(此文章同時發表在本人微信公眾號“dotNET開發經驗談”,歡迎右邊二維碼來關注。)
題記:在上個月的Connect() 2016大會上,微軟宣佈了VS 2017 RC的釋出,其中為資料分析師帶來了一體化的開發環境。
我們知道Visual Studio 2017帶來的一大改變就是,輕量級的快速安裝模式:把各種功能特性按照開發領域(Workload)進行組織劃分,安裝的時候只需要選擇自己所需要用到的那部分開發領域就可以快速完成VS的安裝。
隨著資料科學越來越熱門,在剛剛釋出的VS 2017 RC中,微軟已經獨立提供了兩種和資料分析相關的開發領域了:資料儲存和處理、資料科學和分析應用。見下圖所示:
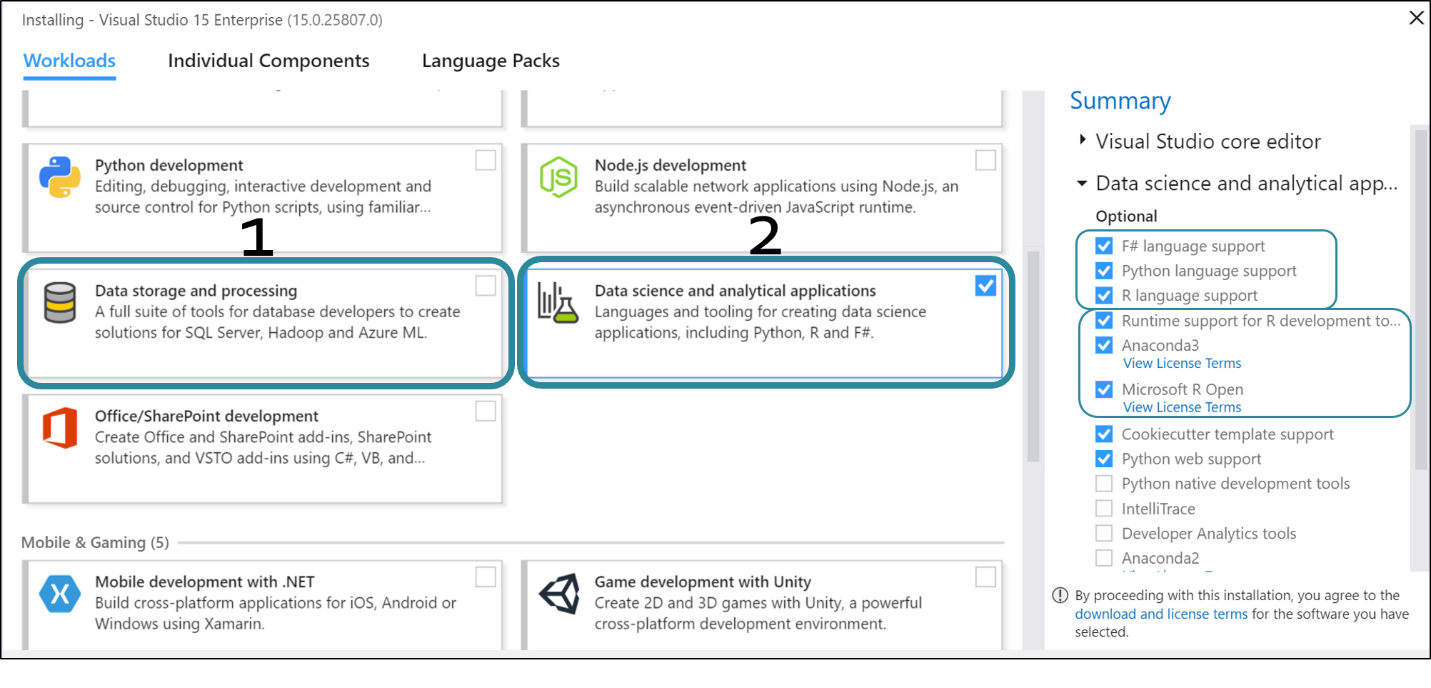
選擇“資料儲存和處理”開發領域,讓你能夠獲得大資料儲存和高階分析的開發環境。除了基本SQL以外,還支援HDInsight(Hadoop/Spark)和Azure機器學習的開發能力。
選擇“資料科學和分析應用”開發領域,讓你能夠獲得用於構建分析應用的相應開發環境。包括如下內容:
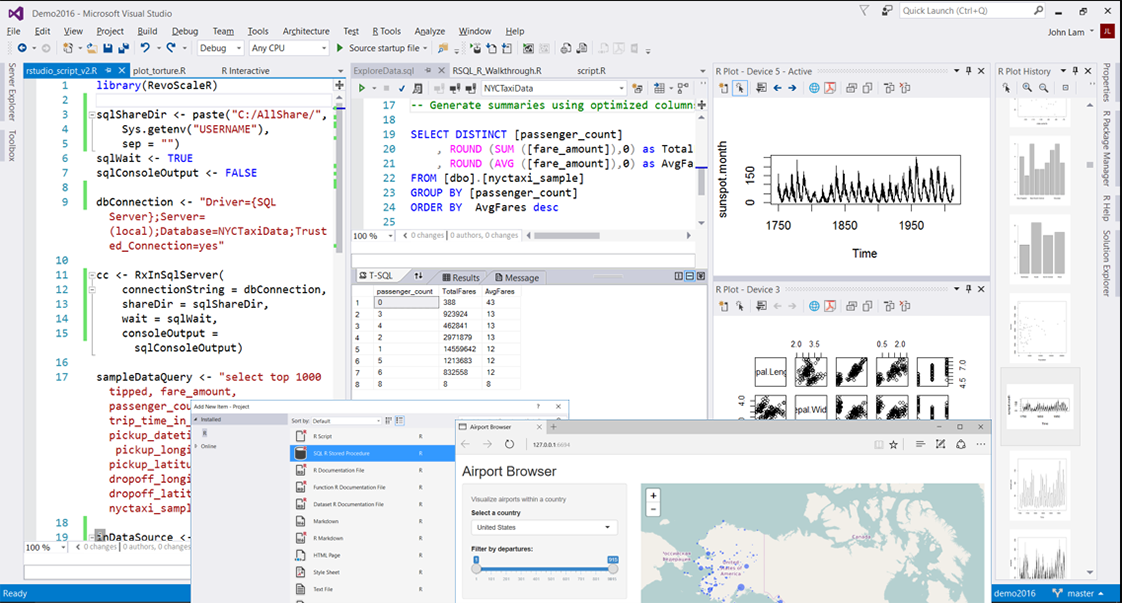
可用來構建桌面、Web、科學計算、資料科學和機器學習應用的Python的開發工具(PTVS)。支援CPython 2.x/3.x、IronPython、Jython、PyPy等。也包含了Anaconda這一可以安裝大量科學計算和分析Python包的包管理器。如下圖所示:

可用來構建統計、資料科學和機器學習應用的R開發工具(RTVS)。同時支援CRAN R和Microsoft R兩種發行版本。如下圖所示:
可用來開發各類資料處理任務的的F#開發工具。由於F#是類LISP的函式式為先的語言,同時兼具物件導向的特性,所以天然就是用來開發機器學習等人工智慧應用的首選語言。如下圖所示:
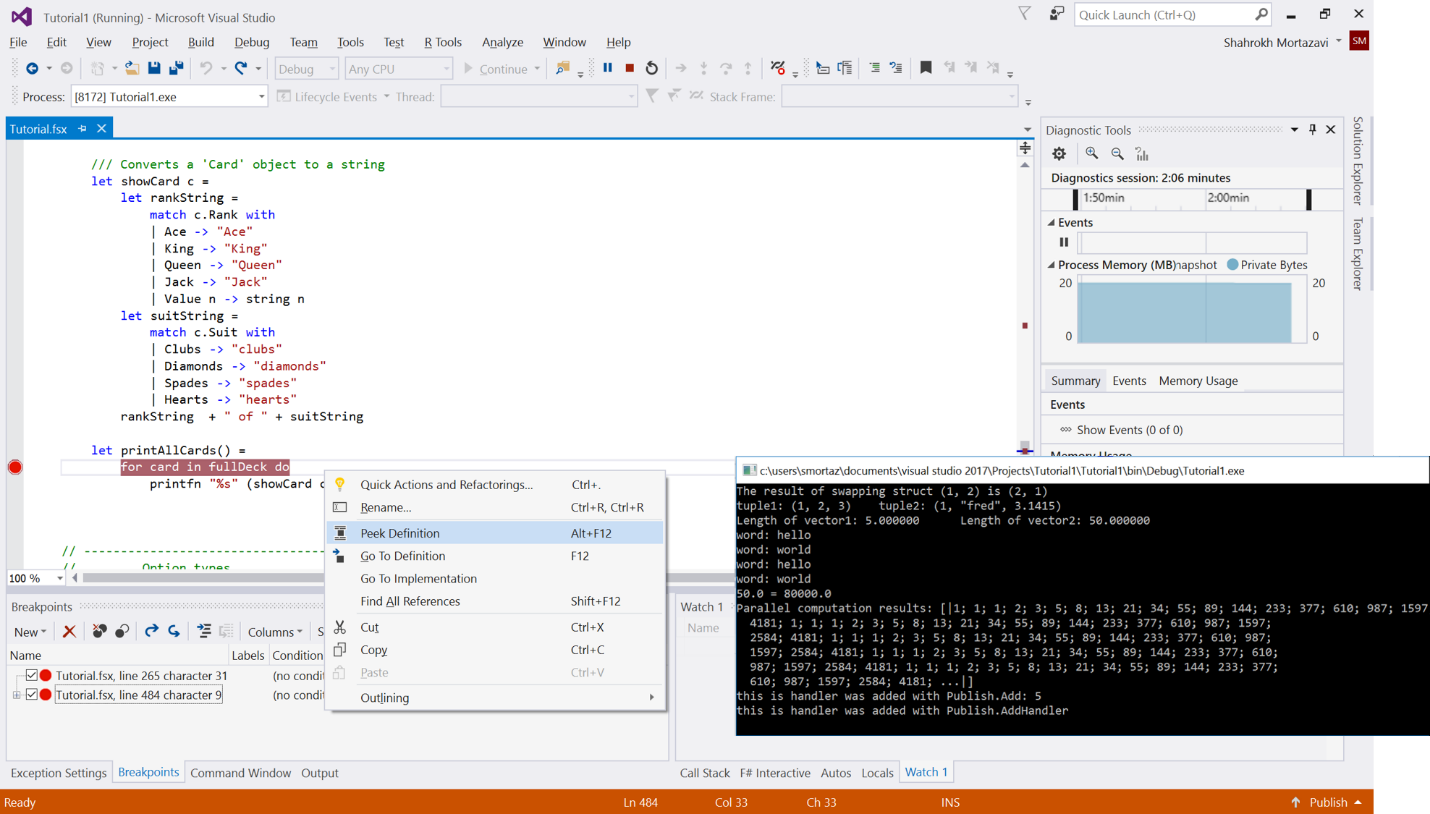
F#作為微軟頭等語言之一,Visual Studio一直以來都支援它的開發環境。而對於Python和R,其實微軟之前也一直以開源外掛的形式為VS提供這方面的開發能力。我之前的文章都有介紹過。
另外需要強調的是,Python和R已經成為資料分析、資料探勘、資料科學方面使用最廣的兩種語言,見下圖:

本文基於The Data Science Workloads in Visual Studio 2017 RC整理翻譯而來。