準備寫點扯淡些的部落格,然後想了好半天,終於想到了個稍微有點文藝的標題,不喜勿噴啊,噴著我這裡到處都是就不好拉。。。
一:場景
先說說場景吧,為了不過分暴露業務,就用字母代替下吧,半個月前業務那邊報了個bug,說根據A條件和B條件篩選一批資料,
當把時間(C條件)範圍拉小點,可以篩選出資料,把(C條件)時間拉大點,就沒有資料了。
二:分析
乍一看,泥煤的。。。真的有點神奇哦,0-24點可以拉到資料,0-12點反而就拉不到了,暈。。。。然後就仔細分析了下程式碼,
然來不知道哪一個程式設計師在M庫里根據各種條件篩選出了20條資料,因為B條件在N庫裡面,所以他拿著這20條資料到N庫去做篩選,
結果20條資料全部暴斃,最後就拿著空集合送到前臺了。。。問題泥煤的終於明白了,就是如何根據多條件去做跨伺服器查詢。
三:探索
其實也挺悲劇的,從業快四年了也沒遇到這個問題,雖然在上一家公司資料庫做了主從複製,跨庫,尼瑪的。。。也沒有跨服務
器查詢呀。。。不過那天問題找到後也挺興奮的,轉了轉珠子想了個辦法,用多執行緒搞一搞。。。
四: 失敗的一次嘗試
由於開發人員接觸不了生產,要是查的話還要找二線人員。。。我人又懶,不想郵件啥的通知人家,然後就自己假象了下資料應該
不會超過多少條。。。後來就是因為這個應該導致了該解決方法的失敗。
步驟如下:
①: 我那時假象一天的資料應該不會超過5w吧,為了加速,我準備多開幾個執行緒,一個執行緒撈tmd的5000條資料,5w的話我就開
10個執行緒。10w的話就開20個執行緒,反正執行緒是隨資料變的。
②: 就這樣我分別從M和N庫中撈出來我也不知道多少個OrderID,然後在兩組OrderID裡面求個交集,當然這個要注意了,從資料
結構的角度說,這個需要用hash來去重,複雜度O(M+N),當我看到C#自帶的intersect就是先灌到hash裡面做的,我就放
心了,至少不會出現噁心的O(MN)的複雜度了。。。
③: 求交集後,我現在就拿到一組OrderID了,然後拿這些orderID在記憶體中分頁,取出20條OrderID後再到主庫M中去查真正我需
要的資料,最後把資料送到前臺上。。。

這些想法在我腦子裡面遨遊之後,我就啪啪啪的寫完了程式碼,測試環境下也通過了。。。然後屁顛屁顛的上生產了,就這樣噩夢開始了。。。
過了個星期,業務過來說:這下好了,原先資料查不出來,現在你給我頁面報錯了,我說:暈,不會吧,我馬上去看看。。。查了下後,然來
發現是頁面執行時間過長,iis超時了。。。唉,這下沒法子了,去找二線查了下資料,居然N庫中有26w的資料,那我得要開52個執行緒,暈死,
我不知道當時生產環境的cpu狂飆的有木有。。。苦逼呀。。。還得繼續扣這些猥瑣的程式碼。。。
五: 再次尋找解決方案
1:使用opendatasource跨伺服器查詢
剛才我也寒酸的分析了下5個where,有4個在M庫中,有1個在N庫中,那就用opendatasource來做遠端伺服器的inner join吧。。。
也許是公司為了效能和安全性考慮,禁用了此種使用方式,沒撤,此方案破產。。。
2: 做資料的冗餘
泥煤的,把我逼到絕境了。。。既然跨不了伺服器,那也只能做資料冗餘了,沒辦法,只能在M庫裡面建立一張冗餘表,將N庫中表的數
據導入到這張冗餘表吧,然後我就可以堂堂正正的用sql直接inner join了,問題也就差不多解決了,說幹就幹吧。
<1>事前冗餘
我準備在web端插入資料的時候再冗餘到XX表中,雖然是個過得去的主意,但是web端太多了,你懂的,要是為了這個小功能,要去改動無
數個的web端,工作量有點大了,還不知道人家部門配合不配合。。。而且我的需求也比較特殊,需要等M庫具有某些操作的時候,N庫中的
表才會生成資料,所以該種方案想想還是放棄了。。。

<2>事後冗餘
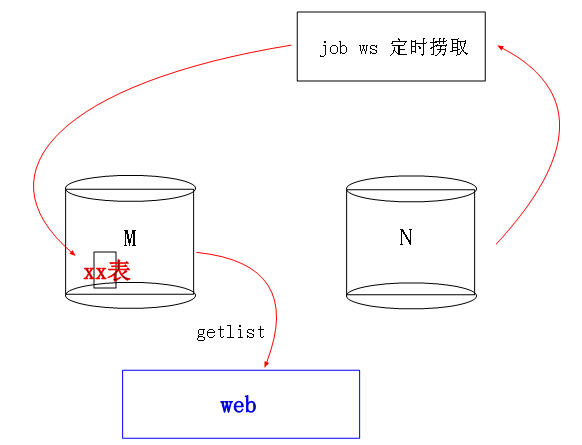
後來還是決定用jobws每個小時去定時撈N庫中的資料,然後放入M庫的冗餘表中,雖然業務那邊看的可能不是最新的一個小時的資料,
但是沒關係,這些資料不需要實時的,只要保證是最近一天的就足夠了,最後也就決定這種可行點了。。。悲劇啊。。。啊啊啊啊啊。。。
突然發現部落格好像沒這麼扯蛋過。。。還好蛋都扯完了,不過這也算是一個非常經典的問題,如果大家有什麼好招數,記得分享分享
啊。。。謝謝了。。。。