序言
這算是hibernate的最後一篇文章了,下一系列會講解Struts2的東西,然後說完Struts2,在到Spring,然後在寫一個SSH如何整合的案例。之後就會在去講SSM,在之後我自己的個人部落格應該也差不多可以做出來了。基本上先這樣定下來,開始完成hibernate的東西把。這章結束後,我會將我一些hibernate的資料奉上,供大家一起學習。
---WH
一、概述
這章總的分兩大塊來講解,
第一大塊,hibernate的事務管理。,對於hibernate的事務管理來說,如果之前學過資料庫的事務管理,那麼在這裡就順風順水了。如果沒學過,第一次遇到,那也沒關係,我會詳細解釋其中的內容。
第二大塊,hibernate的二級快取機制。這個看起來好高大上啊,如果從來沒了解過二級快取的人肯定覺得他很難,但是學過會發現,真的是so easy。最起碼會知道什麼是二級快取,作用是什麼。
二、hibernate的事務管理
2.1、回顧資料庫的事務的特性和隔離級別
2.1.1、什麼是事務?
事務是一組業務邏輯,比如A去銀行給B轉錢,A轉了100塊給B(update語句更新A的錢減少一百),B收到錢(update語句更新B的錢增加一百),這轉錢整個過程稱為事務,注意,不要覺得A轉錢給B,A做完了操作,就是事務了,要記住事務是一組業務邏輯,兩個在一起才是事務。在比如有一個數字5,現在有一個事務A,事務A做的事情就是將5變為4,該事務要做的事情有,拿到5,然後5-1,然後資料庫中的5變為了4,這才算這個事務A真正的成功了,可以那麼說,業務邏輯太抽象了,事務就是一組操作,只有整個操作在一起才算是一個事務。就向上面說的,轉錢也是一個事務,它做的操作就只有兩個,A減少錢,B增加錢。
2.1.2、事務的特性ACID
A(atomicity):原子性:事務不可被劃分,是一個整體,要麼一起成功,要麼一起失敗
C(consistence):一致性,A轉100給B,A減少了100,那麼B就要增加100,增加減少100就是一致的意思
I(isolation):隔離性,多個事務對同一內容的併發操作。
D(durability):永續性,已經提交的事務,就已經儲存到資料庫中,不能在改變了。
2.1.3、事務隔離性產生的問題
跟執行緒安全差不多,多個事務對同一內容同時進行操作,那麼就會出現一系列的併發問題。一定要注意,這個是兩個或者多個事務同時對一個內容進行操作,是同時,而不是先事務A操作完,然後事務B在操作,這個要理解清楚。
2.1.3.1、髒讀:一個事務 讀到 另一個事務 沒有提交的資料。
A給B轉100塊錢(事務A),A在ATM機上轉,將100塊錢放到ATM機裡了,然後ATM機會最後詢問A,確定轉賬100給B嗎,A還沒點確定這個時候,B在另外一個ATM機上就發現賬戶上多了100塊錢,然後高興的取走了這100塊錢,B取錢(事務B)但是此時A覺得不行,覺得還是拿現金給B比較好,然後就點了取消,把放到ATM機中的100塊錢給拿了回來。這其中,A轉錢給B(事務A)、B取錢(事務B),也就發生了事務B讀到了事務A沒有提交的資料,也就是髒讀。注意:要明白事務是什麼,才能理解這些東西。還有,剛開始接觸可能會覺得這是不可能發生的呀,怎麼會讀到還沒有提交的資料呢?這裡只是說明這個是一個問題,現實生活中肯定沒有呀,銀行也不會出現這種問題,因為已經全部解決掉了,但是這種問題肯定是存在的,該如何解決呢?這就是我們後面需要討論的東西。現在只需要知道事務隔離會產生這種問題就行了。
2.1.3.2、不可重複讀:一個事務 讀到 另一個事務 已經提交的資料(update更新語句)
解釋:有時候不可重複讀是一個問題,有時候卻不是。這要看業務需求是怎麼樣的,就好比銀行轉錢的事情,事務A(A給B轉錢),事務B(B取錢),A在ATM機上插卡轉錢給B,同時B也將銀行卡插入ATM機中準備檢視A是否轉了錢給B,當A事務結束後,也就是A轉賬成功後,B就查到了自己賬戶上多了100塊錢,這就是事務B讀到了事務A已經提交的資料。這個例子不可重複讀就不是個問題。此業務邏輯中,就不需要解決這個問題。在別的業務中,可能這個就是個問題了。比如,一個公司,每個月15號給員工結算工資,工資數是從上個月15號到這個月15號根據每個人提交的工作量來結算的,但是會計師A在這個月15號從資料庫中拿每個員工的工作記錄量的資料做工資的統計的同時,員工B在次提交了一次工作量(將資料庫中B的工作量增加了),此時會計師A在結算員工B的工資時,就會把前面30天的工作量和他今天提交的工作量一起算工資,到了下個月15號,又會把員工B這次提交的工作量算在它當前月的總工作量中,這樣一來,就相當於給B多算了一次工作量的工資。這樣就不合理了。
2.1.3.4、虛度(幻讀):一個事務 讀到 另一個事務 已經提交的資料(insert插入語句)
這個跟不可重複讀描述的問題是一樣的,但是其針對的事務不一樣,不可重複讀針對的是做更新的事務,比如轉錢呀等,都是做更新的事務,而這個虛讀針對的是做插入的事務,比如,在工地有很多人做事,工地有規定,做了事的中午才包飯,到了中午的時候,工地負責人要去給做事的工人買盒飯,就要統計人數,現在工地也會用電腦了,負責人就到電腦上查有多少人做事,來決定買多少盒飯,就在查人數的時候,另一個專門招工人的負責人招到一個工人,就把該工人的資訊輸入到資料庫裡面,然後買盒飯的負責人在電腦上一查資料庫,發現有N個人,剛招進來的工人也在其中,然後就也給那個沒做事的,剛招進來的員工買了盒飯,這是不符合規定的。這只是舉一個這樣的例子,幫助大家理解,一個盒飯也不貴,覺得無所謂,但是如果是涉及很重要的東西時,就不能出現這種問題。
2.1.4、事務隔離級別,用於解決隔離問題
2.1.4.1、read uncommitted :讀未提交,一個事務 讀到 另一個事務 沒有提交的資料,存在問題3個,解決0個問題
2.1.4.2、read committed:讀已提交,一個事務 讀到 另一個事務 已經提交的資料,存在問題2個,解決1個問題(髒讀問題)
2.1.4.3、repeatable read:可重複讀,一個事務 讀到重複的資料,即使另一個事務已經提交。存在問題1個,解決2個問題(髒讀、不可重複讀)
2.1.4.4、serializable:單事務,同時只有一個事務可以操作,另一個事務掛起(暫停),存在問題0個,解決3個問題(髒讀、不可重複讀、虛讀)
注意:一定要搞清楚上面三個問題(髒讀、不可重複讀、幻讀)是什麼樣的情況,你才能知道這四種隔離級別為什麼能夠解決這些問題。切記,如果看我的話還是覺得這幾個問題模糊不清,就請留言告訴我你的疑問,因為如果不明白這三個問題,那麼後面你將一直會混淆。
2.1.5、使用MySQL來進行隔離級別的演示
這裡就不寫程式碼了,直接上文字,讓你們熟悉一下事務隔離級別的使用。
順便說一句,MySQL預設的隔離級別:repeatable read Oracle預設的隔離級別:read committed
MySQL預設事務提交的,也就是在cmd中每執行一條sql語句就是一個事務,所以如果你要進行實驗就必須先關閉MySQL的自動事務提交,並改為手動,set autocommit=0
2.1.5.1、read uncommitted
A隔離級別:讀未提交,會發生髒讀問題
AB同時開始事務,
A先查詢 --正常資料
B更新,但未提交
A在查詢 --讀到B沒有提交的資料
B回滾 --B沒有提交資料,回滾的話,就相當於剛才的更新語句並沒有執行
A再查詢 --讀到回滾後的資料,也就是原來的正常資料。
2.1.5.2、read committed
A隔離級別:讀已提交
AB同時開啟事務
A 先查詢 --正常
B 更新,但未提交
A再查詢 --得到的還是之前的資料,並沒有拿到B沒有提交的資料, 解決問題:髒讀
B 提交
A 再查詢 -- 已經提交的資料。問題:不可重複讀(到這裡就不要在糾結為什麼不可重複讀是個問題了,上面已經解釋清楚了,根據不同的業務,可能是問題,也可能不是)
2.1.5.3、repeatable read
A隔離界別:可重複讀,保證當前事務中讀到的是重複的資料
AB 同時開啟事務
A 先查詢 --正常
B 更新,但未提交
A 再查詢 -- 之前資料,解決:髒讀
B 提交
A 再查詢 -- 之前資料,解決:不可重複讀
A 回滾|提交
A 再查詢 -- 更新後資料,新事務獲得最新資料
2.1.5.3、serializable
A隔離級別:序列化,單事務
AB 同時開啟事務
A 先查詢 --正常
B 更新 -- 等待 (對方事務A結束或者超時B才能進行。)
2.1.6、丟失更新問題 lost update
這個丟失更新問題也是屬於事物隔離性產生的問題之一,但是不同上面所說的三個,上面所說的髒讀、不可重複讀、虛讀,都是一個事務 拿到了 另一個事務所提交或者未提交的資料而產生的問題,而丟失更新並不拿對方事務所提交的資料,那丟失更新描述的是一個什麼樣的問題呢?
A 查詢資料,username = 'jack' ,password = '1234'
B 查詢資料,username="jack", password="1234'
A更新密碼,使用者名稱不變 username='jack',password='456' //A將密碼更新完後,將其儲存到資料庫中了
B更新使用者名稱,username='rose',password='1234' //B更新之後,資料庫中的資料就為 username='rose',password='1234'
丟失更新:最後更新資料,將前面更新的資料給覆蓋了。那A之後就發現自己剛設定的密碼登入不上了,這就出現了丟失更新問題,解決的方法有兩種
解決方法一:
樂觀鎖
認為丟失更新一定不會發生,非常樂觀,在資料庫表中新增一個欄位,可以說是標識欄位把,用於記錄操作次數的,比如如果對有人拿到了該行記錄做了更新操作,該欄位就加1。然後下一個拿到該記錄的人要先將拿到的記錄的標識和資料庫中該記錄的標識做對比,如果一樣,則可以修改,並且修改後標識(版本)+1,如果不一樣,先從資料庫中查詢,然後在做更新。舉個例子
A 查詢資料,username = 'jack' ,password = '1234',version=1
B 查詢資料,username="jack", password="1234',version=1 //AB同時拿到資料庫中資料,且version讀為1
A更新密碼,使用者名稱不變 username='jack',password='456',version=2 //先和資料庫中該行記錄的version做對比,拿到的version是1,跟資料庫中一樣,所以能做更新,A將密碼更新,version+1,然後將其儲存到資料庫中(注意,這裡寫的是A更新之後的的資料。 不要搞混了。)
B更新使用者名稱,username='rose',password='1234',version=1 //B想要更新時,先和資料庫中該條記錄的版本號做對比,發現不一樣,然後查詢
B重新查詢資料, 使用者名稱不變 username='jack',password='456',version=2 //然後在進行對比,這次version一樣了,B就可以實現更新操作了。
B更新使用者名稱,username='rose',password='456',version=3 //更新後,version+1
解決方法二:
悲觀鎖
認為丟失更新一定會發生,此時採用資料庫鎖機制,也就是相當於誰操作了該記錄行,就會在上面加把鎖,別人進不去,只有等你操作完之後,該鎖就釋放,別人就可以操作了。跟那個隔離級別單事務差不多。但是鎖也分很多種。
讀鎖:共享鎖,大家可以一起讀資料,但是不能一起操作(更新,刪除,插入等)
寫鎖:排他鎖,只能一個進行寫,也就是上面我們說的原理。
2.2、hibernate中對事務產生的隔離性問題以及解決方案
上面通過很大的篇幅講解資料庫的事務相關問題,就是為了講解hibernate中的事務做鋪墊,懂了上面這些,那麼這裡就順風順水了。
2.2.1、hibernate中設定事務隔離級別,隔離級別是為了解決事務隔離性產生的問題的。
在hiberante.cfg.xml檔案中配置 hibernate.connection.isolation 隔離級別
有四種隔離級別可選擇,後面的數字表示在設定隔離級別的時候,直接寫數字也是可以代表對應的隔離級別的,比如 hibernate.connection.isolation 4 跟hibernate.connection.isolation Repeatable read 是一樣的。
Read uncommoitted isolation 1
Read committed isolation 2
Repeatable read isolation 4
Serializable isolation 8

2.2.2、hibernate中丟失更新問題的解決
悲觀鎖: 就是認為一定會發生丟失更新問題,採取鎖機制
User user = (User) session.load(User.class,1,LockMode.UPGRADE);
樂觀鎖:
hibernate 為Customer表 新增版本欄位
1) 在User類 新增 private Integer version; 版本欄位
2) 在User.hbm.xml 定義版本欄位
<!-- 定義版本欄位 -->
<!-- name是屬性名 -->
<version name="version"></version>

如果產生了丟失更新就會報異常
![]()
總結:
1、如果知道了資料庫中事務的知識,那麼在hibernate中就非常簡單,只是簡單的配置一下就OK了。所以在hibernate的事務講解這裡篇幅就比較少,重要的還是需要弄懂前面的知識。很重要。
三、hibernate的二級快取
說點廢話,二級快取理解起來真的非常非常簡單,大家不要覺得怕,就三個內容,知道什麼是二級快取,如何使用它,就沒了。
3.1、什麼是二級快取
我們知道一級快取,並且一級快取的作用範圍就在session中,每個session都有一個自己的一級快取,而二級快取也就是比一級快取的作用範圍更廣,儲存的內容更多,我們知道session是由sesssionFactory建立出來的,一個sessionFactory能夠建立很多個session,每個session有自己的快取,稱為一級快取,而sessionFactory也有自己的快取,存放的內容供所有session共享,也就是二級快取。 是不是很簡單?還不理解看下面我畫的一張圖就一目瞭然了。

一級快取:儲存session中,事務範圍的快取(通俗點講,就是session關閉後,該快取就沒了,其快取只能在session的事務開啟和結束之間使用)
二級快取,儲存在SessionFactory,程式範圍內的快取(程式包括了多個執行緒,也就是我們上面說的意思,A執行緒可能拿到一個session進行操作,B執行緒也可能拿到一個session進行操作,但是A和B讀能訪問到SessionFactory中的快取,也就是二級快取,這裡只是拿A,B說事,可能有一個執行緒剛建立出來session,也能拿到二級快取中的資料)
3.2、二級快取的作用?優點
這個可能要到實際開發工作中才會知道二級快取有哪些用處,現在給出一些我認為比較好的答案,因為我還沒真正到去工作,所以目前也只是理解其內容。
。。。。
3.3、二級快取的內部結構
類快取區域
比如:session.get(Customer.class,1); //這就是類快取區域
集合快取區域
customer.getOrders(); //就是存放Orders集合的內容的快取區域就叫集合快取區域
更新時間戳區域
查詢快取區域
這幾個在後面會詳細講到,現在不講,想直接看的就跳過看後面測試例項。
3.4、二級快取的併發訪問策略配置。
為什麼要講解這個呢?想一下,二級快取是sessionFactory中的,其sessionFactory建立出來的session都可以共享它,所以其中就會出現併發問題,也就是我們一開始講的一些事務隔離性問題。為了解決這些問題,hibernate也提供了相應的方法,就是二級快取的併發訪問策略,總共有四種,通過一張表格來看把,通過下面這張圖,我們應該就知道了其實跟開始講的差不多,換了一個名詞而已。並且如果要使用二級快取,就必須配置這個病房訪問策略,不然是用不了二級快取的,就好比你已經有了二級快取,其中也有內容,但是你沒有設定訪問方式,就訪問不出來。
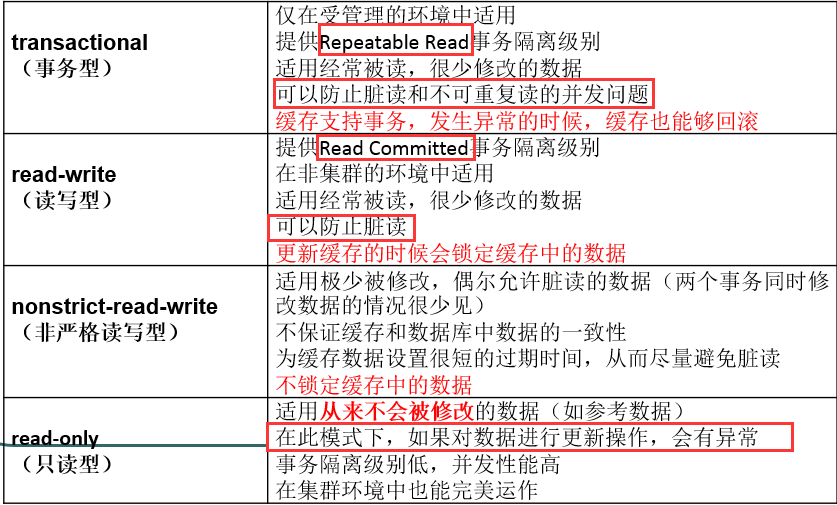
在配置二級快取之後,就要相應的配上其二級快取併發訪問策略。
3.5、如何配置二級快取?
分兩大步,第一步單純配置二級快取,第二步配置二級快取的併發訪問策略。第三步,配置ehcache.xml
3.5.1、配置二級快取
要使用二級快取,需要匯入其它的元件來幫我們完成,而hibernate本身是有一個預設的二級快取元件,但是平常我們不用,一般是用EhCacheProvider,來了解一下hibernate所能支援的二級快取元件提供商

1、我們使用Ehcache,所以匯入其jar包

2、在hibernate.cfg.xml檔案中配置,開啟二級快取,
![]()
3、在hibernate.cfg.xml檔案中配置二級快取提供商
![]()
開啟二級快取就只需要三步,就上面三步,然後開始配置我們的併發訪問策略。
3.5.2、配置二級快取的併發訪問策略
二級快取元件所能支援的併發訪問策略。 為什麼
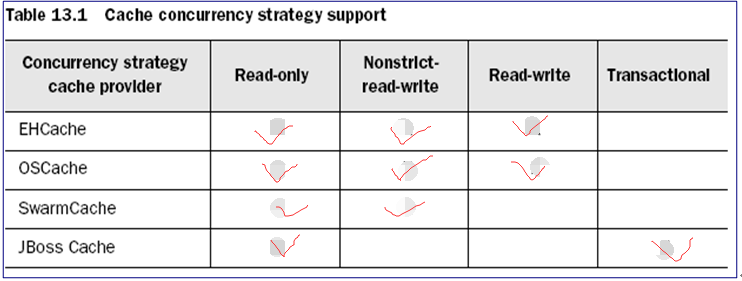
今天我們要用的就是EHCache,它不支援Transactional這種併發訪問策略,所以我們使用的是read-write這種併發訪問策略,read-write提供的就是read committed事務隔離級別,能夠防止髒讀,具體的功能就看上面的表格。
配置方案有兩種
1、xxx.hbm.xml檔案中配置
可以在<class>標籤下配置<cache usage=”read-write”> 類級別
可以在<set>標籤下配置<cache usage=”read-write”> 集合級別
2、hibernate.cfg.xml檔案中配置

3.5.3、配置ehcache.xml檔案
將 ehcache-1.5.0 jar包中 ehcache-failsafe.xml 改名 ehcache.xml 放入 src。 這非常簡單。如果使用的別的元件快取,則在相同位置也有類似的檔案。
3.6、測試二級快取的存在
3.6.1、搭建測試環境
並且將上面的步驟自己搭建好,三步走,注意:使用的業務邏輯是Dept-Staff,也就是部門和職工的關係。
1、配置二級快取,也就是將一些元件快取提供商弄好

2、配置併發訪問策略,這裡其實就自由配置了,如果你想在二級快取中只存取某個類的值,那麼就在xxx.hbm.xml中配置一下其訪問策略
這裡,我先只對dept進行read-write的訪問策略,然後等會進行測試

3、新增ehcache.xml
3.6.2、測試二級快取是否存在

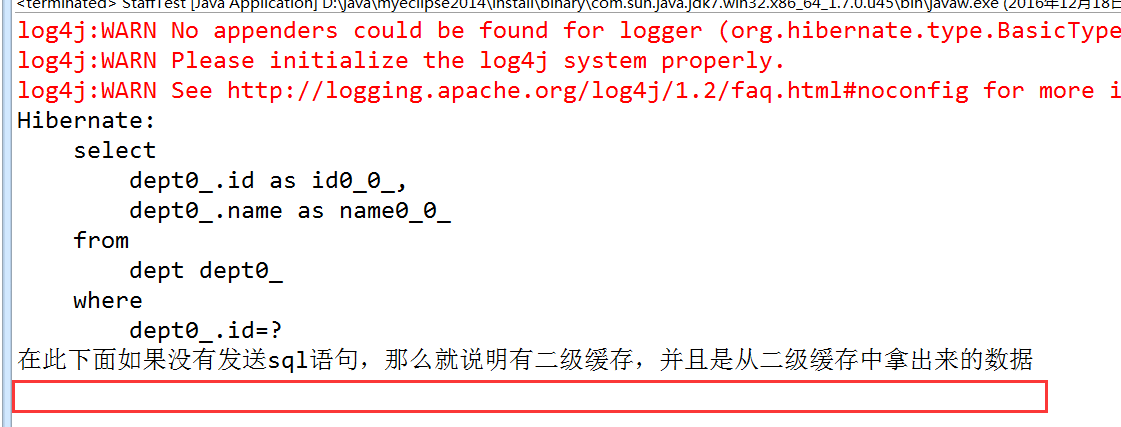
3.6.3、注意get/load可以從二級快取中獲取資料,而query的list不能從二級快取獲取資料,但是其查詢結果會存入二級快取。
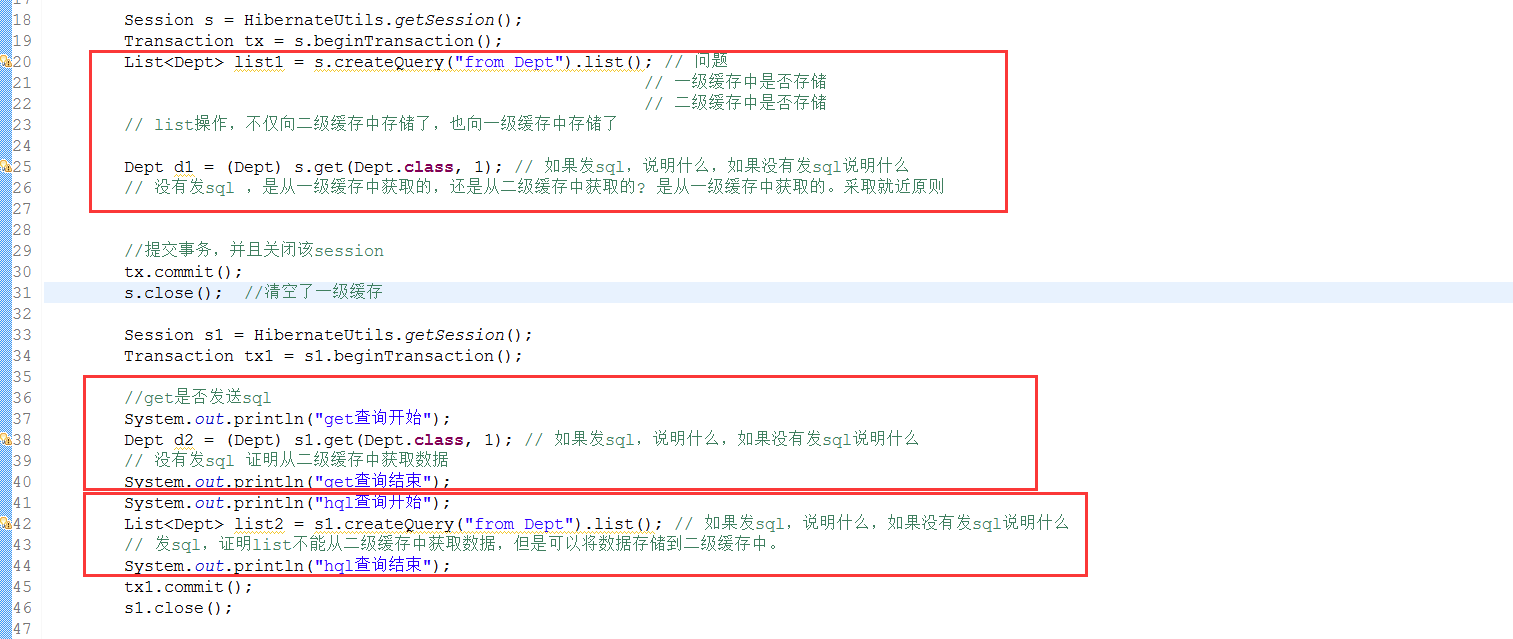

小結:
hql做的查詢能夠存入一級快取和二級快取,但是不能夠從二級快取中拿資料
get\load能夠將其查詢資料插入一級快取和二級快取,也能夠從一級二級快取中拿資料。
3.6.4、一級快取資料會同步二級快取
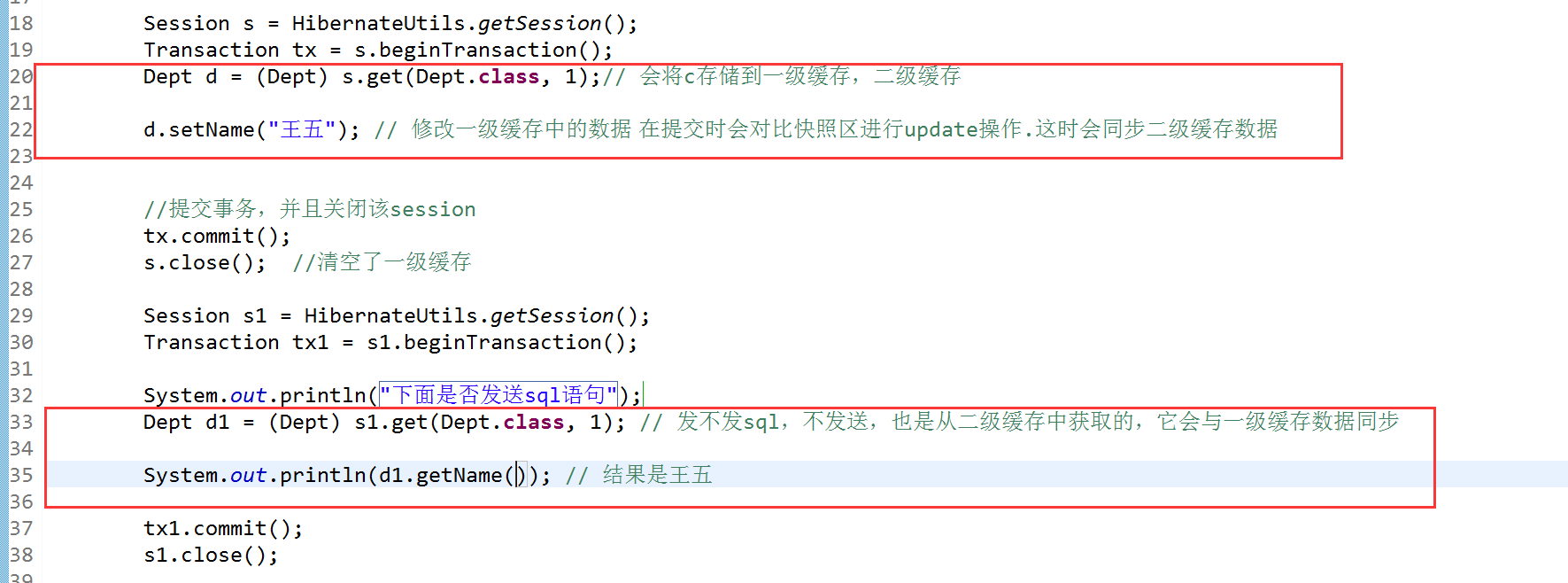

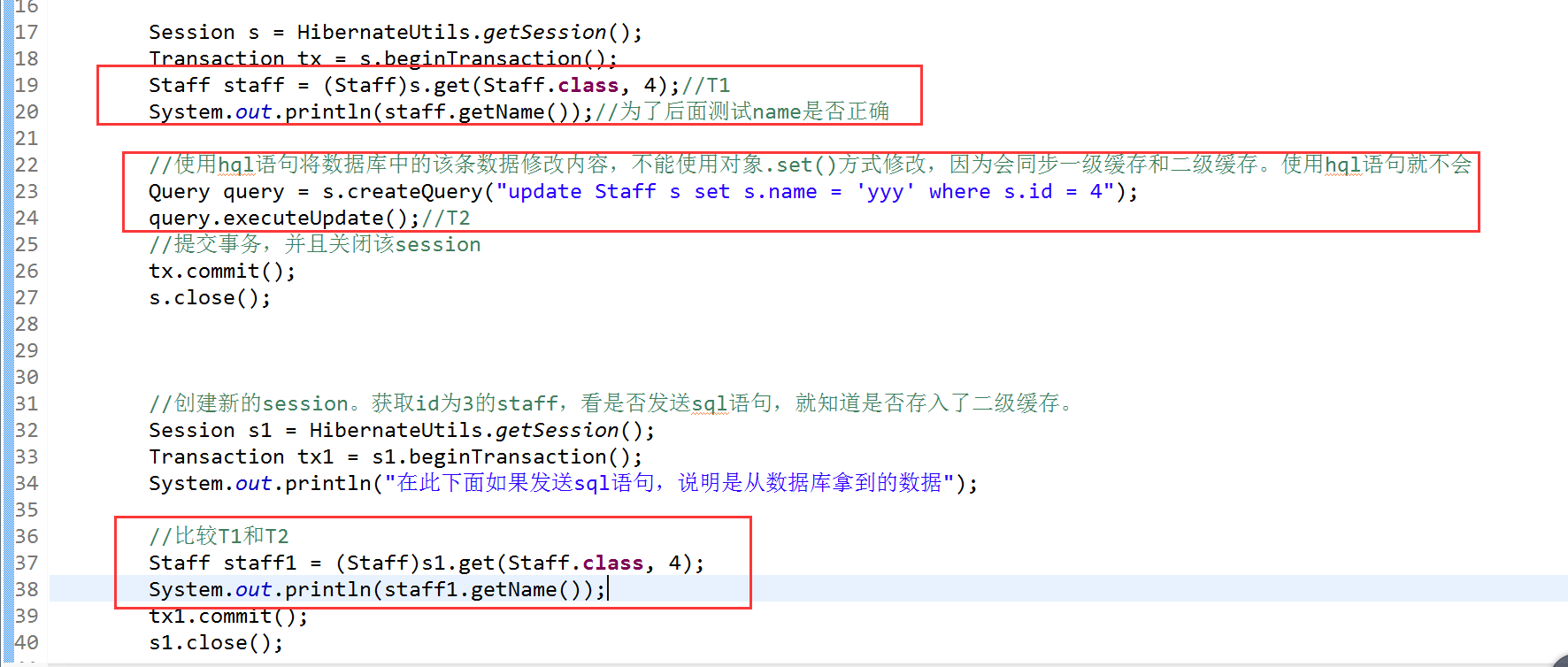
注意:如果是用hql來更新修改name,那麼就不會同步二級快取,連一級快取中的資料也不會改變,hql是直接針對資料庫來進行修改的,而set()方法是通過hibernate中的快照區,而不是直接對資料庫進行操作。
3.6.5、測試二級快取中的四種快取區域
3.6.5.1、類快取區域
類快取區域,通過id查詢到的物件,就將其放入類快取區域,其區域中快取的都是PO物件,而不是單獨的一些屬性,值,而是完整的物件,比如上面測試是否有二級快取,就是將id為2的dept物件存入二級快取中,而不是就存dept的name,或者是id,如果只存dept的name,或者別的欄位屬性,那麼就會放入查詢快取中,而不是放入類快取區域。
3.6.5.2、集合快取區域
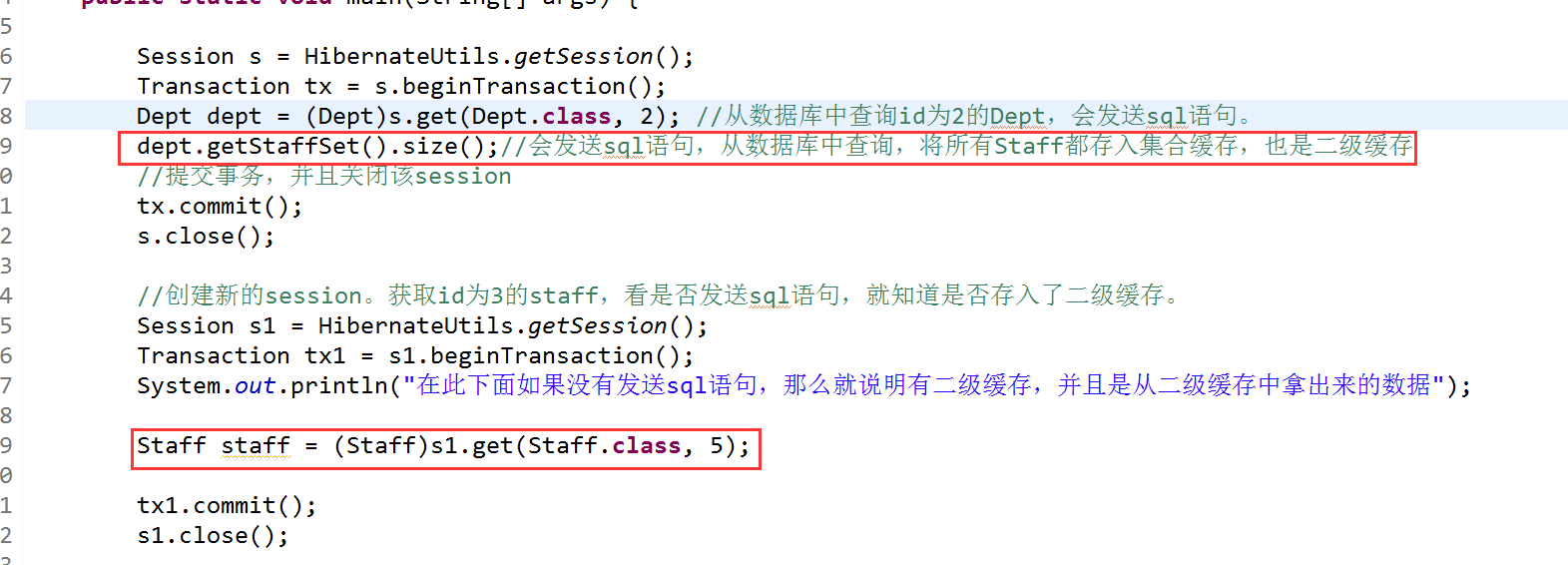
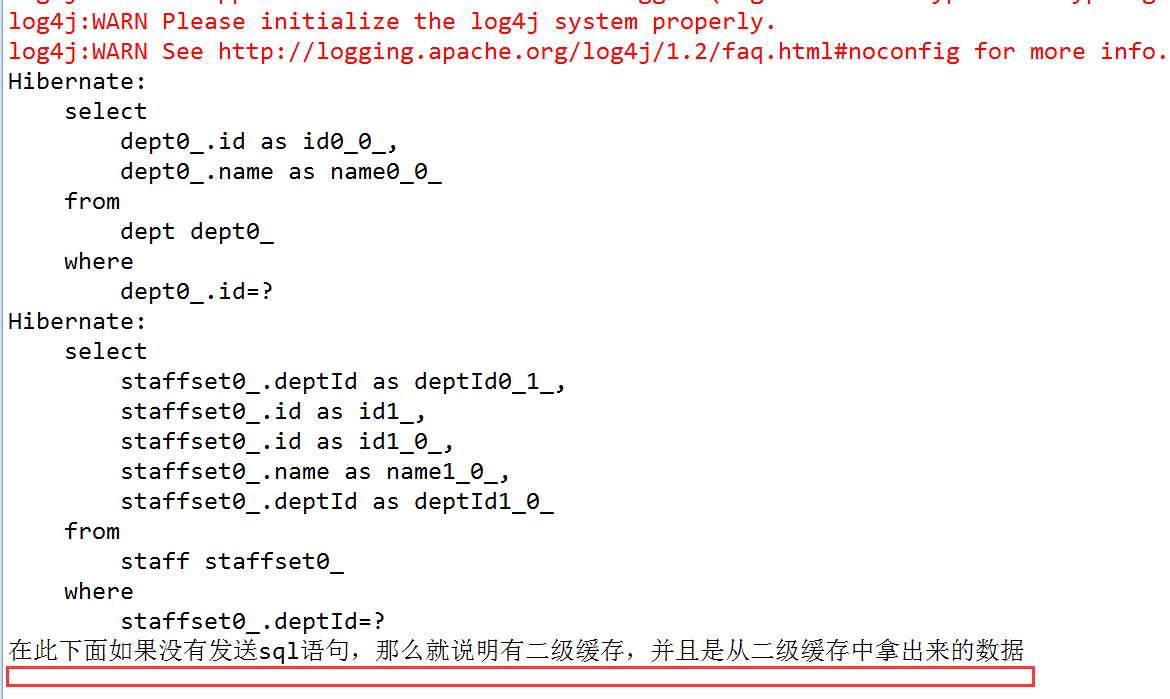
記得以前說的集合級聯關係嗎,其實這個也一樣,比如這個Dept-Staff的例子中,dept.getStaffSet(); 這查詢出來的就將其放入集合快取區域,其區域內也全部是PO物件。
設定二級快取的訪問策略,由於要測試集合快取,那麼其set中就要設定訪問策略,並且注意一點,集合級別的快取依賴於類級別的快取,也就是說,set中設定cache還不夠,因為要快取staff,所以必須將staff.hbm.xml也設定訪問策略。同時我們只是測試集合快取,那麼對查詢出來的Dept可以不設定訪問策略了,有沒有他讀沒關係,因為我們不需要用。也就是下圖中第一個用紅框框起來的,

staff.hbm.xml

測試從dept獲取到的staff是否能夠存入二級快取中。
3.6.5.3、時間戳快取區域
存放了對於查詢結果相關的表進行插入,更新,刪除操作的時間戳,Hibernate通過時間戳快取區域來判斷被快取的查詢結果是否過期,如果過期了則從資料庫中拿資料,沒過期則直接從快取中拿資料。通俗點講,就三步
1、查詢結果放到二級快取中,此時記錄一個時間為T1
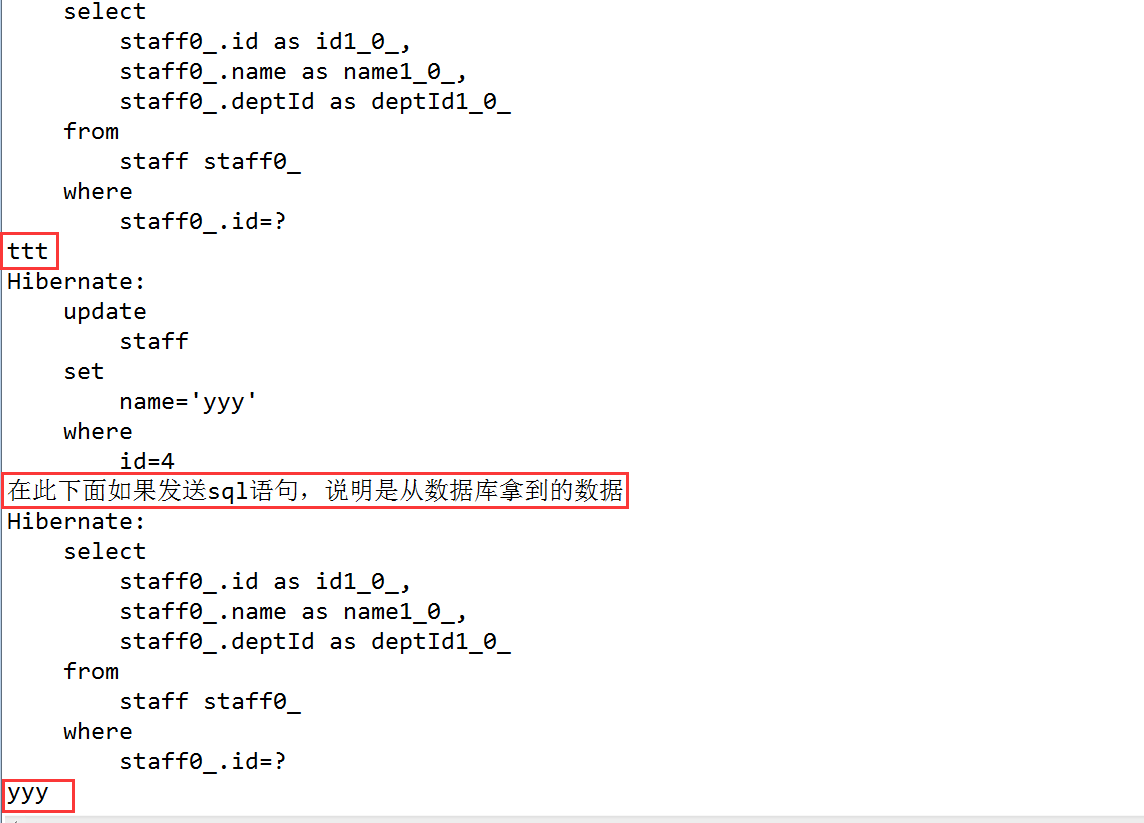
2、當有操作直接更改了資料庫的資料時,比如使用hql語句,就會直接對資料庫進行修改,而不會改變快取中的資料。此時記錄時間為T2
3、當下次在查詢記錄時,會先將T1和T2進行比較,如果T2>T1,則說明快取中的資料不是最新的,那麼就從資料庫中拿出正確的資料,如果T2<T1,就說明沒有對資料庫進行過什麼修改操作,那麼就可以直接從快取中獲取資料。
解惑:如果沒有T1和T2的比較,那麼會出現我們查詢到的資料不是準確的,因為就像上面第二步所說的,資料庫的資料會和快取中的資料不一樣,什麼讀不做就從快取中拿資料,就會出現錯誤。
測試:
3.6.5.4、查詢快取區域
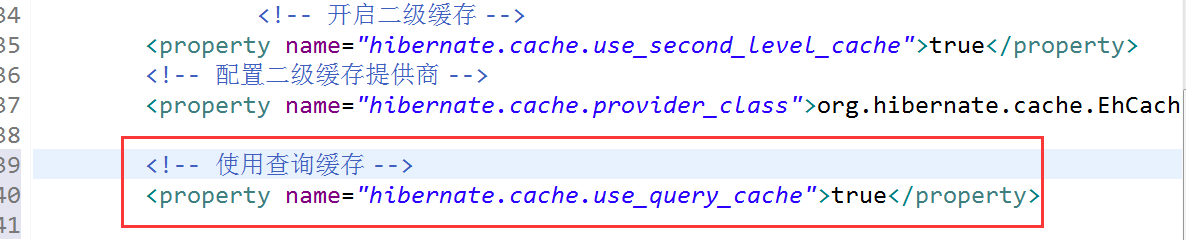
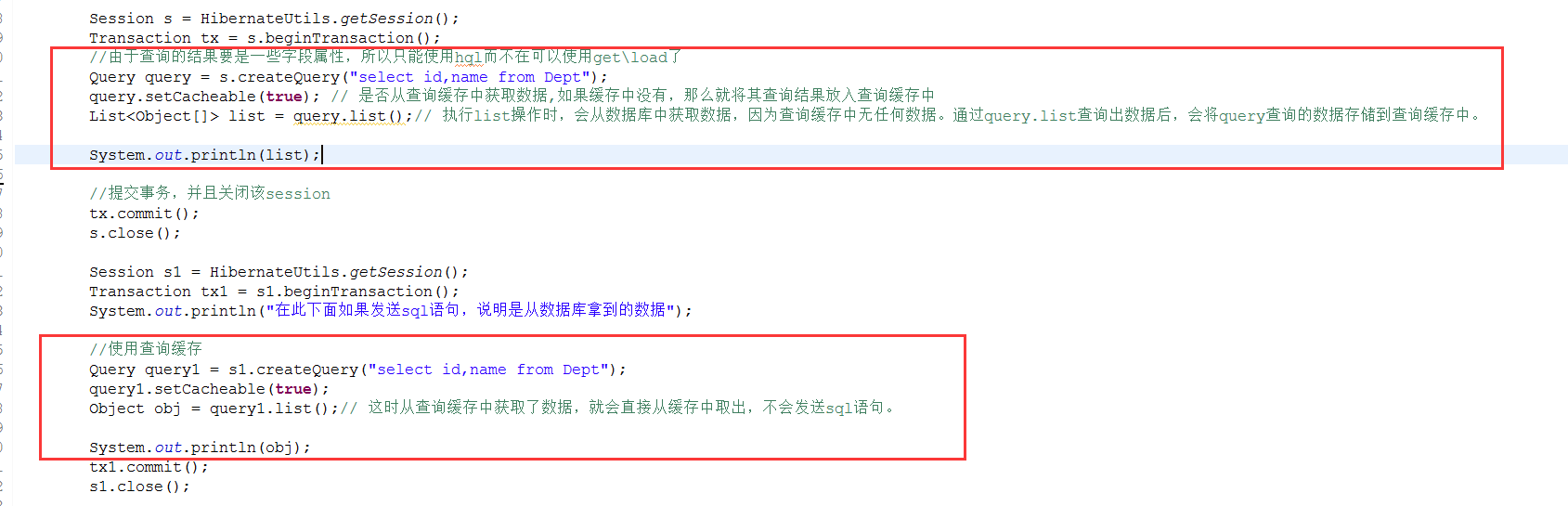
這個在將類快取區域差不多已經解釋過了,就是通過查詢的結果不是一個po物件,而是一些零散的欄位屬性,那麼就存入該區域,但是使用它是需要兩個東西
1、在hibernate.cfg.xml檔案中配置

2、在使用query操作時,需要指定是否從查詢快取中獲取資料

測試:

以上寫的訪問策略全是使用的xxx.hbm.xml來配置,現在我將上面例子的使用hibernate.cfg.xml來配置訪問策略的程式碼寫一下。

上圖說了兩個快取區域,時間戳快取區域不用設定,而查詢快取區域就通過別的方式去設定了。 這就是我們所要講解的四個快取區域。很簡單把。
四、總結
這篇文章本該早寫完的,但是中途因為一些事情而耽誤了,今天上午終於將它完結了。hiberante我覺得差不多就這些東西了。 希望對大家有所幫助