SparkStreaming拉取Kafka中資料,處理後入庫。整個流程速度很慢,除去程式碼中可優化的部分,也在spark叢集中找原因。
發現:
叢集在處理資料時存在移動資料與移動計算的區別,也有些其他叫法,如:資料本地化、計算本地化、任務本地化等。
自己簡單理解:
假設叢集有6個節點,來了一批資料共12條,資料被均勻的分佈在了每個節點,也就是每個節點2條。現在要開始處理這些資料。
一種情況是:某資料由哪個節點處理被隨機的分配,類似A節點存了資料1和資料2卻可能被要求處理C節點的資料5和資料6,C節點的資料5和資料6就被備份到A節點,而A節點的資料又要備份到其他某一節點用於被處理。叢集節點間存在大量資料移動,影響了速度。
另一種情況:某節點自身儲存的資料就由自身來處理,比如A節點儲存了資料1和資料2,那麼資料1和資料2就由A節點來計算,C節點儲存了資料5和資料6,那麼資料5和資料6就由C節點來計算。這也就避免了資料的移動。
當然實際要比我描述的複雜得多,我的理解肯定也有不對的地方。
瀏覽器開啟spark 8080埠master介面,圖中紅色箭頭處如果顯示各機器IP地址那就很有可能會造成移動資料的問題。
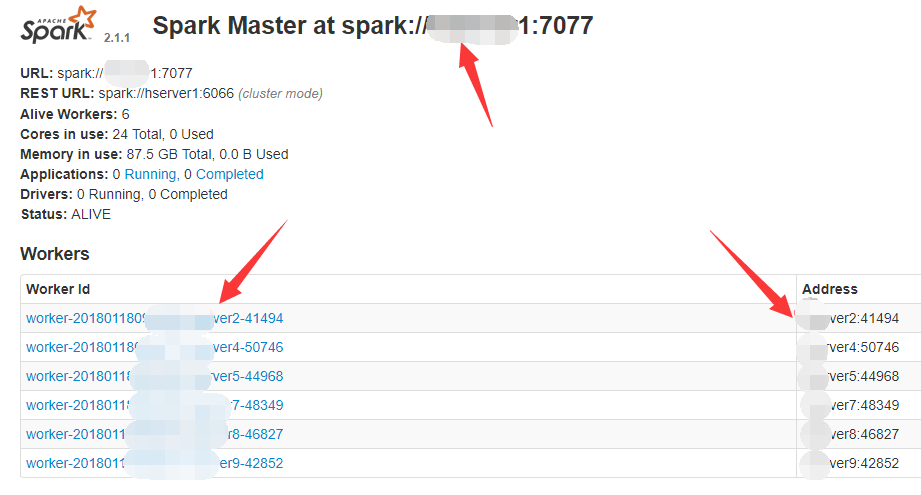
解決:
先停止spark叢集,在master機器用 start-master.sh 啟動,然後分別在每一臺worker機器用 start-slave.sh -h 本機hostname spark://master機器hostname:7077 啟動。
過程中可能遇到很多問題,多注意每臺機器上的幾個檔案中的內容是否有問題:/etc/hosts, spark中conf資料夾中spark-env.sh和slaves