使用 Linux/Unix 進行文字處理

正規表示式
翻譯領域不乏讓人摸不著頭腦的詞彙,比如“控制程式碼”、“套接字”、“魯棒性”。當然,“正規表示式”也屬於這一類詞彙。我剛接觸正規表示式的時候,對這個名詞感到非常迷惑。深入瞭解之後,才突然明白,原來所謂的 regular expression, 其實就是“有規律、有模式的字串”而已。
很少有一門技術,只需要投入少量的學習成本即可獲得巨大的價值回報。正規表示式就屬於這一類技術。可惜很多人被它密碼般的語法形式當頭棒喝,甚至連門都不得而入。
為什麼你應該學習正規表示式?其一,在實踐中應用這門技術其實不難,只需理解為數不多的幾個元字元以及並不複雜的語法,就能夠獲得強大的文字操控能力;其二,正規表示式往往能提供處理文字的最簡單最高效的解決方法(有時也許是唯一的解法)。遇上覆雜的情況,如果你不會正規表示式,就只好束手無策、黯然神傷了。
正規表示式入門容易,精通卻難。本文並不打算挑戰此項任務,如果你希望系統地學習正規表示式,請一定閱讀 Jeffrey Friedl 的著作 精通正規表示式。
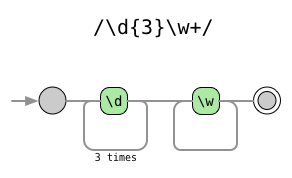
正規表示式
文字檢索
grep 命令可以完成簡單的文字搜尋任務。
先來準備一份文字材料,把 grep 的幫助頁儲存為文字檔案:
> man grep | col -b > grephelp.txt下面,我想檢索 grephelp.txt 檔案中所有包含 "find" 這個單詞的文字行:
> grep "find" grephelp.txt
To find all occurrences of the word `patricia' in a file:
To find all occurrences of the pattern `.Pp' at the beginning of a line:
To find all lines in a file which do not contain the words `foo' or我希望匹配到的文字使用不同的顏色顯示,可以新增 --color 選項,預設的顏色是紅色。
> grep --color "find" grephelp.txt我希望在匹配結果中顯示檔名和行號,使用 -H 選項可以顯示檔名,使用 -n 選項可以顯示行號:
> grep -H -n --color "find" grephelp.txt
grephelp.txt:252: To find all occurrences of the word `patricia' in a file:
grephelp.txt:256: To find all occurrences of the pattern `.Pp' at the beginning of a line:
grephelp.txt:265: To find all lines in a file which do not contain the words `foo' or很多時候,我們需要知道匹配行前後的上下文。-A 和 -B 這兩個選項會是你的好朋友。-A n 表示顯示匹配行以及其後的 n 行;-B n 表示顯示匹配行以及之前的 n 行。現在,我們在匹配行的前後分別額外顯示兩行:
> grep -A 2 -B 2 -H -n --color "find" grephelp.txt
grephelp.txt-250-
grephelp.txt-251-EXAMPLES
grephelp.txt:252: To find all occurrences of the word `patricia' in a file:
grephelp.txt-253-
grephelp.txt-254- $ grep 'patricia' myfile
--
--
grephelp.txt-254- $ grep 'patricia' myfile
grephelp.txt-255-
grephelp.txt:256: To find all occurrences of the pattern `.Pp' at the beginning of a line:
grephelp.txt-257-
grephelp.txt-258- $ grep '^\.Pp' myfile
--
--
grephelp.txt-263- match any character.
grephelp.txt-264-
grephelp.txt:265: To find all lines in a file which do not contain the words `foo' or
grephelp.txt-266- `bar':
grephelp.txt-267-如果需要查詢所有不包含 "find" 的文字行,該怎麼做呢?很簡單,使用 -v 選項即可。
grep 還有兩個變體,egrep 和 fgrep。相對於僅支援基本正則模式(BREs)的 grep 來說,egrep 支援擴充套件正則模式(EREs),因而檢索能力更為強大;fgrep 是所有三個工具中速度最快的一個,因為它完全不支援正則模式。
其實,我更喜歡一個叫做 ack 的工具。
ack
文字替換
tr 命令可以完成簡單的字元轉換任務。例如,可以透過 tr 把 grephelp.txt 檔案轉換為全文大寫:
> cat grephelp.txt | tr '[:lower:]' '[:upper:]'簡而言之,tr 的工作就是把第一個集合中的字元轉換為第二個集合中的相應的字元。常用的字符集合有下面這些:
[:alnum:]:字母數字[:alpha:]:字母[:cntrl:]:控制字元[:digit:]:數字[:graph:]: 圖形字元[:lower:]:小寫字母[:print:]:可列印字元[:punct:]:標點符號[:space:]:空白字元[:upper:]:大寫字母[:xdigit:]:十六進位制數字
tr 命令的應用場景非常受限,如果希望進行更加靈活的模式替換,我們還有 sed(也就是 stream editor,流編輯器)。
把檔案中所有的 "find" 文字替換為 "search":
> sed "s/find/search/g" grephelp.txt這條命令中,s 表示執行“替換操作”,/find/search/ 表示把 "find" 替換為 "search",g 表示對一行中所有的匹配進行替換。sed 預設把處理結果列印到標準輸出,我們可以透過重定向把處理結果轉儲到一個新檔案中,或者使用選項 -i 把結果直接寫回原檔案(有風險,需謹慎):
> sed -i "s/find/search/g" grephelp.txt把檔案中所有的數字 n 替換為 "--n--" 的形式:
> sed -E "s/([0-9]+)/--\1--/g" grephelp.txt選項 -E 表示在處理過程中使用擴充套件的正則模式(EREs),替換命令中的 \1 表示引用正規表示式的第一個捕獲分組。請注意,-E 這個選項只在 Mac OS X 系統和 FreeBSD 系統上有效,其他 Unix 系統需要使用另一個等效的選項 -r。
sed 的功能遠不止這一些,篇幅所限,不可能詳細講解 sed 的用法。如果希望學習更多,請移步這篇文章。
文字去重
> cat -n sonnet116.txt
1 Let me not to the marriage of true minds
2 Admit impediments. Love is not love
3 Which alters when it alteration finds,
4 Or bends with the remover to remove:
5 O, no! it is an ever-fix`ed mark,
6 O, no! it is an ever-fix`ed mark,
7 That looks on tempests and is never shaken;
8 It is the star to every wand'ring bark,
9 Whose worth's unknown, although his heighth be taken.
10 Love's not Time's fool, though rosy lips and cheeks
11 Love's not Time's fool, though rosy lips and cheeks
12 Love's not Time's fool, though rosy lips and cheeks
13 Within his bending sickle's compass come;
14 Love alters not with his brief hours and weeks,
15 But bears it out even to the edge of doom:
16 If this be error and upon me proved,
17 I never writ, nor no man ever loved.這是莎士比亞的一首十四行詩,只可惜第5行和第10行有重複(而且第10行重複了3次)。怎麼檢視文字中重複的行呢?uniq 命令可以幫助你。
> uniq -d sonnet116.txt
O, no! it is an ever-fix`ed mark,
Love's not Time's fool, though rosy lips and cheeks選項 -d 表示僅輸出重複的行。如果需要去重,使用不帶選項的 uniq 命令就可以了:
> uniq sonnet116.txt
Let me not to the marriage of true minds
Admit impediments. Love is not love
Which alters when it alteration finds,
Or bends with the remover to remove:
O, no! it is an ever-fix`ed mark,
That looks on tempests and is never shaken;
It is the star to every wand'ring bark,
Whose worth's unknown, although his heighth be taken.
Love's not Time's fool, though rosy lips and cheeks
Within his bending sickle's compass come;
Love alters not with his brief hours and weeks,
But bears it out even to the edge of doom:
If this be error and upon me proved,
I never writ, nor no man ever loved.想要檢視每一行究竟重複了多少次?沒問題,使用選項 -c:
> uniq -c sonnet116.txt
1 Let me not to the marriage of true minds
1 Admit impediments. Love is not love
1 Which alters when it alteration finds,
1 Or bends with the remover to remove:
2 O, no! it is an ever-fix`ed mark,
1 That looks on tempests and is never shaken;
1 It is the star to every wand'ring bark,
1 Whose worth's unknown, although his heighth be taken.
3 Love's not Time's fool, though rosy lips and cheeks
1 Within his bending sickle's compass come;
1 Love alters not with his brief hours and weeks,
1 But bears it out even to the edge of doom:
1 If this be error and upon me proved,
1 I never writ, nor no man ever loved.文字排序
假設有這樣一個報表檔案,第一列是月份,第二列是當月的銷售個數:
> cat report.txt
March,19
June,50
February,17
May,18
August,16
April,31
May,18
July,26
January,24
August,16這個檔案的內容不僅順序是亂的,而且還有重複。我希望按字母表順序排序,可以下面這個命令:
> sort report.txt
April,31
August,16
August,16
February,17
January,24
July,26
June,50
March,19
May,18
May,18選項 -u (表示 unique)可以在排序結果中去除重複行:
> sort -u report.txt
April,31
August,16
February,17
January,24
July,26
June,50
March,19
May,18能不能按照月份排序呢?選項 -M (表示 month-sort)可以幫助我們:
> sort -u -M report.txt
January,24
February,17
March,19
April,31
May,18
June,50
July,26
August,16按照第二列的數字進行排序也是很簡單的:
> sort -u -t',' -k2 report.txt
August,16
February,17
May,18
March,19
January,24
July,26
April,31
June,50上面的例子中,選項 -t',' 表示以逗號為分隔符對文字進行列分割;-k2 表示對第2列進行排序。
當然了,把結果逆序排列也並非不可能:
> sort -u -r -t',' -k2 report.txt
June,50
April,31
July,26
January,24
March,19
May,18
February,17
August,16文字統計
wc 命令用來完成文字統計工作,透過使用不同的選項,它可以統計檔案中的位元組數(-c),字元數(-m),單詞數(-w)與行數(-l)。
例如,檢視 grephelp.txt 這個檔案總共有多少個單詞:
> wc -w grephelp.txt
1571 grephelp.txt檢視 sonnet116.txt 這個檔案總共有多少不重複的行(廢話,十四行詩當然是有14行):
> uniq sonnet116.tx6 | wc -l
14你還應該試試 Awk 與 Perl
如果上面介紹的工具仍然不能滿足你,也許你需要火力更強的武器。試試 Awk 與 Perl 吧。
Awk 也是一款上古神器,它的年齡可能和 sed 不相上下。Awk 可謂是專門為了文字處理而生,它的語法和特性非常適合用於操縱文字和生成報表。如需學習,請參考 這篇文章,你會喜歡上它的。
長久以來,Perl 揹負了“只寫語言”的惡名。實際上,只要處理得當,用 Perl 一樣可以寫出模組清晰的、容易閱讀和理解的程式碼。根據我的經驗,使用 Perl 的場合 80% 以上與文字處理有關。Perl 內建的正規表示式支援可能是所有語言中最好的,再加上簡潔緊湊的語法以及便利的運算子,這些特性幫助 Perl 成了文字處理領域當仁不讓的霸主。
相關文章
- 在 Linux/Unix 中文字處理方式總結Linux
- 在Linux中,如何使用awk和sed進行文字處理?Linux
- Linux文字處理命令sed基本使用示例Linux
- Linux文字處理命令Linux
- 使用 canvas 對影象進行處理Canvas
- 使用 getopt() 進行命令列處理命令列
- Linux文字處理技巧分享Linux
- Linux文字處理命令(轉)Linux
- .NET使用MailKit進行郵件處理AI
- Linux文字處理詳細教程Linux
- Linux中文字處理命令sed的使用示例分享Linux
- 使用Preprocessor前處理器語句對外部表進行介入處理
- LINUX學習(五)Linux文字處理命令Linux
- linux下的文字處理命令sedLinux
- 如何使用awk處理文字內容
- VIM 進階 —— 《VIM 8 文字處理實戰》
- excel檔案怎麼使用php進行處理ExcelPHP
- 使用Spark和Cassandra進行資料處理(一)Spark
- 使用JavaScript進行基本圖形操作與處理JavaScript
- Linux檔案管理知識:文字處理Linux
- 使用python進行簡單的媒體處理Python
- 使用matlab對影像進行二值化處理Matlab
- 使用aop來監控方法進行增強處理
- 使用HttpURLConnection訪問介面進行資料處理HTTP
- 在 NASA 使用開源工具進行影像處理開源工具
- oracle windows下使用批處理進行exp匯出OracleWindows
- UNIX的檔案處理(轉)
- Linux Shell程式設計(23)——文字處理命令Linux程式設計
- 如何使用卷積神經網路進行影像處理?卷積神經網路
- 使用 WebSphere Business Events V6.1 進行業務事件處理Web行業事件
- Ajax 處理時進度條使用
- 使用 Python+spaCy 進行簡易自然語言處理Python自然語言處理
- 使用Spring Boot + Redis 進行實時流處理 - vinsguruSpring BootRedis
- Flutter 中使用 OpenAI GPT-3 進行語義化處理FlutterOpenAIGPT
- 使用 scipy.fft 進行Fourier Transform:Python 訊號處理FFTORMPython
- 海量資料處理_使用外部表進行資料遷移
- WebSphere Business Events 進行業務事件處理Web行業事件
- 全棧 - 17 NLP 使用jieba分詞處理文字全棧Jieba分詞