序言
寫這篇文章之前,自己也查了很多的資料來搞清楚這兩者的關係和各自所做的事情,但是百度一搜,大多數博文感覺說的雲裡霧裡,可能博主自己清楚是怎麼一回事,但是給一個不懂的人或者一知半解的人看的話,別人也看不懂其中的關係,所以我自己寫博文的時候,會盡量用通俗通俗在通俗的語言去描述一個概念,希望能儘自己的力量去幫助你們理解。光看我的是不行的,最關鍵的是要自己動手去實踐一遍,能得出一樣的結論,那就說明懂了,在我不懂的時候,我就去自己實現它,一次次嘗試,慢慢的就總結出規律了。
--WH
一、外來鍵
我為什麼要把這個單獨拿出來說呢?因為昨天我才發現我自己對這個外來鍵的概念原來理解偏差了,並且很多人估計和我一樣,對這個東西理解錯了,現在就來說說一個什麼誤區。
1、這張表的外來鍵是deptId把? 2、這張表有外來鍵嗎?
大多數人這裡說的外來鍵,度是指的一張表中被外來鍵約束的欄位名稱。這是很多人從一開始就預設的,其實並不然,
解釋:對於每張有外來鍵約束這個約束關係的表,都會給這個外來鍵約束關係取一個名字,從給表設定外來鍵約束的語句中就可以得知。
CONSTRAINT 外來鍵名 FOREIGN KEY 被外來鍵約束脩飾的欄位名 REFERENCES 父表名(主鍵)
所以說,平常大多數人口中的外來鍵,指的是被外來鍵約束脩飾的欄位名,外來鍵關係是有自己的名稱的。這點大家需要搞清楚,雖然平常影響不大,但是到真正關鍵的地方,自己可能就會被這種小知識點給弄蒙圈。
二、cascade(級聯)關係
為什麼要把這個單獨拿出來講一篇文章呢?因為我在看別人博文時,就把cascade和inverse和那幾種關聯關係連在一起講了,並且是那種一筆帶過的描述,寫的比較簡單,其實理解了確實很簡單,但對於剛開始學的人來說,這將會是一個大的災難,一知半解是最難受的了。
解釋:級聯,就是對一個物件進行操作的時候,會把他相關聯的物件也一併進行相應的操作,相關聯的物件意思是指 比如前兩節學的一對多關係中,班級跟學生,Student的實體類中,存在著Classes物件的引用變數,如果儲存Classes物件的引用變數有值的話,則該值就是相關聯的物件,並且在對student進行save時,如果儲存Classes物件的引用變數有值,那麼就會將Classes物件也進行save操作, 這個就是級聯的作用。
說大白話這個意思很難到位,舉個員工和部門 雙向一對多的例子把。
建立實驗環境(這個可以自己去實現一下,練習一下關聯關係的配置)
首先得對這兩個表的關係圖弄清楚,在接下來的所有分析中,度要帶著這個關係去分析,你才不會蒙圈
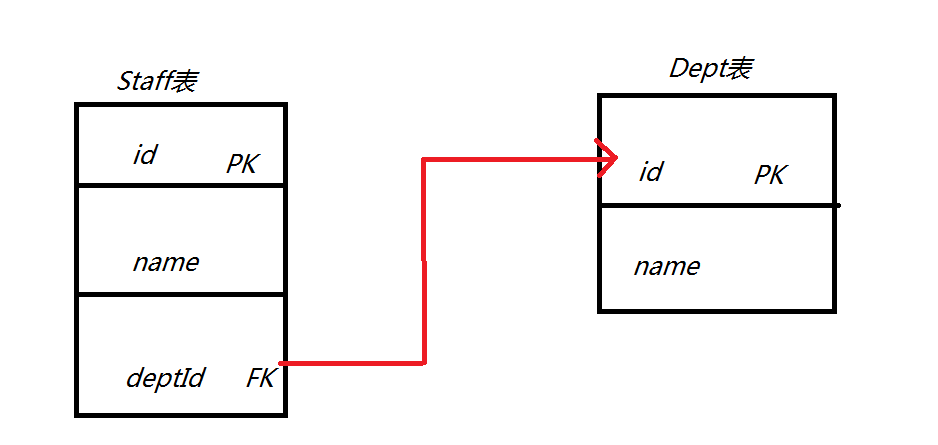
Staff.java 和 Staff.hbm.xml
public class Staff { private int id; private String name; private Dept dept; 。。。 } //Staff.hbm.xml <hibernate-mapping> <class name="oneToMany.Staff" table="staff"> <id name="id" column="id">
//設定的increment,這個應該看得懂, <generator class="increment"></generator> </id> <property name="name"></property> //name:staff實體類中的dept屬性,column:子表中被外來鍵約束脩飾的欄位名 class:Staff相關聯的Dept類 <many-to-one name="dept" column="deptId" class="oneToMany.Dept"></many-to-one> </class> </hibernate-mapping>
Dept.java 和 Dept.hbm.xml
public class Dept { private int id; private String name; private Set<Staff> staffSet = new HashSet<Staff>(); 。。。 } //Dept.hbm.xml <hibernate-mapping> <class name="oneToMany.Dept" table="dept"> <id name="id" column="id"> <generator class="increment"></generator> </id> <property name="name"></property> //key:子表被外來鍵約束脩飾的欄位名 <set name="staffSet"> <key column="deptId"></key> <one-to-many class="oneToMany.Staff"/> </set> </class> </hibernate-mapping>
配置了一個雙向一對多的關聯關係
測試類
//建立新部門
Dept dept = new Dept(); dept.setName("er部門");
//建立新的職員 Staff staff = new Staff(); staff.setName("www");
//給職員中新增部門 staff.setDept(dept);
//給部門中新增職員 dept.getStaffSet().add(staff);
//儲存部門 session.save(dept);
//儲存員工 session.save(staff);
結果 肯定將兩個例項儲存到對應表中了。
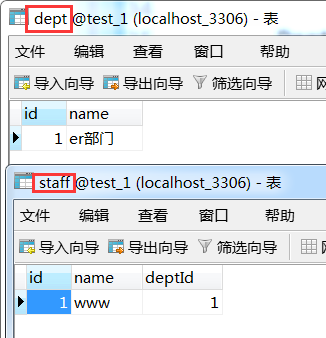
在我們什麼都不清楚的時候,就會先儲存部門,然後又要在儲存一下員工,這樣才能讓兩條記錄進入響應的表中,如果使用了級聯,那麼就不需要這樣寫的如此麻煩那了。
比如我們想在儲存staff時,就把dept也順帶給儲存了。
其他不變,就在staff.hbm.xml中增加級聯屬性
<class name="oneToMany.Staff" table="staff">
<id name="id" column="id">
<generator class="increment"></generator>
</id>
<property name="name"></property>
<many-to-one name="dept" column="deptId" class="oneToMany.Dept" cascade="save-update"></many-to-one>
</class>
cascade="save-update" 在相關聯的屬性這裡設定級聯,表示該實體類物件如果在save或update或者saveOrUpdate操作時,會將這個相關聯的物件(前提是有這個物件,也就是引用物件變數有值)進行相應的操作,所以在測試類中就只需要寫上session.save(staff); 而不在需要寫session.save(dept)啦。因為有級聯的存在,
Dept dept = new Dept(); dept.setName("er部門"); Staff staff = new Staff(); staff.setName("www");
//這個就是設定相關聯的物件 staff.setDept(dept); //這句話可以有可以沒有,具體作用在講解inverse的時候在說 dept.getStaffSet().add(staff); //session.save(dept);
//只需要儲存staff,就會將dept也一併儲存了。 session.save(staff);
結果 如我們想的那樣,級聯儲存了dept這個物件。
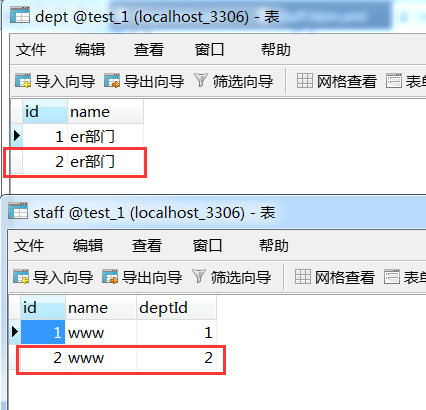
當然,這只是在staff這一方設定級聯,你也可以在dept這一方設定級聯,使的只儲存dept,就能將staff也儲存了。這裡只是把儲存物件做一個例子來講解,級聯並不一定就只是級聯儲存還有很多別的屬性,看下面總結
總結:
知道了級聯的作用,下面來看看級聯的屬性
cascade關係有以下幾種
all: 所有情況下均進行關聯操作,即save-update和delete。
none: 所有情況下均不進行關聯操作。這是預設值。
save-update: 在執行save/update/saveOrUpdate時進行關聯操作。
delete: 在執行delete 時進行關聯操作。
all-delete-orphan: 當一個節點在物件圖中成為孤兒節點時,刪除該節點
我們使用得是save-update,也就是說如果相關聯的物件在表中沒有記錄,則會一起save,如果有,看是否發生改變,會進行updat
其他應該度知道,說一下這個all-delete-orphan:什麼是孤兒節點,舉個例子,班級和學生,一張classes表,一張student表,student表中有5個學生的資料,其5個學生都屬於這個班級,也就是這5個學生中的外來鍵欄位都指向那個班級,現在刪除其中一個學生(remove),進行的資料操作僅僅是將student表中的該學生的外來鍵欄位置為null,也就是說,則個學生是沒有班級的,所以稱該學生為孤兒節點,我們本應該要將他完全刪除的,但是結果並不如我們所想的那樣,所以設定這個級聯屬性,就是為了刪除這個孤兒節點。也就是解決這類情況。
cascade關係比較簡單,就是這麼幾種,不難理解。關鍵的地方是理解對關聯物件進行相應的操作,這個關聯物件指的是誰,知道了這個,就知道了為什麼在對映檔案中那個位置設定級聯屬性了。
三、inverse
這個是我比較難理解的一個點,一開始,因為很多人度沒把他說清楚。
inverse的值是boolean值,也就是能設定為true或false。 如果一方的對映檔案中設定為true,說明在對映關係(一對多,多對多等)中讓對方來維護關係。如果為false,就自己來維護關係。預設值是true。 並且這屬性只能在一端設定。比如一對多,這個一端。也就是在有set集合的這方設定。
維護關係:維護什麼關係呢?包括兩個方面
1、也就是維護外來鍵的關係了,通俗點講,就是哪一方去設定這個被外來鍵約束的欄位的值。就拿上面這個例子來說,staff和dept兩張表不管進行什麼操作,只要關係到了另一張表,就不可避免的要通過操作外來鍵欄位,比如,staff查詢自己所屬的部門,就得通過被外來鍵約束的欄位值到dept中的主鍵中查詢,如果dept想查詢自己部門中有哪些員工,就拿著自己的主鍵值跟staff中的外來鍵欄位做比較,找到相同的值則是屬於自己部門的員工。 這個是查詢操作, 現在如果是新增操作呢,staff表中新增一條記錄,並且部門屬於dept表中的其中一個,staff中有被外來鍵約束脩飾的欄位,那是通過staff的insert語句就對這個外來鍵欄位賦值,還是讓dept物件使用update語句對其賦值呢,兩個都能對這個外來鍵欄位的值進行操作,誰去操作呢?如果不做設定,兩個都會操作,雖然不會出現問題,但是會影響效能,因為staff操作的話,在使用insert語句就能設定外來鍵欄位的值了,但是dept也會進行對其進行操作,又使用update語句,這樣一來,這個update就顯的很多餘。
2、維護級聯的關係,也就是說如果如果讓對方維護關係,則自己方的級聯將會失效,對方設定的級聯有用,如果自己維護關係,則自己方的級聯會有用,但是對方設定的級聯就會失效。
就上面的執行結果,會傳送5條sql語句,前兩條沒關係,看後面三條。看到最後一條了嗎,就是我們所說的發了一跳update語句。這就證實了我們上面所說的觀點,兩個表度對其維護外來鍵關係。
Hibernate: select max(id) from dept Hibernate: select max(id) from staff 上面這兩條不用管,這個是設定了主鍵生成策略為increment就會傳送這兩句。得到資料庫表中最大的一個id值,才知道下一次要賦的id值給多少。
-------------------------------------------------
Hibernate: insert into dept (name, id) values (?, ?) Hibernate: insert into staff (name, deptId, id) values (?, ?, ?) Hibernate: update staff set deptId=? where id=?
為了解決這種問題,使用inverse這個屬性,來只讓一方維護關係(維護外來鍵值)。
在一的一方設定該屬性,inverse=true 是預設值,也就是說讓staff來維護這種關係。
//Dept.hbm.xml <hibernate-mapping> <class name="oneToMany.Dept" table="dept"> <id name="id" column="id"> <generator class="increment"></generator> </id> <property name="name"></property> //inverse="true",讓對方維護關係,此時這裡的cascade設定沒什麼用,因為自身不維護關係,它也就失效了。 <set name="staffSet" inverse="true" cascade="save-update"> <key column="deptId"></key> <one-to-many class="oneToMany.Staff"/> </set> </class> </hibernate-mapping>
//Staff.hbm.xml
<class name="oneToMany.Staff" table="staff">
<id name="id" column="id">
<generator class="increment"></generator>
</id>
<property name="name"></property>
//這個級聯就有用,因為是讓自己這方維護關係
<many-to-one name="dept" column="deptId" class="oneToMany.Dept" cascade="save-update"></many-to-one>
</class>
注意:dept.getStaffSet().add(staff); 或者 staff.setDept(dept); 作用有兩個,一個是讓其雙方度有相關聯的物件,在設定級聯時,能只需儲存一方,另一方就級聯儲存了。另一個作用是這樣設定了關係,會讓staff或者dept這方會知道兩者的關係是怎麼樣的,也就是能夠有給外來鍵欄位賦值的能力。 因為我們設定了讓staff管理,所以dept.getStaffSet().add(staff);這句話就可以註釋掉,是多餘了,告訴他了該怎麼設定外來鍵欄位的值,他也不會去設定,只需要讓staff去設定就好。
Dept dept = new Dept(); dept.setName("er部門"); Staff staff = new Staff(); staff.setName("www"); staff.setDept(dept); //dept.getStaffSet().add(staff); //session.save(dept);//在dept方設定了級聯,但是隻儲存dept,staff也不會級聯儲存,因為這種關係dept已經不管了,dept方的級聯會失效。所以需要將其註釋,在staff方設定級聯,儲存staff就行 session.save(staff);//級聯儲存dept,並且自己會設定外來鍵欄位的值,也就是維護外來鍵關係。
看傳送的SQL語句,如果猜想沒錯的話,這次就不會在傳送update語句了。
Hibernate: select max(id) from dept Hibernate: select max(id) from staff ------------------------------------------------------ Hibernate: insert into dept (name, id) values (?, ?) Hibernate: insert into staff (name, deptId, id) values (?, ?, ?)
如果將inverse設定為false。就表明讓dept來設定外來鍵值,staff可以不用管了,
//Dept.hbm.xml <hibernate-mapping> <class name="oneToMany.Dept" table="dept"> <id name="id" column="id"> <generator class="increment"></generator> </id> <property name="name"></property> //inverse="false",讓自己維護關係,此時這裡的cascade設定就生效了,對方的eascade失效。 <set name="staffSet" inverse="false" cascade="save-update"> <key column="deptId"></key> <one-to-many class="oneToMany.Staff"/> </set> </class> </hibernate-mapping> //Staff.hbm.xml <class name="oneToMany.Staff" table="staff"> <id name="id" column="id"> <generator class="increment"></generator> </id> <property name="name"></property> //這個級聯失效,也就是說,如果單單隻儲存staff,是不會級聯儲存dept的。 <many-to-one name="dept" column="deptId" class="oneToMany.Dept" cascade="save-update"></many-to-one> </class>
因為有了上面的配置,看看測試的程式碼如何寫
Dept dept = new Dept(); dept.setName("er部門"); Staff staff = new Staff(); staff.setName("www"); //這句就可以去掉了,staff不會在管理了。
//staff.setDept(dept); //因為dept來維護關係,所以必須得讓他知道如何去關係這種外來鍵關係並且知道相關聯物件,所以說這句話的作用正好又能讓級聯的作用體現出來,又能體現外來鍵關係, dept.getStaffSet().add(staff); session.save(dept);//因為在dept方設定了save-update級聯,所以只儲存dept就可以了。 //session.save(staff);
這個的結果就會有update語句,因為是dept來管理,他要管理,就必須傳送update
Hibernate: select max(id) from dept Hibernate: select max(id) from staff 上面這兩條不用管,這個是設定了主鍵生成策略為increment就會傳送這兩句。得到資料庫表中最大的一個id值,才知道下一次要賦的id值給多少。 ------------------------------------------------- Hibernate: insert into dept (name, id) values (?, ?) Hibernate: insert into staff (name, deptId, id) values (?, ?, ?) Hibernate: update staff set deptId=? where id=?
四、總結
到這裡,inverse和cascade這兩個的作用就已經講解完了
1、inverse的許可權在cascade之上,意思就是cascade是否有用,還得看inverse這個屬性
2、inverse的作用:在對映關係中,讓其中一方去維護關係,好處就是能提高效能,不用重複維護。維護兩種關係,看下
2.1 控制級聯關係是否有效
cascade是否有效,就得看inserve的值,如果是自己方來維護關係,那麼cascade就有效,反之無效
2.2 控制外來鍵關係
這個就得通過讓自己擁有對方的例項引用(可能是set,也可能就是單個儲存物件的變數),這樣才具備控制外來鍵關係的能力,然後看inserve的值,
3、inverse只能在一的一方設定,並且預設值是true,也就是說,不設定inverse時,預設是讓多的一方去維護關係,這種一般是在雙向、外來鍵關係中才設定inverse的值,如果是單向的,就只有一方有維護關係的權利。
4、在以後的程式碼中,先要搞清楚關係,才能寫出效能最好的程式碼。通過學習這兩個屬性,在測試程式碼中,就不必那麼麻煩了,只需要考慮維護關係的一方,另一方就會自動儲存了。
5、如果你對測試程式碼傳送了多少條sql語句不清楚的話,可以往前面看看那篇講解一級快取和三種狀態的文章,通過快照區和session作用域來分析,到底會傳送多少條sql語句。