DevOps落地三部曲:如何歸責?用啥工具?往哪裡去?

(獲取任發科演講完整PPT,請看完本文章底部資訊)
講師介紹
任發科,網名常新居士,曾任職唯品會、會唐網、亞馬遜、ThoughtWorks,有十餘年軟體開發、架構和管理經驗。曾參與多個電商相關係統的研發工作,近年主要關注DevOps工具鏈的設計與實現,以及高效研發團隊的組建與管理。
今天我主要是從兩個方面去探討DevOps,由於大部分的同學可能更多的是看到了運維這個層面,所以我更多側重的是Dev這個層面,也就是從Dev到運維,因為正好是整個全流程走到這裡,我們看到了一些實踐,也看到了將來的一些機會和趨勢,所以今天會談一談我們公司近兩年做的過程,也就是我們怎麼做DevOps。
今天我主要是從兩個方面去探討DevOps,由於大部分的同學可能更多的是看到了運維這個層面,所以我更多側重的是Dev這個層面,也就是從Dev到運維,因為正好是整個全流程走到這裡,我們看到了一些實踐,也看到了將來的一些機會和趨勢,所以今天會談一談我們公司近兩年做的過程,也就是我們怎麼做DevOps。
一、從業務、系統發展看問題
從業務和系統的發展,我們來看當時面臨的問題和解決的措施,有一些總結性和思考性的東西。就像程永新老師在企業級運維三板斧所說的,未來不是DevOps,關注方向的可能是AIOps這個層面,也就是說DevOps更要關注的是ADPaas平臺,而在運維側則更多的是AIOps,就像谷歌的系統是自治的,不需要人為介入,所以運維側是要受到很大挑戰的。
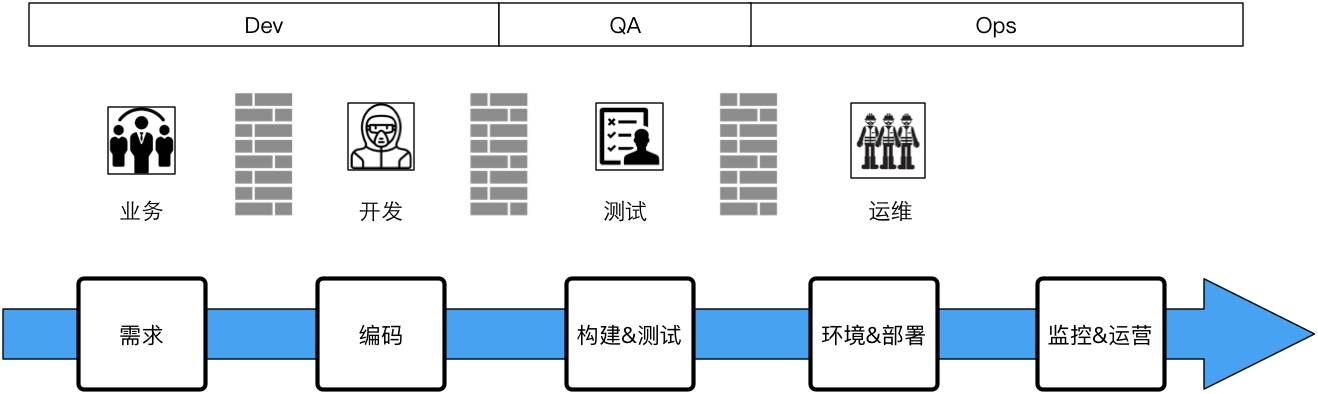
這是我當時加入公司時的一個基礎組織架構,跟所有網際網路公司,或者一些創業已經過了風險期的公司大致相似,這是標準化的建制,就是說業務和研發、測試、運維都有,是這樣的一個結構。
敏捷與持續整合
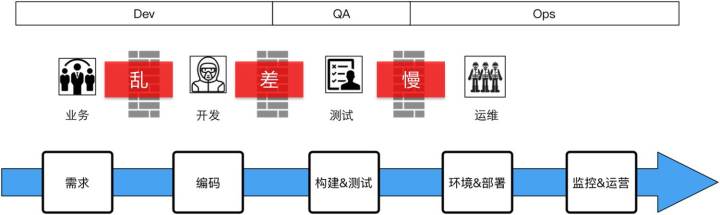
第一個過程,當我加入到這個團隊裡面時,整個研發體系加上在一起大概40人左右。剛進去時我們做敏捷和持續整合,跟所有的創業團隊一樣,內部沒有規範,做事圖快,質量較低。大家在創業公司或者是一些中型公司呆過的話就會知道,基本上沒有走到標準化流程階段,基本上都會存在相同的問題,就是業務和研發對接的管理非常混亂,沒有相對規範的流程。
開發做出來的東西提交測試時沒有太多的責任心(在心理定位上將測試人員當作編碼質量的防護網),裡面Bug非常多。然後上線測試,我們當時讓測試做構建,把這個包構建出來,最後交給運維,由運維負責上線。整個過程很亂,比如拷到某一個發版機器上,拷上去以後用資料夾打個標籤交給運維,運維再往線上扔,扔到線上以後就要人肉一段時間,看一看沒什麼問題才回家睡覺。
存在問題:你可以看到基本上的問題就是,需求側這面專案管理非常亂,研發的交付質量很低,會有很多返工的事。專案上線的週期長,問題非常多。
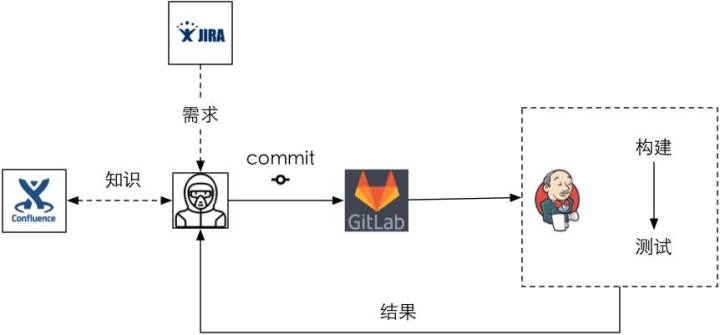
我們首先做的是基於持續整合的改善。從過程管理這個層面,我們把Scrum引入進來,對Scrum做了一定的調整。實際上最近在敏捷圈子裡吵得非常厲害,各種方法論大家都不服,都認為自己代表了“天意”。但從企業的角度,尤其是我們解決問題的角度,用哪個都無所謂,能解決問題才是根本。所以我們根據企業當前人員情況對Scrum進行了裁剪,不是什麼都要,明確哪些問題需要用Scrum去做。把Scrum流程引入之後,再用JIRA做需求管理、排期這些事情,然後內部用GitLab去做整個程式碼的管理,搭一個伺服器,把UT做起來,很快能夠得到好的反饋。這個是非常成熟的套路,如果用強制的方法做的話見效很快,基本上1-2個月就能梳理出來。
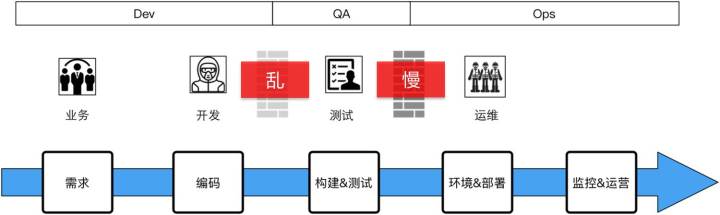
在我們做完了後會發現,這個過程不是那麼順,不是上來以後奇蹟一般的就做好了,中間肯定有很多很多需要去溝通、協調的一些過程。你可以看到業務跟研發的對接相對來說變得好了,不一定非常流暢,但可控了。但研發到測試這邊,你會發現它的牆變灰了,不是那麼實了,因為當你有UT搭建起來後,其實提交的質量、責任已經放在研發這一側了,這時候測試拿到的東西相對就好很多,它就不會來來回回地在底層的一些簡單問題上掰扯。但這時運維這一側還沒有受到太大的影響。
存在問題:這時我們發現還是有一些問題,就是研發到測試的交付物不同源,一致性存在問題(我們後面會講一致性的問題);測試手工驗證週期還很長,因為它沒有做測試的自動化,即功能測試和效能測試都沒有做自動化;專案上線時間長,因為沒有觸動到運維側。所以這時候我們要做的就是持續交付的第一個版本,我們把它叫做持續交付的1.0。
持續交付1.0
持續交付的1.0做了什麼事?就是我們現在大部分在40人以下的小團隊要做的——一個交付流水線,其實多數團隊都是這樣做,就是加一個pipeline的外掛,部署的指令碼寫在Jenkins裡頭,然後把它跟原始碼放在一起,這就是我們現大部分持續交付的事情——加一個pipeline外掛。我沒有截那個圖,這裡畫了一個大概的形式。
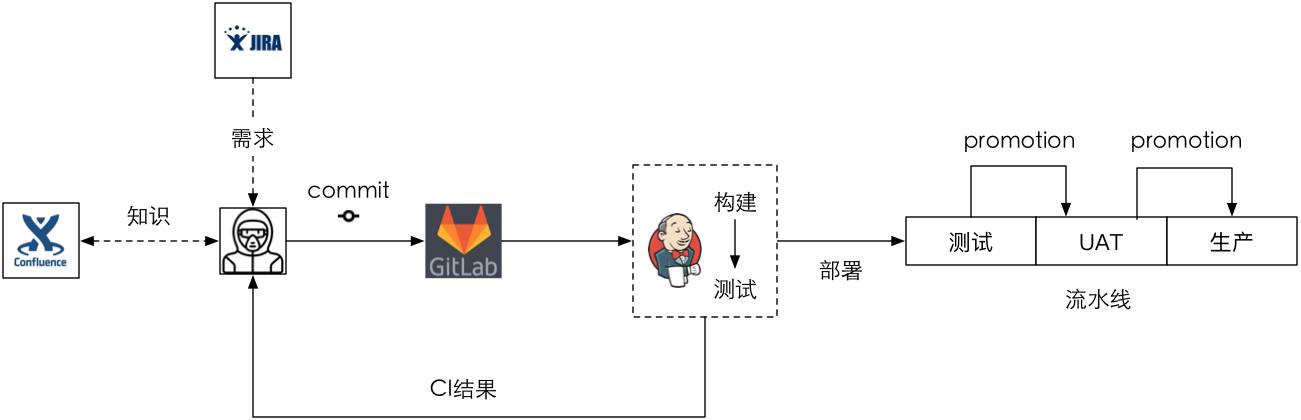
你可以看到之前的CI我們還需要做,但Jenkins有了一定的構建能力,並且通過pipeline外掛我們可以做多環境的部署,只要構建出來以後一步一步往上推(Promotion),但在UAT到生產這一步需要人工做最後的審批,並不全自動化。
這裡涉及到兩個概念的差別呢?就是什麼是持續交付,什麼是持續部署,現在行業裡頭談持續交付多一些,談持續部署少一些。持續整合是關注在研發側,不涉及到後面的自動化驗證和部署的過程,但持續交付關注到了構建後的部署和驗證,但它有一部分的手工驗證過程,它可能在全線是貫通的,但最後的一步和中間驗證都是手工的。而持續部署強調的是全自動,中間沒有任何人為的干預,只要你一提交程式碼馬上就開始通過部署流水線向生產流動。我們現在說的是持續交付,所以這在生產過程實際上還需要手工去稽核的。但這個過程實際是有問題的,在系統很小的時候可以這麼做,但團隊變大的時候就有問題。
存在問題:什麼問題?持續交付說只構建一次,然後在這個構建的產物上進行驗證和部署,這就需要引入製品庫。但是我們遇到了一些團隊,你會發現實際上在程式碼的生成和驗證的過程中,它都是從版本庫裡頭直接拉程式碼回來,不斷地拉程式碼,拉了以後再動態地打包,這樣的話會有一些問題。
所以我們希望把製品庫引進來,就是拿的東西是第一次就構建成功的東西,然後在這個上面不斷地附加原資料。什麼是原資料?就是經過或沒經過單測,單測的百分比是多少,然後誰去驗證它,這都是跟這個製品有關的一些行為和流程資料,它必須要記錄下來,因為後期的活動可以基於這些資料去做選擇。
-
製品庫:Nexus->Artifactor->自研
我們整個製品庫過程選擇經過了3個階段,最早的整個專案是用Java來做的,很自然的,我們就用Nexus做私庫,去做製品的構建產物管理。因為它很容易解決依賴的問題,而依賴是很麻煩的事情。因為Nexus支援產品版本,不支援構建版本的追蹤,同時它沒有原資料管理的能力。
所以第二步我們跟JFrog對接,希望用它的Artifactory,這是用得比較成熟且用得比較多的,目前谷歌、騰訊、阿里也在用。但問題是公司體量不大,而專業版的Artifactory比較貴,我們負擔這樣的花費有點不划算,跟大家一樣我們想用開源版本的,但社群版的Artifactory不支援多語言,而且它構建版本的支援要專業版,所以沒辦法,我們調研以後自己做,拿什麼做?
很簡單,你可以搭一個類似S3的檔案服務,把它放在檔案服務上去。第二種方式我們用資料庫去做,有些資料庫實際上是可以去存二進位制的大檔案的,而且它可以很方便地做Key-Value的後設資料管理,但自己研發製品庫的問題在於併發、高可用和快速下發。在規模較小時,這些還不是問題。

它的好處是什麼?加了製品庫以後,我們能保證把構建版本和後設資料打上去,在這樣的話我們保證部署的都是同源的,而且一步一步可以在它的部署邏輯裡頭根據後設資料經過選擇,就是它沒有經過前面的階段或者到達一定的百分比我是不允許後面的階段看到這個構建產物。
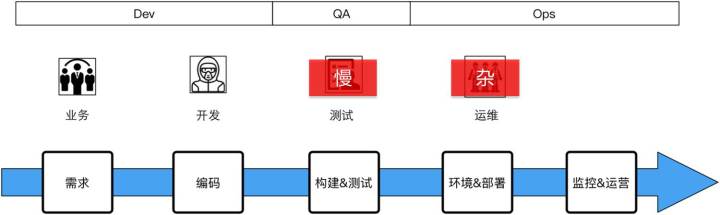
現在你可以看到我們的整個結構,就是說開發到測試的階段實際上這個牆就沒有了。這裡說一下我們自己的業務,我們的業務基本上是支援公司內部的電商和公司內部的其它網際網路產品。這時你可以看到測試到運維這邊的牆實際上可以把它拿走,但運維這時還有一些問題就是他的事比較雜,為什麼雜?因為應用的運維。我們可以把運維看成兩部分,一部分是傳統的運維或者說是基礎設施和工具化的運維,另一方面是跟應用相關的運維,應用的運維我們也是放在運維團隊的,這個安排實際上是不合適的。所以說運維的事就比較雜,不能專心地幹自己特別擅長的事。
存在問題:這時我們發現運維人員需要維護大量的環境,包括應用的部署;第二,構建環境與生產環境的一致性是有問題的。為什麼?比如說構建環境放在Jenkins裡,如果去用它做構建的話,它的環境是定好的,例如JDK1.8,那我所有的東西只能在JDK1.8上去構建,但如果我要裝JDK1.7呢?那就另搭一套環境去做它,比較麻煩。部署邏輯和Jenkins是緊耦合的,因為這些東西我們是在Jenkins裡用指令碼程式設計,而且它沒有快速回滾機制。有些時候實際上是要快速回滾的,不能重新拉程式碼版本再部署一次。最後,依然需要大量的人員去做半自動化的測試。
持續交付2.0
-
用配置管理工具(Ansible)管理環境
這時我們就想做2.0的持續交付,最早我們是用Ansible做環境的管理,在持續交付2.0之前和持續交付1.0之間發生了一件事情:我們把大量的機器從阿里雲上搬到自己的私有云上,在一年不到的時間我們搭建了OpenStack的私有云,一年裡給公司節省的成本大概是在幾百萬左右,除了少量對外的一些服務必須要放在阿里雲上,我們大部分核心計算都是放在內部的私有云上,這是我們運維團隊做的非常大的貢獻。我們到了2.0的階段,實際上大部分的機器都是虛機。這時候加上Ansible以後,可以拿Jenkins去管這些叢集的環境,這樣的大家相對都用得比較多,就不過多解釋。
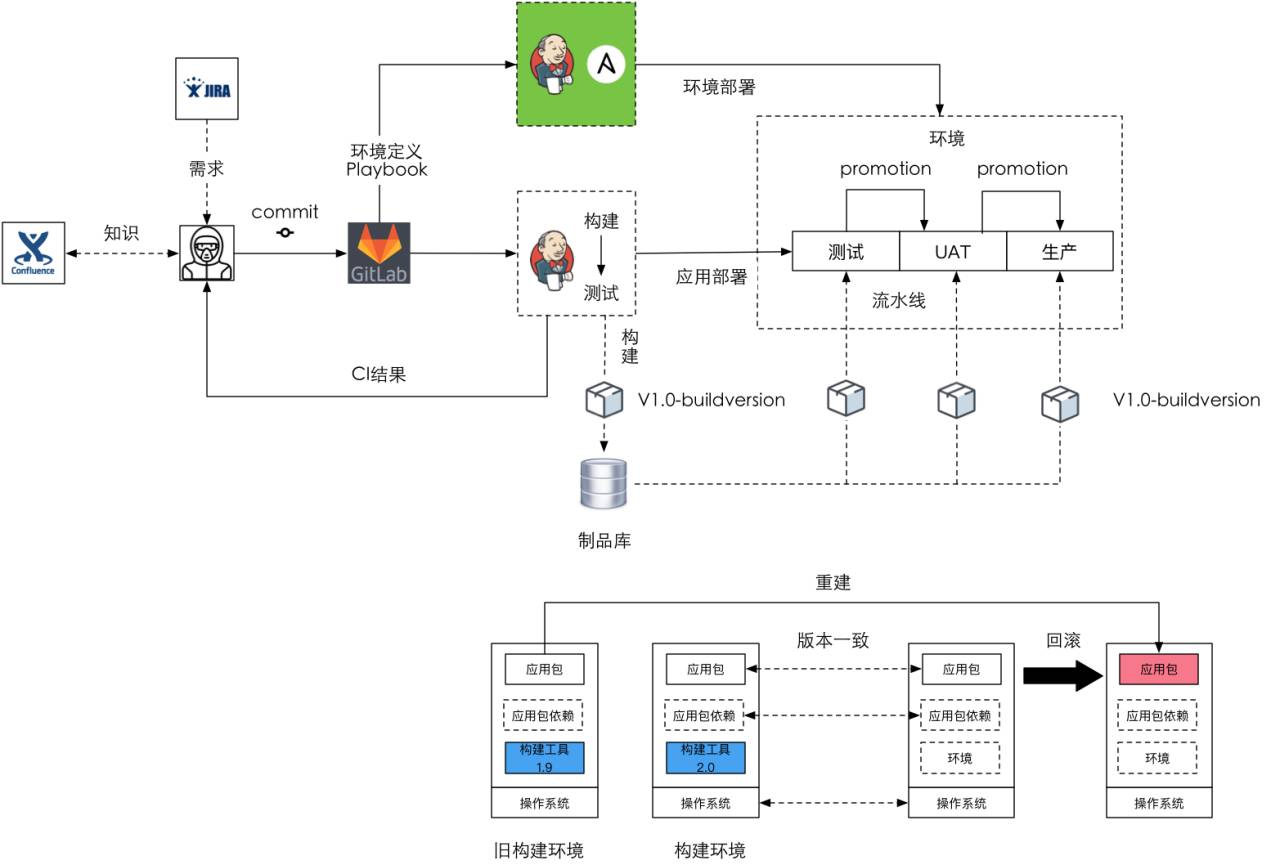
存在問題:這時整個場景裡可以看到,有一部分是應用的業務部署,有一部分是環境的部署、管理,但當真正去實踐時發現有些問題。第一個是需要構建環境和生產環境的版本是一致的,即應用包依賴的版本一致,包括作業系統也是一致的。第二個就是需要構建工具的一致性,就是說,構建時比如說是1.9構建的,回滾時也必須要回滾到1.9進行重建,必須要把這個資訊記錄下來。
如果大家讀過谷歌的文章,講他們bazel整個構建系統的話,你會發現它的一個巨大的目標就是要做到一致性,最重要的經驗就是把所有的構建的依賴和構建工具放到版本庫裡進行統一管理。現在用Ansible這個方式去管環境,用Jenkins去構建,不會有什麼問題。但當發現應用包丟了,想重新構建一次時用Jenkins進行環境構建時相對比較麻煩,很難自動化再一鍵構建出來一個。怎麼辦?接下來我們在3.0裡頭會講我們是怎麼做的。
-
測試人員和測試工作的定位
這時,我們開始做測試的自動化,就是功能測試,還包括測試平臺。這樣的話,測試人員和測試工作的定位我們需要重新反思一下。
因為我們做的工作跟傳統的業務相對還不是那麼結合緊密,基本上就做資料支援的,大資料、使用者行為分析,包括我們自己做APM和其它工具,這些工作大部分是技術性的工作,在這裡麵人肉QA的工作沒有那麼大量。所以這時我們希望把QA的工作極大地壓縮,甚至從我們的業務流程裡頭去除掉,事實上我們也整個把QA給幹掉了。
這裡面邏輯是什麼?就是留活不留人,比如說一些使用者的可用性這樣的測試我們也是需要人的,但這種工具型別的東西我們不需要人做測試,我們用機器做就可以了。所以這時你會發現整個流程就留下Dev和Ops了,把活留下了。

-
Docker與不可變部署
我們開始引入Docker,希望做基於Docker的不可變部署。Docker有個好處就是在生成一個映象時,可以通過描述來宣告其包含的內容,並將整個應用和它的環境打包成一個映象,這樣的話,測試驗證了這個映象以後,它隨後進行的所有部署都不需要變更,所需要變更的東西只是配置,你可以在啟動這個映象時給它加一些不同的配置,但它內部的實現一般是不變的,回滾和前滾都是非常容易的。
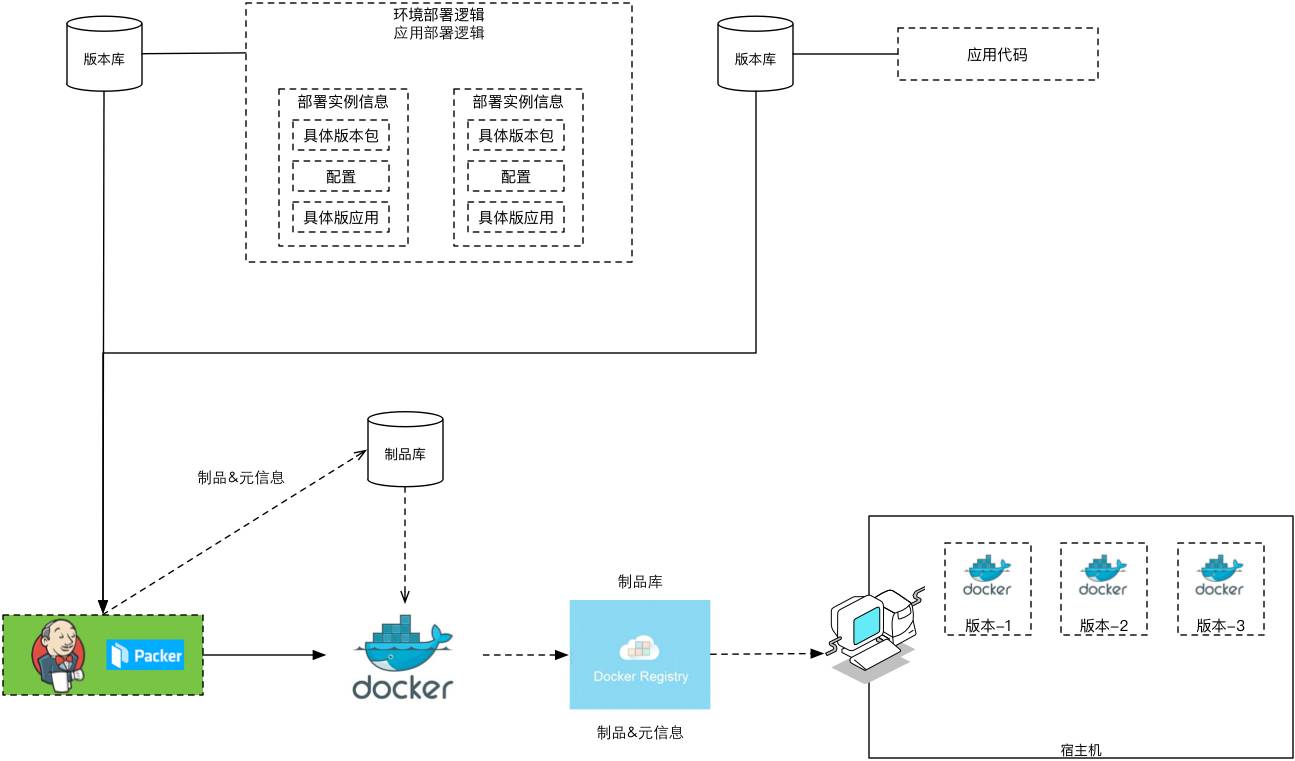
我們第一個版本的Docker部署是內部的一個工具,一個線上報障工具,整個執行在Docker上。因為大部分業務還不敢把核心業務放到Docker上去,當然我們知道一些網際網路公司在做嘗試,而且我們沒有用原生的Docker commit去打包,因為遺留系統應用的打包我們還需要用,還是有一些虛機的打包,所以我們用的是Paker。那麼整個流程實際上很簡單,還是用Jenkins去做打包,映象儲存到內部的私服上。
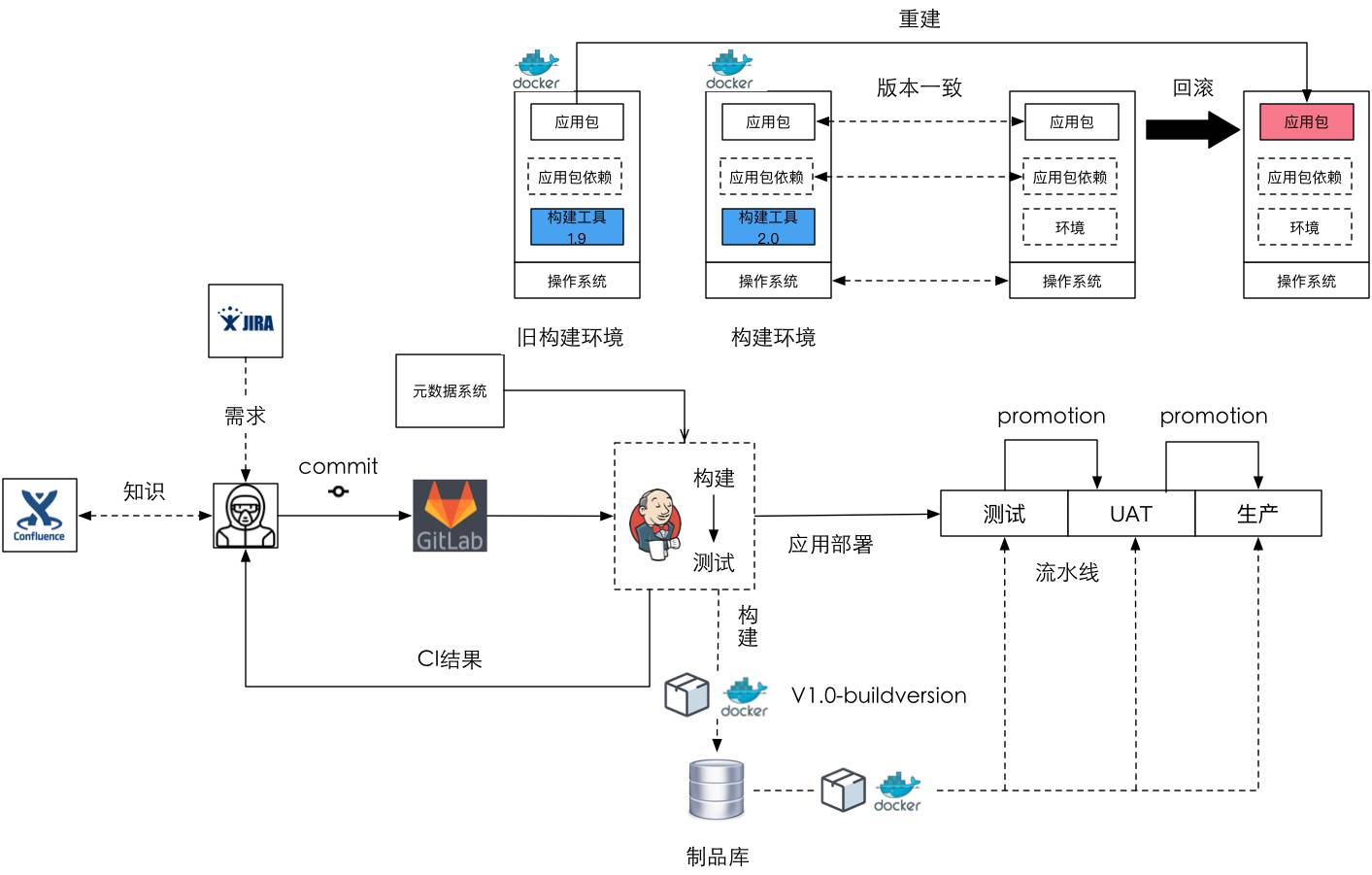
既然產品可以執行在Docker上,那麼構建環境能不能也執行在Docker上?肯定能,這時候Jenkins上拉起來去構建實際是在Docker環境裡頭構建,就是我們在生成一個專案時,我們會給這個專案新增一些後設資料:專案的名稱、負責團隊、程式碼庫,我們還會指定這個專案構建的依賴是什麼。
這時它會在內部選擇我們已經打好的基礎構建映象,比如到底是選JDK 1.7的Docker還是JDK 1.8的Docker,將來構建是在Docker上構建,就是構建時用Docker做構建環境。這樣的話就簡單了,回滾時拉一個Docker進來就可以了,比Jenkins自己構建容易管理很多,同時你會發現重建的過程也隨之簡單了。
-
運維人員和運維工作的定位
這時,我們開始對運維人員和運維的工作進行定位,因為測試人員已經被我們精簡了,從整個業務流程裡拿掉了。那運維人員是不是也要被我們拿掉?其實不是,我們所做的是把運維的工作簡化了,把不該運維負責的東西拿出來了。應用運維不需要運維團隊負責,最終,產品從需求變成程式碼,從程式碼到生產,生產上以後監控,出了問題以後修復,這些具體執行都不需要運維介入,研發來做,誰構建誰運營。那運維管什麼?管基礎設施的運維,甚至是工具的開發,我們把工具開發的團隊放在運維團隊裡頭。
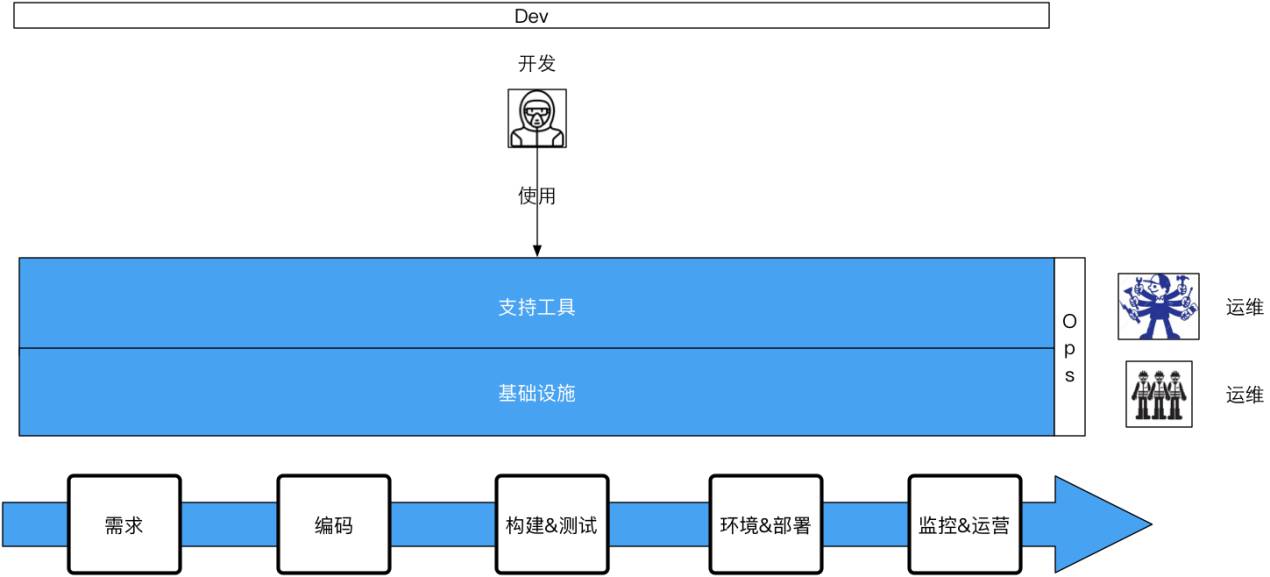
這時大家看到的就是這樣一個結構,就是研發使用運維提供的兩種工具,第一個是支援工具,可能在還沒有成為一個整合的工具前我們可能有多個工具,比如程式碼管理、專案管理、分支管理、構建系統,以及最後的部署和釋出系統。還有基礎設施的東西也是需要運維人員去做的,所以運維團隊變成了兩個部分,但在亞馬遜工具的開發是放在Dev這個部分的,這樣的話就變成開發在整個生命流程中他全管,他管的是跟業務相關的使用,而並不是要去開發監測系統,但所有的監測系統、部署系統都交由運維做。
-
Jenkins承擔了太多職責
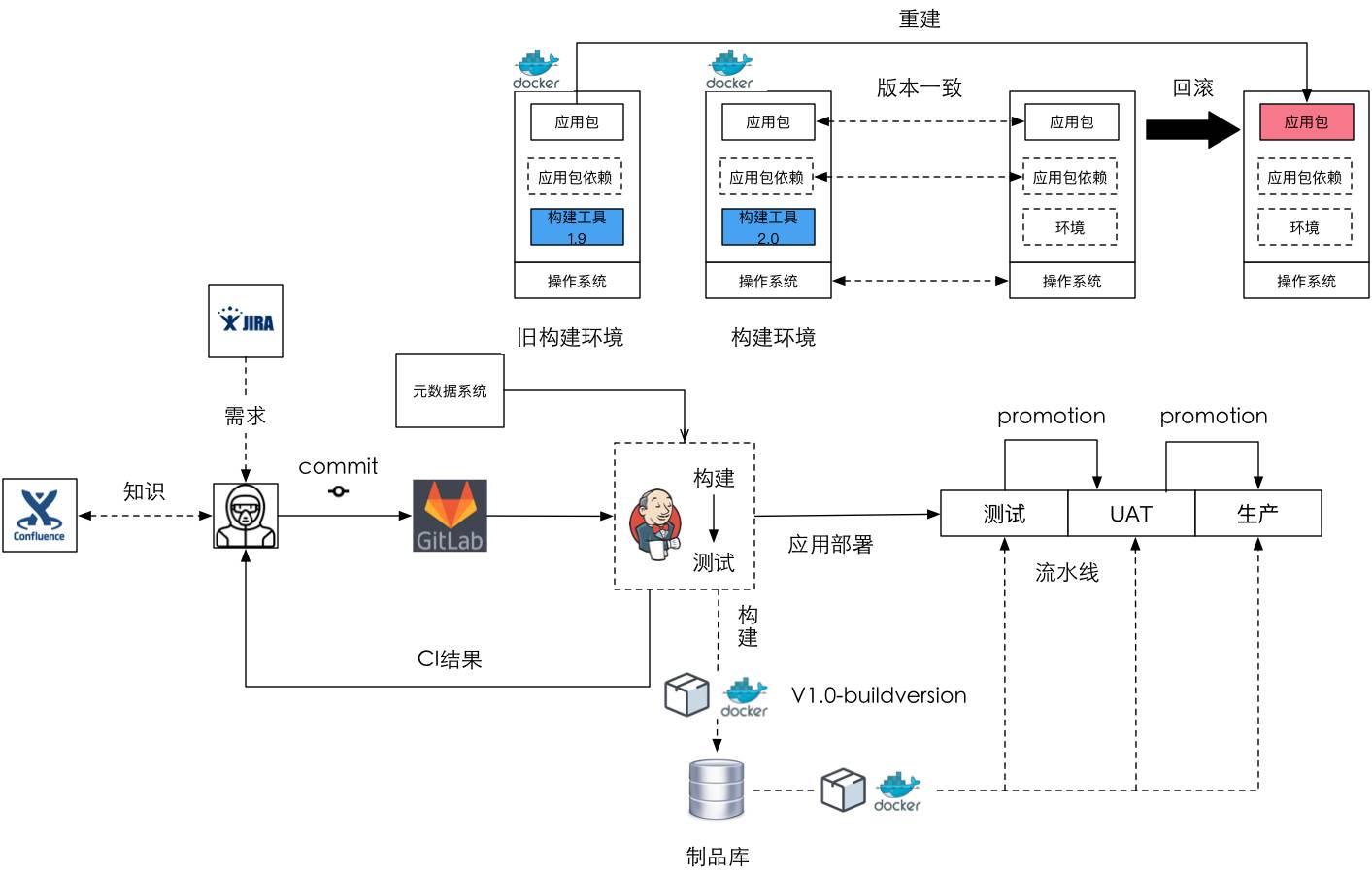
這個時候,Jenkins承擔了太多的工作,CI、構建、環境、部署都是放在它這兒,所以每個團隊上來做一個新的部署流水線時,要根據他的東西微調,重寫所有的指令碼,這實際上非常浪費時間。我們希望能通過配置,不需要重寫這些東西,也就是把程式設計性的工作變成配置性的工作。
持續交付3.0
-
關鍵工作系統化
首先,就是要把關鍵的工作做成單獨的系統,把它系統化;對於構建,我們不能再把它作為Jenkins的一個外掛,我們需要把它單獨拿出來做一個系統。部署也需要單獨做一個系統,都需要脫離Jenkins做,這樣才好管理,好拿一些關鍵性的資料。於是就演變成這樣一個系統,就是環境管理系統、執行環境、部署流水線、後設資料服務的一個簡單結構。
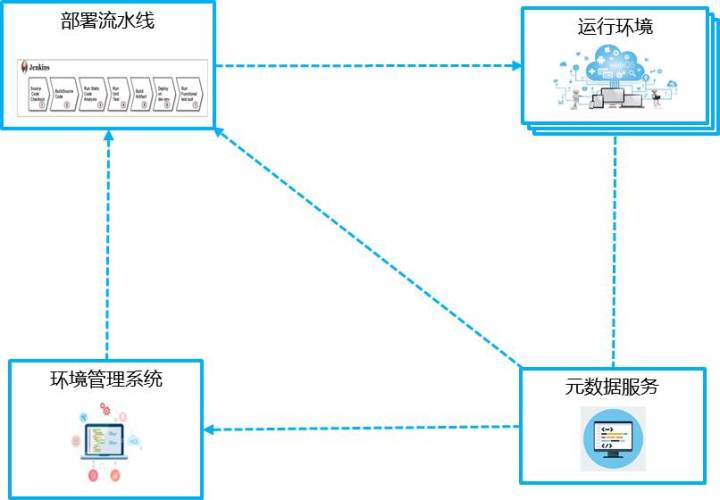
下一步我們要把程式設計性的工作變成配置性的工作,因為我們不想讓程式設計師老寫一大堆指令碼,而且在專屬系統內可以開展一些更細節的工作,這是什麼意思呢?
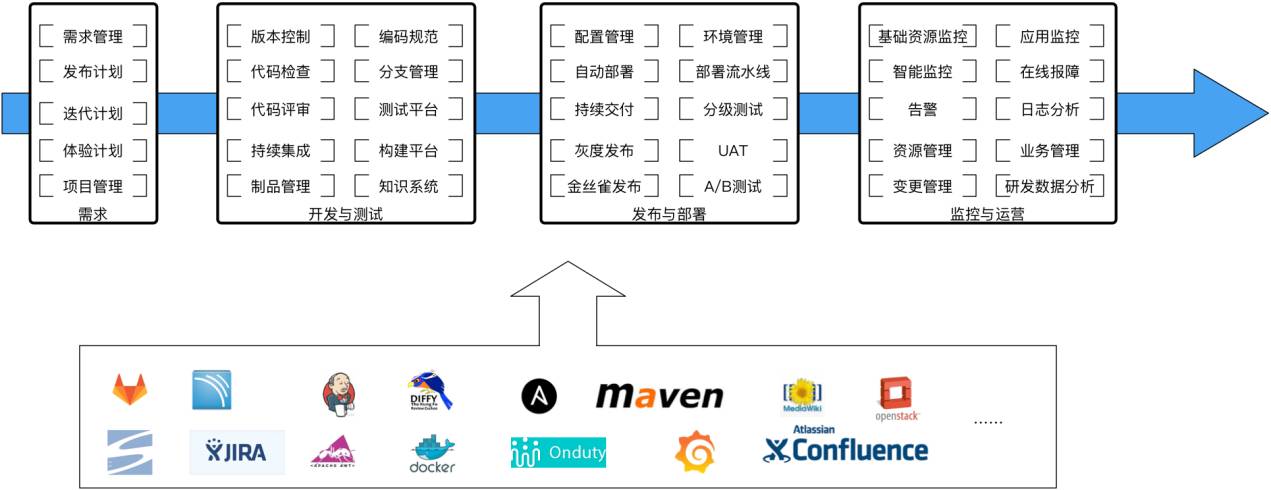
實際上你可以看到每一個部分都有很多的實踐要做,比如說部署策略,包括了一些分層測試、環境、流量進來怎麼樣分流,一些精確測試,告警這邊也是一樣的,有很多具體的細節實踐,如果都放在Jenkins裡是非常難做的。
這樣的話我們軟體開發交付的是什麼?應該是一個執行的系統,那麼這個系統的生成的過程應該是可配置、可重建、可追溯的,而且它的過程是自動化、服務化和視覺化的,整個過程都能一目瞭然地看到。
-
自改進體系
自改進的體系,這個是偏運維側的東西。第一個報障和事故分析,就是我們的系統到底執行得好與不好?業務執行的好壞怎麼樣判斷?最簡單的就是通過資料判斷。有一個方法就是我們一旦發現一個問題,就要迅速發現、定位、跟進、解決,而且要促進分析,產生改進,積累知識和支撐管理。
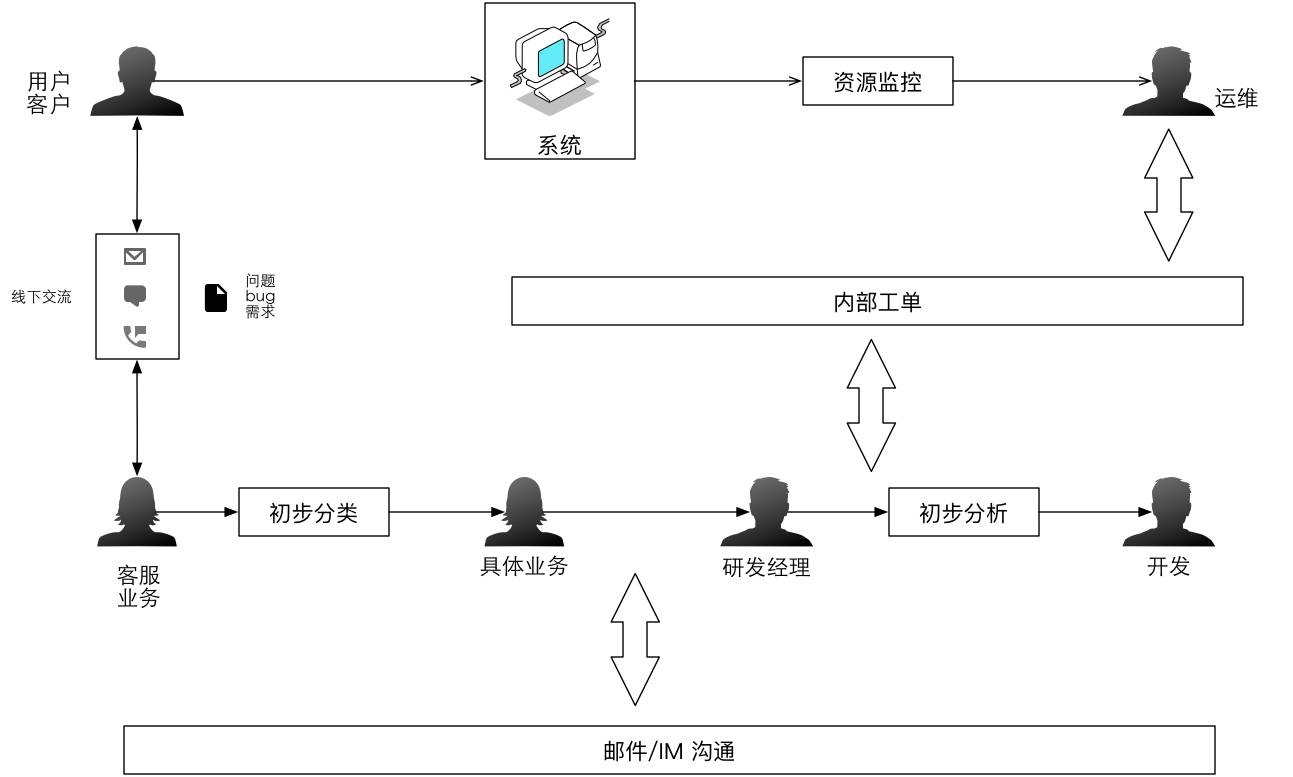
這是傳統的內部溝通的結構。它可能有個內部工單的系統,但沒有全流程的打通,而是通過郵件和IM這樣的東西去做溝通。
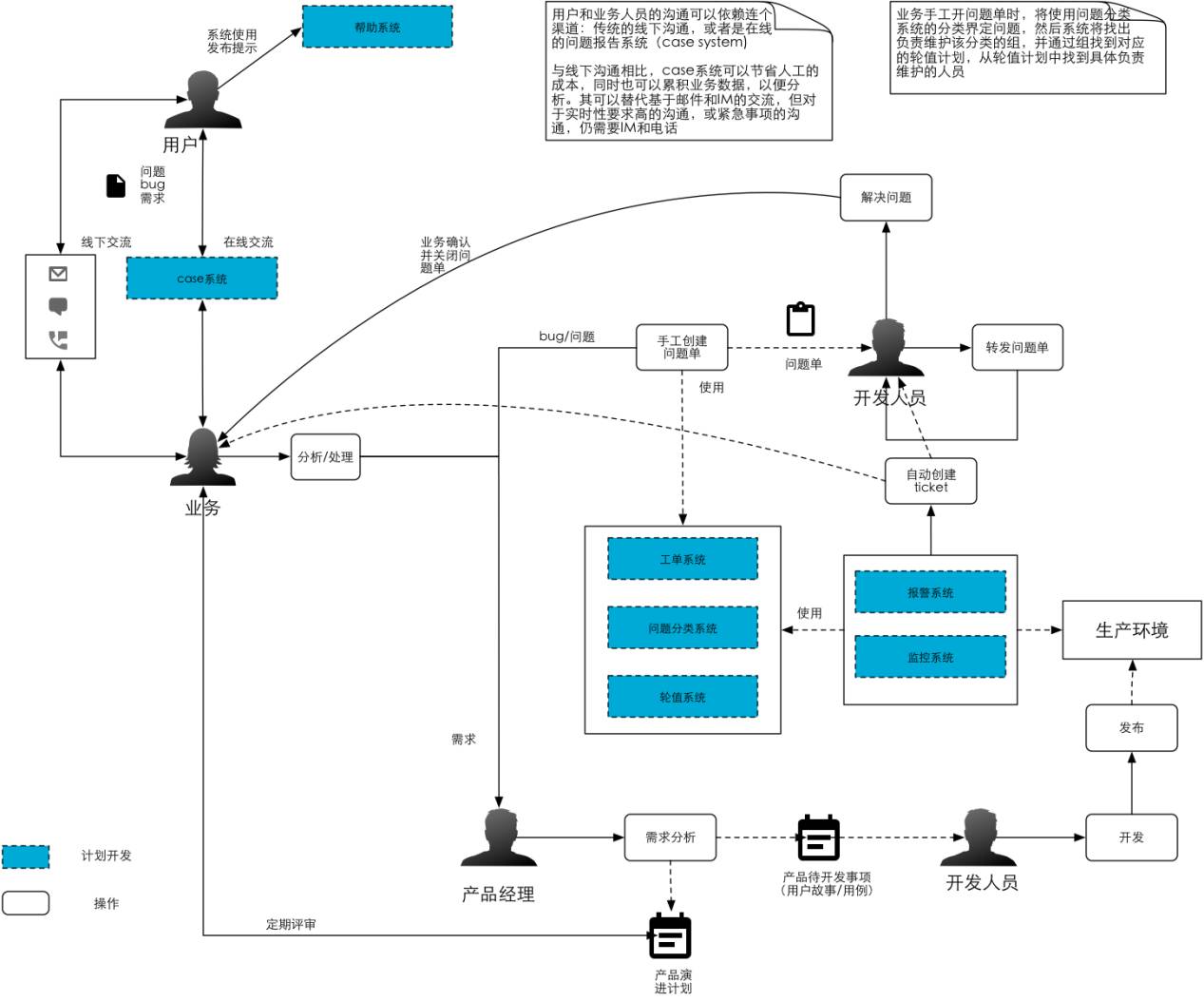
這是我給之前公司畫的流程,包括已經做的、還沒有做的事情,很複雜。但如果我加上兩個系統,就可以產生一個是輪值、報障系統,加上卓越運營的理念,就可以基於故障做事故分析,總結經驗,把它變成流程和工具的改進源頭。

整個結構如上圖所示,有智慧報障系統、根因分析系統,根因分析系統會產生兩種東西,第一種流程性的改進變成了SOP放在WIKI裡頭,然後專案性的東西反饋到JIRA裡面跟進,即哪一個迭代需要通過系統進行改進。然後系統可以根據指標(閾值)——是3級報障去生成一個COE(事故分析)還是2級報障要生成一個COE,就是谷歌和亞馬遜說的事故總結和分析,但它會有一些資料的分析和呈現。
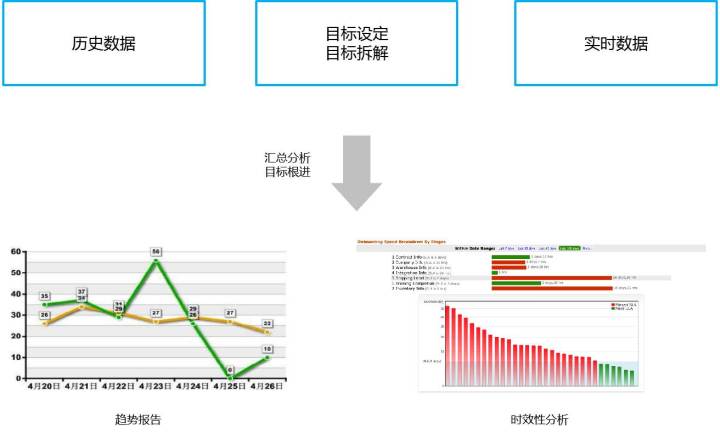
運營目標和運營資料方面,我們可以看歷史的資料和它的趨勢,整個SLA趨勢是不是在變好。
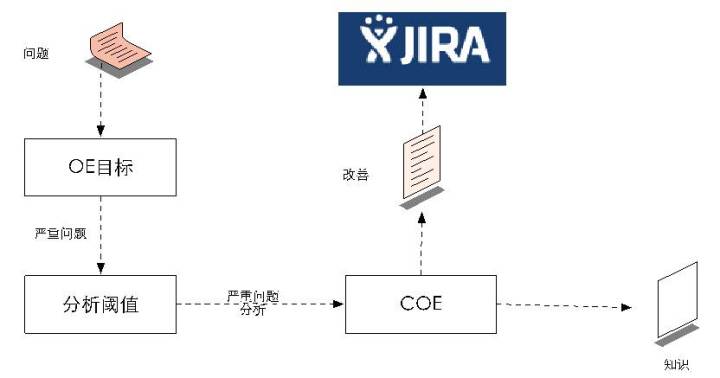
問題分析實際上是這樣一個結構,如果大家看SRE的話,SRE中的事故分析有五個結構,我們用的是亞馬遜的一套結構,跟谷歌的略有不同,但大致上是相同的,理念也是相同的。
APM、日誌與追蹤

運維側大家都比較熟悉,你會發現研發層面已經順暢,這時系統的執行狀態就是我們需要關注的,這實際上是縱向的和橫向的,縱向是從業務面的,橫向是在系統架構從前到後那麼多機器裡頭,到底哪出問題了,這時就會發現需要三個東西,第一個需要傳統的APM,第二需要日誌的分析,第三需要全鏈路的追蹤能力。
場景化運維:定位到點
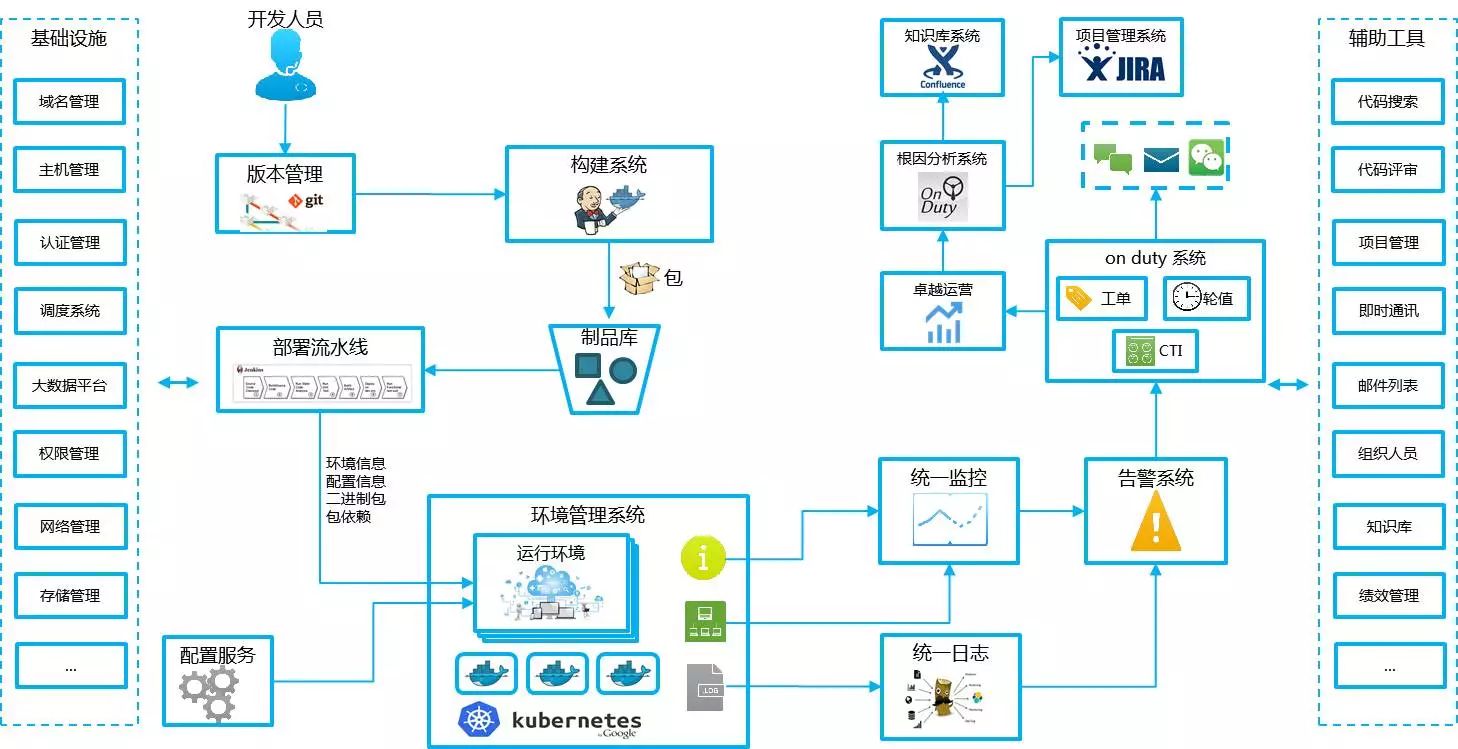
全景圖基本上如上圖所示,可以看到左邊是偏研發的,右邊是偏運維的,還有很多的工具在內部運營,比如統一身份的認證,安全掃描和管理,網路這些東西都需要,一旦運維起來整個業務很多東西都需要工具來支撐。這裡面績效管理、組織人員、郵件列表、技術通訊、專案管理都需要考慮方法。

整個組織結構如上圖,核心的東西實際上只考慮兩個東西。第一個就是誰構建誰運維,研發要做所有的事,因為他構建這個系統,所以他運維這個系統,但他不運維基礎設施,也不運維工具。第二個就是領導力,我們非常關注領導力,領導力是整個企業的核心價值,從人員的招聘、培養到淘汰,都是基於領導力考慮的。這裡我說幾項領導力,一是責任感,二是執行力,三是學習能力,你要判斷你招來的人是怎樣一個人,能否靠得住,他需要跟你企業價值觀高度吻合和融合。如果你招來一個人能力很強,但不認同你的價值觀,大家就很難到一塊工作。
下一步AIOps因為現在所有的原始資料都有了。當資料大量呈現出來時,要做到沒有誤報、沒有漏報,更具不同情況動態選擇閾值等等,還有很多要做的,比如說機器學習、異常檢測等。
總結
-
運維側的目標是自治系統
第一,在未來,運維側的改進是下一個爆發點,而且這個改進一定是去人化的,怎樣研製出自治的系統,不需要人為干預,出了問題馬上知道在哪,然後它自己去修復自己,這個是將來的趨勢。因為它不需要應用的運維,而是整個資源的運維,它要把所有東西都看成資源,所有的資料都能拿上來,無論是面的資料、點的資料、線的資料。目前我們也還在做這部分工作。
-
研發側的目標是ADPaas
第二,研發側的目標一定是ADPaas,將來研發要做一個系統出來時,並不是說我這個系統是一步步程式設計的,程式設計要做的應該是核心業務模組,但系統執行在什麼上面環境應該很簡單的搭建起來。我們基本的一個理念就是先利用開源,在公司規模比較小時開源是非常好的,先解決關鍵問題,不需要大生態的建設和佈局,在需要的時候才去自研,因為開源的東西絕對不可能滿足全部需求。
Q&A
Q1:老師剛才說的誰開發誰負責,可能在你們公司做得到,但像我的公司不一定做得到,因為我們很多系統都是包給不同的供應商,他們有自己環境的標準,或者說他們開發完交付以後不一定負責運維,還是有統一的團隊可能會做應用的運維。這一點上有沒有什麼辦法?或者說建一個抽象的或統一的標準來把這個東西實現?
A1:我們現在也在做一些輸出,就是幫著說銀行、能源去做這樣交付性的工作。你會發現網際網路企業的特點,就是什麼事都自己幹,為什麼?因為最快,跟他的業務結合得最緊。我們接觸到的銀行、電力,尤其是銀行系統,特別喜歡外包,他只做甲方。但你可以看到銀行的一個趨勢就是從五六年前開始,實際上是慢慢在解凍的,銀行現在也在學習網際網路,而且網際網路化的特別快,比如說平安、中信,這種有民資的不是完全國企化管得那麼嚴格的銀行實際上都是在向敏捷、DevOps轉型,他們學得很快,會把很多關鍵的開發系統拿回來自己做,因為這樣才是最快的。另外,電商公司的ERP系統有買的嗎,有,唯品會早期是買的,但是當訂單幾百萬時,買的軟體完全跟不上業務開發節奏,就變成了自研,所以整個趨勢一定是自研的。
接下來說一說我們的經驗。我們給一些能源系統實施的時候,如果你要外包你的軟體需要做好兩個東西,第一是這個軟體的標準化,就是怎麼樣跟你的大生態系統契合在一起,無論是架構上、還是整個管理流程上必須要有個通盤的考慮,第二你在做甲方的時候不要太舒服,需要外派一些人跟在他們那兒,這些人在系統交接完畢回來就變成了這個系統的運維層面的人。類似於谷歌的SRE,就是我要看著你把系統做出來,然後你參與到裡再拉回來,因為你不可能把他的人拉進來變成你的人。谷歌的SRE通常要求研發人員運維半年以上,系統穩定以後才交給SRE做下一步的運維。
Q2:老師您好,我想問一下剛才您說的誰研發誰運維這個問題,你們所有的產品都是由開發同學自己完全負責嗎?比方說有一個產品上線了以後,還需要產品運維之類的去介入嗎?還有另外就是ADPaaS這塊不是太瞭解,再簡單介紹一下。
A2:您剛才說有沒有產品需要其它運維的介入,現在的問題在於基本上不需要運維的介入,像CMDB這塊現在都是動態化的,不再是靜態的形式了,包括資源的申請也全部都是自動的,就是我要一個什麼資源,到運維這兒審計一下,一個資源自動就分配過來了。所以你沒有看到的那個東西就是我們之前在運維時,機器的申請還需要手工去做,但是後來上到Docker和其它的之後就不需要告訴你了,這都是可以做到的。在這個層面上,這個進步帶來的一個問題就是我們確實沒有再讓專門的人去做應用運維,因為我不知道什麼叫產品的運維,我們只有應用的運維。出了什麼問題,我的工具能告訴我哪個點出了問題就行了,接下來去修復它。
這裡面沒細講我們報障系統,它報賬一旦出來以後我們發現是機器壞了,誰負責修這個東西呢?是我們的運維的人員去負責的,因為這個機器是你管的,這個層面還是運維團隊去負責的,但是系統出了問題,邏輯出了問題,產品出了問題肯定是研發修復的。
第二個問題你剛才說的是ADPaas。亞馬遜內部有個叫做Apollo的系統有很多人沒有見過這個系統,這個系統非常強大,以前沒有Docker時,它已經做到了Docker所有能做到的事情,但是它沒有用Docker,比如Docker根本上是用檔案做分割槽,分資料夾的方式,理念是一樣的,但可以在單機上跑很多東西,做一些隔離,底層不管怎麼做,最後做出來的效果是開發人員看到的是一個環境管理系統,就是告訴你這裡有一個環境,這個環境包含哪些包,這些包只和執行環境有關係,還有哪些應用的包,我只宣告頂級包需要什麼,怎樣部署和部署哪些版本全部都是控制好的。這個東西就叫做ADPaas,也就是最後研發人員需要面對的是配置性的東西,怎麼上線、怎麼部署都是系統做的。
谷歌的方式是側重於運維端,谷歌的ADPaas就是圍繞Borg這個系統來做,他們的方法比較程式設計師化,不是那麼面向使用者。比如他把所有東西都打成一個大包,這樣的話最簡單,上線的時候就往上扔就行了,這個也都可以。你最後是不是ADPaas,實際就看研發人員面對系統的時候是不是有程式設計性的工作。
Q3:剛才說到那個產品可能您說應用領域可能說法不太一樣,但比如您說的現在所謂的IP變化就是那種服務化,但比如說你依賴的中介軟體,運用ADPaas自動生成,每個應用所用的都不太一樣,這樣怎麼做一個標準化的動作,或者出了故障的話這種是應該由誰來負責?
A3:我覺得你實際上說的是另一個東西,就是如果當你出現一個問題定位到事,定位到人,定位到點,就是剛才你說的到底發生了什麼事,這個事由誰來解決,它多長時間應該解決,這個實際上在我們內部是三個系統,第一個叫做問題分類系統,怎麼樣分類這個問題,第二個在問題分類的基礎上有一個輪值的系統,就是這些問題由哪些團隊進行處理,這些團隊今天誰當班,如果這個人不在的話怎麼樣告訴他經理,如果他經理不在再向上彙報。第三個定位到點的話,這就需要我們拉通,比如APM資料有沒有,其它業務日誌資料分析有沒有,在發生問題的一瞬間需要分析,然後把這些資料塞到報障系統裡頭。
很多時候自動化出現問題時,實際上我們大量情況下也能知道哪出問題了,可以自動去找。而我們需要AI處理的更多是誤報和漏報的東西,哪些東西可以動態調整的需要學習,減少誤報的情況。
↓↓↓↓↓↓↓↓ 獲得詳細的PPT下載連結:https://pan.baidu.com/s/1hsaP59U
相關文章
- 移動時代軟體測試團隊該往哪裡去?
- DevOps落地,這裡有幾個案例想和你聊聊!dev
- 蘋果企業簽名去哪裡找?蘋果
- 遊戲產業站在十字路口,騰訊往哪裡走遊戲產業
- Oracle將往何處去?Oracle
- 視訊去水印工具哪個好用
- 自定義的請求頭,你去哪裡了?
- Python培訓去哪裡好?學習需要多久?Python
- 想學Linux運維技術,去哪裡好呢?Linux運維
- ASP.NET MVC 4 檢視頁去哪裡兒ASP.NETMVC
- 京東數科DevOps落地攻略dev
- Linux記憶體被吃掉了,它去哪裡了?Linux記憶體
- Linux雲端計算運維去哪裡培訓好?Linux運維
- 都說DevOps落地難,到底難在哪裡?也許你還沒找到套路dev
- 如何打造易用的DevOps工具鏈dev
- AI=機器學習²,我們在去往²的路上AI機器學習
- 杭州哪裡可以開發票“哪裡能開,哪裡有開”
- 武漢哪裡可以開發票“哪裡能開,哪裡有開”
- 南昌哪裡可以開發票“哪裡能開,哪裡有開”
- 業務瘦身42%+效率提升50% :去哪兒網業務重構DDD落地實踐
- 歸去來兮
- 報名最後三天 | DevOps落地,這裡有幾個案例想和你聊聊!dev
- Linux運維應該怎麼學?去哪裡學啊?Linux運維
- DevOps落地實施要有哪些支柱?dev
- 重慶哪裡可以開發票“哪裡能開,哪裡有開”
- 長沙哪裡可以開發票“哪裡能開,哪裡有開”
- 賣茶葉去哪裡進貨放心,茶葉代理在哪拿貨
- DevOps落地實踐,BAT系列,敏捷看板devBAT敏捷
- 面試: 怎麼往 Generator 裡拋個錯?面試
- 如何應用雲架構DevOps?架構dev
- Sevenhugs智慧遙控器:哪裡要用點哪裡
- 往IE中嵌入工具條 (轉)
- 想學習Linux運維應該去哪裡?Linux學多久?Linux運維
- 如何把圖片轉換成文字?轉換工具用哪個?
- mac上哪款文字處理工具好用?看這裡Mac
- 濟南哪裡有開發具票#如何#
- Cookie是什麼?從哪來?存在哪?往哪去?Cookie
- DevOps與傳統的融合落地實踐dev