為了有趣我們今天就主要去爬取以下MM的圖片,並將其按名儲存在本地。要爬取的網站為: 大秀臺模特網
1. 分析網站
進入官網後我們發現有很多分類:

而我們要爬取的模特中的女模內容,點進入之後其網址為: http://www.daxiutai.com/mote/5.html ,這也將是我們爬取的入口點,為了方便,我們只是爬取其推薦的部分的模特的資訊和圖片。

當我們點選其中的一個人物的時候就會進入他們的個人主頁中,裡邊包括個人的詳細資訊以及各種圖片。模特的詳細都將從這裡爬取。
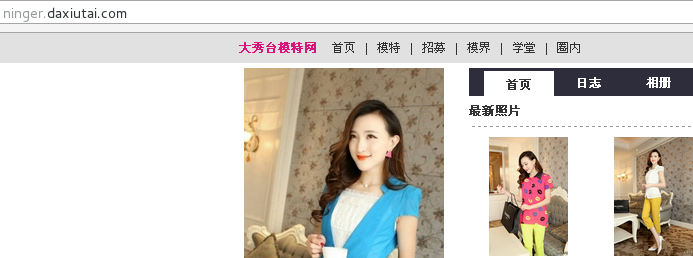
上述的個人主頁中的模特圖片不全,所以模特的圖片將從其照片展示網頁中爬取,而其照片的展示網頁可以通過點選任意主頁上的圖片進入,如下圖所示:

我們要實現的效果就是每個模特一個資料夾,特定模特資料夾下包括一個模特資訊說明的txt文件以及其所有爬取到圖片
2. 爬取過程
2.1 爬取各個模特的主頁地址
在點選女性模特頁面中的模特頭像的時候就會進入此模特的主頁之中,而各個模特的主頁中包含模特的主要資訊,所以要先在 http://www.daxiutai.com/mote/5.html 中獲得每個模特的主頁地址。

其最裡邊的<li>標籤中就包含模特的主頁地址資訊,通過藍色選中部分中地址就可以獲取模特主頁地址,但卻不是圖片的地址,應為其是被重定向過。

In [93]: url_femal = "http://www.daxiutai.com/mote/5.html" In [94]: request = urllib2.Request(url_femal) In [95]: response = urllib2.urlopen(request) In [96]: content = response.read()
#綠色部分就是獲取到的地址 In [105]: pattern = re.compile(r"(?:<li\s+class=\"li_01\">).*?<a\s+href=\"(.*?)\".*?>",re.S) In [106]: result = re.findall(pattern,content)
In [107]: result[0]
Out[107]: 'http://www.daxiutai.com/mote_profile/13517.html'
# 總共抓取了60條資料 In [108]: len(result) Out[108]: 60
艾,寫網頁的那個傢伙太懶了沒有把女模特和其它的模特區分開來,所以只能把其他的都抓取下來,而且有重複地址,所以還要去重。
# 去除重複
In [110]: result = list(set(result)) In [111]: len(result) Out[111]: 57
因為上述這些抓取到的地址在訪問的時候會重定向,所以我們需要一一獲取其重定後的地址,這一階段比較費時間,得等一會兒。
#重定位後的地址放在main_url中
In [124]: main_url = [] # 迴圈獲取重定位後的地址 In [125]: for item in result: ...: res = urllib2.urlopen(item) ...: main_url.append(res.geturl()) ...: print res.geturl()
http://www.daxiutai.com/mote_profile/13523.html http://heijin.daxiutai.com/ http://fuxinyu.daxiutai.com/ http://152nicai.daxiutai.com/ http://lfh0706.daxiutai.com/ http://649629484.daxiutai.com/
........................
上述列印的地址中紅色型別的地址不是重定位後的地址,且是不可訪問的,如果在瀏覽器中輸入此地址會出現如下反應:
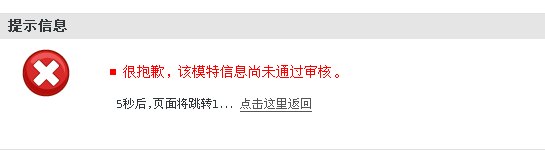
所以這樣的地址是需要剔除的,剔除時所依據的特性就是//後邊是否接著www。
In [135]: main = [] In [136]: for item in main_url: ...: mat = re.match(".*?www.*?",item) ...: if not mat: ...: main.append(item) # 剔除之後還有55條資料 In [137]: len(main) Out[137]: 55
2.2 爬取模特的個人資訊
模特的個人資訊顯示如圖所示:
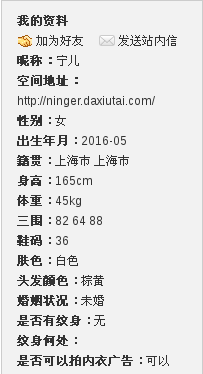
HTML原始碼情況為:

粗略提取一個模特的資訊:
In [184]: response = urllib2.urlopen(main[10],timeout=5) ...: content = response.read() In [185]: pattern = re.compile(r"<strong>(.*?)</strong>(.+?)<br\s*/>") In [186]: result = re.findall(pattern,content) In [187]: for item in result: ...: print item[0],item[1] 暱稱: 我才是寶寶 空間地址: <br /><a href="http://babysix.daxiutai.com/">http://babysix.daxiutai.com/</a> 性別 :女 出生年月 :2016-03 籍貫 :天津市 天津市 身高 :166cm 體重 :45kg 三圍 :82 63 88 鞋碼 :38 膚色 :黃色 頭髮顏色 :黑 婚姻狀況 :未婚 是否有紋身 :無 紋身何處 : 是否可以拍內衣廣告 :不可以
我們發現在匹配過程中中文的:符號也被匹配出來了,而這個在匹配過程中應該去掉。同時空間地址一項的結果明顯混亂,但是為了不增加正規表示式的難度,我們在後續處理中直接用我們重定向後的地址取代這個地址即可。
因為包含中文符號的情況可能是這樣的:
![]()
也會是這樣的:

所以明顯感覺到了網頁的作者的慢慢的惡意。。。。。,所以我們用 (?::)? 來解決這個問題。分組中?:表示匹配但不計入結果,接下來的:是要匹配到的中文冒號,一定要是中文的,分組外邊的?表示這個分組可以匹配到也可以匹配不到都行。
In [205]: response = urllib2.urlopen(main[10],timeout=5) In [206]: content = response.read() In [207]: pattern = re.compile(r"<strong>(.*?)(?::)?</strong>(?::)?(.+?)<br\s*/>") In [208]: result = re.findall(pattern,content) In [209]: for item in result: ...: print item[0],item[1] ...: 暱稱 我才是寶寶 空間地址 <br /><a href="http://babysix.daxiutai.com/">http://babysix.daxiutai.com/</a> 性別 女 出生年月 2016-03 籍貫 天津市 天津市 身高 166cm 體重 45kg 三圍 82 63 88 鞋碼 38 膚色 黃色 頭髮顏色 黑 婚姻狀況 未婚 是否有紋身 無 紋身何處 : # 這裡還是有些問題,為了簡單我們就不再更改內容了 是否可以拍內衣廣告 不可以
上邊僅僅是獲取一個模特的詳細資訊,接下來我們將獲取所有的模特的資訊:
In [90]: result = [] In [90]: for item in main: response = urllib2.urlopen(item,timeout=8) content = response.read() temp = re.findall(pattern,content) result.append(temp)
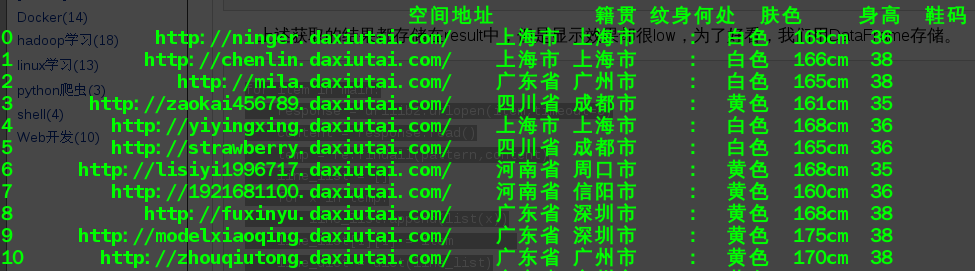
上述獲取的結果都儲存在result中,但是顯示效果卻很low,為了好看,我們用DataFrame儲存。
注意:下邊的程式碼如果直接copy到ipython中執行會有錯誤,最好是自己按照程式碼層級自己敲入:
for item in main: response = urllib2.urlopen(item,timeout=8) content = response.read() temp = re.findall(pattern,content) line_list = [] for x in temp: line_list.append(list(x))
# 這裡 line_list[1][1] = item line_dict = dict(line_list) result.append(line_dict) frame = DataFrame(result)
效果如下圖所表示(只是擷取了前10個資訊):
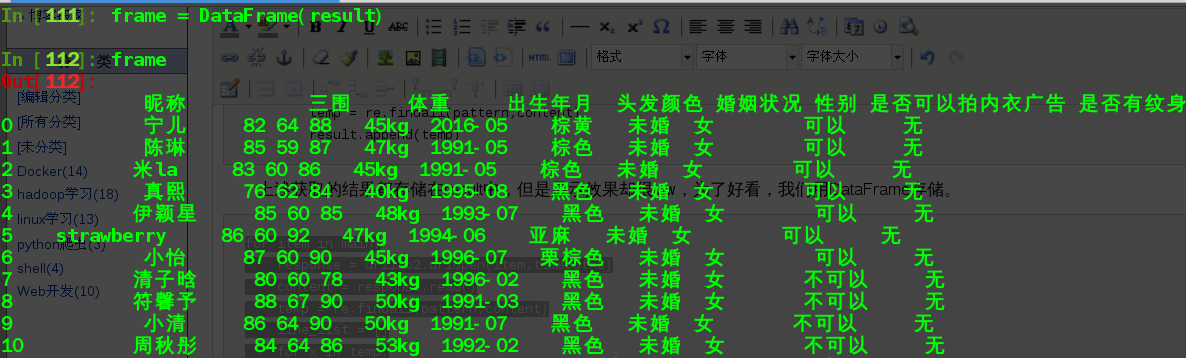
為了方便,我們將這個過程寫為一個python可執行檔案,內容如下:
#!/usr/bin/python #! -*- coding:utf-8 -*- import urllib import urllib2 import re import numpy as np import pandas as pd from pandas import DataFrame,Series class ScrapModel: def __init__(self): self.entry_url = "http://www.daxiutai.com/mote/5.html" def get_personal_address(self): try: print "進入主頁中..." request = urllib2.Request(self.entry_url) response = urllib2.urlopen(request,timeout=5) content = response.read() pattern = re.compile(r"(?:<li\s+class=\"li_01\">).*?<a\s+href=\"(.*?)\".*?>",re.S) original_add = re.findall(pattern,content) # 去重複 original_add = list(set(original_add)) redirect_add = [] print "獲取重定向地址中..." for item in original_add: res = urllib2.urlopen(item,timeout=5) url = res.geturl() # 去除不可訪問地址 mat = re.match(r".*?www.*?",url) if not mat: redirect_add.append(url) print url return redirect_add except Exception,e: if hasattr(e,"reason"): print u"連線失敗,原因:",e.reason if hasattr(e,"code"): print "code:",e.code return None def get_personal_info(self,redirect_add): if (len(redirect_add) == 0): print "傳入引數長度為0" return None try: pattern = re.compile(r"<strong>(.*?)(?::)?</strong>(?::)?(.+?)<br\s*/>") print "獲取模特資訊中..." result = [] for item in redirect_add: response = urllib2.urlopen(item,timeout=8) content = response.read() temp = re.findall(pattern,content) line_list = [] for x in temp: # list(x) 是將匹配到的二元組變換為二元的list line_list.append(list(x)) print "獲取到 %s 的資訊"%line_list[0][1] # 這裡重新設定模特的空間地址 line_list[1][1] = item # 這個做法會將二元list的第一個元素變成字典的型別的key,對應的第二個會變成value line_dict = dict(line_list) result.append(line_dict) # 將結果轉換為DataFrame型別 frame = DataFrame(result) print frame return frame except Exception,e: print Exception,e if hasattr(e,"reason"): print u"連線失敗,原因:",e.reason if hasattr(e,"code"): print "code:",e.code return None spider = ScrapModel() redirect_add = spider.get_personal_address() spider.get_personal_info(redirect_add)
2.3 爬取模特的圖片
在模特的個人主頁中點選相簿就會進入相簿介面,其地址格式為: 個人主頁/album.html

而點選其中的任意一個相簿就會進入其圖片展示頁面,而我們的圖片也將從這裡抓取

所以接下來我們要獲取每一個相簿的地址,我們從每個模特的相簿集頁面中進入,也就是地址格式為: 個人主頁地址/album.html 的形式:
In [226]: url = "http://yiyingxing.daxiutai.com/album.html" In [227]: response =urllib2.urlopen(urllib2.Request(url)) In [228]: content = response.read() In [229]: pattern = re.compile(r"<p><a.*?href=\"(.*?)\".*?img.*?/a></p>") In [230]: albums = re.findall(pattern,content) In [231]: albums Out[231]: ['http://yiyingxing.daxiutai.com/photo/14422.html', 'http://yiyingxing.daxiutai.com/photo/14421.html']
接下來我們獲取所有模特的相簿地址
# model_info就是前邊一節中get_personal_info返回的結果
def get_albums_address(modle_info): albums_addr = {} try: redirect_add = modle_info.index.tolist() pattern = re.compile(r"<p><a.*?href=\"(.*?)\".*?img.*?/a></p>") for item in redirect_add: response = urllib2.urlopen(item + "album.html",timeout=10) content = response.read() albums = re.findall(pattern,content) print "the albums is:",albums albums_addr[item] = albums return albums_addr except Exception,e: print Exception,e if hasattr(e,"reason"): print u"連線失敗,原因:",e.reason if hasattr(e,"code"): print "code:",e.code return None
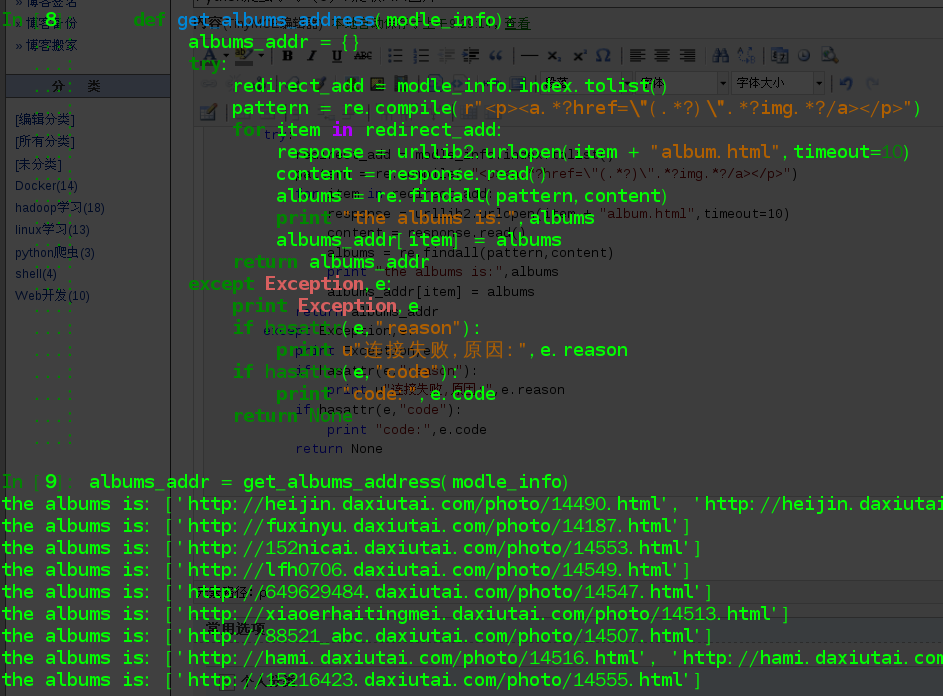
獲取到的地址放在字典型別中,其中的每一項的key值是模特的個人主頁,value就是相簿地址構成的列表。
獲取到了相簿地址之後就該進入每一個相簿中獲取其圖片,但是有的時候其相簿頁面中的圖片就是原圖,像這樣的:

但有的時候卻又是縮圖,是這樣的:

實際上去掉圖片名中 _thumb 就會是原圖地址,所以這兩種都按照一種形式抓取,然後去掉縮圖中的 _thumb:
def get_album_photos(address): print "獲取一個新模特的圖片中..." photos = [] try: pattern = re.compile(r"<p><a.*?rel=\"(.*?)\".*?/a></p>") for item in address: response = urllib2.urlopen(item,timeout=10) content = response.read() temp = re.findall(pattern,content) if temp: print "獲得了MM的%d張照片",len(temp) photos = photos + temp if not photos: print "這傢伙太懶了,什麼圖片都沒有留下.." return None return photos except Exception,e: print Exception,e if hasattr(e,"reason"): print u"連線失敗,原因:",e.reason if hasattr(e,"code"): print "code:",e.code return None
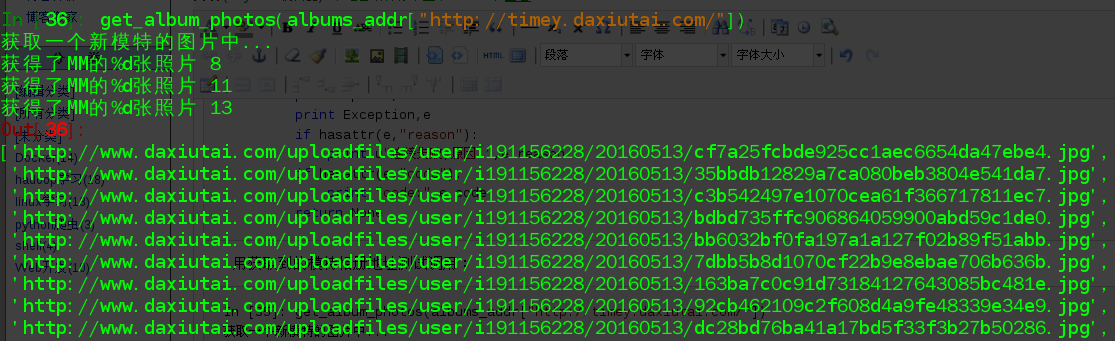
用獲取到的模特相簿地址測試呼叫:
In [35]: get_album_photos(albums_addr["http://timey.daxiutai.com/"]) 獲取一個新模特的圖片中... 獲得了MM的%d張照片 8 獲得了MM的%d張照片 11 獲得了MM的%d張照片 13 Out[35]: ['http://www.daxiutai.com/uploadfiles/user/i191156228/20160513/cf7a25fcbde925cc1aec6654da47ebe4.jpg', 'http://www.daxiutai.com/uploadfiles/user/i191156228/20160513/35bbdb12829a7ca080beb3804e541da7.jpg',
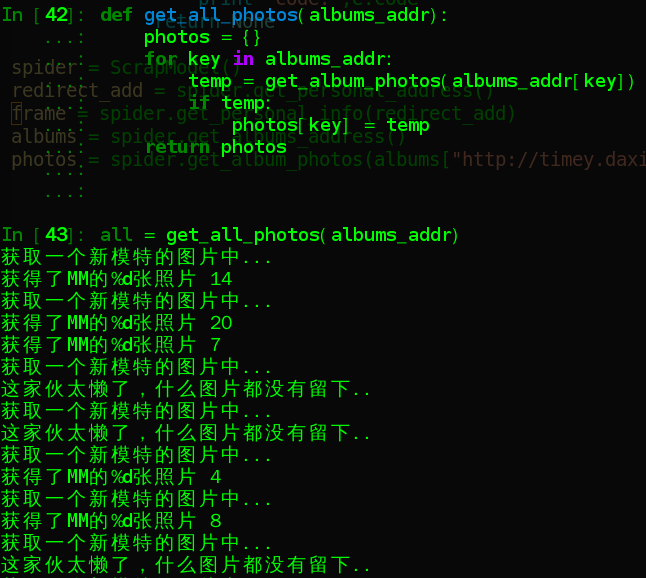
獲取所有的圖片,並將放入字典型別中
def get_all_photos(albums_addr): photos = {} for key in albums_addr: temp = get_album_photos(albums_addr[key]) if temp: photos[key] = temp return photos
2.4 資訊儲存
模特的圖片和個人資訊已經有了,接下來我們就將其儲存在本地。
def save_one_info(self,info,photos): dir_name = info[" 暱稱"] exists = os.path.exists(dir_name) if not exists: print "建立模特資料夾:"+dir_name os.makedirs(dir_name) print "儲存模特資訊中: "+dir_name one.to_csv(dir_name+"/"+dir_name+".txt",sep=":") for photo in photos: photo = re.sub("_thumb","",photo) file_name = dir_name+"/"+re.split("/",photo)[-1] print "正在儲存圖片: "+file_name res = urllib.urlopen(photo) data = res.read() f = open(file_name,"wb") f.write(data) f.close()
測試一個人的儲存:
save_one_info(modle_info.ix["http://zaokai456789.daxiutai.com/"],all["http://zaokai456789.daxiutai.com/"])
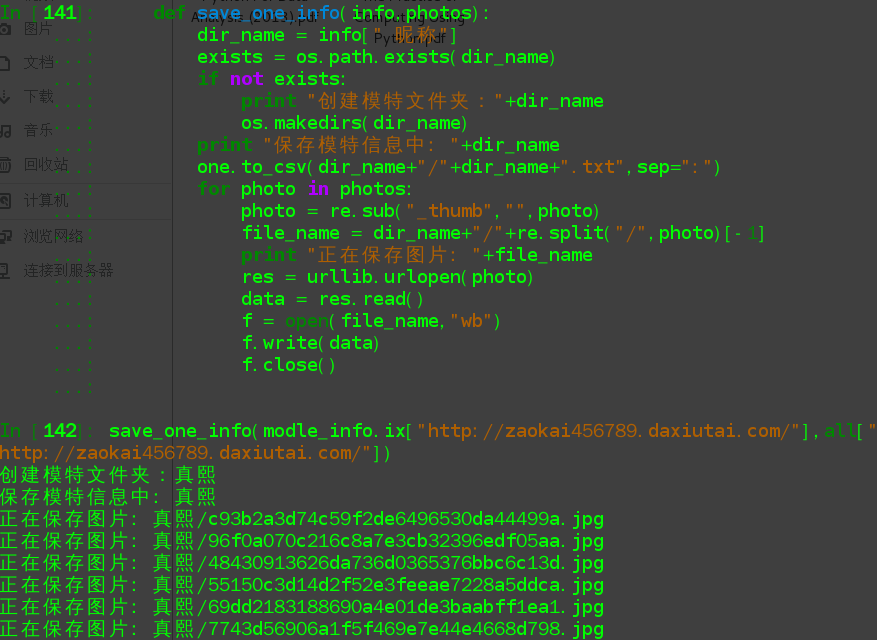
儲存後的結果:

好了,接下來我們將儲存所有人的圖片以及資訊:
def save_all_info(modle_info,modles_photos): for item in modles_photos: save_one_info(modle_info.ix[item],modles_photos[item])

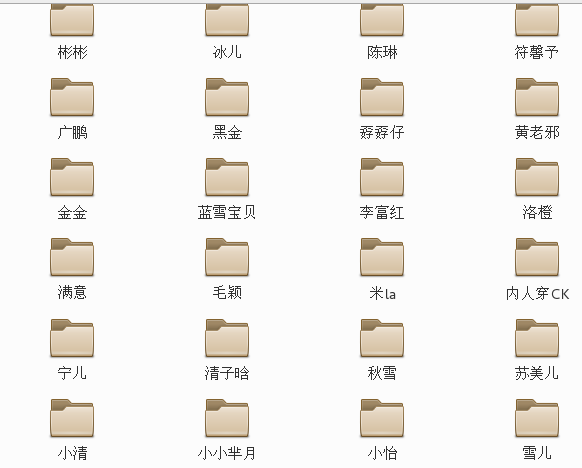
3. 完整的爬取過程
python 入手不久,歡迎大神莫噴
#!/usr/bin/python #! -*- coding:utf-8 -*- import os import urllib import urllib2 import re import numpy as np import pandas as pd from pandas import DataFrame,Series class ScrapModel: def __init__(self): self.entry_url = "http://www.daxiutai.com/mote/5.html" self.modle_info = DataFrame() self.albums_addr = {} def get_personal_address(self): try: print "進入主頁中..." request = urllib2.Request(self.entry_url) response = urllib2.urlopen(request,timeout=5) content = response.read() pattern = re.compile(r"(?:<li\s+class=\"li_01\">).*?<a\s+href=\"(.*?)\".*?>",re.S) original_add = re.findall(pattern,content) # 去重複 original_add = list(set(original_add)) redirect_add = [] print "獲取重定向地址中..." for item in original_add: res = urllib2.urlopen(item,timeout=5) url = res.geturl() # 去除不可訪問地址 mat = re.match(r".*?www.*?",url) if not mat: redirect_add.append(url) print url return redirect_add except Exception,e: if hasattr(e,"reason"): print u"連線失敗,原因:",e.reason if hasattr(e,"code"): print "code:",e.code return None def get_personal_info(self,redirect_add): if (len(redirect_add) == 0): print "傳入引數長度為0" return None try: pattern = re.compile(r"<strong>(.*?)(?::)?</strong>(?::)?(.+?)<br\s*/>") print "獲取模特資訊中..." result = [] for item in redirect_add: response = urllib2.urlopen(item,timeout=10) content = response.read() temp = re.findall(pattern,content) line_list = [] for x in temp: # list(x) 是將匹配到的二元組變換為二元的list line_list.append(list(x)) print "獲取到 %s 的資訊"%line_list[0][1] # 這裡重新設定模特的空間地址 line_list[1][1] = item # 這個做法會將二元list的第一個元素變成字典的型別的key,對應的第二個會變成value line_dict = dict(line_list) result.append(line_dict) # 將結果轉換為DataFrame型別 self.modle_info = DataFrame(result) self.modle_info = self.modle_info.set_index("空間地址") print self.modle_info return self.modle_info except Exception,e: print Exception,e if hasattr(e,"reason"): print u"連線失敗,原因:",e.reason if hasattr(e,"code"): print "code:",e.code return None #獲取每個模特的每個相簿的地址,每個模特都會有一個預設相簿地址,但是裡邊可能沒有圖片 def get_albums_address(self): try: redirect_add = self.modle_info.index.tolist() pattern = re.compile(r"<p><a.*?href=\"(.*?)\".*?img.*?/a></p>") for item in redirect_add: response = urllib2.urlopen(item + "album.html",timeout=10) content = response.read() albums = re.findall(pattern,content) print "the albums is:",albums self.albums_addr[item] = albums return self.albums_addr except Exception,e: print Exception,e if hasattr(e,"reason"): print u"連線失敗,原因:",e.reason if hasattr(e,"code"): print "code:",e.code return None # 獲取一個模特的所有圖片地址 def get_album_photos(self,address): print "獲取一個新模特的圖片中..." photos = [] try: pattern = re.compile(r"<p><a.*?rel=\"(.*?)\".*?/a></p>") for item in address: response = urllib2.urlopen(item,timeout=10) content = response.read() temp = re.findall(pattern,content) if temp: print "獲得了MM的%d張照片",len(temp) photos = photos + temp if not photos: print "這傢伙太懶了,什麼圖片都沒有留下.." return None return photos except Exception,e: print Exception,e if hasattr(e,"reason"): print u"連線失敗,原因:",e.reason if hasattr(e,"code"): print "code:",e.code return None # 獲取所有模特的圖片地址 def get_all_photos(self,albums_addr): photos = {} for key in albums_addr: temp = self.get_album_photos(albums_addr[key]) if temp: photos[key] = temp return photos # 儲存一個模特的資訊 def save_one_info(self,info,photos): dir_name = info[" 暱稱"] exists = os.path.exists(dir_name) if not exists: print "建立模特資料夾:"+dir_name os.makedirs(dir_name) print "儲存模特資訊中: "+dir_name info.to_csv(dir_name+"/"+dir_name+".txt",sep=":") for photo in photos: photo = re.sub("_thumb","",photo) file_name = dir_name+"/"+re.split("/",photo)[-1] print "正在儲存圖片: "+file_name res = urllib.urlopen(photo) data = res.read() f = open(file_name,"wb") f.write(data) f.close() # 儲存所有模特的資訊 def save_all_info(self,modle_info,modles_photos): for item in modles_photos: self.save_one_info(modle_info.ix[item],modles_photos[item]) spider = ScrapModel() redirect_add = spider.get_personal_address() frame = spider.get_personal_info(redirect_add) albums = spider.get_albums_address() all_photos = spider.get_all_photos(albums) spider.save_all_info(frame,all_photos)