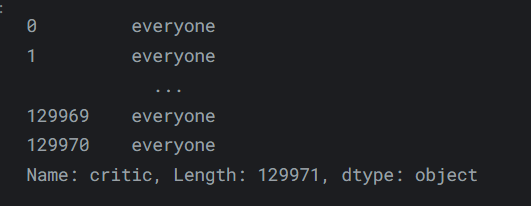
- 反過來,向
DataFrame分配資料很容易。你可以分配一個常量值:
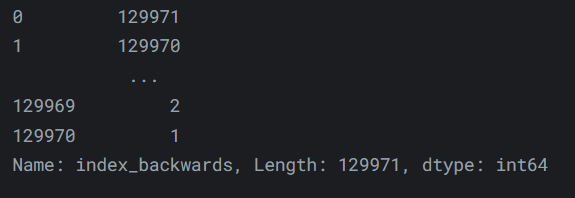
輸出如下:reviews['critic'] = 'everyone' reviews['critic']
- 或者使用一個值的可迭代物件:
輸出如下:reviews['index_backwards'] = range(len(reviews), 0, -1) reviews['index_backwards']