主 題 :INTO100沙龍
時間 :2015年11月21日下午
地點 :夢想加聯合辦公空間
分享人:衛向軍(畢業於北京郵電大學,現任微博平臺架構師,先後在微軟、金山雲、新浪微博從事技術研發工作,專注於系統架構設計、音視訊通訊系統、分散式檔案系統和資料探勘等領域。)
架構以及我理解中架構的本質
在開始談我對架構本質的理解之前,先談談對今天技術沙龍主題的個人見解,千萬級規模的網站感覺數量級是非常大的,對這個數量級我們戰略上 要重 視 它 , 戰術上又 要 藐 視 它。先舉個例子感受一下千萬級到底是什麼數量級?現在很流行的優步(Uber),從媒體公佈的資訊看,它每天接單量平均在百萬左右, 假如每天有10個小時的服務時間,平均QPS只有30左右。對於一個後臺伺服器,單機的平均QPS可以到達800-1000,單獨看寫的業務量很簡單 。為什麼我們又不能說輕視它?第一,我們看它的資料儲存,每天一百萬的話,一年資料量的規模是多少?其次,剛才說的訂單量,每一個訂單要推送給附近的司機、司機要並
發搶單,後面業務場景的訪問量往往是前者的上百倍,輕鬆就超過上億級別了。
今天我想從架構的本質談起之後,希望大家理解在做一些建構設計的時候,它的出發點以及它解決的問題是什麼。
架構,剛開始的解釋是我從知乎上看到的。什麼是架構?有人講, 說架構並不是一 個很 懸 乎的 東西 , 實際 上就是一個架子 , 放一些 業務 和演算法,跟我們的生活中的晾衣架很像。更抽象一點,說架構其 實 是 對 我 們 重複性業務 的抽象和我 們 未來 業務 擴充的前瞻,強調過去的經驗和你對整個行業的預見。
我們要想做一個架構的話需要哪些能力?我覺得最重要的是架構師一個最重要的能力就是你要有 戰 略分解能力。這個怎麼來看呢:
- 第一,你必須要有抽象的能力,抽象的能力最基本就是去重,去重在整個架構中體現在方方面面,從定義一個函式,到定義一個類,到提供的一個服務,以及模板,背後都是要去重提高可複用率。
- 第二, 分類能力。做軟體需要做物件的解耦,要定義物件的屬性和方法,做分散式系統的時候要做服務的拆分和模組化,要定義服務的介面和規範。
- 第三, 演算法(效能),它的價值體現在提升系統的效能,所有效能的提升,最終都會落到CPU,記憶體,IO和網路這4大塊上。
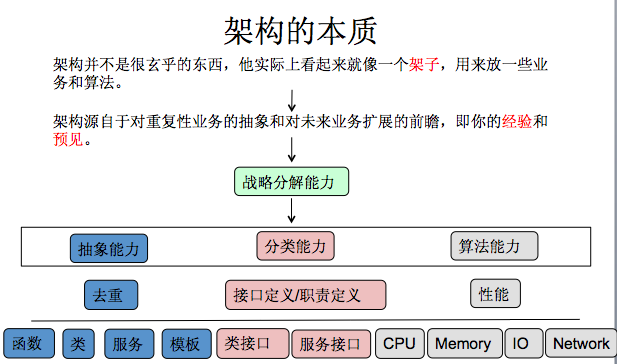
這一頁PPT舉了一些例子來更深入的理解常見技術背後的架構理念。
- 第一個例子,在分散式系統我們會做 MySQL分 庫 分表,我們要從不同的庫和表中讀取資料,這樣的抽象最直觀就是使用模板,因為絕大多數SQL語義是相同的,除了路由到哪個庫哪個表,如果不使用Proxy中介軟體,模板就是價效比最高的方法。
- 第二看一下加速網路的CDN,它是做速度方面的效能提升,剛才我們也提到從CPU、記憶體、IO、網路四個方面來考慮,CDN本質上一個是做網路智慧排程優化,另一個是多級快取優化。
- 第三個看一下服務化,剛才已經提到了,各個大網站轉型過程中一定會做服務化,其實它就是做抽象和做服務的拆分。第四個看一下訊息佇列,本質上還是做分類,只不過不是兩個邊際清晰的類,而是把兩個邊際不清晰的子系統通過佇列解構並且非同步化。

新浪微博整體架構是什麼樣的
接下我們看一下微博整體架構,到一定量級的系統整個架構都會變成三層,客戶端包括WEB、安卓和IOS,這裡就不說了。
接著還都會有一個介面層, 有三個主要作用:
- 第一個作用,要做 安全隔離,因為前端節點都是直接和使用者互動,需要防範各種惡意攻擊;
- 第二個還充當著一個 流量控制的作用,大家知道,在2014年春節的時候,微信紅包,每分鐘8億多次的請求,其實真正到它後臺的請求量,只有十萬左右的數量級(這裡的資料可能不準),剩餘的流量在介面層就被擋住了;
- 第三,我們看對 PC 端和移 動 端的需求不一樣的,所以我們可以進行拆分。介面層之後是後臺,可以看到微博後臺有三大塊:
- 一個是 平臺服 務,
- 第二, 搜尋,
- 第三, 大資料。
到了後臺的各種服務其實都是處理的資料。 像平臺的業務部門,做的就是 資料儲存和讀 取,對搜尋來說做的是 資料的 檢 索,對大資料來說是做的資料的 挖掘。微博其實和淘寶是很類似
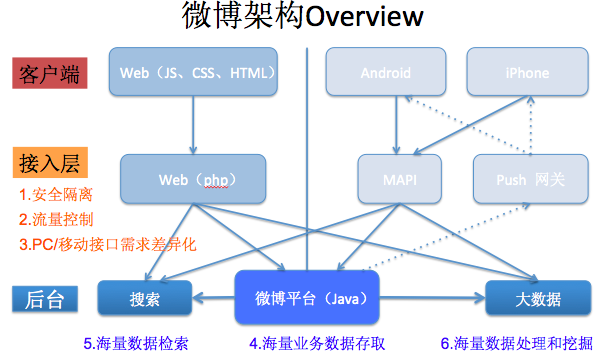
微博其實和淘寶是很類似的。一般來說,第一代架構,基本上能支撐到使用者到 百萬 級別,到第二代架構基本能支撐到 千萬 級別都沒什麼問題,當業務規模到 億級別時,需要第三代的架構。
從 LAMP 的架構到面向服 務 的架構,有幾個地方是非常難的,首先不可能在第一代基礎上通過簡單的修修補補滿足使用者量快速增長的,同時線上業務又不能停, 這是我們常說的 在 飛 機上 換 引擎的 問題。前兩天我有一個朋友問我,說他在內部推行服務化的時候,把一個模組服務化做完了,其他部門就是不接。我建議在做服務化的時候,首先更多是偏向業務的梳理,同時要找準一個很好的切入點,既有架構和服務化上的提升,業務方也要有收益,比如提升效能或者降低維護成本同時升級過程要平滑,建議開始從原子化服務切入,比如基礎的使用者服務, 基礎的短訊息服務,基礎的推送服務。 第二,就是可 以做無狀 態 服 務,後面會詳細講,還有資料量大了後需要做資料Sharding,後面會將。 第三代 架構 要解決的 問題,就是使用者量和業務趨於穩步增加(相對爆發期的指數級增長),更多考慮技術框架的穩定性, 提升系統整體的效能,降低成本,還有對整個系統監控的完善和升級。
大型網站的系統架構是如何演變的
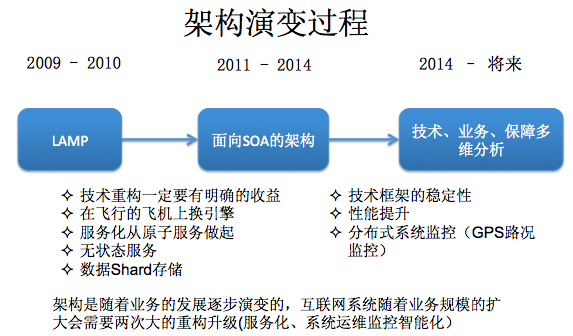
我們通過通過資料看一下它的挑戰,PV是在10億級別,QPS在百萬,資料量在千億級別。我們可用性,就是SLA要求4個9,介面響應最多不能超過150毫秒,線上所有的故障必須得在5分鐘內解決完。如果說5分鐘沒處理呢?那會影響你年終的績效考核。2015年微博DAU已經過億。我們系統有上百個微服務,每週會有兩次的常規上線和不限次數的緊急上線。我們的挑戰都一樣,就是資料量,bigger and bigger,使用者體驗是faster and faster,業務是more and more。網際網路業務更多是產品體驗驅動, 技 術 在 產 品 體驗上最有效的貢獻 , 就是你的效能 越來越好 。 每次降低載入一個頁面的時間,都可以間接的降低這個頁面上使用者的流失率。

微博的技術挑戰和正交分解法解析架構
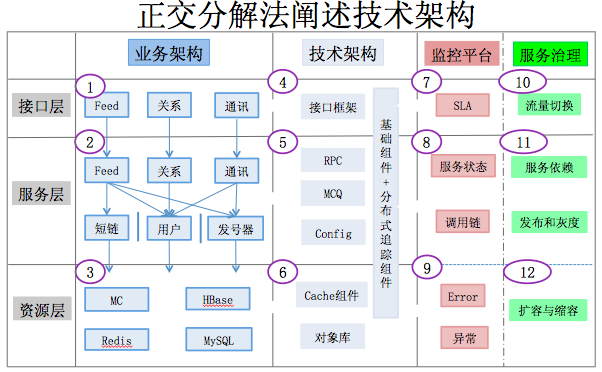
下面看一下 第三代的 架構 圖 以及 我 們 怎麼用正交分解法 闡 述。 我們可以看到我們從兩個維度,橫軸和縱軸可以看到。 一個 維 度 是 水平的 分層 拆分,第二從垂直的維度會做拆分。水平的維度從介面層、到服務層到資料儲存層。垂直怎麼拆分,會用業務架構、技術架構、監控平臺、服務治理等等來處理。我相信到第二代的時候很多架構已
經有了業務架構和技術架構的拆分。我們看一下, 介面層有feed、使用者關係、通訊介面;服務層,SOA裡有基層服務、原子服務和組合服務,在微博我們只有原子服務和組合服務。原子服務不依賴於任何其他服務,組合服務由幾個原子服務和自己的業務邏輯構建而成 ,資源層負責海量資料的儲存(後面例子會詳細講)。技 術框架解決 獨立於 業務 的海量高併發場景下的技術難題,由眾多的技術元件共同構建而成 。在介面層,微博使用JERSY框架,幫助你做引數的解析,引數的驗證,序列化和反序列化;資源層,主要是快取、DB相關的各類元件,比如Cache元件和物件庫元件。監 控平臺和服 務 治理 , 完成系統服務的畫素級監控,對分散式系統做提前診斷、預警以及治理。包含了SLA規則的制定、服務監控、服務呼叫鏈監控、流量監控、錯誤異常監控、線上灰度釋出上線系統、線上擴容縮容排程系統等。
下面我們講一下常見的設計原則。
- 第一個,首先是系統架構三個利器:
- 一個, 我 們 RPC 服 務組 件 (這裡不講了),
- 第二個,我們 訊息中 間 件 。訊息中介軟體起的作用:可以把兩個模組之間的互動非同步化,其次可以把不均勻請求流量輸出為勻速的輸出流量,所以說訊息中介軟體 非同步化 解耦 和流量削峰的利器。
- 第三個是配置管理,它是 程式碼級灰度釋出以及 保障系統降級的利器。
- 第二個 , 無狀態 , 介面 層 最重要的就是無狀 態。我們在電商網站購物,在這個過程中很多情況下是有狀態的,比如我瀏覽了哪些商品,為什麼大家又常說介面層是無狀態的,其實我們把狀態從介面層剝離到了資料層。像使用者在電商網站購物,選了幾件商品,到了哪一步,介面無狀態後,狀態要麼放在快取中,要麼放在資料庫中, 其 實 它並不是沒有狀 態 , 只是在 這 個 過 程中我 們 要把一些有狀 態 的 東 西抽離出來 到了資料層。
- 第三個, 資料 層 比服 務層 更需要 設計,這是一條非常重要的經驗。對於服務層來說,可以拿PHP寫,明天你可以拿JAVA來寫,但是如果你的資料結構開始設計不合理,將來資料結構的改變會花費你數倍的代價,老的資料格式向新的資料格式遷移會讓你痛不欲生,既有工作量上的,又有資料遷移跨越的時間週期,有一些甚至需要半年以上。
- 第四,物理結構與邏輯結構的對映,上一張圖看到兩個維度切成十二個區間,每個區間代表一個技術領域,這個可以看做我們的邏輯結構。另外,不論後臺還是應用層的開發團隊,一般都會分幾個垂直的業務組加上一個基礎技術架構組,這就是從物理組織架構到邏輯的技術架構的完美的對映,精細化團隊分工,有利於提高溝通協作的效率 。
- 第五, www .sanhao.com 的訪問過程,我們這個架構圖裡沒有涉及到的,舉個例子,比如當你在瀏覽器輸入www.sanhao網址的時候,這個請求在介面層之前發生了什麼?首先會檢視你本機DNS以及DNS服務,查詢域名對應的IP地址,然後傳送HTTP請求過去。這個請求首先會到前端的VIP地址(公網服務IP地址),VIP之後還要經過負載均衡器(Nginx伺服器),之後才到你的應用介面層。在介面層之前發生了這麼多事,可能有使用者報一個問題的時候,你通過在介面層查日誌根本發現不了問題,原因就是問題可能發生在到達介面層之前了。
- 第六,我們說分散式系統,它最終的瓶頸會落在哪裡呢?前端時間有一個網友跟我討論的時候,說他們的系統遇到了一個瓶頸, 查遍了CPU,記憶體,網路,儲存,都沒有問題。我說你再查一遍,因為最終你不論用上千臺伺服器還是上萬臺伺服器,最終系統出瓶頸的一定會落在某一臺機(可能是葉子節點也可能是核心的節點),一定落在CPU、記憶體、儲存和網路上,最後查出來問題出在一臺伺服器的網路卡頻寬上。

微博多級雙機房快取架構
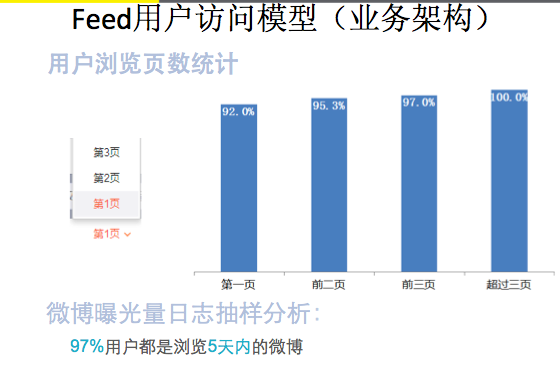
接下來我們看一下微博的Feed多級快取。我們做業務的時候,經常很少做業務分析,技術大會上的分享又都偏向技術架構。其實大家更多的日常工作是需要花費更多時間在業務優化上。這張圖是統計微博的資訊流前幾頁的訪問比例,像前三頁佔了97%,在做快取設計的時候,我們最多隻存最近的M條資料。 這裡強調的就是做系統設計 要基於用 戶 的 場 景 , 越細緻越好 。舉了一個例子,大家都會用電商,電商在雙十一會做全國範圍內的活動,他們做設計的時候也會考慮場景的,一個就是購物車,我曾經跟相關開發討論過,購物車是在雙十一之前使用者的訪問量非常大,就是不停地往裡加商品。在真正到雙十一那天他不會往購物車加東西了,但是他會頻繁的瀏覽購物車。針對這個場景,活動之前重點設計優化購物車的寫場景, 活動開始後優化購物車的讀場景。
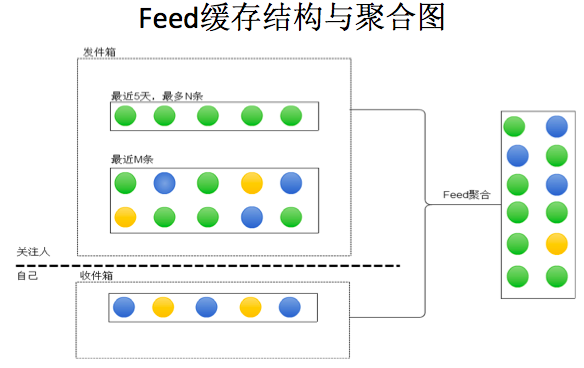
你看到的微博是由哪些部分聚合而成的呢?最右邊的是Feed,就是微博所有關注的人,他們的微博所組成的。微博我們會按照時間順序把所有關注人的順序做一個排序。隨著業務的發展,除了跟時間序相關的微博還有非時間序的微博,就是會有廣告的要求,增加一些廣告,還有粉絲頭條,就是拿錢買的,熱門微博,都會插在其中。分發控制,就是說和一些推薦相關的,我推薦一些相關的好友的微博,我推薦一些你可能沒有讀過的微博,我推薦一些其他型別的微博。 當然對非時序的微博和分發控制微博,實際會起多個並行的程式來讀取,最後同步做統一的聚合。這裡稍微分享一下, 從SNS社交領域來看,國內現在做的比較好的三個資訊流:
- 微博 是 基於弱關係的媒體資訊流 ;
- 朋友圈是基於 強 關係的資訊流 ;
- 另外一個做的比 較 好的就是今日 頭 條 , 它並不是基於關係來構建資訊流 , 而是基於 興趣和相關性的個性化推薦 資訊流 。
資訊流的聚合,體現在很多很多的產品之中,除了SNS,電商裡也有資訊流的聚合的影子。比如搜尋一個商品後出來的列表頁,它的資訊流基本由幾部分組成:第一,打廣告的;第二個,做一些推薦,熱門的商品,其次,才是關鍵字相關的搜尋結果。 資訊流 開始的時候 很 簡單 , 但是到後期會 發現 , 你的 這 個流 如何做控制分發 , 非常複雜, 微博在最近一兩年一直在做 這樣 的工作。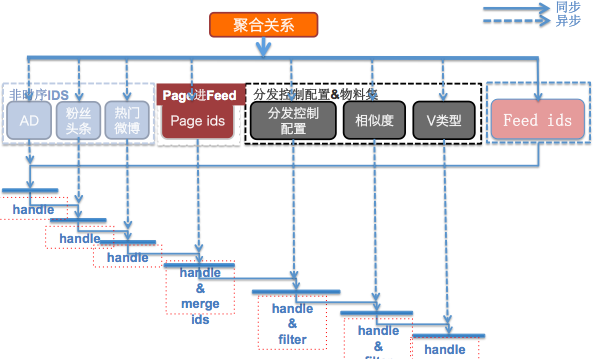
剛才我們是從業務上分析,那麼技術上怎麼解決高併發,高效能的問題?微博訪問量很大的時候,底層儲存是用MySQL資料庫,當然也會有其他的。對於查詢請求量大的時候,大家知道一定有快取,可以複用可重用的計算結果。可以看到,發一條微博,我有很多粉絲,他們都會來看我發的內容,所以 微博是最適合使用 緩 存 的系統,微博的讀寫比例基本在幾十比一。微博使用了 雙 層緩 存,上面是L1,每個L1上都是一組(包含4-6臺機器),左邊的框相當於一個機房,右邊又是一個機房。在這個系統中L1快取所起的作用是什麼? 首先,L1 緩 存增加整個系 統 的 QPS, 其次 以低成本靈活擴容的方式 增加 系統 的 頻寬 。想象一個極端場景,只有一篇博文,但是它的訪問量無限增長,其實我們不需要影響L2快取,因為它的內容儲存的量小,但它就是訪問量大。這種場景下,你就需要使用L1來擴容提升QPS和頻寬瓶頸。另外一個場景,就是L2級快取發生作用,比如我有一千萬個使用者,去訪問的是一百萬個使用者的微博 ,這個時候,他不只是說你的吞吐量和訪問頻寬,就是你要快取的博文的內容也很多了,這個時候你要考慮快取的容量, 第二 級緩 存更多的是從容量上來 規劃,保證請求以較小的比例 穿透到 後端的 資料 庫 中 ,根據你的使用者模型你可以估出來,到底有百分之多少的請求不能穿透到DB, 評估這個容量之後,才能更好的評估DB需要多少庫,需要承擔多大的訪問的壓力。另外,我們看雙機房的話,左邊一個,右邊一個。 兩個機房是互 為 主 備 , 或者互 為熱備 。如果兩個使用者在不
同地域,他們訪問兩個不同機房的時候,假設使用者從IDC1過來,因為就近原理,他會訪問L1,沒有的話才會跑到Master,當在IDC1沒找到的時候才會跑到IDC2來找。同時有使用者從IDC2訪問,也會有請求從L1和Master返回或者到IDC1去查詢。 IDC1 和 IDC2 ,兩個機房都有全量的使用者資料,同時線上提供服務,但是快取查詢又遵循最近訪問原理。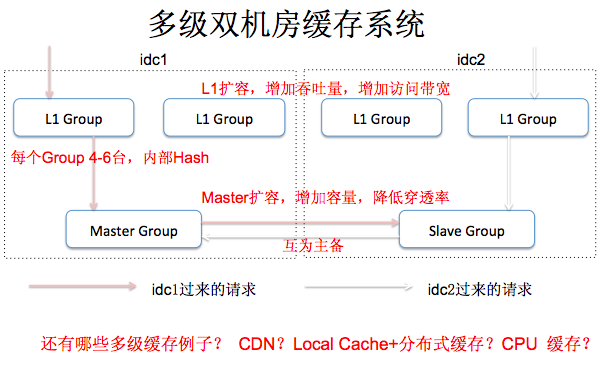
還有哪些多級快取的例子呢?CDN是典型的多級快取。CDN在國內各個地區做了很多節點,比如在杭州市部署一個節點時,在機房裡肯定不止一臺機器,那麼對於一個地區來說,只有幾臺伺服器到源站回源,其他節點都到這幾臺伺服器回源即可,這麼看CDN至少也有兩級。Local Cache+ 分散式 緩 存,這也是常見的一種策略。有一種場景,分散式快取並不適用, 比如 單 點 資 源 的爆發性峰值流量,這個時候使用Local Cache + 分散式快取,Local Cache 在 應用 服 務 器 上用很小的 記憶體資源 擋住少量的 極端峰值流量,長尾的流量仍然訪問分散式快取,這樣的Hybrid快取架構通過複用眾多的應用伺服器節點,降低了系統的整體成本。
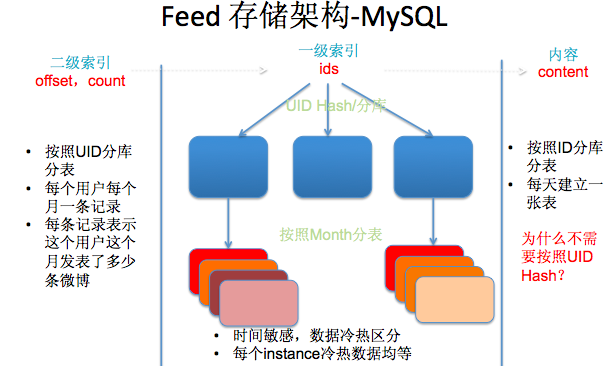
我們來看一下 Feed 的存 儲 架構,微博的博文主要存在MySQL中。首先來看內容表,這個比較簡單,每條內容一個索引,每天建一張表,其次看索引表,一共建了兩級索引。首先想象一下使用者場景,大部分使用者刷微博的時候,看的是他關注所有人的微博,然後按時間來排序。仔細分析發現在這個場景下, 跟一個使用者的自己的相關性很小了。所以在一級索引的時候會先根據關注的使用者,取他們的前條微博ID,然後聚合排序。我們在做雜湊(分庫分表)的時候,同時考慮了按照UID雜湊和按照時間維度。很業務和時間相關性很高的,今天的熱點新聞,明天就沒熱度了,資料的冷熱非常明顯,這種場景就需要按照時間維度做分表,首先冷熱資料做了分離(可以對冷熱資料採用不同的儲存方案來降低成本),其次, 很容止控制我資料庫表的爆炸。像微博如果只按照使用者維度區分,那麼這個使用者所有資料都在一張表裡,這張表就是無限增長的,時間長了查詢會越來越慢。二級索引,是我們裡面一個比較特殊的場景,就是我要快速找到這個人所要釋出的某一時段的微博時,通過二級索引快速定位。
分散式服務追蹤系統
分散式追蹤服務系統,當系統到千萬級以後的時候,越來越龐雜,所解決的問題更偏向穩定性,效能和監控。剛才說使用者只要有一個請求過來,你可以依賴你的服務RPC1、RPC2,你會發現RPC2又依賴RPC3、RPC4。分散式服務的時候一個痛點,就是說一個請求從使用者過來之後,在後臺不同的機器之間不停的呼叫並返回。
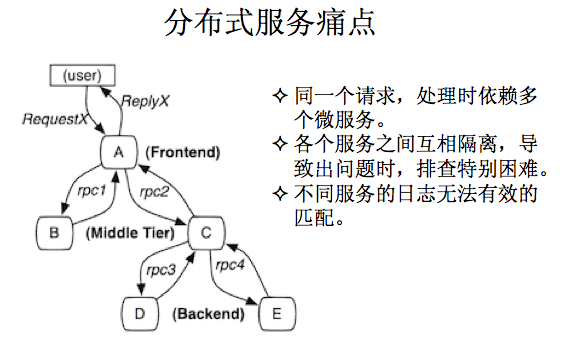
當你發現一個問題的時候,這些日誌落在不同的機器上,你也不知道問題到底出在哪兒,各個服務之間互相隔離,互相之間沒有建立關聯。所以導致排查問題基本沒有任何手段,就是出了問題沒法兒解決。
我們要解決的問題,我們剛才說日誌互相隔離,我們就要把它建立聯絡。建立聯絡我們就有一個請求ID,然後結合RPC框架, 服務治理功能。假設請求從客戶端過來,其中包含一個ID 101,到服務A時仍然帶有ID 101,然後呼叫RPC1的時候也會標識這是101 ,所以需要 一個唯一的 請求 ID 標識 遞迴迭代的傳遞到每一個 相關 節點。第二個,你做的時候,你不能說每個地方都加,對業務系統來說需要一個框架來完成這個工作, 這 個框架要 對業務 系 統 是最低侵入原 則 , 用 JAVA 的 話 就可以用 AOP,要做到零侵入的原則,就是對所有相關的中介軟體打點,從介面層元件(HTTP Client、HTTP Server)至到服務層元件(RPC Client、RPC Server),還有資料訪問中介軟體的,這樣業務系統只需要少量的配置資訊就可以實現全鏈路監控 。為什麼要用日誌?服務化以後,每個服務可以用不同的開發語言, 考慮多種開發語言的相容性 , 內部定 義標 準化的日誌 是唯一且有效的辦法。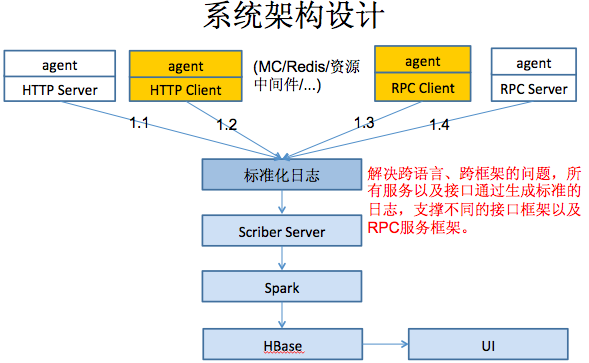
最後,如何構建基於GPS導航的路況監控?我們剛才講分散式服務追蹤。分散式服務追蹤能解決的問題, 如果 單一用 戶發現問題 後 , 可以通 過請 求 ID 快速找到 發 生 問
題 的 節 點在什麼,但是並沒有解決如何發現問題。我們看現實中比較容易理解的道路監控,每輛車有GPS定位,我想看北京哪兒擁堵的時候,怎麼做? 第一個 , 你肯定要知
道每個 車 在什麼位置,它走到哪兒了。其實可以說每個車上只要有一個標識,加上每一次流動的資訊,就可以看到每個車流的位置和方向。 其次如何做 監 控和 報 警,我們怎麼能瞭解道路的流量狀況和負載,並及時報警。我們要定義這條街道多寬多高,單位時間可以通行多少輛車,這就是道路的容量。有了道路容量,再有道路的實時流量,我們就可以基於實習路況做預警?
對應於 分散式系 統 的話如何構建? 第一 , 你要 定義 每個服 務節 點它的 SLA A 是多少 ?SLA可以從系統的CPU佔用率、記憶體佔用率、磁碟佔用率、QPS請求數等來定義,相當於定義系統的容量。 第二個 , 統計 線 上 動態 的流量,你要知道服務的平均QPS、最低QPS和最大QPS,有了流量和容量,就可以對系統做全面的監控和報警。
剛才講的是理論,實際情況肯定比這個複雜。微博在春節的時候做許多活動,必須保障系統穩定,理論上你只要定義容量和流量就可以。但實際遠遠不行,為什麼?有技術的因素,有人為的因素,因為不同的開發定義的流量和容量指標有主觀性,很難全域性量化標準,所以真正流量來了以後,你預先評估的系統瓶頸往往不正確。實際中我們在春節前主要採取了三個措施:第一,最簡單的就是有降 級 的 預 案,流量超過系統容量後,先把哪些功能砍掉,需要有明確的優先順序 。第二個, 線上全鏈路壓測,就是把現在的流量放大到我們平常流量的五倍甚至十倍(比如下線一半的伺服器,縮容而不是擴容),看看系統瓶頸最先發生在哪裡。我們之前有一些例子,推測系統資料庫會先出現瓶頸,但是實測發現是前端的程式先遇到瓶頸。第三,搭建線上 Docker 叢集 , 所有業務共享備用的 Docker叢集資源,這樣可以極大的避免每個業務都預留資源,但是實際上流量沒有增長造成的浪費。
總結

接下來說的是如何不停的學習和提升,這裡以Java語言為例,首先, 一定要 理解 JAVA;第二步,JAVA完了以後,一定要 理 解 JVM;其次,還要 理解 作業系統;再次還是要了解一下 Design Pattern,這將告訴你怎麼把過去的經驗抽象沉澱供將來借鑑;還要學習 TCP/IP、 分散式系 統、資料結構和演算法。
最後就是我想說的就是今天我所說的可能一切都是錯的!大家通過不停的學習、練習和總結, 形成自己的一套架構設計原則和方法,謝謝大家。