1. MySQL持久化資料,Redis只讀資料
redis在啟動之後,從資料庫載入資料。
讀請求:
不要求強一致性的讀請求,走redis,要求強一致性的直接從mysql讀取
寫請求:
資料首先都寫到資料庫,之後更新redis(先寫redis再寫mysql,如果寫入失敗事務回滾會造成redis中存在髒資料)
2.MySQL和Redis處理不同的資料型別
MySQL處理實時性資料,例如金融資料、交易資料】
Redis處理實時性要求不高的資料,例如網站最熱貼排行榜,好友列表等
在併發不高的情況下,讀操作優先讀取redis,不存在的話就去訪問MySQL,並把讀到的資料寫回Redis中;寫操作的話,直接寫MySQL,成功後再寫入Redis(可以在MySQL端定義CRUD觸發器,在觸發CRUD操作後寫資料到Redis,也可以在Redis端解析binlog,再做相應的操作)
在併發高的情況下,讀操作和上面一樣,寫操作是非同步寫,寫入Redis後直接返回,然後定期寫入MySQL
幾個例子:
1.當更新資料時,如更新某商品的庫存,當前商品的庫存是100,現在要更新為99,先更新資料庫更改成99,然後刪除快取,發現刪除快取失敗了,這意味著資料庫存的是99,而快取是100,這導致資料庫和快取不一致。
解決方法:
這種情況應該是先刪除快取,然後在更新資料庫,如果刪除快取失敗,那就不要更新資料庫,如果說刪除快取成功,而更新資料庫失敗,那查詢的時候只是從資料庫裡查了舊的資料而已,這樣就能保持資料庫與快取的一致性。
2.在高併發的情況下,如果當刪除完快取的時候,這時去更新資料庫,但還沒有更新完,另外一個請求來查詢資料,發現快取裡沒有,就去資料庫裡查,還是以上面商品庫存為例,如果資料庫中產品的庫存是100,那麼查詢到的庫存是100,然後插入快取,插入完快取後,原來那個更新資料庫的執行緒把資料庫更新為了99,導致資料庫與快取不一致的情況
解決方法:
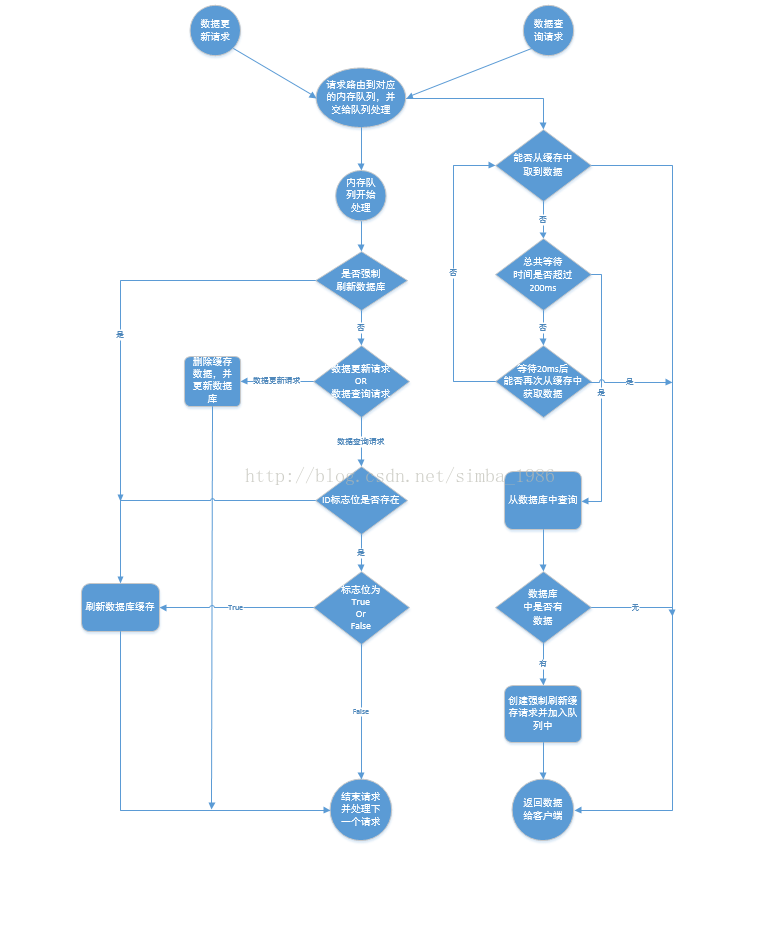
遇到這種情況,可以用佇列的去解決這個問,建立幾個佇列,如20個,根據商品的ID去做hash值,然後對佇列個數取摸,當有資料更新請求時,先把它丟到佇列裡去,當更新完後在從佇列裡去除,如果在更新的過程中,遇到以上場景,先去快取裡看下有沒有資料,如果沒有,可以先去佇列裡看是否有相同商品ID在做更新,如果有也把查詢的請求傳送到佇列裡去,然後同步等待快取更新完成。
這裡有一個優化點,如果發現佇列裡有一個查詢請求了,那麼就不要放新的查詢操作進去了,用一個while(true)迴圈去查詢快取,迴圈個200MS左右,如果快取裡還沒有則直接取資料庫的舊資料,一般情況下是可以取到的。
在高併發下解決場景二要注意的問題:
(1)讀請求時長阻塞
由於讀請求進行了非常輕度的非同步化,所以一定要注意讀超時的問題,每個讀請求必須在超時間內返回,該解決方案最大的風險在於可能資料更新很頻繁,導致佇列中擠壓了大量的更新操作在裡面,然後讀請求會發生大量的超時,最後導致大量的請求直接走資料庫,像遇到這種情況,一般要做好足夠的壓力測試,如果壓力過大,需要根據實際情況新增機器。
(2)請求併發量過高
這裡還是要做好壓力測試,多模擬真實場景,併發量在最高的時候QPS多少,扛不住就要多加機器,還有就是做好讀寫比例是多少
(3)多服務例項部署的請求路由
可能這個服務部署了多個例項,那麼必須保證說,執行資料更新操作,以及執行快取更新操作的請求,都通過nginx伺服器路由到相同的服務例項上
(4)熱點商品的路由問題,導致請求的傾斜
某些商品的讀請求特別高,全部打到了相同的機器的相同丟列裡了,可能造成某臺伺服器壓力過大,因為只有在商品資料更新的時候才會清空快取,然後才會導致讀寫併發,所以更新頻率不是太高的話,這個問題的影響並不是很大,但是確實有可能某些伺服器的負載會高一些。
摘自:https://blog.csdn.net/Thousa_Ho/article/details/78900563