使用buffer類處理二進位制資料
在客戶端javascript指令碼程式碼中,對於二進位制資料並沒有提供一個很好的支援。然後在nodejs中需要處理像TCP流或檔案流時,必須要處理二進位制資料。因此在node.js中,定義了一個Buffer類,該類用來建立一個專門存放二進位制資料的快取區。
一:建立Buffer物件
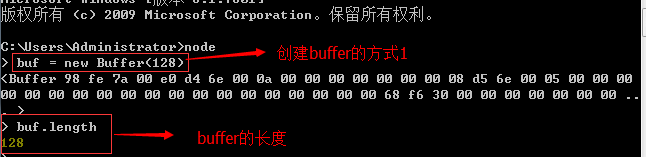
在node.js中,Buffer類是一個可以在任何模組被利用的全域性類,不需要為該類的使用而載入任何模組。可以使用new關鍵字來建立該類的例項物件。Buffer類可以使用三種方式來建構函式,第一種方式如下:
new Buffer(size)
被建立的buffer物件擁有一個length屬性,屬性值為快取區的大小。如下:
我們現在也可以使用Buffer物件的fill方法來初始化快取區中的所有內容,如下所示:
buf.fill(value,[offset],[end]);
在Buffer物件的fill方法中,可以使用三個引數,第一個引數為必須指定的引數,引數值為需要被寫入的數值,第二個引數與第三個引數為可選引數,其中第二個引數用於指定從第幾個位元組處開始寫入被指定的數值,預設值為0,即從快取區的起始位置寫入,第三個引數用於指定將數值一直寫入到第幾個位元組處,預設值為Buffer物件的大小,即書寫到快取區的底部。
現在我們希望從buffer物件的快取區的第10位元組處開始寫入1,一直到快取區底部,如下所示:

我們現在也可以在快取區的第20到第30位元組處(從第20位元組開始,不包含第30位元組)填入2,演示如下:

Buffer類的第二種形式的建構函式是直接使用一個陣列來初始化快取區,程式碼如下所示:
new Buffer(array)
演示如下:

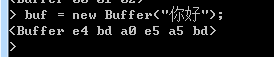
Buffer類的第三種形式的建構函式是直接使用一個字串來初始化快取區,程式碼如下:
new Buffer(str,[encoding]);
第一個引數為必須指定的引數,引數值為用於初始化換出區的字串,第二個引數值為一個用於指定文字編碼格式的字串,預設值為utf-8
如下所示:
在Node.js中,將自動執行字串的輸入輸出時的編碼與解碼處理,預設使用utf-8編碼,可以使用編碼格式如下表所示:
| 編碼 | 說明 |
| ascii | ASCLL字串 |
| utf8 | UTF-8字串 |
| utf16le | UTF-16LE字串 |
| ucs2 | UCS2字串 |
| base64 | 經過BASE64編碼後的字串 |
| binary | 二進位制資料(不推薦使用) |
| hex | 使用16進位制數值表示的字串 |
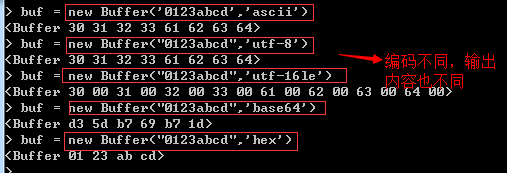
當使用字串引數來建立buffer物件並初始化快取區時,如果使用不同的編碼格式,則快取區中的資料也會有所不同,如下演示:
二:字串的長度與快取區的長度
在node.js中,一個字串的長度與根據該字串所建立的快取區的長度並不相同,因為在計算字串的長度時,是以文字作為一個單位,而在計算快取區的長度時,是以位元組作為一個單位。
比如針對 ”我喜愛程式設計”這個字串,該字串物件的length屬性值與根據該字串建立的buffer物件的length屬性值並不相同。因為字串物件的length屬性值獲取的是文字個數,而buffer物件的length屬性值獲取的是快取區的長度,即快取區中的位元組。
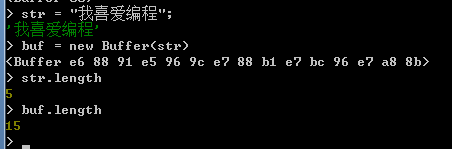
另外,可以使用0開始的序號來取出字串物件或快取區中的資料。但是,在獲取資料時,字串物件是以文字作為一個單位,而快取區物件是以位元組作為一個單位。比如,針對一個引用了字串物件的str變數來說,str[2]獲取的是第三個文字,而針對一個引用了快取區物件的buf物件來說,buf[2]獲取的是快取區中的第三個位元組資料轉換為整數後的數值。如下:

而buffer物件是可以被修改的。可以通過序號來修改其中某個位元組處的資料。如下:

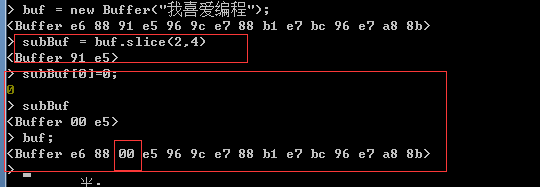
Buffer物件還有一個用於取出指定位置處資料的slice方法,該方法的使用方法與string物件的slice方法相同。

注意:由於buffer物件的slice方法並不是複製快取區中的資料,而是與該資料共享記憶體區域,因此,如果修改使用slice方法取出的資料,則快取區中儲存的資料也將被修改。如下演示:
三:Buffer物件與字串物件之間的相互轉換;
1. Buffer物件的toString方法
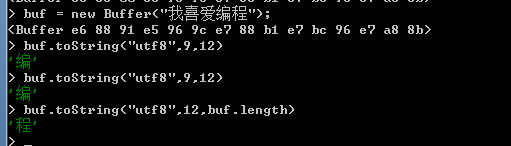
可以使用Buffer物件的toString方法將Buffer物件中儲存的資料轉換為字串,使用方法如下所示:
buf.toString([encoding],[start],[end]);
在Buffer物件的toString方法中,可以使用三個可選引數,第一個引數用於指定Buffer物件中儲存的文字編碼格式,預設引數值為utf8,第二個及第三個用於指定被轉換資料的起始位置和終止位置,以位元組為單位。toString方法返回經過轉換後的字串。
四:Buffer物件的write方法
如果要將字串當做二進位制資料來使用,只需將該字串作為Buffer類的建構函式的引數來建立Buffer物件即可。但是有時候我們需要向已經建立好的Buffer物件中寫入字串,這時候我們可以使用Buffer物件的write方法,程式碼如下所示:
buf.write(string,[offset],[length],[encoding]);
在buffer物件的write方法中,可以使用四個引數,第一個引數為必須指定的引數,後三個引數為可選引數,第一個引數用於指定需要寫入的字串,第二個引數offset與第三個引數length用於指定字串轉換為位元組資料的寫入位置。位元組資料的書寫位置為從第1+offset個位元組開始到offset+length個位元組為止(列如offset為3,length為8,寫入位置為從第4個位元組開始到第11個位元組為止,包括第4個位元組與第11個位元組)。第四個引數用於指定寫入字串時使用的編碼格式,預設是utf8格式。
如下程式碼演示:

五:Buffer物件與JSON物件之間的相互轉換
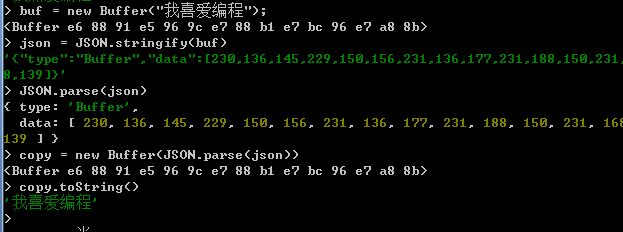
在Node.js中,可以使用JSON.stringfy方法將Buffer物件中儲存的資料轉換為一個字串,也可以使用JSON.parse方法將一個經過轉換後的字串還原為一個陣列。
六:複製快取資料。
當需要將Buffer物件中儲存的二進位制資料複製到另一個Buffer物件中時,可以使用Buffer物件的copy方法,copy方法的使用方法如下所示:
buf.copy(targetBuffer,[targetStart],[sourceStart],[sourceEnd]);
在Buffer物件的copy方法中,使用四個引數,第一個引數為必須指定的引數,其餘三個引數均為可選引數。第一個引數用於指定複製的目標Buffer物件。第二個引數用於指定目標Buffer物件中從第幾個位元組開始寫入資料,引數值為一個小於目標的Buffer物件長度的整數值,預設值為0(從開始處寫入資料)。第三個引數用於指定從複製源Buffer物件中獲取資料時的開始位置,預設值為0,即從複製源Buffer物件中的第一個位元組開始獲取資料,第四個引數用於指定從複製源Buffer物件中獲取資料時的結束位置,預設值為複製源Buffer物件的長度,即一直獲取完畢複製源Buffer物件中的所有剩餘資料。
比如如下:將a中buffer物件中的內容複製到b中的buffer物件中,複製的目標起始位置為b的buffer物件中的第11位元組處(第11位元組處開始寫入)。如下所示:
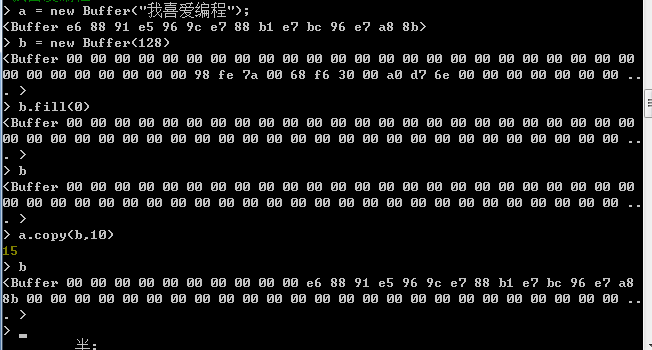
七:Buffer類的類方法
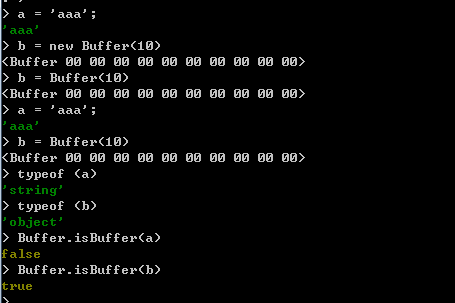
- isBuffer方法
isBuffer方法用於判斷一個物件是否為一個Buffer物件,使用方法如下:
Buffer.isBuffer(obj)
在isBuffer方法中,使用一個引數,用於指定需要被判斷的物件,如果物件為Buffer物件,方法返回true,否則返回false。演示如下:
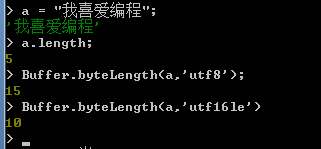
2. byteLength方法;
可以使用byteLength方法計算一個指定字串的位元組數,使用方法如下所示:
Buffer.byteLength(string,[encoding]);
在byteLength方法中,使用兩個引數,第一個引數為必須輸入的引數,用於指定需要計算位元組數的字串,第二個引數為可選引數,用於指定按什麼編碼方式來計算位元組數。預設值為utf8.
如下演示:
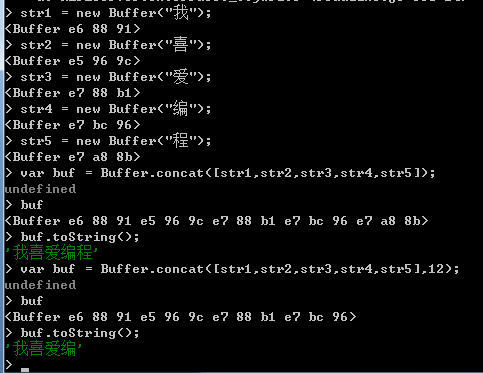
3. concat方法。
concat方法用於將幾個Buffer物件結合建立為一個新的Buffer物件,使用方法如下所示:
Buffer.concat(list,[totalLength])
在concat方法中,使用兩個引數,第一個引數為必須指定的引數,引數值為一個存放了多個buffer物件的陣列,concat方法將把其中的所有Buffer物件連結建立為一個Buffer物件;第二個引數為可選引數,用於指定被建立的Buffer物件的長度,當省略該引數時,被建立的Buffer物件為第一個引數陣列中所有Buffer物件的長度的合計值。
如果一個引數值為一個空陣列或第二個引數值等於0,那麼concat方法返回一個長度為0的Buffer物件。
如果第一個引數值陣列中只有一個Buffer物件,那麼concat方法直接返回該Buffer物件。
如果第一個引數值陣列中擁有一個以上的Buffer物件,那麼concat方法返回被建立的Buffer物件。
如下演示:
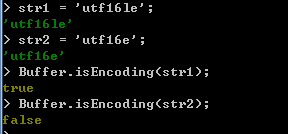
4. isEncoding方法。
isEncoding方法用於檢測一個字串是否為一個有效的編碼格式字串,使用方法如下所示:
Buffer.isEncoding(encoding);
在isEncoding方法中,使用一個引數,用於指定需要被檢測的字串。如果該字串為有效的編碼格式字串,則方法返回true,如果該字串不是一個有效的編碼格式字串,則方法返回false。如下演示: