需求起因
在高併發的業務場景下,資料庫大多數情況都是使用者併發訪問最薄弱的環節。所以,就需要使用redis做一個緩衝操作,讓請求先訪問到redis,而不是直接訪問MySQL等資料庫。
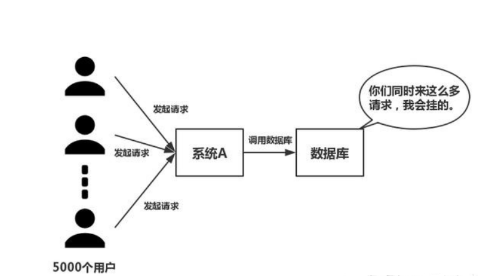
這個業務場景,主要是解決讀資料從Redis快取,一般都是按照下圖的流程來進行業務
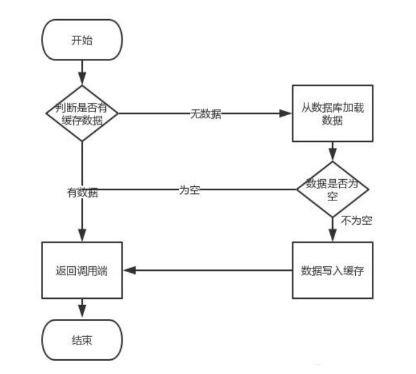
讀取快取步驟一般沒有什麼問題,但是一旦涉及到資料更新:資料庫和快取更新,就容易出現快取(Redis)和資料庫(MySQL)間的資料一致性問題。
不管是先寫MySQL資料庫,再刪除Redis快取;還是先刪除快取,再寫庫,都有可能出現資料不一致的情況。舉一個例子:
1.如果刪除了快取Redis,還沒有來得及寫庫MySQL,另一個執行緒就來讀取,發現快取為空,則去資料庫中讀取資料寫入快取,此時快取中為髒資料。
2.如果先寫了庫,在刪除快取前,寫庫的執行緒當機了,沒有刪除掉快取,則也會出現資料不一致情況。
因為寫和讀是併發的,沒法保證順序,就會出現快取和資料庫的資料不一致的問題。
如來解決?這裡給出兩個解決方案,先易後難,結合業務和技術代價選擇使用。
快取和資料庫一致性解決方案
1.第一種方案:採用延時雙刪策略
在寫庫前後都進行redis.del(key)操作,並且設定合理的超時時間。
虛擬碼如下
public void write( String key, Object data )
{
redis.delKey( key );
db.updateData( data );
Thread.sleep( 500 );
redis.delKey( key );
}
2.具體的步驟就是:
- 先刪除快取
- 再寫資料庫
- 休眠500毫秒
- 再次刪除快取
那麼,這個500毫秒怎麼確定的,具體該休眠多久呢?
需要評估自己的專案的讀資料業務邏輯的耗時。這麼做的目的,就是確保讀請求結束,寫請求可以刪除讀請求造成的快取髒資料。
當然這種策略還要考慮redis和資料庫主從同步的耗時。最後的的寫資料的休眠時間:則在讀資料業務邏輯的耗時基礎上,加幾百ms即可。比如:休眠1秒。
3.設定快取過期時間
從理論上來說,給快取設定過期時間,是保證最終一致性的解決方案。所有的寫操作以資料庫為準,只要到達快取過期時間,則後面的讀請求自然會從資料庫中讀取新值然後回填快取。
4.該方案的弊端
結合雙刪策略+快取超時設定,這樣最差的情況就是在超時時間內資料存在不一致,而且又增加了寫請求的耗時。
2、第二種方案:非同步更新快取(基於訂閱binlog的同步機制)
1.技術整體思路:
MySQL binlog增量訂閱消費+訊息佇列+增量資料更新到redis
- 讀Redis:熱資料基本都在Redis
- 寫MySQL:增刪改都是操作MySQL
- 更新Redis資料:MySQ的資料操作binlog,來更新到Redis
2.Redis更新
(1)資料操作主要分為兩大塊:
- 一個是全量(將全部資料一次寫入到redis)
- 一個是增量(實時更新)
這裡說的是增量,指的是mysql的update、insert、delate變更資料。
(2)讀取binlog後分析 ,利用訊息佇列,推送更新各臺的redis快取資料。
這樣一旦MySQL中產生了新的寫入、更新、刪除等操作,就可以把binlog相關的訊息推送至Redis,Redis再根據binlog中的記錄,對Redis進行更新。
其實這種機制,很類似MySQL的主從備份機制,因為MySQL的主備也是通過binlog來實現的資料一致性。
這裡可以結合使用canal(阿里的一款開源框架),通過該框架可以對MySQL的binlog進行訂閱,而canal正是模仿了mysql的slave資料庫的備份請求,使得Redis的資料更新達到了相同的效果。
當然,這裡的訊息推送工具你也可以採用別的第三方:kafka、rabbitMQ等來實現推送更新Redis!