文/高揚
什麼是爬蟲?
爬蟲只是一種形象的比喻,不是樹上爬來爬去的那種……爬蟲是一種自動獲取網頁內容的程式,是搜尋引擎的重要組成部分,是資料處理的第一個環節。大體上,可以有傳統和垂直兩種型別,傳統的就是google、baidu大搜尋爬蟲,本篇介紹是的電商垂直爬蟲。
做一個簡單的爬蟲很容易,你只要寫下面這行程式碼:
wget http://www.meituan.com/
完了……
看,很簡單吧,大家都覺得寫一個爬蟲很簡單,也預示著爬蟲攻城溼苦逼日子的開始……
上面這行程式碼給學生講講課是夠用的,但實戰還需要解決很多問題,爬蟲的基本工作有抓取、抽取、儲存,我們分別說一說。
(一)抓取
1. 編碼識別&翻頁
網際網路上的網頁大多是http協議的,但編碼每家都不一樣,有utf-8,gbk,gb2312等等。如果無視編碼問題,會使部分網頁下載後是亂碼,導致無法使用。
通常網頁head標籤內會標記編碼,例如 ,但總有不靠譜的網站維護者不遵守標準,實際編碼並不一定是utf8的。我們研發了一種通用技術解決方案:編碼智慧識別。我們內建了每個編碼的常用字符集二進位制碼,然後將網頁內容二進位制化,找出匹配度最大的,作為這個網頁的真正編碼。這個方法很有效,99%+的準確率,就是稍微耗費點CPU,我們基本都用這個方法來識別網頁編碼,無視charset標籤。
,但總有不靠譜的網站維護者不遵守標準,實際編碼並不一定是utf8的。我們研發了一種通用技術解決方案:編碼智慧識別。我們內建了每個編碼的常用字符集二進位制碼,然後將網頁內容二進位制化,找出匹配度最大的,作為這個網頁的真正編碼。這個方法很有效,99%+的準確率,就是稍微耗費點CPU,我們基本都用這個方法來識別網頁編碼,無視charset標籤。
另外,很多電商商品頁面,部分割槽域是ajax非同步載入的,用POST的也比較多,直接使用wget、curl有諸多不便,需要支援。我們對其進行了整體封裝,內部稱這個類庫為httpfetcher。
2. 智慧的排程、更新
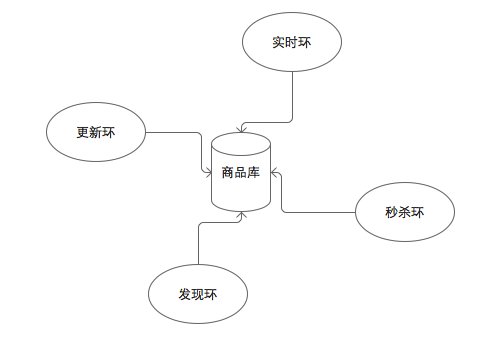
電商網頁變化比較頻繁,特別是商品價格欄位,有時候幾乎幾分鐘一變。上億的商品庫做到每個商品都能及時更新是很困難的,如何用有限資源,抓取最應該更新的商品,是一個難題。以商品更新為例,我們採用基於賣場場景的排程方式,不同的賣場場景更新頻率不同,每一個爬蟲負責特定場景的抓取任務,稱作一個環。發現環負責粗粒度發現,更新環負責粗粒度更新,秒殺環負責限時搶購類的細粒度更新,如下圖
3. 重複抓取規避
頻寬,恩,頻寬……一談到頻寬,爬蟲溼都雙眉緊鎖。創業小公司,不是BAT那種不差錢的主,在北京這種地方頻寬是很貴滴,如果能省下一點點頻寬,那年終獎都出來了滴。gzip壓縮這種最佳化標準套餐後,我們還需要解決重複網頁抓取,節約頻寬。
我們管理的網址是億級別的,普通hashmap在記憶體中存不下,需要使用BloomFilter了。
BloomFilter是一種空間效率很高的隨機資料結構,它利用位陣列很簡潔地表示一個集合,並能判斷一個元素是否屬於這個集合。
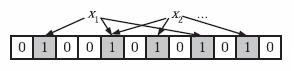
下面我們具體來看Bloom Filter是如何用位陣列表示集合的。初始狀態時,Bloom Filter是一個包含m位的位陣列,每一位都置為0。

為了表達S={x1, x2,…,xn}這樣一個n個元素的集合,Bloom Filter使用k個相互獨立的雜湊函式(Hash Function),它們分別將集合中的每個元素對映到{1,…,m}的範圍中。對任意一個元素x,第i個雜湊函式對映的位置hi(x)就會被置為1(1≤i≤k)。注意,如果一個位置多次被置為1,那麼只有第一次會起作用,後面幾次將沒有任何效果。在下圖中,k=3,且有兩個雜湊函式選中同一個位置(從左邊數第五位)。
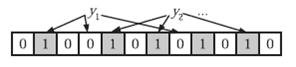
在判斷y是否屬於這個集合時,我們對y應用k次雜湊函式,如果所有hi(y)的位置都是1(1≤i≤k),那麼我們就認為y是集合中的元素,否則就認為y不是集合中的元素。下圖中y1就不是集合中的元素。y2或者屬於這個集合,或者剛好是一個false positive。
BloomFilter的這種高效是有一定代價:
1. 在判斷一個元素是否屬於某個集合時,有可能會把不屬於這個集合的元素誤認為屬於這個集合(falsepositive)。不過對於爬蟲場景,來判斷一個網址是否被抓取過來說,這種誤判率是可以接受的。
2. 無法unset。如果一個網頁較早前被抓取過,因為某種原因想再抓一次,Bloom Filter下無法重新清狀態再抓取。我們在實踐中,採用的是定期清空Bloom Filter,在頻寬浪費和unset之間做了一個平衡。
此外,抓取還要解決防封禁等。
(二)抽取
垂直爬蟲所涉及的網頁空間相對比較集中,對資料結構化要求較高,需要透過模板來解決。我們定義並使用了四種模板:URL模板,列表模板,商品模板和點評模板,這裡簡單說說前三種。
URL模板
1. URL歸一化
商品URL可以標識一個唯一商品,在網站上同一個商品可能有不同的url,原因可能多方面的,一是入口不一樣,列表頁,搜尋頁點選過去的頁面是不一樣的,二是URL後面經常帶有統計資訊。這樣會導致庫裡大量的商品重複以及Bloom Filter失效,所以需要採用某種規則,將這些URL轉化為同一型別的URL,被我們成為URL歸一化。
2. URL特徵
制定不同的規則來判定是列表url還是商品url,方便採取不同的抓取策略。列舉一些URL模板例子:
商品URL模板
www.jd.com|^/product/[0-9]+/.html.*$
book.jd.com|^/[0-9]+/.html.*$
列表模板
表明當前的為一個列表模板,需要透過模板獲取的資訊為商品總頁數
一個列表連結意味著這個連結上面都是一個跳出的連結,透過獲取所有的連結,然後與當前網站商品的URL特徵匹配,可以獲得純淨的商品URL連結,從而控制了發現的連結的準確性。
當一個頁面可以翻頁的時候,種子URL模板如下
http://www.jd.com/products/652-828-1107-0-0-0-0-0-0-0-1-5-[xx].html
爬蟲收到這種型別的連結,按照初始預設起始頁,步長爬起第一個頁面。
http://www.jd.com/products/652-828-1107-0-0-0-0-0-0-0-1-5-1.html。爬取完畢以後,透過列表模板獲得商品總頁數,寫入到連結物件持久化。然後將這個連結新發現的商品連結和自身寫入URLDB。當爬蟲在次從URLDB取到這個連結時,發現這個連結是可以翻頁的連線,於是按照當前的pageIndex,pageStep計算出下一個頁面。然後爬取下一個頁面。
商品模板
早期商品模板主要使用Xpath正則、JS子模板及自定義的表示式來完成商品資訊的解析。Xpath正則很常見,自行百度。JS子模板主要用來解決一些技術的問題
1,實現在解析某個頁面時呼叫其子頁面(ajax),因為有時某些商品資訊(如點評量),在商品頁的html程式碼中是不存在的,需要呼叫該商品頁的子頁面(如點評頁)才能獲取;
2,實現從頁面中抽取內容傳遞給某個中間變數(虛擬的模板項),因為有時某個最終結果需要同時對兩個中間結果做處理才能得到,需要支援建立多箇中間變數。
JS子模板這個名字不好,最初未來解決javascript帶來的問題,後面也就懶得改了。隨著技術的迭代最佳化,逐漸使用一種自研的指令碼語言(內部代號,behemoth)來簡化模板抽取工作。鑑於指令碼語言的靈活性,behemoth幾乎能做到任何程度的處理,可用來抽取商品SKU,點評等。目前我們正逐漸替換成behemoth。
behemoth極大簡化了模板編寫工作,隱藏諸多技術資訊(例如常用的xpath、正則封裝),讓模板編寫者只關注業務邏輯。此外,大多數電商網頁,都存在著盤根交錯的ajax呼叫,behemoth先執行整個網頁的dom渲染後再進行抽取工作,每個抽取模板是一個code unit,極大降低了模板編寫複雜度。
behemoth也是有代價的,由於大量的渲染工作,抽取一個網頁的時間是之前的幾倍。總體上,好處還是大於壞處。

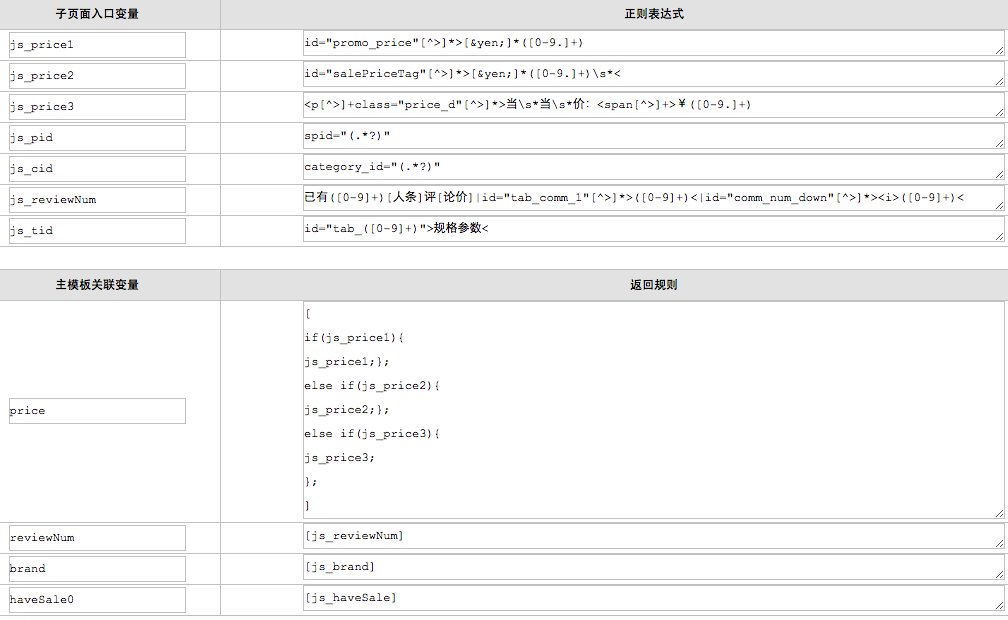
這是我們早期一些模板的示例。
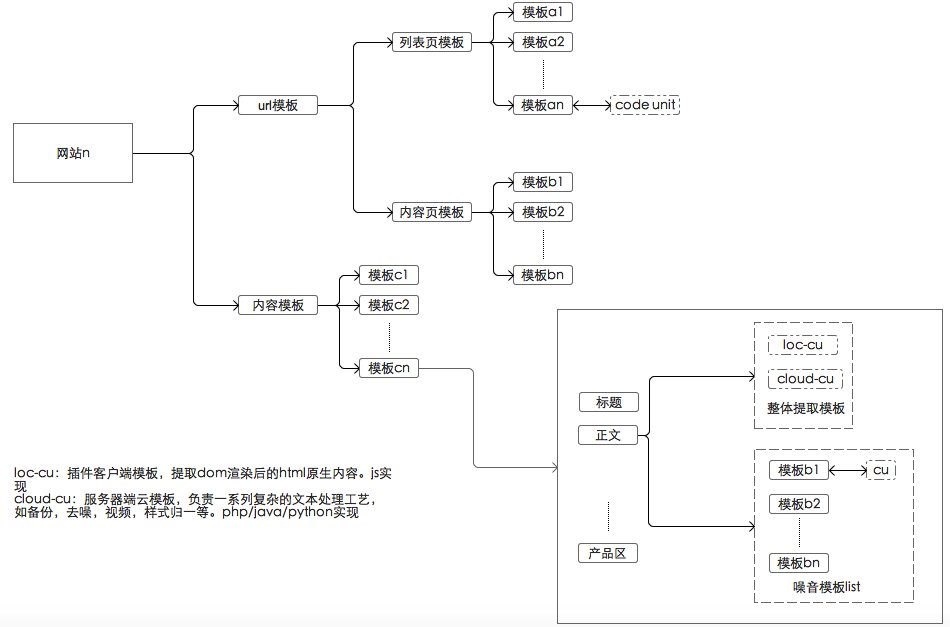
這是目前模板的演化現狀。
對了,還有一個問題,模板這麼多,如果模板失效了怎麼檢測呢?我們為此研發了一個自動檢查機器人,將有問題的模板定期挑出來,讓人工修改更新。這種架構,維護幾千家網站不成問題。
此外,我們正在研發第三代抽取技術,模板工作將會進一步再減少50%+。
(三)儲存
需要管理的網址連結是百億級,商品是10億級,為了方便分析和讀取,需要支援隨機寫和順序寫的儲存系統,關係型資料無法滿足我們的需求,需要no-sql型。早期我們自研了一套檔案系統——ministore,隨著資料量的增長,維護的成本比較高,中期我們且換到了Cassandra,到現在我們使用改造後的Hadoop+redis。有關Cassandra、Redis、Hadoop文章很多,兩個系統各有特點,這裡不展開說。
小結
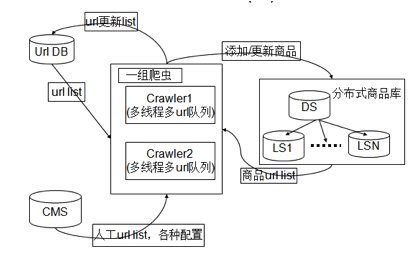
要寫好一個爬蟲要幹這麼多活,絕對是一個髒活累活有木有,堪稱技術界的活雷鋒有木有。
一個優秀的爬蟲對搜尋引擎發揮著極其重要的作用,它是核心資料的源頭,處理的越好,對後續的處理幫助越大。