三月不減肥,五月徒傷悲,這就是我現在的狀態,哈哈~ 健身、部落格堅持。
--WH
一、request請求引數出現的亂碼問題
get請求:
get請求的引數是在url後面提交過來的,也就是在請求行中,
![]()
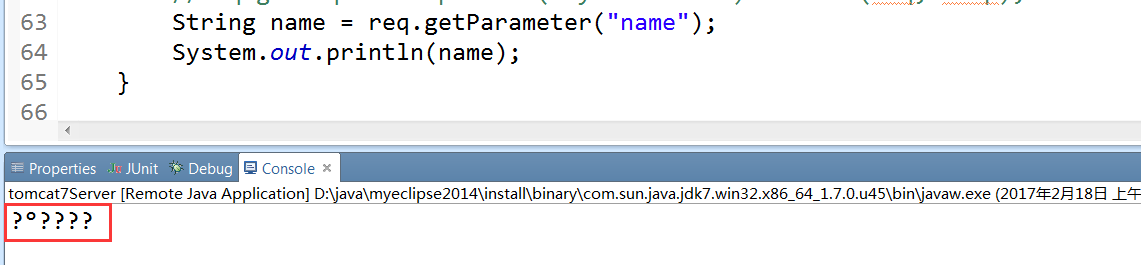
MyServlet是一個普通的Servlet,瀏覽器訪問它時,使用get請求方式提交了一個name=小明的引數值,在doGet中獲取該引數值,並且列印到控制檯,發現出現亂碼
出現亂碼的原因:
前提知識:需要了解碼錶,編碼,解碼這三個名詞的意思。我簡單說一下常規的,
碼錶:是一種規則,用來讓我們看得懂的語言轉換為電腦能夠認識的語言的一種規則,有很多中碼錶,IS0-8859-1,GBK,UTF-8,UTF-16等一系列碼錶,比如GBK,UTF-8,UTF-16都可以標識一個漢字,而如果要標識英文,就可以用IS0-8859-1等別的碼錶。
編碼:將我們看得懂的語言轉換為電腦能夠認識的語言。這個過程就是編碼的作用
解碼:將電腦認識的語言轉換為我們能看得懂得語言。這個過程就是解碼的作用
這裡只能夠代表經過一次編碼例子,有些程式中,會將一個漢字或者一個字母用不同的碼錶連續編碼幾次,那麼第一次編碼還是上面所說的作用,第二次編碼的話,就是將電腦能夠認識的語言轉換為電腦能夠認識的語言(轉換規則不同),那麼該解碼過程,就必須要經過兩次解碼,也就是編碼的逆過程,下面這個例子就很好的說明了這個問題。
瀏覽器使用的是UTF-8碼錶,通過http協議傳輸,http協議只支援IS0-8859-1,到了伺服器,預設也是使用的是IS0-8859-1的碼錶,看圖

也就是三個過程,經歷了兩次編碼,所以就需要進行兩次解碼,
1、瀏覽器將"小明"使用UTF-8碼錶進行編碼(因為小明這個是漢字,所以使用能標識中文的碼錶,這也是我們可以在瀏覽器上可以手動設定的,如果使用了不能標識中文的碼錶,那麼就將會出現亂碼,因為碼錶中找不到中文對應的計算機符號,就可能會用??等其他符號表示),編碼後得到的為 1234 ,將其通過http協議傳輸。
2、在http協議傳輸,只能用ISO-8859-1碼錶中所代表的符號,所以會將我們原先的1234再次進行一次編碼,這次使用的是ISO-8859-1,得到的為 ???? ,然後傳輸到伺服器
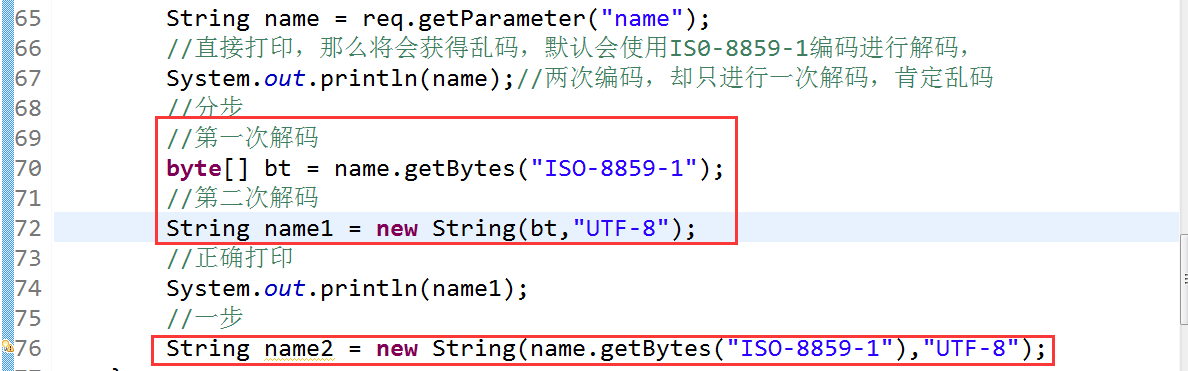
3、伺服器獲取到該資料是經過了兩次編碼後得到的資料,所以必須跟原先編碼的過程逆過來解碼,先是UTF-8編碼,然後在ISO-8859-1編碼,那麼解碼的過程,就必須是先ISO-8859-1解碼,然後在用UTF-8解碼,這樣就能夠得到正確的資料。????.getBytes("ISO-8859-1");//第一次解碼,轉換為電腦能夠識別的語言, new String(1234,"UTF-8");//第二次解碼,轉換為我們認識的語言
解決程式碼


Post請求:
post請求方式的引數是在請求體中,相對於get請求簡單很多,沒有經過http協議這一步的編碼過程,所以只需要在伺服器端,設定伺服器解碼的碼錶跟瀏覽器編碼的碼錶是一樣的就行了,在這裡瀏覽器使用的是UTF-8碼錶編碼,那麼伺服器端就設定解碼所用碼錶也為UTF-8就OK了
設定伺服器端使用UTF-8碼錶解碼
request.setCharacterEncoding("UTF-8"); //命令Tomcat使用UTF-8碼錶解碼,而不用預設的ISO-8859-1了。
所以在很多時候,在doPost方法的第一句,就是這句程式碼,防止獲取請求引數時亂碼。
總結請求引數亂碼問題
get請求和post請求方式的中文亂碼問題處理方式不同
get:請求引數在請求行中,涉及了http協議,手動解決亂碼問題,知道出現亂碼的根本原因,對症下藥,其原理就是進行兩次編碼,兩次解碼的過程
new String(xxx.getBytes("ISO-8859-1"),"UTF-8");
post:請求引數在請求體中,使用servlet API解決亂碼問題,其原理就是一次編碼一次解碼,命令tomcat使用特定的碼錶解碼。
request.setCharaterEncoding("UTF-8");
二、response響應回瀏覽器出現的中文亂碼。
首先介紹一下,response物件是如何向瀏覽器傳送資料的。兩種方法,一種getOutputStream,一種getWrite。
ServletOutputStream getOutputStream(); //獲取輸出位元組流。提供write() 和 print() 兩個輸出方法
PrintWriter getWrite(); //獲取輸出字元流 提供write() 和 print()兩個輸出方法
print()方法底層都是使用write()方法的,相當於print()方法就是將write()方法進行了封裝,使開發者更方便快捷的使用,想輸出什麼,就直接選擇合適的print()方法,而不用考慮如何轉換位元組。
1、ServeltOutputStream getOutputStream();
不能直接輸出中文,直接輸出中文會報異常,

報異常的原始碼
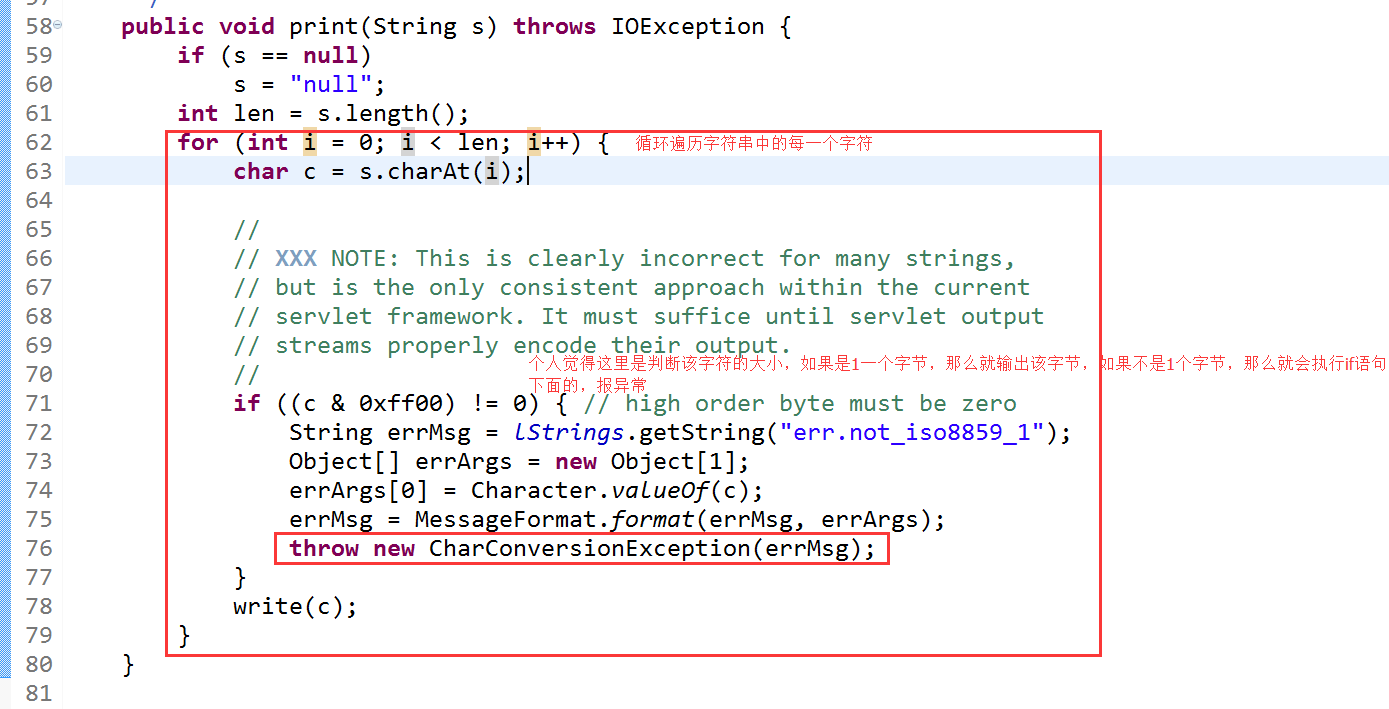
解決:
resp.getoutputStream().write("哈哈哈,我要輸出到瀏覽器".getBytes("UTF-8"));
將要輸出的漢字先用UTF-8進行編碼,而不用讓tomcat來進行編碼,這樣如果瀏覽器用的是UTF-8碼錶進行解碼的話,那麼就會正確輸出,如果瀏覽器用的不是UTF-8,那麼還是會出現亂碼,所以說這個關鍵要看瀏覽器用的什麼碼錶,這個就不太好,這裡還要注意一點,就是使用的是write(byte)方法,因為print()方法沒有輸出byte型別的方法。
2、PrintWriter getWrite();
直接輸出中文,不會報異常,但是肯定會報異常,因為用ISO-8859-1的碼錶不能標識中文,一開始就是錯的,怎麼解碼編碼讀沒用了
有三種方法來讓其正確輸出中文
1、使用Servlet API response.setCharacterEncoding()
response.setCharacterEncoding("UTF-8"); //讓tomcat將我們要響應到瀏覽器的中文用UTF-8進行編碼,而不使用預設的ISO-8859-1了,這個還是要取決於瀏覽器是不是用的UTF-8的碼錶,跟上面的一樣有缺陷

2、通知tomcat和瀏覽器都使用同一張碼錶
response.setHeader("content-type","text/html;charset=uft-8"); //手動設定響應內容,通知tomcat和瀏覽器使用utf-8來進行編碼和解碼。
charset=uft-8就相當於response.setCharacterEncoding("UTF-8");//通知tomcat使用utf-8進行編碼
response.setHeader("content-type","text/html;charset=uft-8");//合起來,就是既通知tomcat用utf-8編碼,又通知瀏覽器用UTF-8進行解碼。
response.setContentType("text/html;charset=uft-8"); //使用Servlet API 來通知tomcaat和強制瀏覽器使用UTF-8來進行編碼解碼,這個的底層程式碼就是上一行的程式碼,進行了簡單的封裝而已。
![]()
3、通知tomcat,在使用html<meta>通知瀏覽器 (html原始碼),注意:<meta>建議瀏覽器應該使用編碼,不能強制要求
進行兩步

所以response在響應時,只要通知tomcat和瀏覽器使用同一張碼錶,一般使用第二種方法,那麼就可以解決響應的亂碼問題了
三、總結
在上面講解的時候總是看起來很繁瑣,其實知道了其中的原理,很簡單,現在來總結一下,
請求亂碼
get請求:
經過了兩次編碼,所以就要兩次解碼
第一次解碼:xxx.getBytes("ISO-8859-1");得到yyy
第二次解碼:new String(yyy,"utf-8");
連續寫:new String(xxx.getBytes("ISO-8859-1"),"UTF-8");
post請求:
只經過一次編碼,所以也就只要一次解碼,使用Servlet API request.setCharacterEncoding();
request.setCharacterEncoding("UTF-8"); //不一定解決,取決於瀏覽器是用什麼碼錶來編碼,瀏覽器用UTF-8,那麼這裡就寫UTF-8。
響應亂碼
getOutputStream();
使用該位元組輸出流,不能直接輸出中文,會出異常,要想輸出中文,解決方法如下
解決:getOutputStream().write(xxx.getBytes("UTF-8")); //手動將中文用UTF-8碼錶編碼,變成位元組傳輸,變成位元組後,就不會報異常,並且tomcat也不會在編碼,因為已經編碼過了,所以到瀏覽器後,如果瀏覽器使用的是UTF-8碼錶解碼,那麼就不會出現中文亂碼,反之則出現中文亂碼,所以這個方法,不能完全保證中文不亂碼
getWrite();
使用字元輸出流,能直接輸出中文,不會出異常,但是會出現亂碼。能用三種方法解決,一直使用第二種方法
解決:通知tomcat和瀏覽器使用同一張碼錶。
response.setContentType("text/html;charset=utf-8"); //通知瀏覽器使用UTF-8解碼
通知tomcat和瀏覽器使用UTF-8編碼和解碼。這個方法的底層原理是這句話:response.setHeader("contentType","text/html;charset=utf-8");
注意:getOutputStream()和getWrite() 這兩個方法不能夠同時使用,一次只能使用一個,否則報異常