【Python】透過Python備份itpub部落格
最近在學習python語言,今天練習了一下如何利用Python備份itpub部落格
1,備份一篇部落格
2,備份所有部落格
1,備份一篇部落格
- 以http://blog.itpub.net/29096438/viewspace-1982636/這篇部落格為例
- 檢視原始碼可以看到標題部分的原始碼為
- <a href<a ="/29096438/viewspace-1982636/">【Python】python練習
-
-
我們主要是想提取出中間紅色色部分的URL,然後找到這篇文章的正文進行分析,然後提取進行下載。首先,假
設已經得到這個字串,然後研究如何提取這個URL,觀察發現,對於所有的這類字串,都有一個共同點,那
就是都含有子串'<a 'href="</a 'href=/29096438",那麼我們可以用最笨的方式---查詢子串進行定界。
執行程式碼發現部落格已經備份下來了-
# -*- coding: cp936 -*-
-
import re
-
import urllib2
-
str = 'http://blog.itpub.net/29096438/viewspace-1982636/">【Python】python練習' ---自己手工補全網址,原始碼裡面的href不全
-
-
fname=re.match('(.*)',str)
-
fname2=fname.group(1)+'.html'
-
print fname2
-
-
start = str.find(r'href=')
-
start += 6
-
end = str.find('viewspace')
-
end += 17
-
url = str[start : end]
-
print url
-
-
-
text=urllib2.urlopen(url).read()
-
f=open(fname2,'w')
-
f.write(text)
- f.close()
-
# -*- coding: cp936 -*-
- 程式碼被轉義了
-

2,備份所有部落格
- 首先進入目錄列表檢視原始碼
- 所有文章的URL都符合一個模式,除了文章id不一樣,29096438就是我們的使用者id吧,每個人都有個獨特的id,29096438就是我的使用者id
- <a href<a ="/29096438/viewspace-1981855/">【Mysql】sysbench基準測試工具
- <a href<a ="/29096438/viewspace-1982636/">【Python】python練習
-
-
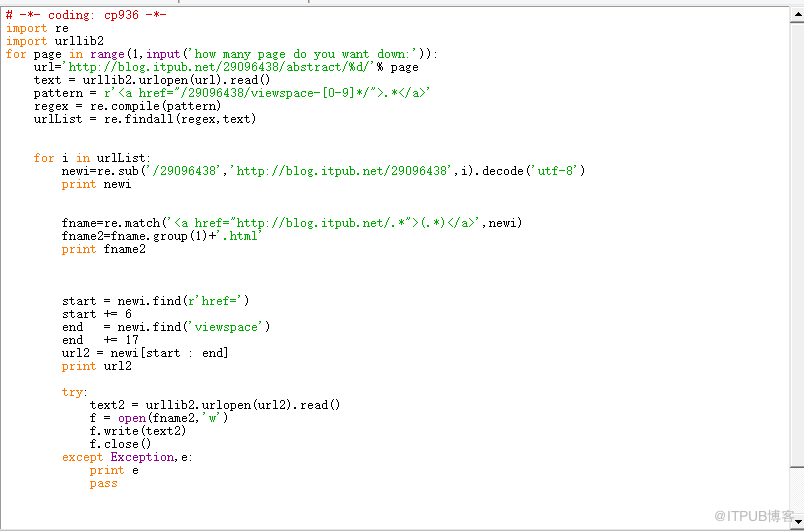
# -*- coding: cp936 -*-
-
import re
import urllib2
for page in range(1,input('how many page do you want down:')): ###這兒就是輸入你希望下載的頁數,輸入你的總頁數吧
url='http://blog.itpub.net/29096438/abstract/%d/'% page ####迴圈不同的頁
text = urllib2.urlopen(url).read()
pattern = r'.*'
regex = re.compile(pattern)
urlList = re.findall(regex,text) ####透過正規表示式找到所有文章的href,此時的href是帶上標題的
for i in urlList:
newi=re.sub('/29096438','http://blog.itpub.net/29096438',i).decode('utf-8') ###補全文章的href,,因為我們獲取到的href是不全
的,少了http://blog.itpub.net這一段,decode編碼是為了解決亂碼問題
#print newi
fname=re.match('(.*)',newi)
fname2=fname.group(1)+'.html' ####獲取文章的標題名
#print fname2
start = newi.find(r'href=')
start += 6
end = newi.find('viewspace')
end += 17
url2 = newi[start : end]
print url2 ####去掉上面href中的標題 只獲取href的網址部分
try:
text2 = urllib2.urlopen(url2).read()
f = open(fname2,'w')
f.write(text2)
f.close()
except Exception,e:
print e
pass
- 程式碼有轉義,注意被轉換部分
-
-
how many page do you want down:12 ---我的文章總共12頁,所以輸了個12
-
<a href="http://blog.itpub.net/29096438/viewspace-1682206/">【Mysql】搭建mysql-cluster</a>
-
-
【Mysql】搭建mysql-cluster.html
-
-
http://blog.itpub.net/29096438/viewspace-1682206
-
-
coercing to Unicode: need string or buffer, _sre.SRE_Match found
-
-
<a href="http://blog.itpub.net/29096438/viewspace-1982636/">【Python】python練習</a>
-
-
【Python】python練習.html
-
-
http://blog.itpub.net/29096438/viewspace-1982636
-
-
coercing to Unicode: need string or buffer, _sre.SRE_Match found
-
-
<a href="http://blog.itpub.net/29096438/viewspace-1981855/">【Mysql】sysbench基準測試工具</a>
-
-
【Mysql】sysbench基準測試工具.html
-
-
http://blog.itpub.net/29096438/viewspace-1981855
-
-
coercing to Unicode: need string or buffer, _sre.SRE_Match found
-
-
<a href="http://blog.itpub.net/29096438/viewspace-1981811/">【Mysql】MySQL查詢計劃key_len全知道</a>
-
-
【Mysql】MySQL查詢計劃key_len全知道.html
-
-
http://blog.itpub.net/29096438/viewspace-1981811
-
-
coercing to Unicode: need string or buffer, _sre.SRE_Match found
-
-
<a href="http://blog.itpub.net/29096438/viewspace-1980112/">【Pyrhon】Python在自動化運維時經常會用到的方法</a>
-
-
【Pyrhon】Python在自動化運維時經常會用到的方法.html
-
-
http://blog.itpub.net/29096438/viewspace-1980112
-
-
coercing to Unicode: need string or buffer, _sre.SRE_Match found
-
-
<a href="http://blog.itpub.net/29096438/viewspace-1979572/">【Python】Python連線mysql</a>...
-
....
-
....
- ...
-

-
程式碼:
點選(此處)摺疊或開啟
改進,用beautiful模組取出正文部分
try:
r=requests.get(url2)
soup=bsp(r.content)
cont=soup.find('div',{'class':'Blog_wz1'})
f=open(fname2,'w')
f.write(str(cont))
f.close()
except:
pass
執行結果:
點選(此處)摺疊或開啟
可以看到下載的結果
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/29096438/viewspace-1983945/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 【Python】備份itpub部落格Python
- 小花狸ITPUB部落格備份工具
- 部落格園部落格記錄備份
- Hexo部落格備份Hexo
- 開通ITPub部落格了!
- python好部落格Python
- 透過vscode寫部落格VSCode
- CSDN部落格匯出備份工具
- 部落格園 geek 主題備份
- 今天剛開通ITPUB部落格
- 開通ITPub的部落格啦!
- Python部落格導航Python
- 部落格連結—PythonPython
- 部落格備份工具:Blog_Backup
- 軟體工程教學部落格 (備份)軟體工程
- 部落格園資料備份相關
- 開啟ITPUB部落格專欄技能!
- Ubuntu 14下發布ITPUB部落格Ubuntu
- 部落格連結—Oracle備份與恢復Oracle
- python老師的部落格Python
- 給ITPub部落格小編的幾句話
- 部落格地址http://space.itpub.net/24496749HTTP
- networker透過備用千兆網路備份
- 線上透過dd命令備份分割槽
- unix下透過ftp定時備份FTP
- 如何利用客戶端在itpub發部落格客戶端
- ITPUB部落格頻道電子期刊上線
- ITPUB的部落格空間做的真爛
- Python爬取CSDN部落格資料Python
- 直接透過備份恢復資料庫資料庫
- 透過python發郵件Python
- Python學習要寫部落格嗎?Python程式設計Python程式設計
- 【爬蟲】利用Python爬蟲爬取小麥苗itpub部落格的所有文章的連線地址(1)爬蟲Python
- 學習Python必看的幾個 部落格Python
- Python——個人部落格專案開發Python
- 透過rman備份system系統表空間
- 轉載|如何利用客戶端在itpub發部落格客戶端
- Python爬蟲入門教程 40-100 部落格園Python相關40W部落格抓取 scrapyPython爬蟲