ORACLE關於執行計劃的簡要分析
一、如何開啟執行計劃:
開啟執行計劃(執行 set autotrace traceonly/off),如果提示SP2-0611,SP2-0618,按以下辦法建立相應使用者即可。
1、SYS使用者登入,執行@$ORACLE_HOME/rdbms/admin/utlxplan.sql,建立PLAN_TABLE ;
2、執行@$ORACLE_HOME/sqlplus/admin/plustrce.sql,建立plustrace角色;
3、賦給使用者grant plustrace to public;
執行 set autotrace traceonly即可。也可以採用以下方式:
1、explain plan for select * from student;
2、select * from table(DBMS_XPLAN.display);
二、執行計劃的內容解析:
目前ORACLE最佳化器採用的是基於cost的cbo方式來對sql進行最佳化,因此最佳化器的判斷非常依賴於資料庫物件的統計分析資訊。只有提供給最佳化器正確的物件資訊(DBMS_STAT),才能使得最佳化器做出正確的選擇。
最佳化器選擇的方式無怪乎本文以下幾種方式,只要正確的理解執行計劃中這些內容,就可以根據資料庫物件的資料量和索引情況來改進sql的效能。
看執行計劃時,首先Operation列是指當前操作的內容。從縮排最大的行看,它是最先被執行的步驟,對於兩行縮排相同的行,最上面的最先被執行;ROW列,是ORACLE估算當前行的返回結果集;COST和TIME是ORACLE估算的成本和時間。
oracle訪問資料的存取方式有:
全表掃描(TABLE ACCESS FULL):對所有表中記錄進行掃描。使用多塊讀操作,一次I/O能讀取多塊資料塊。表欄位不涉及索引時往往採用這種方式。較大的表不建議使用全表掃描,除非結果資料超出全表資料總量的10%;
透過ROWID的表存取(Table Access by ROWID):一次I/O只能讀取一個資料塊。透過rowid讀取表欄位,rowid可能是索引鍵值上的rowid;
索引掃描(Index Scan):索引掃描是首先掃描索引得到rowid值,該步驟的資料直接由記憶體讀取,速度較快;然後透過rowid讀出具體資料,如果表較大效率會下降。索引掃描有4種型別的索引掃描:
1、索引唯一掃描(index unique scan),如果表欄位有UNIQUE 或PRIMARY KEY 約束,oracle實現索引唯一掃描,這種掃描方式條件比較極端,出現比較少;
2、索引範圍掃描(index range scan),這種是最常見的索引掃描方式。在非唯一索引上都使用索引範圍掃描。
使用index rang scan的3種情況:
1 ) 在唯一索引列上使用了以下圈定範圍的運算子(> < <> >= <= between等)
2 ) 在組合索引上,只使用部分列進行查詢,導致查詢出多行
3 ) 對非唯一索引列上進行的任何查詢。
3、 索引全掃描(index full scan):這種情況下,是查詢的資料都屬於索引欄位,一般都含有排序操作
4、索引快速掃描(index fast full scan):如果查詢的資料都屬於索引欄位,並且沒有進行排序操作,那麼是屬於這種情況。條件比較極端,出現比較少;
表之間的連線方式有
1、排序 - 合併連線(Sort Merge Join):該種排序限制較大,出現比較少;
內部連線過程:
1) 首先生成表1需要的資料,然後對這些資料按照連線操作關聯列進行排序;
2) 隨後生成表2需要的資料,然後對這些資料按照與表1對應的連線操作關聯列進行排序;
3) 最後兩邊已排序的行被放在一起執行合併操作,即將2個表按照連線條件連線起來。
2、巢狀迴圈(Nested Loops)
該連線過程就是一個2層巢狀迴圈,所以外層迴圈的次數越少越好。如果driving row source(外部表)比較小,並且在inner row source(內部表)上有唯一索引,或有高選擇性非唯一索引時,使用這種方法可以得到較好的效率。
3、雜湊連線(Hash Join)
在2個較大的row source之間連線時會取得相對較好的效率,在一個row source較小時則能取得更好的效率。
三、統計資料的含義:
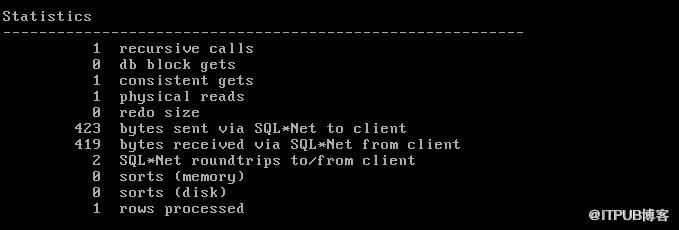
- recursive calls 遞迴呼叫次數;
- db block gets 當期操作時從記憶體讀取的當前最新塊資料,並不是在一致性讀的情況的塊數,即透過update/delete/select for update讀的塊數;
- consistent gets 當期操作時在一致性讀狀態下讀取的塊數,即透過不帶for update的select 讀的塊數;
- physical reads 物理讀,oracle從磁碟讀的資料塊數量 其產生的主要原因是:在資料庫快取記憶體中不存在這些塊;全表掃描;磁碟排序。其中邏輯讀指的是Oracle從記憶體讀到的資料塊數量。一般來說是'consistent gets' + 'db block gets'。當在記憶體中找不到所需的資料塊的話就需要從磁碟中獲取,於是就產生了'phsical reads'。
- redo size 執行SQL的過程中產生的重做日誌;
- 423 bytes sent via SQL*Net to client 透過網路傳送給客戶端的資料
- 419 bytes received via SQL*Net from client 透過網路從客戶端接收到的資料
- SQL*Net roundtrips to/from client
- sorts (memory) 在記憶體中發生的排序;
- sorts (disk) 在硬碟中發生的排序;
- rows processed
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/8494287/viewspace-1349493/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- Oracle資料庫關於SQL的執行計劃Oracle資料庫SQL
- oracle執行計劃相關Oracle
- Oracle資料庫關於SQL的執行計劃(轉)Oracle資料庫SQL
- 【優化】ORACLE執行計劃分析優化Oracle
- 關於索引的執行計劃記載索引
- Oracle檢視正在執行的SQL以及執行計劃分析OracleSQL
- 分析執行計劃優化SQLORACLE的執行計劃(轉)優化SQLOracle
- 關於執行計劃中的%CPU的含義
- ORACLE執行計劃Oracle
- 分析執行計劃最佳化SQLORACLE的執行計劃(轉)SQLOracle
- 【執行計劃】Oracle獲取執行計劃的幾種方法Oracle
- 【Oracle】-【索引-HINT,執行計劃】-帶HINT的索引執行計劃Oracle索引
- explain執行計劃分析AI
- SQL執行計劃分析SQL
- oracle cardinality對於執行計劃的影響Oracle
- SqlServer的執行計劃如何分析?SQLServer
- Oracle 執行計劃 分析和動態取樣Oracle
- oracle 固定執行計劃Oracle
- Oracle sql執行計劃OracleSQL
- oracle sqlprofile 固定執行計劃,並遷移執行計劃OracleSQL
- 看懂Oracle中的執行計劃Oracle
- ORACLE執行計劃的介紹Oracle
- ORACLE執行計劃的檢視Oracle
- oracle執行計劃的使用(EXPLAIN)OracleAI
- Oracle中檢視已執行sql的執行計劃OracleSQL
- 檢視Oracle SQL執行計劃方法比較、分析OracleSQL
- Oracle執行計劃詳解Oracle
- oracle固定執行計劃--sqlprofileOracleSQL
- Oracle 索引和執行計劃Oracle索引
- Oracle閱讀執行計劃Oracle
- oracle 執行計劃變更Oracle
- 【優化】Oracle 執行計劃優化Oracle
- oracle 執行計劃設定Oracle
- 【PG執行計劃】Postgresql資料庫執行計劃統計資訊簡述SQL資料庫
- AutoTRACE是分析SQL的執行計劃,執行效率的一個非常簡單方便的工具SQL
- Oracle檢視執行計劃的命令Oracle
- Oracle訪問表的執行計劃Oracle
- Oracle獲取執行計劃的方法Oracle