想開始陸續研究一些感興趣的開原始碼於是先挑一個程式碼量短的來過渡一下,寫這篇部落格的目的是記錄下自己學習的過程。Tinyhttpd算是一個微型的web伺服器,瀏覽器與Web伺服器之間的通訊採用的是Http,所以一開始的切入點是HTTP協議,這裡說一點如果有做HTTP通訊的開發還是看一下RFC中對不同版本HTTP的定義,以下原理部分都是從《後臺開發:核心技術與應用實踐》中HTTP協議章節中裁剪出來的,對後臺感興趣的同學可以看一下,講述後臺開發所需要具備的技術點一本很不錯的書。
一、HTTP協議
HTTP工作流程:
在OSI七層模型中,HTTP是基於TCP上的應用層協議而我們所說的HTTPS基於同處於應用層的TLS、SSL協議層之上。HTTP預設的埠號為80,HTTPS預設的埠號為443。在HTTP1.1中(通過Connection頭設定)預設在HTTP傳輸完成後不斷開TCP連線,在此之前的HTTP版本則預設是斷開連線的,也就是說這次請求與上次請求是不同的兩個TCP連線。一次HTTP操作稱為一個事務,其工作過程可以分為以下四步。
(1)首先客戶機與伺服器需要建立連線 。 只要單擊某個超級連結, HTTP 的工作即開始 。
(2)建立連線後,客戶機傳送一個請求給伺服器,請求方式的格式為:統一資源識別符號(URL )、協議版本號,後邊是 MIME 資訊(包括請求修飾符、客戶機資訊和可能的內容) 。
(3)伺服器接到請求後,給予相應的響應資訊,其格式為一個狀態行,包括資訊的協議版本號、一個成功或錯誤的程式碼,後邊是 MTh伍資訊(包括伺服器資訊、實體資訊和可能的內容) 。
(4)客戶端接收伺服器所返回的資訊通過瀏覽器顯示在使用者的螢幕上,然後客戶機與伺服器斷開連線 。
HTTP協議結構:
HTTP 協議無論是請求報文還是迴應報文,都分為以下 4 個部分 。
(1)報文頭( initial line ),上面的例子中的“ GET http://www.baidu.com/favicon.icoHTTP/1.1 ”表示用 GET 方法請求 http://www.baidu.com/favicon. ic。這個檔案,用的是HTTP/1.1 協議。
(2) 0 個或多個請求頭( header line ),例如 Accept-Language: en
(3)空行(作為 header lines 的結束) 。
(4)可選的訊息體 。
HTTP 協議是基於行的協議,每一行 以 \r\n 作為分隔符 。 報文頭通常表明報文的型別(例如請求型別),且報文頭只佔一行 ;請求頭附帶一些特殊資訊,每一個請求頭佔一行,其格式為 name:value ,即以分號作為分隔; 空行也就以一個 \r\n 分隔;可選 body 通常包含資料,例如伺服器返回的某個靜態 HTML 檔案的內容 。
HTTP請求方法:
HTTP/ 1.1 協議中共定義了 9 種方法(有時也叫“動作”)來表 明 Request-URI 指定的資源的不同操作方式,如下所述。
( 1 ) OPTIONS :返回伺服器針對特定資源所支援的 HTTP 請求方法;也可以利用向 Web伺服器傳送“*”的請求來測試伺服器的功能性。
( 2) HEAD :向伺服器索要與 GET 請求相一致的響應,只不過響應體將不會被返回 。 這一方法可以在不必傳輸整個響應內容的情況下,就可以獲取包含在響應訊息頭中的元資訊 。該方法常用於測試超連結的有效性,是否可以訪問,以及最近是否更新等資訊 。
( 3) GET :向特定的資源發出請求 。 注意 : GET 方法不應當被用於產生“副作用”的操作中,例如在 web app . 中的應用,其中一個原因是 GET 可能會被網路蜘蛛等隨意訪問 。
( 4 ) POST :向指定資源提交資料進行處理請求(例如提交表單或者上傳檔案) 。 資料被包含在請求體中 。 POST 請求可能會導致新的資源的建立或對已有資源的修改 。
( 5 ) PUT :向指定資源位置上傳其最新內容 。
( 6) DELETE : 請求伺服器刪除 Request-URI 所標識的資源 。
( 7 ) TRACE :回顯伺服器收到的請求,主要用於測試或診斷。
( 8) CONNECT: HTTP/ 1.1 協議中預留給能夠將連線改為管道方式的代理伺服器 。
( 9) PATCH :用來將區域性修改應用於某一資源,該操作新增於規範盯C5789 中 。
HTTP 伺服器至少應該實現 GET 和 HEAD 方法,其他方法都是可選的 。 此外,除了上述方法,特定的 HTTP 伺服器還能夠擴充套件自定義的方法 。
HTTP 常見的請求頭:
在 HTTP/ l.l 協議中,所有的請求頭(除 Host 外)都是可選的,因為Host主要用於請求的伺服器的IP地址和埠號,請求頭有Host、Connection、Accept、Accept-Encoding、User-Agent、Cookie等,請求頭太多這裡就不列出來了。
HTTP迴應報文:
返回碼由 3 位數字組成,第一個數字定義了響應的類別,且有 5 種可能的取值。
( 1 ) lxx :指示資訊,表示請求已接收,繼續處理。
( 2) 2xx :成功,表示請求已被成功接收、理解 、 接受 。
( 3) 3xx :重定向,要完成請求必須進行更進一步的操作 。
( 4 ) 4xx :客戶端錯誤,請求有語法錯誤或請求無法實現。
( 5) 5xx :伺服器端錯誤,伺服器未能實現合法的請求 。
Date :表示訊息傳送的時間,時間的描述格式由 rfc822 定義 。
Server : 指明 Web 伺服器用來處理請求的軟體資訊 。
Accept-Ranges : Web 伺服器表明自己是否接收穫取其某個實體的一部分(比如檔案的一部分)的請求 。 bytes 表示接收, none 表示不接收。
Vary: Web 伺服器用該頭部的內容告訴 Cache 伺服器,在什麼條件下才能用本響應所返回的物件響應後續的請求 。
Content-Encoding : Web 伺服器表明自己使用了什麼壓縮方法( gzip, deflate)壓縮響應中的物件。
Content-Length: Web 伺服器告訴瀏覽器自己響應的物件的長度 。
Content-Type: Web 伺服器告訴瀏覽器自己響應的物件的型別 。
二、CGI
CGI ( Common Gateway Interface ,通用閘道器介面)是 HTTP 協議中最重要的技術之一,有著不可替代的重要地位 。 CGI 是一個 Web 伺服器提供資訊服務的標準介面 。 通過 CGI 介面, Web 伺服器就能夠獲取客戶端提交的資訊,轉交給伺服器端的 CGI 程式進行處理,最後返回結果給客戶端 。 組成 CGI 通訊系統的是兩部分: 一部分是 HTML 頁面,就是在使用者端瀏覽器上顯示的頁面;另一部分則是執行在伺服器上的 CG I 程式 。
瀏覽器只需要指定執行伺服器上的哪個CGI程式就行,一般情況下,伺服器和 CGI 程式之間是通過標準輸入輸出來進行資料傳遞的(就像tinyhttpd中呼叫CGI程式),而這個過程需要環境變茸的協作方可實現。環境變數在 CGI 中有著重要的地位,每個 CGI 程式只能處理一個使用者請求,所以在啟用一個CGI程式程式時也建立了屬於該程式的環境變數,CGI程式能夠用Python、PERL、Shell、C或C++等語言來實現。
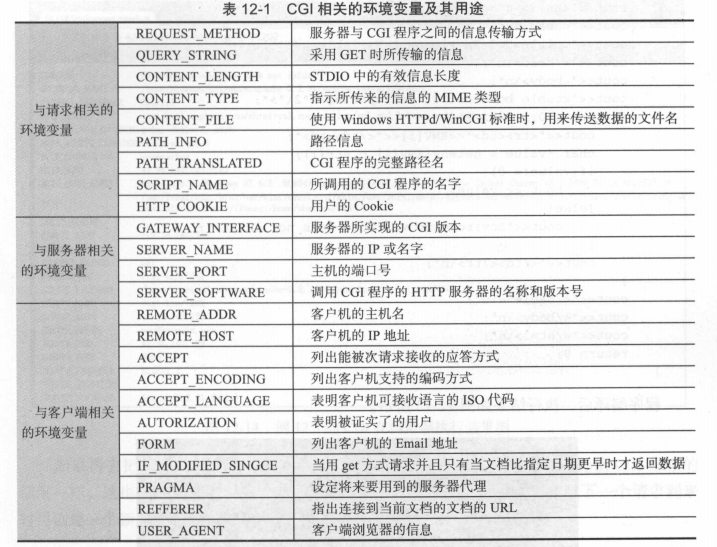
CGI 環境變數在 CGI 程式啟動時初始化,在結束時銷燬。當一個 CGI 程式不是被 HTTP 伺服器呼叫時,它的環境變盤幾乎是系統環境變數的複製 。當這個 CGI 程式被 HTTP 伺服器呼叫時,它的環境變數就會多了以下關於HTTP 伺服器、客戶端、 CGI 傳輸過程等專案。CGI 相關的環境變數有 3 種:與請求相關的環境變數、與伺服器相關的環境變數和與客戶端相關的環境變數,,詳細見表 12-1 。
CGI 工作原理:每當客戶請求 CGI 的時候 Web 伺服器就請求作業系統生成一個新的CGI 程式,該程式處理完請求後退出,下一個請求來時再建立新程式 。 當然,這樣在訪問量很少沒有併發的情況可行,可是當訪問量增大且併發存在時,這種方式就不適合了,於是就有了FastCGI。
一般情況下, FastCGI 的整個工作流程如下所述。
( 1 ) Web Server 啟動時載入 FastCGI 程式管理器( IIS ISAPI 或 Apache Module ) 。
( 2 )FastCGI 程式管理器自身初始化,啟動多個 CGI 程式並等待來自 Web 伺服器的連線 。
( 3 )當客戶端請求到達 Web Server 時, FastCGI 程式管理器選擇並連線到一個 FastCGI程式 。 Web 伺服器將 CGI 環境變數和標準輸入傳送到 FastCGI 程式 。
( 4) FastCGI 子程式完成處理後將標準輸出和錯誤資訊從同一連線返回 Web Server。當FastCGI 子程式關閉連線時,請求便被告知處理完成 。 FastCGI 程式接著等待並處理來自FastCGI 程式管理器(執行在 Web 伺服器中)的下一個連線 。
三、tinyhttpd解析
關於tinyhttpd的程式碼解析的部落格太多了,流程跟註釋都描述的很詳細,隨便搜個tinyhttpd解析就有很多部落格出現,這裡還是寫一下自己在看這份原始碼時缺乏的知識點,因為我幾乎沒有linux下程式設計的經驗,所以對linux下用的Glib庫呼叫不太熟悉,TCP協議棧也是我只看過過輕量級Lwip的原始碼。
1.bind函式當傳入的port為0時是會隨機分配一個埠號,所以tinyhttpd中才會有顯示隨機的埠號,getsockname函式獲取套接字的地址把動態分配的埠號值取出。
![]()

2.int stat(const char *file_name, struct stat *buf);通過檔名filename獲取檔案資訊,並儲存在buf所指的結構體stat中,S_IXUSR:檔案所有者具可執行許可權,S_IXGRP:使用者組具可執行許可權,S_IXOTH:其他使用者具可讀取許可權。
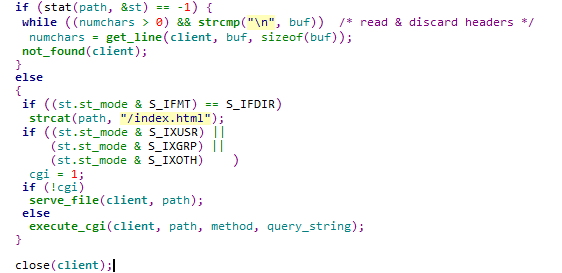
3.int pipe(int filedes[2]);
返回值:成功,返回0,否則返回-1。引數陣列包含pipe使用的兩個檔案的描述符。fd[0]:讀管道,fd[1]:寫管道。
必須在fork()中呼叫pipe(),否則子程式不會繼承檔案描述符。兩個程式不共享祖先程式,就不能使用pipe。但是可以使用命名管道。
pipe(cgi_output)執行成功後,cgi_output[0]:讀通道 cgi_output[1]:寫通道

int dup2(int oldfd,int newfd);函式的作用是複製檔案描述符。
4.fork函式,建立一個子程式,fork函式之後的部分由在fork函式執行完畢後,如果建立新程式成功,則出現兩個程式,一個是子程式,一個是父程式。在子程式中,fork函式返回0,在父程式中,fork返回新建立子程式的程式ID,有時間再看fork原始碼是如何實現的。
5.execl函式執行,第一引數path字元指標所指向要執行的檔案路徑,後面跟著可變引數,這裡說一點由於GCC使用AAPCS規範,可變引數的實現小於四個的話是從r0-r3獲取,大於四個的話就要從棧中獲取引數。
6.pid_t waitpid(pid_t pid, int * status, int options);會暫時停止目前程式的執行, 直到有訊號來到或子程式結束.
在編寫部落格邊看tinyhttpd,目前自己的不夠清楚的函式就上面幾個,有空再看看它們的原始碼實現。