序言
寫的ArrayList原始碼分析這篇文章,第一次登上首頁,真是有點開心啊,再接再厲。這只是第一步,希望以後寫的文章更多的登上首頁,讓更多的人看到,共同學習,能幫助到別人就最好不過了。開始這一系列的第二篇文章吧,LinkedList。
--WH
補充內容
首先要知道一種資料結構,就是連結串列,什麼樣的形式是連結串列呢?推薦博文:http://www.jianshu.com/p/681802a00cdf
注意:上面推薦博文中的大部分是可以參考的,但是他寫這篇博文的時候,是在很久之前了,所以他裡面介紹的linkedList是一個雙向迴圈連結串列,但是現在我寫的版本是JDK1.7了,通過
檢視原始碼,發現linkedList已經不是雙向迴圈連結串列,只是一個雙向連結串列,這裡請分清楚,別搞懵了。如果還不知道我在說什麼,就請先看完我這篇文章然後再回過頭來看這句話。
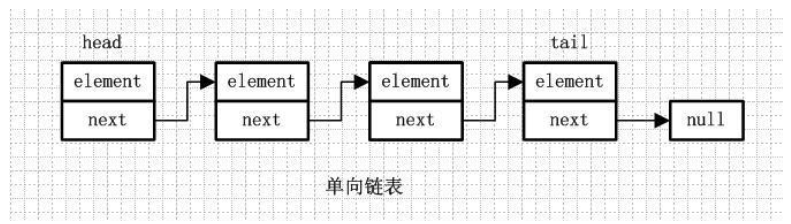
1、單向連結串列:
element:用來存放元素
next:用來指向下一個節點元素
通過每個結點的指標指向下一個結點從而連結起來的結構,最後一個節點的next指向null。
 \
\
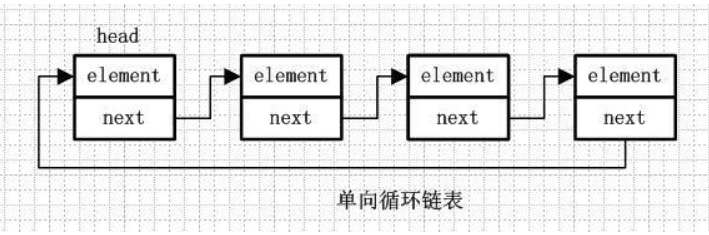
2、單向迴圈連結串列:element、next 跟前面一樣。
在單向連結串列的最後一個節點的next會指向頭節點,而不是指向null,這樣存成一個環
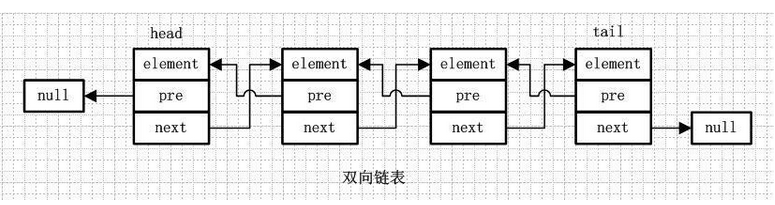
3、雙向連結串列:
element:存放元素
pre:用來指向前一個元素
next:指向後一個元素
雙向連結串列是包含兩個指標的,pre指向前一個節點,next指向後一個節點,但是第一個節點head的pre指向null,最後一個節點的tail指向null。
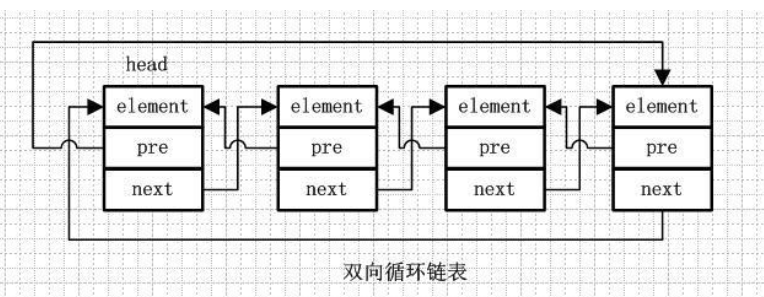
4、雙向迴圈連結串列:element、pre、next
第一個節點的pre指向最後一個節點,最後一個節點的next指向第一個節點,也形成一個“環”。
一、初識LinkedList
在我們平常用linkedList時,我們肯定都知道linkedList的一些特點
1、是通過連結串列實現的,
2、如果在頻繁的插入,或者刪除資料時,就用linkedList效能會更好。
我們只知道這些特性只是很片面的,並且只是常識,現在通過我們自己去查api,看官方是如何解釋LinkedList的。(版本jdk1.7)
1、Doubly-linked list implementation of the List and Deque interfaces. Implements all optional list operations, and permits all elements (including null).
這告訴我們,linkedList是一個雙向連結串列,並且實現了List和Deque介面中所有的列表操作,並且能儲存任何元素,包括null,這裡我們可以知道linkedList除了可以當連結串列使用,還可以當作佇列使用,並能進行相應的操作。
2、All of the operations perform as could be expected for a doubly-linked list. Operations that index into the list will traverse the list from the beginning or the end, whichever is closer to the specified index.
這個告訴我們,linkedList在執行任何操作的時候,都必須先遍歷此列表來靠近通過index查詢我們所需要的的值。通俗點講,這就告訴了我們這個是順序存取,每次操作必須先按開始到結束的順序遍歷,隨機存取,就是arrayList,能夠通過index。隨便訪問其中的任意位置的資料,這就是隨機列表的意思。
3、api中接下來講的一大堆,就是說明linkedList是一個非執行緒安全的(非同步),其中在操作Interator時,如果改變列表結構(add\delete等),會發生fail-fast。
通過檢視api,重新總結一下目前我們知道的linkedList的特性
1、非同步,也就是非執行緒安全
2、雙向連結串列、由於實現了list和Deque介面,能夠當作佇列來使用並且又是雙向連結串列那麼就有著連結串列的好處和壞處。
連結串列:查詢效率不高,但是插入和刪除這種操作效能好。
3、是順序存取結構,注意和隨機存取結構兩個概念搞清楚
二、LinkedList的繼承結構以及層次關係
1、繼承結構:
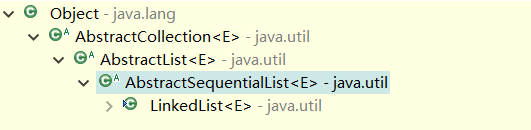
我們可以看到,linkedList在最底層,說明他的功能最為強大,並且細心的還會發現,arrayList只有四層,這裡多了一層AbstractSequentialList的抽象類,為什麼呢?不知道就查api,api文件中都會有說明的
·減少實現順序存取(例如LinkedList)這種類的工作,通俗的講就是方便,抽象出類似LinkedList這種類的一些共同的方法
·既然有了上面這句話,那麼以後如果自己想實現順序存取這種特性的類(就是連結串列形式),那麼就繼承這個AbstractSequentialList抽象類,如果想像陣列那樣的隨機存取的類,那麼就去實現AbstracList抽象類,
·這樣的分層,就很符合我們抽象的概念,越在高處的類,就越抽象,往在底層的類,就越有自己獨特的個性。自己要慢慢領會這種思想。
1 public abstract class AbstractSequentialList<E> 2 extends AbstractList<E> 3 //這裡第一段就解釋了這個類的作用,這個類為實現list介面提供了一些重要的方法, 4 //盡最大努力去減少實現這個“順序存取”的特性的資料儲存(例如連結串列)的什麼鬼,對於 5 //隨機存取資料(例如陣列)的類應該優先使用AbstractList 6 //從上面就可以大概知道,AbstractSwquentialList這個類是為了減少LinkedList這種順//序存取的類的程式碼複雜度而抽象的一個類, 7 This class provides a skeletal implementation of the List interface to minimize the effort required to implement this interface backed by a "sequential access" data store (such as a linked list). For random access data (such as an array), AbstractList should be used in preference to this class. 8 9 //這一段大概講的就是這個AbstractSequentialList這個類和AbstractList這個類是完全//相反的。比如get、add這個方法的實現 10 This class is the opposite of the AbstractList class in the sense that it implements the "random access" methods (get(int index), set(int index, E element), add(int index, E element) and remove(int index)) on top of the list's list iterator, instead of the other way around. 11 12 //這裡就是講一些我們自己要繼承該類,該做些什麼事情,一些規範。 13 To implement a list the programmer needs only to extend this class and provide implementations for the listIterator and size methods. For an unmodifiable list, the programmer need only implement the list iterator's hasNext, next, hasPrevious, previous and index methods. 14 15 For a modifiable list the programmer should additionally implement the list iterator's set method. For a variable-size list the programmer should additionally implement the list iterator's remove and add methods. 16 17 The programmer should generally provide a void (no argument) and collection constructor, as per the recommendation in the Collection interface specification.
實現的介面

1、List介面:列表,add、set、等一些對列表進行操作的方法
2、Deque介面:有佇列的各種特性,
3、Cloneable介面:能夠複製,使用那個copy方法。
4、Serializable介面:能夠序列化。
5、應該注意到沒有RandomAccess:那麼就推薦使用iterator,在其中就有一個foreach,增強的for迴圈,其中原理也就是iterator,我們在使用的時候,使用foreach或者iterator都可以。
三、構造方法
兩個構造方法(兩個構造方法都是規範規定需要寫的。看了AbstractSequentialList的api應該會知道)
1、空的構造方法
1 /** 2 * Constructs an empty list. 3 */ 4 public LinkedList() { 5 }
2、有參構造
1 /** 2 * Constructs a list containing the elements of the specified 3 * collection, in the order they are returned by the collection's 4 * iterator. 5 * 6 * @param c the collection whose elements are to be placed into this list 7 * @throws NullPointerException if the specified collection is null 8 */ 9 //將集合c中的各個元素構建成LinkedList連結串列。 10 public LinkedList(Collection<? extends E> c) { 11 this(); 12 addAll(c); 13 }
addAll(c);
public boolean addAll(Collection<? extends E> c) { //繼續往下看 return addAll(size, c); }
addAll(size,c):這個方法,能包含三種情況下的新增,我們這裡分析的只是構造方法,空連結串列的情況(情況一)看的時候只需要按照不同的情況分析下去就行了。
通過這裡的原始碼分析,就可以得知linkedList是一個雙向連結串列,而不是雙向迴圈連結串列。
//真正核心的地方就是這裡了,記得我們傳過來的是size,c public boolean addAll(int index, Collection<? extends E> c) { //檢查index這個是否為合理。這個很簡單,自己點進去看下就明白了。 checkPositionIndex(index); //將集合c轉換為Object陣列 a Object[] a = c.toArray(); //陣列a的長度numNew,也就是由多少個元素 int numNew = a.length; if (numNew == 0) //集合c是個空的,直接返回false,什麼也不做。 return false; //集合c是非空的,定義兩個節點(內部類),每個節點都有三個屬性,item、next、prev。注意:不要管這兩個什麼含義,就是用來做臨時儲存節點的。這個Node看下面一步的原始碼分析,Node就是linkedList的最核心的實現,可以直接先跳下一個去看Node的分析 Node<E> pred, succ; //構造方法中傳過來的就是index==size if (index == size) { //linkedList中三個屬性:size、first、last。 size:連結串列中的元素個數。 first:頭節點 last:尾節點,就兩種情況能進來這裡
//情況一、:構造方法建立的一個空的連結串列,那麼size=0,last、和first都為null。linkedList中是空的。什麼節點都沒有。succ=null、pred=last=null
//情況二、:連結串列中有節點,size就不是為0,first和last都分別指向第一個節點,和最後一個節點,在最後一個節點之後追加元素,就得記錄一下最後一個節點是什麼,所以把last儲存到pred臨時節點中。 succ = null; pred = last; } else { //情況三、index!=size,說明不是前面兩種情況,而是在連結串列中間插入元素,那麼就得知道index上的節點是誰,儲存到succ臨時節點中,然後將succ的前一個節點儲存到pred中,這樣儲存了這兩個節點,就能夠準確的插入節點了
//舉個簡單的例子,有2個位置,1、2、如果想插資料到第二個位置,雙向連結串列中,就需要知道第一個位置是誰,原位置也就是第二個位置上是誰,然後才能將自己插到第二個位置上。如果這裡還不明白,先看一下文章開頭對於各種連結串列的刪除,add操作是怎麼實現的。 succ = node(index); pred = succ.prev; } //前面的準備工作做完了,將遍歷陣列a中的元素,封裝為一個個節點。 for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o;
//pred就是之前所構建好的,可能為null、也可能不為null,為null的話就是屬於情況一、不為null則可能是情況二、或者情況三 Node<E> newNode = new Node<>(pred, e, null); //如果pred==null,說明是情況一,構造方法,是剛建立的一個空連結串列,此時的newNode就當作第一個節點,所以把newNode給first頭節點 if (pred == null) first = newNode; else //如果pred!=null,說明可能是情況2或者情況3,如果是情況2,pred就是last,那麼在最後一個節點之後追加到newNode,如果是情況3,在中間插入,pred為原index節點之前的一個節點,將它的next指向插入的節點,也是對的 pred.next = newNode; //然後將pred換成newNode,注意,這個不在else之中,請看清楚了。
pred = newNode; } if (succ == null) { //如果succ==null,說明是情況一或者情況二,
情況一、構造方法,也就是剛建立的一個空連結串列,pred已經是newNode了,last=newNode,所以linkedList的first、last都指向第一個節點。
情況二、在最後節後之後追加節點,那麼原先的last就應該指向現在的最後一個節點了,就是newNode。 last = pred; } else { //如果succ!=null,說明可能是情況三、在中間插入節點,舉例說明這幾個引數的意義,有1、2兩個節點,現在想在第二個位置插入節點newNode,根據前面的程式碼,pred=newNode,succ=2,並且1.next=newNode,
1已經構建好了,pred.next=succ,相當於在newNode.next = 2; succ.prev = pred,相當於 2.prev = newNode, 這樣一來,這種指向關係就完成了。first和last不用變,因為頭節點和尾節點沒變 pred.next = succ; //。。 succ.prev = pred; } //增加了幾個元素,就把 size = size +numNew 就可以了 size += numNew; modCount++; return true; }
Node:內部類
item:當前節點的值
prev(previous):指向當前節點的前一個節點
next:指向當前節點的後一個節點
//根據前面介紹雙向連結串列就知道這個代表什麼了,linkedList的奧祕就在這裡。
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
三、常用方法
常規,先看增、刪、查詢方法吧
add(E)
/** * Appends the specified element to the end of this list. * * <p>This method is equivalent to {@link #addLast}. * * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ //看上面第一句話的註釋,在這個連結串列的末尾追加指定的元素 public boolean add(E e) { //在末尾追加元素的方法。 linkLast(e); return true; }
linkLast(e)
/** * Links e as last element. */ void linkLast(E e) { final Node<E> l = last; //臨時節點l(L的小寫)儲存last,也就是l指向了最後一個節點 final Node<E> newNode = new Node<>(l, e, null);//將e封裝為節點,並且e.prev指向了最後一個節點 last = newNode;//newNode成為了最後一個節點,所以last指向了它 if (l == null) //判斷是不是一開始連結串列中就什麼都沒有,如果沒有,則newNode就成為了第一個節點,first和last都要指向它 first = newNode; else //正常的在最後一個節點後追加,那麼原先的最後一個節點的next就要指向現在真正的最後一個節點,原先的最後一個節點就變成了倒數第二個節點 l.next = newNode; size++;//新增一個節點,size自增 modCount++; }
remove(Object o)
/** * Removes the first occurrence of the specified element from this list, * if it is present. If this list does not contain the element, it is * unchanged. More formally, removes the element with the lowest index * {@code i} such that * <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt> * (if such an element exists). Returns {@code true} if this list * contained the specified element (or equivalently, if this list * changed as a result of the call). * * @param o element to be removed from this list, if present * @return {@code true} if this list contained the specified element */ //首先通過看上面的註釋,我們可以知道,如果我們要移除的值在連結串列中存在多個一樣的值,那麼我們會移除index最小的那個,也就是最先找到的那個值,如果不存在這個值,那麼什麼也不做 public boolean remove(Object o) { //這裡可以看到,linkedList也能儲存null if (o == null) { //迴圈遍歷連結串列,直到找到null值,然後使用unlink移除該值。下面的這個else中也一樣 for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; }
unlink(x)
/** * Unlinks non-null node x. */ //不能傳一個null值過,注意,看之前要注意之前的next、prev這些都是誰。 E unlink(Node<E> x) { // assert x != null; //拿到節點x的三個屬性 final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; //這裡開始往下就進行移除該元素之後的操作,也就是把指向哪個節點搞定。 if (prev == null) { //說明移除的節點是頭節點,則first頭節點應該指向下一個節點 first = next; } else { //不是頭節點,prev.next=next:有1、2、3,將1.next指向3 prev.next = next; //然後解除x節點的前指向。 x.prev = null; } if (next == null) { //說明移除的節點是尾節點 last = prev; } else { //不是尾節點,有1、2、3,將3.prev指向1. 然後將2.next=解除指向。 next.prev = prev; x.next = null; } //x的前後指向都為null了,也把item為null,讓gc回收它 x.item = null; size--; //移除一個節點,size自減 modCount++; return element; //由於一開始已經儲存了x的值到element,所以返回。 }
get(index)查詢元素的方法
/** * Returns the element at the specified position in this list. * * @param index index of the element to return * @return the element at the specified position in this list * @throws IndexOutOfBoundsException {@inheritDoc} */ //這裡沒有什麼,重點還是在node(index)中 public E get(int index) { checkElementIndex(index); return node(index).item; }
node(index)
/** * Returns the (non-null) Node at the specified element index. */ //這裡查詢使用的是先從中間分一半查詢 Node<E> node(int index) { // assert isElementIndex(index); //"<<":*2的幾次方 “>>”:/2的幾次方,例如:size<<1:size*2的1次方, //這個if中就是查詢前半部分 if (index < (size >> 1)) {//index<size/2 Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else {//前半部分沒找到,所以找後半部分 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
indexOf(Object o)
//這個很簡單,就是通過實體元素來查詢到該元素在連結串列中的位置。跟remove中的程式碼類似,只是返回型別不一樣。 public int indexOf(Object o) { int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; }
小小總結一下。
如果你搞懂了這幾個方法,那麼其他的方法也就差不多了。可以自己嘗試去看看,看了上面幾個方法之後,應該有以下幾點收穫
1、linkedList:雙向連結串列
2、能存放null值
3、在進行增加、刪除時,雖然要先遍歷到指定位置,但是不需要跟移動大量資料,很輕鬆就完成了任務。
4、資料結構很重要。這是我看原始碼後的第一感覺。
四、ListIterator的使用,LinkedList特殊的東西
在LinkedList中除了有一個Node的內部類外,應該還能看到另外兩個內部類,那就是ListItr,還有一個是DescendingIterator。
ListItr內部類
看一下他的繼承結構,發現只繼承了一個ListIterator,到ListIterator中一看,
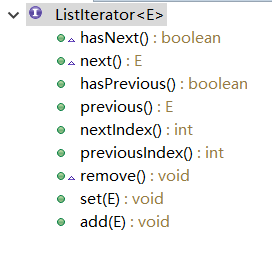
看到方法名之後,就發現不止有向後迭代的方法,還有向前迭代的方法,所以我們就知道了這個ListItr這個內部類幹嘛用的了,就是能讓linkedList不光能像後迭代,也能向前迭代,其中原始碼非常簡單,這裡就不一一講解了
看一下ListItr中的方法,可以發現,在迭代的過程中,還能移除、修改、新增值得操作。
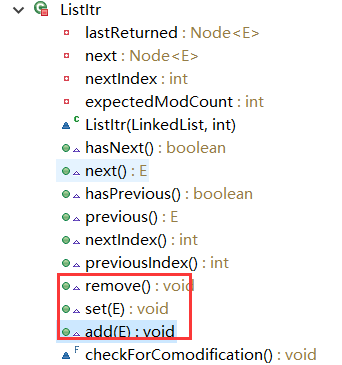
DescendingIterator內部類
/** * Adapter to provide descending iterators via ListItr.previous */ 看一下這個類,還是呼叫的ListItr,作用是封裝一下Itr中幾個方法,讓使用者以正常的思維去寫程式碼,例如,在從後往前遍歷的時候,也是跟從前往後遍歷一樣,使用next等操作,而不用使用特殊的previous。 private class DescendingIterator implements Iterator<E> { private final ListItr itr = new ListItr(size()); public boolean hasNext() { return itr.hasPrevious(); } public E next() { return itr.previous(); } public void remove() { itr.remove(); } }
五、總結
通過檢視LinkedList原始碼,我們知道以下幾點
1、linkedList本質上是一個雙向連結串列,通過一個Node內部類實現的這種連結串列結構。
2、能儲存null值
3、跟arrayList相比較,就真正的知道了,LinkedList在刪除和增加等操作上效能好,而ArrayList在查詢的效能上號
4、從原始碼中看,它不存在容量不足的情況
5、linkedList不光能夠向前迭代,還能像後迭代,並且在迭代的過程中,可以修改值、新增值、還能移除值。
6、linkedList不光能當連結串列,還能當佇列使用,具體的可以自己去先看看其中的奧祕,這個我就歸結到以後寫Deque時在總結吧。
---------------------------------------------------------------------------------------------------------------------------------------------------------------
終於寫完了,如果對你們有幫助,請點個推薦,給我點信心呀,不枉費我花那麼多時間在這裡寫這個。雖然對我自己的幫助也很大