Linux 核心學習筆記-磁碟篇

本文將分三部分來記錄 Linux 核心磁碟相關的知識,分別是虛擬檔案系統 VFS、塊裝置層以及檔案系統。
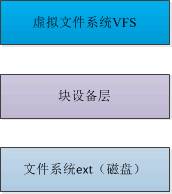
三者的簡要關係如下,如圖所示,檔案系統位於磁碟上,對磁碟上的檔案進行組織和管理,塊裝置層可以理解為塊裝置的抽象,而虛擬檔案系統VFS是對檔案系統的一層抽象,下面先從底層的檔案系統說起。
1 檔案系統
Linux 支援的檔案系統有幾十種,但是 ext 檔案系統使用的最為廣泛,目前 ext 檔案系統族有 ext2、ext3 和 ext4,而 ext2 又是 ext 檔案系統的基礎,所以本文將以 ext2 為例來講解 ext 檔案系統族。
ext2 檔案系統是基於塊裝置的檔案系統,它將硬碟劃分為若干個塊,每個塊的長度都相同,一個檔案佔用的儲存空間是塊長度的整數倍,即一個塊不能用來儲存兩個檔案。
ext2 由大量的塊組組成,塊組的結構如下圖:

而整個硬碟的結構可以用下圖表示:

啟動塊是系統在啟動時,由 BIOS 自動載入並執行,它包含一個啟動裝載程式,通常位於硬碟的起始處,檔案系統是從啟動塊之後開始的。下面來了解塊組中各個部分的構成。
1.1 超級塊
超級塊儲存的資訊包括空閒和已使用的塊的數目、塊長度、當前檔案系統的狀態、各種時間戳,標識檔案系統型別的魔數,每個塊組中儲存的超級塊內容都是相同的,這樣做是為了在系統崩潰損壞超級塊的情況下,有其他副本可以用來恢復資料。
struct ext2_super_block{
__le32 s_inodes_count; /*inode資料*/
__le32 s_blocks_count; /*塊數目*/
__le32 s_r_blocks_count; /* 已分配塊的數目*/
__le32 s_free_blocks_count; /*空閒塊數目*/
__le32 s_free_inodes_count; /*空閒inode數目*/
__le32 s_first_data_block; /*第一個資料塊*/
__le32 s_log_block_size; /*塊長度*/
__le32 s_log_frag_size; /*碎片長度*/
__le32 s_blocks_per_group; /*每個塊組包含的塊數*/
__le32 s_frags_per_group; /*每個塊組包含的碎片*/
__le32 s_inodes_per_group; /*每個塊組的inode數目*/
__le32 s_mtime; /*裝載時間*/
__le32 s_wtime; /*寫入時間*/
__le16 s_mnt_count; /*裝載計數*/
__le16 s_max_mnt_count; /*最大裝載計數*/
__le16 s_magic; /*魔數,標記檔案系統型別*/
…………
}超級塊的儲存結構主要包括以上部分,下面解釋關鍵欄位。
- s_log_block_size:用來表示塊的長度,取值為 0、1 和 2,分別對應的塊長度為 1024、2048 和 4096,塊長度是由 mke2fs 建立檔案系統期間指定,建立後,就不能修改
- s_block_per_group和s_inodes_per_group:每個塊組中塊和 inode 的數量,建立檔案系統時確定。
- s_magic:儲存的是 0XEF53,用來標識 ext2 檔案系統
1.2 組描述符
組描述符反映了檔案系統中各個塊組的狀態,例如塊組中的空閒塊和 inode 數目,每個塊組都包含了檔案系統中所有塊組的組描述資訊,其資料結構如下:
struct ext2_group_desc{ __le32 bg_block_bitmap; /*塊點陣圖塊*/ __le32 bg_inode_bitmap; /*inode點陣圖塊*/ __le32 bg_inode_table; /*inode表塊*/ __le16 bg_free_blocks_count; /*空閒塊數目*/ __le16 bg_free_inodes_count; /*空閒inode數目*/ __le16 bg_used_dirs_count; /*目錄數目*/ __le16 bg_pad; __le32 bg_reserved[3]; }
1.3 資料塊點陣圖和 inode 點陣圖
點陣圖是儲存長的位元位串,該結構中每個位元位都對應於一個資料塊或 inode,用來標識對應的資料塊或 inode 是空閒還是被使用。總是佔用一個資料塊。
1.4 inode 表
inode 表包含了塊組中所有的 inode,inode 包含了檔案的屬性和對應的資料塊的標號,inode 的資料結構如下:
struct ext2_inode{ __le16 i_mode; /*檔案模式*/ __le16 i_uid; /*所有者UID的低16位*/ __le32 i_size; /*長度,按位元組計算*/ __le32 i_atime; /*訪問時間*/ __le32 i_ctime; /*建立時間*/ __le32 i_mtime; /*修改時間*/ __le32 i_dtime; /*刪除時間*/ __le16 i_gid; /*組ID的低16位*/ __le16 i_links_count; /*連結計數*/ __le32 i_blocks; /*塊數目*/ __le32 i_flags; /*檔案標誌*/ uion{ …… }masix1; __le32 i_blocks[EXT2_N_BLOCKS]; /*塊指標*/ __le32 i_generation; /*檔案版本,用於NFS*/ ………… }
- i_mode:訪問許可權
- i_size和i_block:分別以位元組和塊為單位指定了檔案的長度,需要注意的是,這裡總是假定塊的大小是 512 位元組(和檔案系統實際使用的塊大小沒有關係)
- i_blocks:儲存資料塊的標號的陣列,陣列長度為 EXT2_N_BLOCKS,其預設值是 12+3
- i_link_count:統計硬連結的計數器
- 每個塊組的 inode 數量也是由檔案系統建立時設定,預設的設定是 128
1.5 資料塊
資料塊儲存的是檔案的有用資料。
知識點 1:inode 中儲存了檔案佔用的資料塊的編號,那麼 inode 是怎麼儲存資料塊的編碼的?
對於一個 700MB 的檔案,如果資料塊的長度是 4KB,那麼需要 175000 個資料塊,而 inode 需要用 175000*4 個位元組來儲存所有的塊號資訊,這就需要耗費大量的磁碟空間來儲存 inode 資訊,更重要的是大多數檔案都不需要儲存這麼多塊號。

Linux 使用間接儲存的方案來解決這個問題,上圖表示了簡單間接和二次間接,inode 本身會儲存 15 個資料塊的標號,其中 12 個直接指向對應的資料塊,當檔案需要的資料塊超過 12 個時,就需要使用間接,間接指向的資料塊,用來儲存資料塊的標號,而不會儲存檔案資料,同理,當一次間接還不夠用時,就需要二次間接,ext2 最高提供三次間接,這樣我們就很容易算出檔案系統支援的最大檔案長度。
| 塊長度 | 最大檔案長度 |
|---|---|
| 1024 | 16GB |
| 2048 | 256GB |
| 4096 | 2TB |
知識點2:將分割槽分為多個塊組有什麼好處?
檔案系統會試圖把檔案儲存到同一個塊組中,以最小化磁頭在 inode、塊點陣圖和資料塊之間尋道的代價,這樣可以顯著提高磁碟訪問速度
知識點3:目錄是怎麼儲存的?
目錄本身也是檔案,其同樣是有 inode 和對應的資料塊,只不過資料塊上存放的是描述目錄項的的結構,其定義如下。
struct ext2_dir_entry_2{
__le32 inode;
__le16 rec_len;
__u8 name_len;
__u8 file_type;
char name[EXT2_NAME_LEN];
};- file_type:指定了目錄的型別,常用的值有 EXT2_FT_REG_FILE 和 EXT2_FT_DIR,分別用來標識檔案和目錄。
- rec_len:表示從 rec_len 欄位末尾到下一個 rec_len 欄位末尾的偏移量,單位是位元組,對於刪除的檔案和目錄,不用刪除對應的資料,只需要修改 rec_len 的值就可以,用來有效地掃描檔案目錄。
對於檔案系統的建立載入,以及資料塊的讀取和建立,以及預分配等細節,這裡不再贅述。
2 塊裝置層
塊裝置有一下幾個特點:
- 可以在資料中的任何位置進行訪問
- 資料總是以固定長度塊進行傳輸
- 對塊裝置的訪問有大規模的快取
需要注意是,這裡提到的塊和上文 ext2 檔案系統的塊概念是一樣。塊的最大長度受記憶體頁的長度限制。另外,我們知道磁碟還有一個概念是扇區,它表示磁碟讀寫的最小單位,通常是 512 個位元組,塊是扇區的整數倍。
塊裝置層是一個抽象層,用來提高磁碟的讀寫效率,使用請求佇列,來快取並重排讀寫資料塊的請求,同時提供預讀的功能,提供快取來儲存預讀取的內容。因此下文將重點介紹請求佇列以及排程策略。
2.1 請求佇列
請求佇列是一個儲存了 I/O 請求的雙向連結串列,下面來看錶示 I/O 請求的資料結構。
struct request{
struct list_head queuelist;
struct list_head_donelist;
struct request_queue *q;
unsigned int cmd_flags;
enum rq_cmd_type_bits cmd_type;
...
sector_t sector; /*需要傳輸的下一個扇區號*/
sector_t hard_sector; /*需要傳輸的下一個扇區號*/
unsigned long nr_sectors; /*還需要傳輸的扇區數目*/
unsigned long hard_nr_sectors; /*還需要傳輸的扇區數目*/
unsigned long current_nr_secotrs; /*當前段中還需要傳輸的扇區數目*/
struct bio *bio;
struct bio *biotail;
...
void *elevator_private;
void *elevator_private2;
...
};
該結構有3個成員可以指定所需傳輸資料的準確位置。
- sector:指定了資料傳輸的起始扇區
- current_nr_sectors:當前請求在當前段中還需要傳輸的扇區數目
- nr_sectors:當前請求還需要傳輸的扇區數目
其中的 bio 和 biotail 欄位涉及到另外一個概念 BIO,下面來詳述。
2.2 BIO
BIO 用於在系統和裝置之間傳輸資料,其結構如下,主要關聯到了一個陣列上,陣列項則指向一個記憶體頁。
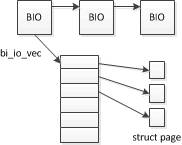
BIO 的資料結構如下:
struct bio{
sector_t bi_sector;
struct bio *bi_next; /*將與請求關聯的幾個BIO組織到一個單連結串列中*/
...
unsigned short bi_vcnt; /*bio_vec的數目*/
unsigned short bi_idx; /*bi_io_vec陣列中,當前處理陣列項的索引*/
unsigned short bi_phys_segments;
unsigned short bi_hw_segments;
unsigned int bi_size; /*剩餘IO資料量*/
struct bio_vec *bi_io_vec; /*實際的bio_vec陣列*/
bio_end_io_t *bi_end_io;
void *bi_private;
};大體上,核心在提交請求時,可以分兩步:
- 首先建立一個 BIO 例項以描述請求,然後請求的 bio 欄位指向建立的 BIO 例項,並把請求置於請求佇列上
- 核心處理請求佇列並執行 BIO 中的操作。
2.3 請求插入佇列
核心使用佇列插入機制,來有意阻止請求的處理,請求佇列可能處於空閒狀態或者插入狀態,如果佇列處於空閒狀態,佇列中等待的請求將會被處理,否則,新的請求只是新增到佇列,但並不處理。
2.4 I/O 排程
排程和重排 I/O 操作的演算法,稱之為 I/O 排程器,也稱為電梯 ,目前常用的排程演算法有:
- noop:按照先來先服務的原則一次新增到佇列,請求會進行合併當無法重排
- deadline:試圖最小化磁碟尋道的次數,並儘可能確保請求在一定時間內完成
- as:預測排程器,會盡可能預測程序的行為。
- cfq:完全公平排隊,時間片會分配到每個佇列,核心使用一個輪轉演算法來處理各個佇列,確保了 I/O 頻寬以公平的方式在不同佇列之間共享。
3 虛擬檔案系統
VFS 是對檔案系統的一層抽象,來遮蔽各種檔案系統的差異,對於 VFS 來說,其主要操作的物件依然是 inode,這裡需要注意的是,記憶體中的 inode 結構和磁碟上檔案系統中的 inode 結構稍有不同。其包含了一些磁碟上 inode 沒有的成員。
3.1 inode
VFS 中 inode 結構如下:
struct inode{
struct hlist_node ihash;
struct list_head i_list;
struct list_head i_sb_list;
struct list_head i_dentry;
...
loff_t i_size;
...
unsigned int i_blkbits;
blkcnt_t i_blocks;
umode_t i_mode;
...
};inode 中沒有儲存檔名,而檔名儲存在目錄項 dentry 中,因此,如果應用層需要開啟一個給定的檔名,就需要先查詢其 dentry,找其對應的 inode,從而找到它在磁碟上的儲存位置。
3.2 dentry
struct dentry{
atomic_t d_count;
unsigned int d_flags; /*由d_lock保護*/
spinlock_t d_lock; /*每個dentry的鎖*/
struct inode *d_inode; /*檔名所屬的inode,如果為NULL,則標識不存在的檔名*/
struct hlist_node d_hash; /*用於查詢的雜湊表*
struct dentry *d_parent; /*父目錄的dentry例項*/
struct qstr d_name;
...
unsigned char d_iname[DNAME_INLINE_LEN_MIN] /*短檔名儲存在這裡*/
};上文提到,dentry 的主要用途是建立檔名和 inode 的關聯,其中有 3 個重要欄位:
- d_inode:指向相關 inode 例項的指標,d_entry 還可以為不存在的檔名建立,這時 d_inode 為 NULL 指標,這有助於查詢不存在的檔名
- d_name:指定了檔案的名稱
- d_iname:如果檔名有少量字元組成,則儲存在該欄位,以加速訪問
由於塊裝置的訪問速度較慢,為了加速 dentry 的查詢,核心使用 dentry 快取來加速其查詢。而 dentry 快取在記憶體中的組織形式如下:
- 一個雜湊表:包含了所有的 dentry 物件
- 一個 LRU 連結串列:不再使用的物件將授予一個最後寬限期,寬限期過後才從記憶體移除。
對於 VFS 來說,主要的一個工作是查詢 inode,下面就介紹 inode 的查詢流程。
首先呼叫 __link_path_walk 來進行許可權檢查然後主要的邏輯在 do_lookup 中實現。
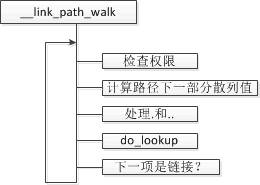
do_lookup 始於一個路徑分量,最終返回一個和帶查詢檔名相關的 inode。
- 去 dentry 快取中查詢 inode,如果查詢到,仍會呼叫檔案系統的 d_revalidate 函式來檢查快取是否有效
- 呼叫 read_lookup 執行特定於檔案系統的查詢操作
3.3 開啟檔案
對於應用程式來說,通常會呼叫 open 系統函式來開啟一個檔案,下面就看下核心處理 open 的流程。
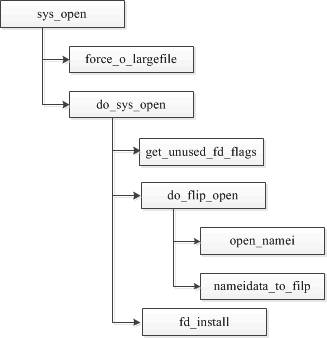
- 首先檢查 force_o_largefile 設定
- 找到一個可用的檔案描述符
- open_namei 呼叫 path_lookup 函式查詢 inode
- 將建立的 file 例項放置到 s_files 連結串列上
- 將file例項放置到程序 task_struct 的 file->fd 陣列中
- 返回到使用者層
總結
核心有關磁碟的實現錯綜複雜,本文試圖透過介紹一些關鍵的概念:ext 檔案系統、inode、dentry、BIO 等,讓大家瞭解核心實現磁碟 I/O 的主要原理。本文屬於讀書筆記,如果有疑問的地方 ,可以直接參閱《深入Linux核心架構》。
(題圖:Pixabay,CC0)
相關文章
- Android 學習筆記核心篇Android筆記
- 磁碟管理--學習筆記筆記
- 【Linux】核心學習筆記(一)——程序管理Linux筆記
- Linux核心學習筆記(5)– 程式排程概述Linux筆記
- JVM核心學習筆記JVM筆記
- Linux 學習筆記Linux筆記
- 【學習筆記】HTML篇筆記HTML
- 《Linux核心完全註釋》學習筆記:2.7 Linux核心原始碼的目錄結構Linux筆記原始碼
- Linux學習筆記(第十二篇)網路基礎Linux筆記
- Linux 學習筆記--程式Linux筆記
- webpack 學習筆記:核心概念(上)Web筆記
- webpack 學習筆記:核心概念(下)Web筆記
- elasticsearch學習筆記一:核心概念Elasticsearch筆記
- Android 學習筆記思考篇Android筆記
- Linux 核心配置筆記Linux筆記
- Linux 筆記分享六:磁碟管理Linux筆記
- Linux基礎學習-Docker學習筆記LinuxDocker筆記
- 【Linux學習筆記】reboot命令Linux筆記boot
- Linux 學習筆記--程式管理Linux筆記
- JAVA核心技術學習筆記--反射Java筆記反射
- swoft 學習筆記之 response 篇筆記
- Python學習筆記(語法篇)Python筆記
- pandas 學習筆記 (入門篇)筆記
- MySQL學習筆記【基礎篇】MySql筆記
- Vue學習筆記之路由篇Vue筆記路由
- Android 學習筆記架構篇Android筆記架構
- Mysql學習筆記(安裝篇)MySql筆記
- Linux學習/TCP程式設計學習筆記LinuxTCP程式設計筆記
- linux學習筆記---一些命令學習Linux筆記
- Linux筆記 篇(二)Linux筆記
- Spring Boot學習筆記:Spring Boot核心配置Spring Boot筆記
- 基礎 IO (Linux學習筆記)Linux筆記
- Linux學習筆記(2)——ls指令Linux筆記
- 01_Linux學習筆記(一)Linux筆記
- Linux與DNS的學習筆記LinuxDNS筆記
- linux學習筆記-day5Linux筆記
- TCP學習筆記(二) 相識篇TCP筆記
- MongDB學習筆記(一) 初遇篇筆記
- CSS學習筆記——傳統定位篇CSS筆記