一套大而全的系統架構體系與具體落地方案
寫在最前面
上次參加DBAplus舉辦的敏捷運維峰會時,一個兄弟的提問一直縈繞耳邊,由於時間有限沒有進行深入的交流,甚是遺憾。那個問題是:你們公司的IT系統架構是怎樣的?又如何具體落地?採用了哪些開源或是商業的技術?
其實之前也寫過或是做過一些關於系統架構的分享,或多或少的個人或其它限制,總覺得未能盡興,留有遺憾。因此經過最近一個多月的總結和梳理,在這寫出來跟大家做一個分享,這也是對我個人技術生涯中系統架構部分做一個階段性的總結,以便往後能夠更好地投入到接下來的雲平臺架構和機器學習,以及企業如何降低IT成本的深入研究中。

系統架構是一個比較大的話題,以一個什麼樣的思路或是方法進行切入很重要。系統架構的脈絡可以讓我們很好地瞭解系統架構的整體概況,也可以幫助我們建立有效的個人架構知識體系。
本文從系統訪問鏈路為切入點,圍繞訪問鏈路的方方面面,包括基礎設施、分層架構、分割架構、系統保障、技術平臺生態圈等幾個方面進行展開,力求展現出一套相對比較完整的系統架構體系,同時結合自身經驗,介紹具體落地的方案和技術,希望能夠給讀者帶來一些收穫。
一、訪問鏈路
訪問鏈路表示從使用者訪問請求到最終生產伺服器響應,再到反饋給使用者請求的結果資訊這一過程。不管是網際網路企業還是傳統企業,在系統架構中一定要明確自己的訪問鏈路,這對系統優化、系統排故、鏈路監控等至關重要。
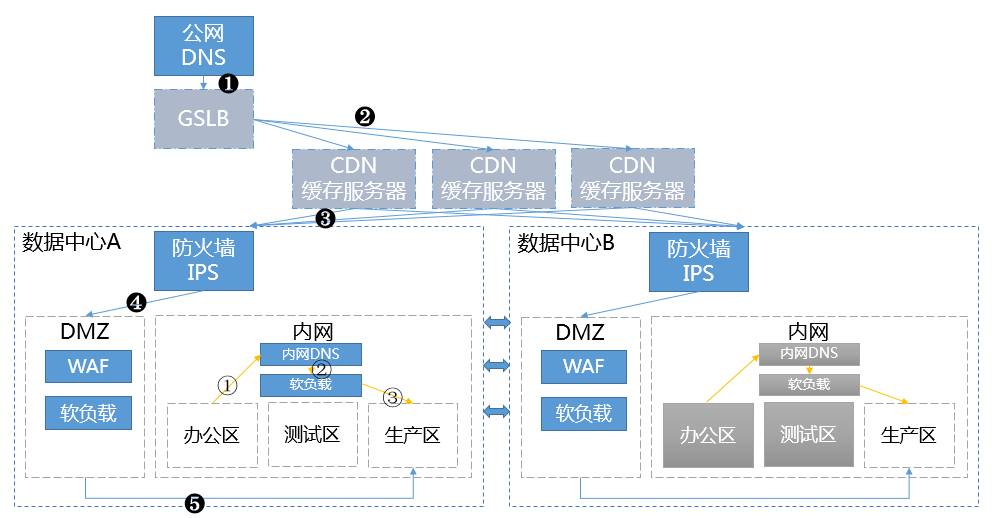
該圖是一家中小型公司的訪問鏈路圖,系統主要分為兩大塊:一是對外提供服務的電商平臺;另外一塊是企業內部的核心生產系統和企業資訊系統等。灰色部分表示正在建立或是規劃建立的部分。
該公司訪問鏈路主要有兩條:一條是外部客戶的外網訪問鏈路,另一條是內部員工的內網訪問鏈路。該公司是有自建的資料中心機房,可能現在很多公司都將對外訪問的系統放到租賃的IDC機房或是雲伺服器,其實都是一樣的。根據系統特點劃分內外網訪問鏈路,可以節省網路流量,也可以增強內部系統的安全性等。
1、外網訪問鏈路
公網DNS->GSLB->CDN->防火牆/IPS->WAF->軟負載->生產伺服器。
外網訪問鏈路從公網DNS開始,按照使用者訪問請求的全鏈路,完整的DNS解析過程應該是這樣的:
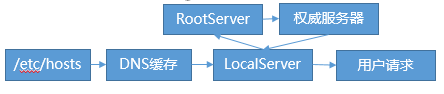
使用者本地Host->使用者DNS快取->LocalServer(本地DNS電信、聯通等)->Root伺服器->權威伺服器->LocalServer->使用者得到DNS解析結果->請求等。
2 、內外訪問鏈路
內外DNS->軟負載->生產伺服器
圖中資料中心B暫時為備份機房,提供實時同步和延遲同步兩種備份方式。有一些大型集團公司可能多個資料中心同時在用,這個時候有的是採用專線的方式,也有的是採用伺服器直接部署在雲中,這個需要根據專線和雲服務的成本(其實雲服務的價格不一定低),以及資料的保密性等進行選擇。
其實上面的訪問鏈路也有一定的潛在問題:
當外網訪問量大的時候,硬體防火牆和WAF將會成為一定的瓶頸,需要進行優化、限流或是直接摘除,轉為在軟防火牆或是應用WAF進行分散式防護;還有一點就是對防火牆和WAF的策略要求較高,要避免漏殺或是誤殺的情況出現。
內網的安全性問題。內網的DNS和軟負載沒有有效地提供內網對生產伺服器的保護。這個需要從兩方面加強:
一是對辦公區PC機的防病毒客戶端安裝並及時更新策略;
二是在軟負載層增加安全策略,一般兩種方式:
調整WAF的策略或是網路位置,對內網進行安全防護;
直接購買新的WAF放在內網區,但這會增加成本,同時讓訪問鏈路更復雜。
其實可以在內網部署開源WAF或是結合Nginx做安全防護,這裡推薦一款Nginx+Lua做的安全防護模組:https://github.com/loveshell/ngx_lua_waf。
訪問鏈路要儘可能的高效、安全、簡單。每一個系統架構師一定要對自己企業或是產品的訪問鏈路瞭然於胸,在系統使用者反饋故障或是效能問題時,深入分析鏈路中的每一個元素找到故障點或是效能瓶頸,進行處理或優化。
二、基礎設施
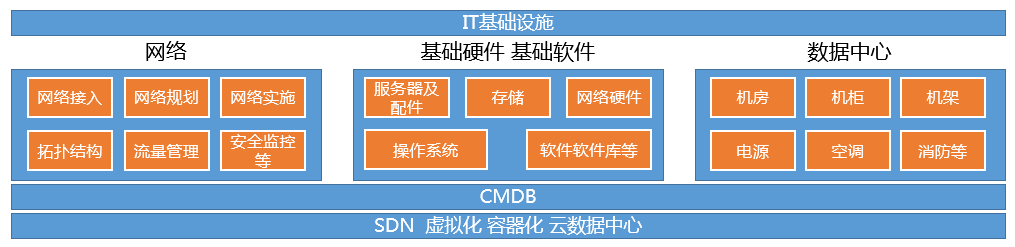
基礎設定主要包括網路、基礎硬體/基礎軟體、資料中心這三部分,以及圍繞基礎設施做的軟體定義網路(SDN)、虛擬化容器化、雲資料中心等,力求做到上層IT架構可以不用去過多考慮基礎設施。
1、網路
網路方面包括:網路接入、網路規劃、網路實施、拓撲結構、流量管理、安全監控等幾個方面。
首先是網路接入,由於中國特殊的網路環境,對於需要對外提供服務的系統一般都需要考慮多網路供應商的接入,包括移動、聯通、電信等。不同的網路接入對外提供服務時,會依賴智慧DNS等手段,實現不同網路環境連線至不同公網IP,儘量避免跨網路供應商的訪問,提高訪問速度。
網路規劃主要包括區域網的規劃和劃分,一般情況是需要分隔離區(DMZ)、辦公區、測試區、生產區等幾個區域,不同區域之間通過防火牆等安全裝置進行有效隔離。另外,廣義上的網路規劃還包括資料流量及約束條件分析、網路選型、拓撲結構設計、網路安全、建設方案等幾個方面。
接下來是網路實施。根據網路規劃和網路建設方案,進行網路的部署和實施。
不管傳統企業還是網際網路公司,一定要有自己的網路拓撲結構圖,這樣網路架構清晰明瞭,當網路故障時,對於故障點、影響範圍等都可以通過網路拓撲結構圖快速獲得。網路拓撲要實時更新,時刻保持與真實網路環境一致。
要對網路的流量進行管理和實時監控。根據網路流量合理調整網路頻寬等。整個網路基礎設施中的網路安全不可或缺。一般通過防火牆、IPS/IDS等軟硬體裝置進行網路安全的防護或是監控、分析和遮蔽絕大部分的網路攻擊行為。
網路作為重要的基礎設施之一,要根據安全策略和實際業務量、業務情況等幾個方面進行合理的規劃和實施,完善網路拓撲結構,通過監控和流量管理等手段,實時瞭解網路以及網路裝置的執行情況,當出現故障或是效能問題時,能夠快速發現故障源或是效能瓶頸點,以便有重點地進行排故、調優。
2、基礎軟硬體
1基礎硬體
基礎硬體包括伺服器、記憶體、CPU、儲存、電源、防火牆、交換機、路由器、集線器等伺服器、網路及周邊硬體設施。
基礎硬體及其備件一般有雙份或是多份,避免硬體單點故障,也就是說一般企業要有自己的備件庫,對伺服器、儲存、網路裝置等硬體進行備份,當出現問題時,可以及時更換。備件庫的資訊也要跟隨CMDB一起入庫管理。
2基礎軟體
基礎軟體包括作業系統ISO檔案、資料庫安裝檔案、應用伺服器安裝檔案等基礎軟體,也包括辦公用的Office、瀏覽器等軟體。
根據個人經驗,推薦一種相對比較好且易於部署管理的基礎軟體管理方式。根據軟體的性質進行如下分類,請大家參考:

將上述軟體進行統一整理,部署到一臺Nginx伺服器上作為靜態資源,並建立二級域名如soft.xxx.com。這樣區域網內使用者在使用軟體時,直接通過訪問soft.xxx.com進行下載安裝即可。這樣做的一個好處是可以管理公司的基礎軟體,並且規範版本號,避免多種版本的存在。以下是使用Nginx搭建的一個軟體庫,僅用來說明。

3、資料中心
如今越來越多的公司採用雲服務進行系統部署,省去了自建資料中心機房等比較繁雜的事情。短時間來看對企業是非常有利的,因為快且方便,可以適應企業的快速發展。但隨著企業的規模不斷變大,大量的使用雲服務,IT成本會越來越高,自建資料中心可能會逐漸成為一種比較經濟的方式。自建資料中心和雲服務本身是沒有矛盾且可以科學組合、相輔相成的。企業哪一階段哪一種方式最優,要根據企業的業務實際情況和進行科學的計算後才可判斷哪種方式最經濟。(注:這裡的雲服務是指的公有云)
當然也有一些企業因為自身資料的保密性比較高,業務相對比較特殊,所以一開始就自建資料中心機房。
一般而言,資料中心機房的建設要按照國家標準和行業標準進行建立,這都有比較明確的標準規範,這裡大概總結了一下:

資料中心的建立有自建或是委託專業資料中心設計公司來進行。一般公司可以通過第二種方式,通過與專業的資料中心設計公司合作,建設安全、可靠、伸縮性強以及節能環保的資料中心。
另外資料中心的建立、驗收、等級、災備等都有著明確的國家規範和行業行規,大家在規劃或建立的時候,一定在合規的底線上,進行優化設計,常用的資料中心參考文件有:
《資料中心建設與管理指南》
《GB50174-2017 資料中心設計規範》
《GB50462-2015資料中心基礎設施施工及驗收規範》
《GBT22239—2008資訊系統安全等級保護基本要求》
TIA-942《資料中心電信基礎設施標準》(中文版)等等
【提示】由於文件打包較大,感興趣的同學可點選連結https://pan.baidu.com/s/1eR7RyPO或點選文末【連結】進行下載。
4、基礎設施管理與優化
1基礎設施管理
對於基礎設施的管理,需要CMDB結合資產管理系統對基礎設施進行統一錄入、上架、管理、下架、報廢等全生命週期進行管理。通過IT系統進行基礎設施管理,可以提高管理效率,降低故障率等。CMDB作為運維管理體系中的基礎一環,至關重要。一些中小型企業可能暫時沒有能力建立或是購買CMDB,這時可以通過採用構建開源CMDB或是直接用最簡單有效的Excel進行管理,總之,不管哪種方式,基礎設施的集中管理不可或缺。CMDB中的資料一定要與實際環境實時對應,確保準確無延遲。
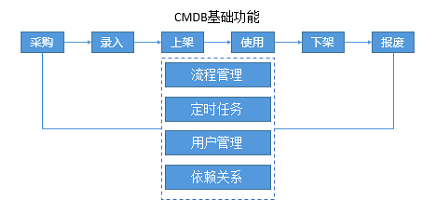
2基礎設施優化
為了更高效地利用基礎設施的資源,虛擬化、容器化正在不同的公司中逐漸實行。本文以一些中小公司(包括我們公司)常見的基礎架構演變路線進行介紹。

很多公司遵循著多臺物理機到虛擬化再到容器化或是虛擬化容器化並存,最終實現到雲服務的這一演變過程。首先是初始階段的多臺物理機部署服務,資源利用率比較粗,相對比較浪費,於是通過虛擬化提高資源的利用率和管理效率。我所經歷的一家公司正處在虛擬化階段,通過購買fc-san儲存,構建虛擬化叢集,實現伺服器的高效利用、叢集高可用並且便於備份。但在虛擬化的過程中,也經歷著虛擬化的以下問題:
搭建成本太高,需要購買專業儲存以及網路裝置等。(當然也可以直接在物理機上部署exsi,但是高可用不是很好實現,例如VMare自帶的高可用元件)
虛擬機器備份比較笨重,需要結合BE或是自帶的備份工具,耗時較長,備份粒度不夠細。
服務當機後虛擬機器漂移時間相對較長,大概5分鐘左右(跟硬體和技術有關係,有的公司可能時間很短)。漂移後虛擬機器自動重啟,如果部署在虛擬機器上的服務未開機自啟,將比較頭疼。
部署虛擬機器時間較長,雖然採用Cobbler等方式實現自動安裝,但部署一套虛擬機器,大概在10~20分鐘左右。
以上四點是我們在做虛擬化時,面臨著比較突出的問題,當然這也許跟我們虛擬化工程師的技術水平有一定的關係。為了解決虛擬化的問題,提高運維效率,我們現在正進行虛擬化+容器化並存的架構改進和優化,當前架構如下:

注:基礎設施架構這一塊,目前我們面臨這1~2年後的資料中心遷移以及新資料中心規劃,後續我們的規範方案和遷移方案定稿後,會繼續跟大家分享、探討。
可以看出,當前基礎資源架構是虛擬化和容器化並存,二者相互隔離又在應用層面相互聯絡,共同組成叢集,為上層應用提供服務。
相比虛擬化以及物理機,單純容器化有以下幾個難點不太好實現:
Windows伺服器在Docker容器不能或是不容易部署。(據稱Docker已經開始支援win,但未研究測試)
Oracle資料庫在Docker部署缺少大規模生產經驗,不敢貿然直接在容器部署Oracle伺服器。尤其是RAC+DG這樣的高可用叢集,在容器部署也不太現實。
就目前我們技術現狀來說,單純容器化有一定的風險,需要一個摸索階段,雖然有很多成熟的經驗可以借鑑,但畢竟適合自己的架構才是最好的。
基於容器的便利性以及高效快捷,未來會逐漸以容器化為主,但資料庫和Window服務相關的部署以虛擬化為主,二者互補,為以後實現雲服務提供基礎鋪墊。
容器化管理計劃以K8s為主進行編排和排程,K8s目前正在技術調研和測試中,待成熟後會為大家繼續進行分享。當然我們也面臨著是否需要採用OpenStack或是其它技術搭建IaaS基礎雲平臺的糾結。
不管系統架構還是基礎架構,都是一個逐漸演化的過程,適合當下業務架構並且易伸縮的架構才是最優化的架構。
三、分層架構
1 、分層架構概述
系統在做分層架構候,一般情況下主要包括:接入層、應用層、公共服務層、資料儲存層等幾個層次,其中接入層還包括DNS轉發、CDN、負載均衡層、靜態資源層等。有CDN的公司會直接將靜態資源放在CDN層中。
系統分層架構圖大概如下:

2、負載均衡和反向代理
負載均衡分為軟負載和硬負載。其中硬負載包括有F5、A10等不同品牌的硬體負載均衡器,軟負載包括LVS、Nginx、HAproxy等開源軟負載均衡軟體。硬負載相對比較貴,成本較高。中小企業可以選擇開源的軟負載實現負載均衡和反向代理,通過負載均衡提高系統的吞吐從而提高效能,反向代理增加內部系統的安全性。負載均衡伺服器一般是部署在DMZ區域與內網通過防火牆進行埠對映,提高內網伺服器的安全。
軟負載的選擇上一般從LVS、Nginx、HAproxy三者中進行選擇或是組合選擇。其中LVS相比Nginx、HAproxy、LVS工作在網路四層,僅做請求轉發,效能效率比較高。Nginx和HAproxy工作在網路七層之上,較LVS效能差一些,但二者之間,並沒有特別大的差別。
使用負載均衡和反向代理一般要著重考慮以下三個問題:
高可用問題
負載策略
有狀態服務的session儲存
(1)實現負載均衡伺服器的高可用一般通過虛擬IP的方式,將虛擬IP通過防火牆與公網IP埠轉換,對外提供服務,常用的開源元件有keepalived。但在使用開源元件進行虛擬IP配置時,一般都要去積極主動地進行腦裂檢測和避免腦裂問題的產生。通常用檢測腦裂問題的辦法進行仲裁,通過多個節點進行仲裁選舉出問題節點,踢出叢集,我們在做腦裂仲裁時除了其它節點選舉之外,還新增本節點的自動檢測,避免本節點故障假死的情況下,選舉不準確。關於腦裂仲裁演算法網上都有實現方法,大夥可以參照,結合實際情況進行改良。

(2)使用負載均衡和反向代理有一個比較重要的問題就是負載策略的選擇。以Nginx為例,常用的有Round-robin(輪循)、Weight-round-robin(帶權輪循)、Ip-hash(Ip雜湊),其中HAproxy還支援動態加權輪循(Dynamic Round Robin),加權源地址雜湊(Weighted Source Hash),加權URL雜湊和加權引數雜湊(Weighted Parameter Hash)等。但是我們生產環境中用的最多的還是輪詢和iphash這兩種方式。如果後端應用是有狀態的,且未實現session共享,一般使用ip-hash的方式。
(3)對於有狀態的後端應用,如果採用輪詢的策略會有問題。但是採用ip-hash的方式也會有一定的問題,首先是後端伺服器的訪問負載不均衡,會有較大的偏差,其次是未實現真正的應用高可用,當連線到的後端伺服器當機,session丟失,需要重新進行業務登入或操作等。解決這一問題一般常用的方法有三種:
應用伺服器共享session
cookie存session
session伺服器存session
應用伺服器共享session,這個Tomcat是支援的,只需要配置即可,但對應用的效能有比較大的影響,尤其是應用節點比較多的情況;cookie存session是一個方法,但cookie的大小有限,不適合存較多的session;session伺服器存session應該算是最佳的辦法,例如使用Redis存共享session,很多公司在用,但也有一個缺點就是增加維護成本和運維複雜度,雖然這項技術實施起來會比較簡單。
3、業務應用層
業務應用層比較大的一塊是做服務化,這會在下面的分割架構進行詳細說明。這裡主要說明簡單的業務拆分和應用叢集的部署方式。
高內聚、低耦合一直是軟體開發和系統運維所積極追求的。通過實現業務系統的高內聚、低耦合,降低系統依賴,提高系統的可用性,降低故障率,業務拆分是解耦的重要利器之一。一般根據公司業務系統的特點和關聯進行拆分,對公共業務系統進行抽取形成公共業務應用,對所有業務系統進行介面化服務。各個業務系統之間獨立部署,降低耦合度,減少了業務系統之間的依賴和影響,提高整個系統的利用率。
因為有前面的負載均衡和反向代理層,所有後端的應用伺服器可以橫向部署多臺,實現高可用也起到使用者訪問分流,增加吞吐、提高併發量。實際應用部署中主要以Java應用居多,且多部署在Tomcat中,以此為例,在應用伺服器部署時,主要考慮以下幾個問題或是建議:
統一JDK和Tomcat版本。這很重要,主要是為了方便管理,另外也方便做自動化運維部署。其中統一部署中的作業系統優化、安全加固,Tomcat優化、安全加固等都要做好,我們在做Tomcat自動部署的時候,採用的是根據系統配置自動優化的方式和安全加固策略進行。另外就是自動備份和日誌的自動切割,都在統一部署指令碼中體現。這樣所有部署下來,安裝位置、部署方式等都是一致的,方便統一管理,統一備份和升級。
動態頁面靜態化。這個根據訪問量選擇系統進行,例如公司的B2C官網等可以採用靜態化的技術,提高頁面的訪問速度。
4、公共服務層
公共服務層將上層業務層公共用到的一些快取、訊息佇列、session、檔案圖片、統一排程、定時任務等抽取出來,作為單獨的服務進行部署,為業務層提供快取、訊息佇列以及圖片等服務。

快取主要是指的快取資料。應用伺服器通過快取伺服器查詢常用資料,提高系統的查詢速度,對於高併發的寫,通過非同步呼叫訊息佇列,進行資料的臨時儲存,提高系統的併發量和系統效率。Session叢集以及檔案圖片伺服器叢集主要是為上層業務應用提供統一的session儲存和圖片檔案儲存的,避免系統的session失效和單點故障。
常用的資料快取以及session儲存主要是Redis。Redis的叢集部署方式在資料儲存層會詳細說明。
訊息佇列的主要中介軟體有ActiveMQ和RabbitMQ等,二者都提供master-slave或是叢集的部署方式。我所經歷的公司中二者都有生產上的應用。常用的還有ZeroMQ、Kafka,但ZeroMQ不能持久化儲存,因為並未在生產使用,所以不好多說。Kafka主要在搭建日誌分析平臺時用到過。對於ActiveMQ和RabbitMQ,二者並沒有太大的區別,都在生產用過,也沒遇到太大問題。在技術選擇中,還是選擇開發和運維最熟悉的為好,再具體點,建議以開發最熟悉的為標準。
檔案圖片伺服器,如果公司的資料比較敏感且有較高的保密性,加上核心生產系統只能內部使用的話,建議搭建內部分散式檔案伺服器、圖片伺服器,我所經歷的公司有使用FastDFS進行構建分散式叢集檔案伺服器的,目前比較火的分散式儲存主要是Ceph吧。如果對外提供服務,建議採用購買雲服務,如阿里雲的OSS等,方便運維管理,而且雲服務自身的特性,也比較容易增加檔案或圖片的載入速度。
統一排程、統一任務平臺,我們使用淘寶的TBSchedule,也有一部分使用Spring自帶的定時任務,目前正在做整合。就現在來看,可以滿足我們的定時任務和統一排程的需求。
公共服務層的架構和部署一般來說都提供了主從和叢集兩種高可用方式,並且都實現分散式部署。由於公共服務的重要性,所有業務都在呼叫,所以在實際生產部署的時候,一定要採用高可用的方式進行部署,並且要有可伸縮性和可擴充套件性。結合我們公司實際情況,在進行公共服務部署時,除了採用主從或是Cluster的方式進行部署,還增加了一鍵擴充套件的指令碼,實現對叢集中伺服器的快速擴充套件。分散式擴充套件方式中的常用演算法主要是一致性hash的方式,網上資料很多,這裡不在一一贅述。
5、資料儲存層
資料儲存層主要分為關係型資料庫和NoSQL資料庫。主要從高可用叢集包括負載均衡、讀寫分離、分庫分表等幾個方面,結合自身實際應用經驗進行分析。
1關係型資料庫
目前用得比較多的資料庫主要Oracle和MySQL兩種,我之前所經歷的生產系統,做如下架構,請參考:

(1)Oracle
首先是Oracle資料庫,為了避免單點故障,一般資料庫都進行叢集部署,一方面實現高可用,另一方面實現負載均衡提高業務資料處理能力等。
Oracle常用的比較經典的高可用方案主要是RAC+DataGuard,其中RAC負責負載均衡,對應用的資料庫請求分佈在不同的節點進行。DataGuard作為RAC的Standby,平常以readonly模式開啟,為應用提供讀的服務,實現讀寫分離的功能。
Oracle整體的叢集架構成本較高,除了專用的license,還需共享儲存等,且搭建比較複雜,運維成本較高。
很多人感覺RAC並不是Oracle高可用架構的原因可能有以下場景:當節點負載很高,壓力很大的時候,如果一個節點突然宕掉,相應該節點的請求會飄到另一個節點上,另一個節點也很快會因為負載過高而當機,進而整個叢集不可用。
關於Oracle分庫分表。平常用得比較多的是Oracle的分表,將一些大表通過hash或日期等方式拆分成多個表,實現大表資料分散化,提高大表的效能。但對於Oracle的分庫,本人並沒有找到好的方式或是中介軟體,用的比較多的主要是DBLINK+Synonym的方式,相比效能有不小的下降。不知大家是否有關於Oracle分佈更好的方案或是中介軟體,可留言一起探討。
(2)MySQL
MySQL的高可用架構相對會更靈活一些,成本會較低。目前生產MySQL高可用架構主要以主從同步、主主同步+Keepalived、MHA等為主。關於MHA,不管是楊建榮老師還是賀春暘老師都做過深入的解析和結合自編指令碼做了一些改進,生產系統使用MHA,除了瞭解MHA的原理以及管理指令碼,二位老師的解析和自編指令碼,推薦大家做深入研究。
除了基於主從複製的高可用方案,不同的MySQL分支也提供了相應的Cluster的服務,我們生產中並未使用MySQL的Cluster,所以不做過多介紹。
對於MySQL的分庫分表、讀寫分離等功能的實現,我們更多的是依賴於MySQL中介軟體。常用的MySQL中介軟體也非常多。

上圖摘自14年8月份在做分庫分表技術調研時在網上找的一個圖。截止到目前,我經歷過生產使用較多的分庫分表和讀寫分離中介軟體的主要有Maxscale(實現讀寫分離),Spider(分庫分表),OneProxy以及MyCat。下面是之前我們電商平臺使用MyCat實現讀寫分離和分庫分表的架構,希望能夠給各位帶來一些收穫:

該架構分為四個大的資料庫叢集:交易平臺、會員中心、金融平臺、物流平臺,每個叢集內部讀寫分離。四個叢集之上採用OneProxy做資料庫路由,實現對開發來說後臺只是一個資料庫。
採用資料庫中介軟體,或多或少的都有一些限制,例如跨庫查詢、跨庫事務等,各位在進行改造的時候,一定要結合開發、測試,共同進行分庫分表後的測試,確保無誤。關於讀寫分離和分庫分表,這裡將個人的感悟分享一下:
關於MySQL讀寫分離
讀寫分離通過分解資料庫讀寫操作,減緩寫的壓力。尤其是在未實現分庫的情況下,採用maste-slave模式的master節點面臨著巨大的讀寫壓力。採用讀寫分離的好處不言而喻,但也有苦惱。假如讀寫落在的庫上資料有延遲導致不一致,也是個很痛苦的事情。
提供讀寫分離的中介軟體也很多,Maxscale首薦,Amoeba比較經典,歲數也比較大,另外下面的MySQL分庫分表的中介軟體也大多支援讀寫分離。對於讀寫分離的訴求一般都是寫庫壓力大。對於這種情況,3種建議方式:
資料庫之上新增訊息佇列,減輕直接寫資料庫的壓力;
使用快取伺服器例如Redis,將常用資料快取在快取伺服器中;
讀寫分離,同時加強主從同步速度,儘量避免屬於延遲的情況。
1~2步需要開發的同學參與進來由架構師主導完成,進行這3步的同時還要不斷優化慢查詢。
關於MySQL分庫分表
首先強烈建議業務層面拆分,微服務的同時資料庫也完成拆分,通過開發手段避免跨庫查詢和跨庫事務。減少使用資料庫中介軟體實現MySQL的分庫操作,當然單表過大是需要DBA介入進行分表優化的。
分庫分表常用的中介軟體也較多:MariaDB的Spider、OneProxy、360的Atlas、MyCat、Cobar等。
Spider
https://mariadb.com/kb/en/library/spider-storage-engine-overview/
OneProxy
http://www.onexsoft.com/proxy.html
Atlas:目前應該已經停更了。
https://github.com/Qihoo360/Atlas/blob/master/README_ZH.md
MyCat:功能比較全,而且比較火。
http://www.mycat.io/ mycat
Cobar:目前也已經停更,記得MyCat早期就是繼續Cobar而逐漸演化的
https://github.com/alibaba/cobar?spm=0.0.0.0.arolKs
PS:阿里關於資料庫開源了很多不錯的產品
https://yq.aliyun.com/opensource
大家可以看出,對於讀寫分離和分庫分表我都是優先推薦的MariaDB系的產品。因為公司和個人原因吧,我只有在之前的公司研究過一段時間MySQL的讀寫分離和分庫分表,在測試環境做了大量的測試,但最終沒上到生產中,反而是隨著公司的業務重組,IT順勢做了服務化,將原來的一套B2B平臺拆分成多個模組,實現瞭解耦,資料庫也順勢拆分了出來,所以就單個模組,讀寫壓力少了很多。算是業務重組和系統重構讓我們暫時沒用中介軟體來實現讀寫分離和分庫分表。但報表型別的查詢我們還是讓開發直接查詢的slave端的。
之所以推薦MariaDB系,是因為之前和賀春暘老師(http://blog.51cto.com/hcymysql)聊天的時候,得知他們有一些採用的Maxscale和Spider,他本身也做了大量的測試,也有生產經驗,所以在這裡給大家做推薦。當時我們公司測試的主要以OneProxy為主,但其是收費產品。
看似讀寫分離和分庫分表有點打太極,都先把事情推給開發同學。實際上從架構的角度來看,資料庫承擔的計算越少越好,資料庫越輕越靈活。一般來講,需要DBA來採用中介軟體的方式實現讀寫分離和分庫分表時,某種程度上都會降低效能,畢竟加了中介軟體一層;另外也增加DBA的運維負擔,同時中介軟體支援的分庫分表對於跨庫查詢和跨庫事務都有一定的限制,需要開發的同學做一些程式碼上的轉變。
(3)DMP資料平臺
DMP統一資料管理平臺主要用於資料分析和報表展示等功能。通過搭建統一資料管理平臺,減少直接生產庫查詢資料的壓力,減少生產壓力。對於中小企業的資料平臺,我之前寫過一篇介紹,可以參考:《資料即金錢,中小企業如何搭建資料平臺分得一杯羹?》,比較適合中小企業使用,可以在這個架構基礎上新增Hadoop叢集等來處理大資料相關的分析,很容易進行擴充套件。
2非關係資料
非關係型資料庫主要以Redis為主。Redis常用的高可用方案有哨兵模式和Cluster。使用Redis除了上面講的做共享session儲存之外,最大的應用就是快取常用資料。這兩大應用建議生產環境中分叢集部署。我們當前或是未來的一個實際情況:由於目前正在做服務拆分,更多的服務和應用實現了實現服務無狀態,所以存共享session的需求會越來越少。
關於非關係型資料庫,除了高可用、監控之外平常工作中還面臨很大的一個工作就是分庫和分片,如何方便快速擴充套件,這很有用。對於Redis的使用,個人建議在一開始規劃時就考慮好擴充套件問題避免以後的遷移或是線上擴充套件等。這跟關係型資料庫的分庫分表有異曲同工之妙。Redis的分庫分片和擴充套件對系統架構來說很重要,尤其業務的高速發展期,越來越多的資料快取在Redis中,如果沒有做好規劃,將會很被動。具體Redis架構,結合我們實際生產環境,在以後的文章中在跟大家詳細描述和分享。
除Redis之外,很多生產環境也會有MongoDB、HBASE等常見的NoSQL資料庫,不同的資料庫有不同的應用場景,大家在做系統架構時,根據實際情況進行稽核。
四、分割架構
分割架構主要是指業務拆分。根據具體的業務內容和高內聚、低耦合的原則,將複雜的業務進行模組化的劃分,單獨部署,介面化運算元據,實現業務的橫向分割。細粒度分割複雜的業務系統,可以降低業務系統的複雜度,按照模組進行開發和維護,降低整體系統的當機時間。
一般來說,分割架構需要開發、業務為主,運維、測試為輔,架構師統一主導進行,共同進行系統劃分工作。
業務劃分因公司的業務不同而異,支援服務化的開源技術框架也很多,常見的有Dubbo、Dubbox以及比較新的Spring Boot、Spring Cloud等。本人有幸在一家公司以DBA的身份參與到公司的系統重構中去,雖然對服務化的技術框架不是很熟悉,但這個系統劃分及服務化過程,可以結合之前的經驗給大家做一個簡單的分享,希望讀者能夠有所收穫。
首先是不可避免。一般系統初期,公司為了業務儘快上線,大多將業務功能堆加在一起。隨著公司業務發展,系統拆分、系統重構不可避免。
成本頗高。系統拆分,系統重構一般帶來的IT高成本,風險相對也較高。該工作一般適合於系統平穩發展時進行,或是單獨的團隊進行並行進行。
做好計劃,持久作戰。系統拆分、系統重構時間相對較長,一定要提前做好計劃,避免出現專案持續時間久,專案疲憊的情況。
業務拆分要科學。業務的拆分一定要經過架構、開發、業務、DBA等部門共同討論,共同制定出既適合當下,又能夠適合未來一段時間內(2~3年)的業務發展。
業務拆分要徹底。業務拆分不應該只是系統或是程式工程的拆分,還應該包括資料庫的拆分。我們之前就是拆分了程式,未徹底拆分資料庫,導致程式實現服務化後,後端資料庫的壓力不斷增大。採用資料庫中介軟體實現後端資料庫的分庫,但因為中介軟體的一些限制,開發又不得不修改一些跨庫查詢和跨庫事務的情況。所以業務拆分一定要徹底,不管是專案工程,還是資料庫。
拆分取捨有道。拆分取捨有道,既不能將系統拆分得過細,這樣會有很多跨系統的事務或查詢的情況;但也不能拆分得太粗,隨著時間增長,有面臨著被拆的問題。所以系統的拆分要結合實際情況進行,既要避免技術潔癖,也要避免粒度太粗。
以上幾條,是我們之前在做系統業務拆分和系統重構時候的一些經驗,至於重構的服務化架構,因為本人之前沒有參與太深,一知半解,這裡不便多言。不過目前我們也在以架構的身份進行系統拆分和服務化的探索,待逐漸完成後,整體的架構會拿出來跟大家分享,目前我們採用的技術框架主要以Spring Cloud為主。
五、系統保障
系統保障主要圍繞基礎運維資料(CMDB),以監控、災備、安全三大體系保駕護航,運維自動化作為馬達,保障系統和服務的安全、穩定、高效的執行。關於運維管理體系,運維基礎資料,災備和安全的介紹,我在之前的文章都有介紹,歡迎指正。
監控這塊一直沒有下定決心來寫,因為目前我們監控面臨著監控閥值設定不夠精準導致誤報過多引發告警疲勞,監控因素關聯關係未完全梳理清楚導致一個問題引發告警風暴的問題。告警疲勞和告警風暴是我們目前監控面臨的兩大難題。待解決完成後,會進行監控體系的分享。
關於告警風暴目前我們得到一定程度的環境,主要依賴告警分級和CMDB中的依賴關係來做的,自動判斷故障根源進行告警,多個告警引發候,有限告出根本故障點。目前有一定成效,但還需進一步改進。網上也有一下使用機器學習的方式來準確設定或是動態設定告警閥值的情況,也值得我們進一步學習。
關於系統保障我已完成的文章和推薦給大家關於監控動態設定閥值的連線,整理如下,請參閱指正:
《一個可供借鑑的中小企業運維管理平臺架構樣本》
《乾貨!談自動化運維平臺的地基如何打牢》
《從安全、監控與災備說開去,談運維管理防線建設》
《做好災備平臺,打造自動化運維管理的最後堡壘》
《解放運維的雙手,談自動化運維管理平臺設計》
阿里的Goldeneye
http://www.infoq.com/cn/articles/alibaba-goldeneye-four-links
智慧運維裡的時間序列:預測、異常檢測和根源分析
http://www.infoq.com/cn/presentations/time-series-in-intelligent-operation-and-maintenanc
六、總結暨技術平臺和技術生態圈
寫到這裡,關於系統架構這一塊基本結束。關於系統架構個人建議主要分兩大塊,一個是系統架構,一個是系統運維。首先通過系統架構設計出穩定、高可用、高效能且易擴充套件的系統來,然後通過系統運維來保障。個人感覺這應該是做系統架構應該著重考慮的地方。(這考慮可能跟我目前的工作職責有關係)
關於技術平臺和技術生態圈,這是一個很大的話題,跟個人的職業規劃也有一定的關係,我這裡直說一點,就是對於自己所在的公司所用到的技術棧,每一種技術適用的場景以及優缺點要了然於胸,尤其是對於架構師。對於系統架構的技術生態圈,這裡以StuQ中各種技能圖譜來表述技術生態圈。常見的IT技能圖譜可以參考:https://github.com/TeamStuQ/skill-map 每一種腦圖代表了這一IT領域可能用到的技術知識,各位可以在此基礎上,結合自身情況,建立起自己的技術體系,並且在日常工作和學習中不斷得完善。
最後,圍繞系統架構,再重複一句經久不變的哲理:系統架構不是一開始就架構出來的,是通過不斷的演變而來的。做系統架構一定要符合公司的實際情況,採用最熟悉的技術進行架構,同時要做好技術儲備,以便應對瞬息萬變的技術革新。
Q&A
Q:問CMDB有什麼開源產品推薦的?謝謝!
A:關於CMDB開源的產品還是蠻多的,懂Python的話,推薦這幾個開源開源資產管理系統:
https://github.com/hequan2017/autoops
https://github.com/pengzihe/cmdb
https://github.com/welliamcao/OpsManage
https://github.com/hgz6536/opman-django
https://github.com/voilet/cmdb
https://github.com/roncoo/roncoo-cmdb
如果直接可用的話,ITOP還不錯。不過適合自己的CMDB才是最好的,一般都需要二次開發。
直播連結
https://m.qlchat.com/topic/details?topicId=2000000501733146&ch=live_tpl_inform
↓↓↓點這裡下載資料中心標準及相關規範文件
https://pan.baidu.com/s/1eR7RyPO
相關文章
- Android系統架構-----Android的系統體系架構Android架構
- 軟體系統架構有感架構
- 解密微信域名防封、防紅系統的具體方案解密
- MySQL體系架構MySql架構
- SQLite體系架構SQLite架構
- Oracle體系架構Oracle架構
- 軟體體系架構的認識架構
- 分散式系統的那些事兒 - SOA架構體系分散式架構
- 論軟體系統架構風格架構
- 《計算機系統:系統架構與作業系統的高度整合》——第2章處理器體系結構計算機架構作業系統
- GPU體系架構(二):GPU儲存體系GPU架構
- 程式設計體系結構(09):分散式系統架構程式設計分散式架構
- Tomcat 體系架構Tomcat架構
- JavaEE體系架構概述Java架構
- Solr體系架構圖Solr架構
- RAC體系架構理解架構
- Shuttle Bus體系架構的特徵架構特徵
- 企業資訊體系與系統體系
- 採用開源軟體搭建WebGIS系統(1)系統架構Web架構
- 教育系統開發的具體流程
- 構築Unix系統內防火牆體系的多種方案(轉)防火牆
- JavaEE體系架構概述(續)Java架構
- zt_oracle體系架構Oracle架構
- 架構設計:資料服務系統0到1落地實現方案架構
- 『網際網路架構』軟體架構-mybatis體系結構(14)架構MyBatis
- 具體資訊系統防護罩
- [Virtualization]ESXi體系結構與記憶體管理(一)體系結構記憶體
- java 考試系統 模組架構方案Java架構
- 智慧家居系統的匯流排系統和無線系統的具體介紹
- 老闆:把系統從單體架構升級到叢集架構!架構
- Oracle Data block 的物理結構-體系架構OracleBloC架構
- 作業系統體系結構作業系統
- 架構知識體系總結架構
- Kafka體系架構、命令、Go案例Kafka架構Go
- 2_指令集、體系架構、微架構架構
- 招聘—軟體系統架構師,座標北京知春路架構
- SimpleRpc-系統邊界以及整體架構RPC架構
- 基於golang分散式爬蟲系統的架構體系v1.0Golang分散式爬蟲架構