Windows cluster要求同一個cluster中的所有windows版本都是相同的,這樣就出現一個問題,當我們要將對windows進行升級時,(例如從windows 2008 R2升級到windows 2012)不得不搭建一套新的windows cluster。你可以選擇使用新的硬體搭建,或者將現有windows cluster中的節點一臺一臺的evict掉,重灌/升級系統後加入到新的windows cluster中。具體的cluster升級方案我就不在這裡討論。馬上進入主題:
SQL Server AlwaysOn Availability Group (後文簡稱為AG) 的一個要求是:所有的replica都要求隸屬於同一個windows cluster。
 所以當我們對windows cluster進行升級時,無法在新的windows cluster和現有的windows cluster之間建立AG。那麼在遷移過程中會有一段時間內AG無法對外提供服務。
所以當我們對windows cluster進行升級時,無法在新的windows cluster和現有的windows cluster之間建立AG。那麼在遷移過程中會有一段時間內AG無法對外提供服務。
從資料庫的角度上說,我們需要做下面的事情
- 接下來停止應用並刪除cluster1中的Listener,確保沒有外界來接使用SQL SERVER.
- Backup database
- Backup tail log
- 將備份檔案copy到新的伺服器
- Restore 到各個伺服器
- 然後重新建立AG
- 建立Listener
- 重啟應用
我們需要將資料庫備份並還原到新的primary replica和secondary replica。 相應的downtime時間就是1+2+3+4+5+6+7+8想要的時間。 或許你想到了在新舊cluster之間建立一個mirroring,但遺憾的是,建立了AG的資料庫是不再允許建立mirroring的.
那應當如何進行遷移呢?從SQL Server 2012 SP1 開始,允許在兩套不同的windows cluster之間建立AG。下面用一個例子說明一下
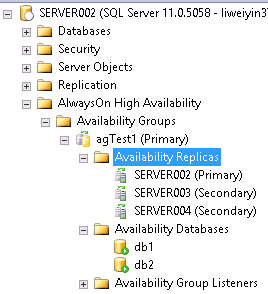
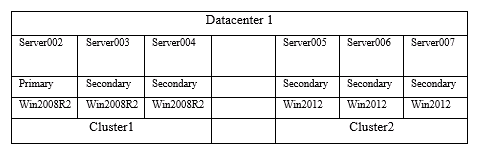
有一個三個節點的windows cluster, windows版本為Windows 2008 R2
Domain:liweiyin3.lab
Cluster name: cluster1
Server002
Server003
Server004
Listener name: Listener1
三個節點上裝有SQL Server 2012 SP1的standalone例項。均為預設例項。
之間建立了AG.拓撲圖如下:

現在建立一套兩個節點的windows 2012的windows cluster
Domain:liweiyin3.lab
Cluster name: cluster2
Server005
Server006
|
Datacenter 1 |
|
|
Server005 |
Server006 |
|
Win 2012 |
Win2012 |
|
Cluster2 |
|
兩個cluster中間建立AG:
- 對cluster1上的AG資料庫進行備份,包含full database backup和log backup
- 將第一步得到的檔案在cluster2的節點上進行還原,指定為with norecovery.
-
接下來在cluster2的三個資料庫上執行下面的語句
ALTER SERVER CONFIGURATION SET HADR CLUSTER CONTEXT='cluster1.liweiyin3.lab'
這條語句執行完畢後,這臺資料庫的cluster context就會切換為cluster1了。這個結果可以從下面的DMV中檢查到
select cluster_name from sys.dm_hadr_cluster

4.接下就可以在cluster1和cluster2之間建立AG。我們可以使用UI或者T-SQL語句。需要注意的是,請將cluster2中的至少一個SQL Server的同步模式設定為Synchronous commit,以保證遷移是沒有資料損失的。

這樣,我們就建立了一套既包含win 2008R2,也包含win 2012的AG環境了。並且也可以正常地向外界提供服務,整個過程不需要downtime.

但需要注意的是,這種情況下是不允許在兩個cluster之間進行failover的。相應的提示資訊如下
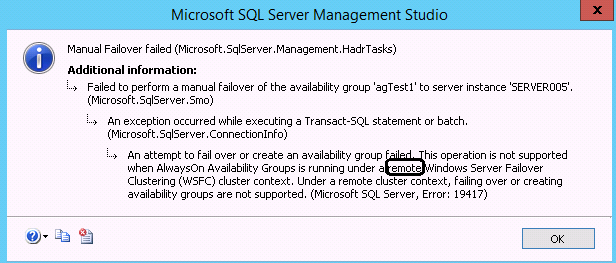 An attempt to fail over or create an availability group failed. This operation is not supported when AlwaysOn Availability Groups is running under a remote Windows Server Failover Clustering (WSFC) cluster context. Under a remote cluster context, failing over or creating availability groups are not supported.
An attempt to fail over or create an availability group failed. This operation is not supported when AlwaysOn Availability Groups is running under a remote Windows Server Failover Clustering (WSFC) cluster context. Under a remote cluster context, failing over or creating availability groups are not supported.
5.接下來停止應用並刪除cluster1中的Listener,確保沒有外界來接使用SQL SERVE
6.在Cluster1將AG進行offline操作
ALTER AVAILABILITY GROUP agName offline
7.將cluster2中所有sql server的CLUSTER CONTEXT切換回來
ALTER SERVER CONFIGURATION SET HADR CLUSTER CONTEXT=local
8.在cluster2中重新建立AG
9.在cluster2中建立新的listener
10.重啟應用
這樣所涉及的downtime就是5+6+7+8+9+10
和之前的解決方案相比,省去了backup,檔案copy和restore的時間。其餘的操作都是句操作,很大程度地減少了downtime。
更多資訊
===
遷移之前,Cluster2中的sql server不允許建立任何AG。
遷移之前需要授予cluster2中的sql server啟動賬號訪問cluster1登錄檔的許可權
在第六步“在Cluster1中將AG進行offline操作”之前在各個AG 資料庫中執行checkpoint,以前少cluster2中資料庫的recovery時間。
對於multiply subnet場景,則需要在各自的子網內建立新的cluster,然後搭建AG。
Change the HADR Cluster Context of Server Instance (SQL Server) http://msdn.microsoft.com/en-us/library/jj573601.aspx
-----------------------3/1/2017----------------
Distributed Availability Groups is a better choice :)