一、什麼是高併發
在網際網路時代,所講的併發、高併發,通常是指併發訪問,也就是在某個時間點,有多少個訪問同時到來。比如,百度首頁同時有1000個人訪問,那麼也就是併發為1000。
通常一個系統的日PV在千萬以上,有可能是一個高併發系統(但有可能不算是一個高併發系統,比如有的公司不走技術路線,全靠機器堆...因為有錢任性!)
二、高併發,我們具體應該關心什麼?
QPS:每秒請求或者查詢的數量,在網際網路領域,指的是每秒相應請求數(指HTTP請求)。
吞吐量:單位時間內處理的請求數(通常由QPS於併發數決定)。
響應時間:從請求發出到收到響應花費的時間。例如系統處理一個HTTP請求需要100ms,這個100ms就是系統的響應時間(可從瀏覽器的NetWork檢視到)
PV:綜合瀏覽量,即頁面瀏覽量或者點選量,一個訪客在24小時內訪問的頁面數量(在一個系統中訪問多個頁面,每個頁面訪問各算一個PV,如果在一個頁面重新整理多次,也只算一個PV)。
UV:獨立訪客,即一定時間範圍內相同訪客多次訪問網站,只計算為一個獨立訪客(和IP類似,一個使用者一個IP)。
頻寬:計算頻寬大小需要關注兩個指標,峰值流量和頁面的平均大小。
日網站頻寬的計算公式: 日網站頻寬 = PV / 統計時間(換算到秒)* 平均頁面大小(單位KB)* 8。
比如統計時間是一天,那麼一天就是24小時,24 * 60 * 60,比如一個頁面10K。峰值一般是平均值的倍數,這個需要根據實際情況來定。
QPS不等於併發連線數
QPS是每秒HTTP請求數量,併發連線數是系統同時處理的請求數量。有可能一個併發連線數裡有多個HTTP請求。
峰值每秒請求數(QPS) = (總PV數 * 80% ) / (6小時秒數 * 20%),意思是80%的訪問量集中在20%的時間內(2/8定律,這裡的6小時只是估計,比如早上中午下午各兩小時)。
壓力測試
為什麼要做測試呢?因為對於我們的伺服器,我們應該知道我們的伺服器最大承受多少QPS,而我們的網站一天多少PV,那麼計算出來整個峰值的QPS,那麼可以根據需要來優化,並不是感覺訪問量大了才優化,是需要依據的!
測試出最大能夠承受的併發出,測試出最大承受的QPS值。比如我們的日QPS是200,單機峰值的QPS承受是50,那麼我們至少需要4臺同樣配置的伺服器才能正常訪問。
常用的效能測試工具
ab、wrk、http_load、Web Bench、Siege、Apache JMeter
ab全程是apache benchmark,是apache官方推出的一個工具,建立多個併發訪問執行緒,模擬多個訪問者同時對一個URL地址進行訪問。它的測試目標是基於URL的,因此它既可以來測試apache的負載壓力,也可以測試Nginx等伺服器的壓力。
測試的注意事項:
測試機器與被測試機器要分開,別在同一臺機器上測試,否則結果是不準確的
不要對線上的伺服器做測試,否則掛了就不好了哦。
觀察測試工具ab所在的機器,以及被測試的前端機器的CPU,記憶體,網路等都不超過最高限度的75%。
http://www.cnblogs.com/wt645631686/p/6868430.html //簡單的ab壓力測試方法
QPS達到極限
隨著QPS的增長,每個階段都需要根據實際情況來進行優化,優化的方案也與硬體條件、網路頻寬息息相關。
如果QPS達到50,可以稱之為小型網站,一般的伺服器就可以應付。
如果QPS達到100,每秒達到100的話,假設關係型資料庫的每秒請求在0.01秒完成,這時候資料庫優化的就很好了。假設單個頁面只有一個SQL查詢,那麼100QPS意味著1秒完成100次請求,但是此時我們並不能保證資料庫查詢能完成100次,所以就達到極限了。那麼需要優化了,方案如:資料庫層的快取、資料庫的負載均衡。
如果QPS達到800,即使我們是用百兆頻寬,意味著網站出口的實際頻寬是8M左右,假設每個頁面只有10K,在這個併發條件下,百兆頻寬已經吃完了,那麼頻寬極限就達到了,方案如:CDN加速、負載均衡。
如果QPS達到了1000,假設使用Memcache、Redis快取做資料庫查詢,每個頁面對Memcache的請求遠遠大於直接對DB的請求,Memcache的悲觀併發數在2W左右,但是有可能在之前內網頻寬已經吃光,表現出不穩定。方案如:靜態HTML快取。
如果QPS達到了2000,這個級別下,檔案系統訪問鎖都成了災難,方案如:做業務分離,分散式儲存。
三、高併發方案的措施詳解
A:流量優化
①防盜鏈
盜鏈的概念
指在自己的頁面上展示一些並不在自己伺服器上的內容。也就是獲得他人伺服器上的資源地址,繞過別人的資 源展示頁面,直接在自己的頁面上向終端使用者提供此內容。如,小站盜用大站的圖片、音樂、視訊、軟體等資源來減輕自己伺服器的負擔。
防盜鏈的概念
防止別人通過一些技術手段繞過本站的資源展示頁面,盜用本站的資源。繞開本站資源展示頁面的資源連結失效就達到了防盜鏈。
防盜鏈的工作原理
通過Referer或者簽名,網站可以檢測到目標頁面訪問的來源頁面,如果是資原始檔,則可以跟蹤到顯示它的網址頁面。一旦檢測到來源不是本站即進行組織或者返回指定的頁面。
觀察一下NetWork中Request Header中的Referer,可以根據此方法判斷是不是盜鏈。
還比如用簽名,就是在請求圖片的時候,帶一個引數,這個引數是彼此之前約定好的簽名,伺服器在顯示圖片的時候判斷簽名是否正確來判斷,通常簽名是很複雜的。
http://www.cnblogs.com/wt645631686/p/7285703.html //本篇文章有說明
B:前端優化
①減少HTTP請求(比如JS合併、CSS合併、圖片合併。雖然檔案大了點,但是減少了請求)。
效能黃金法則
只有10%-20%的終端使用者響應時間花在了接收HTML文件請求上,剩下的80%-90%時間花在HTML文件所引用的所有元件上(圖片、javascript、css等)進行HTTP請求。
如何改善
改善響應時間得最簡單途徑就是減少元件數量,並由此減少HTTP請求。
HTTP連線會產生開銷
域名解析->TCP連線->傳送請求->等待下載資源->下載資源->解析時間
疑問?
本身我們的DNS解析是有快取的,再者HTTP協議1.1版本是用Keep-Alive方式進行操作,也就是不會花費TCP握手時間了。但我們HTTP本身是序列請求的,還是有時間的。
解答:
查詢DNS快取也需要時間,多個快取就要查詢多次有可能快取被清除了。
HTTP1.1協議規定請求只能序列傳送,也就是一百個請求必須依次逐個傳送,簽名的請求完成才能進行下一個,這裡也會造成響應時間的影響。
圖片地圖
允許你在一個圖片上關聯多個URL。目標URL的選擇取決於使用者單擊了哪個位置。就比如常見的一個大圖很多零零碎碎的小圖示,CSS中定位找位置
合併指令碼和樣式表適
使用外部的JS和CSS檔案引用的方式,因為這要比直接寫在頁面中效能好一些。但是也會增加HTTP請求,可以合併JS和CSS檔案,獨立一個JS比用多個JS檔案組成的頁面載入要快38%
圖片使用Base64編碼減少頁面請求數
採用Base64的編碼方式將圖片直接嵌入到網頁中,而不是從外部載入,如<img src="data:image/gif;base64,/9j/2SDFG..." >,這樣下載HTML文件的時間就會增長了。在CSS背景圖中也是可以這麼做的
②新增非同步請求(比如不太重要的東西先不展示,使用者需要的時候再放一些事件,juqery等新增非同步請求獲取)。
③啟用瀏覽器快取和檔案壓縮(啟用瀏覽器快取html檔案,設定快取時間等。將js或者圖片等前端靜態檔案設定過期時間做瀏覽器快取,下次請求就直接從瀏覽器輸出,減少了請求。其次,圖片檔案壓縮也減少了流量的消耗,啟用Nginx的gzip壓縮)。
HTTP快取機制
a:瀏覽器快取
可以降低伺服器壓力,降低頻寬和流量。
快取分類
HTTP快取模型中,如果請求成功會有三種情況
200 from cache :直接從本地快取中獲取響應,最快速,最省流量,因為根本沒有向伺服器傳送請求。
304 Not Modified :協商快取,瀏覽器在本地沒有命中快取的情況下,請求頭中傳送一定的校驗資料到服務端,如果服務端資料沒有改變瀏覽器從本地快取響應,返回304。也就是說本地快取失效,會去服務端請求一下,帶頭資訊過去讓伺服器端判斷這個資源是不是已經過去,如果沒有過期還有效的話,那麼告訴瀏覽器還可以使用本地快取,最終返回304,否則返回真實資料。特點:傳送速度快,資料小,只返回一些基本的響應頭資訊,資料量小,不傳送實際響應體。
200 OK:以上兩種快取全部失敗,伺服器返回完整響應,也就是最慢的了。
b:本地快取
Pragma:HTTP1.0時代時遺留的產物,該欄位被設定為no-cache時,會告知瀏覽器禁用本地快取,即每次都向伺服器傳送請求。
Expires:HTTP1.0時代用來啟用本地快取的欄位,expires值對應一個行如Thu,31 Dec 2037 23:55:55 GMT的格林威治時間,告訴瀏覽器快取實現的時刻,如果還沒到該時刻,表明快取有效,無需傳送請求。但對於Expires有一個問題,當我們去請求服務端的時候,服務端會返回Expires回來,告訴響應時間和過期時間,這個時間是伺服器返回,那麼這個時間就是伺服器時間,再去進行判斷是否過期的時候,判斷是通過瀏覽器判斷,瀏覽器是通過客戶端時間判斷,那麼有可能會出現時間差,那麼就會影響快取結果。
Cache-Control:HTTP1.14針對Expires時間不一致的解決方案,運用Cache-Control告知瀏覽器快取過期的時間間隔而不是時刻,即使具體時間不一致,也不影響快取的管理。也就是Cache-Control給的是一個秒數,就說這個檔案多少秒之後過期,不是時間點了,這樣就沒有對比時間的問題。Cache-Control可以禁止瀏覽器快取響應no-store,也可以不允許直接使用本地快取,先發起請求和伺服器協商 no-cache,也可以告知瀏覽器該響應本地快取有效的最長期限,以秒為單位 max-age=delta-seconds,比如設定3600秒,那麼就是一小時了。
優先順序
Pargma > Cache-Control > Expires ,如果同時設定,那麼最高的是Pargma...依次....
哪些適合本地快取?
不變的影象,如LOGO,圖示等;js,css等靜態檔案
c:協商快取
當瀏覽器沒有命中本地快取,如本地快取過期或者響應中宣告不允許直接使用本地快取,那麼瀏覽器肯定會發起服務端請求。比如Cache-Control設定no-cache,那麼瀏覽器肯定發起服務端請求,服務端會驗證資料是否修改,如果沒有修改通知瀏覽器使用快取。
Last-Modified:通知瀏覽器資源的最後修改時間。當我在頁面上請求一個資源的時候,服務端會給一個相應,會相應一個Last-Modified,當然這個需要設定,相應Last-Modified表示資源的最後修改時間是多少,便於下次請求服務端的時候,帶這個時間過來,服務端會判斷在這個時間節點之後這個檔案是否發生修改,如果沒有修改會返回304,讓瀏覽器使用本地快取。格式Last-Modified:Mon,28 Sep 2015 08:06:43 GMTIf-Modified-Since: 得到資源的最後修改時有修改,返回304狀態碼。格式Last-Modified:Mon,28 Sep 201508:06:43 GMT
ETag: HTTP1.1推出,檔案的指紋識別符號,如果檔案內容修改,指紋會改變。也就是如果檔案發生了內容的修改,ETag就會改變,也就脫離了時間的約束,會更加準確,對於ETag也就是檔案的標識,下次請求的時候,伺服器會給響應一個ETag,告訴檔案資源的標識是多少,下次請求服務端的時候,會帶著值去,服務端會看這個檔案是否發生改變,如果改變,那麼ETag會發生改變,如果沒改變就告訴瀏覽器使用本地快取,返回304狀態碼。格式:“78437556c-6739”
If-None-Match:本地快取失效,會攜帶此值去請求服務端,服務端判斷該資源是否改變,如果沒有改變,直接使用本地快取,返回304。原理差不多的。
哪些適合協商快取?
比如經常改變的,HTML檔案。比如在服務端生成了一個靜態HTML檔案,為了減輕壓力負載,但HTML檔案有可能會改變,因為檔案是根據資料生成的,資料可能會改變,這種檔案適合做協商快取;還比如經常改變的圖片;
再比如經常修改的css、js等靜態檔案。
css、js檔案的載入可以加入檔案的簽名來拒絕快取,如index.css?簽名或者index.簽名.js
不建議快取的內容
使用者隱私的等敏感資料、購物車資訊、個人資訊等、經常改變的api資料介面
Nginx配置快取策略
a:本地快取配置
add_header指令:新增狀態碼為2XX和3XX的響應頭資訊
add_header name value [always];
可以設定Pragma/Expires/Cache-control,可以繼承
expires指令:通知瀏覽器過期時長
expires time; 可以是分鐘可以是小時或者天,比如30秒,就是30s,30分鐘,就是30m
如果為負值時,就表示Cache-Control:no-cache;
如果為正值或者0時,就表示Cache-Control:max-age=指定的時間;
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf|flv|mp4|ico)$ {
expires 30d;
access_log off;
}
location ~ .*\.(js|css)?$ {
expires 7d;
access_log off;
}
b:協商快取配置
Etag指令:指定簽名。用的少
add_header cache-control,也用的少,瞭解就夠了。
前端程式碼和資源的壓縮
優勢
讓資原始檔更小,加快檔案在網路中的傳輸,讓網頁更快的展現,降低頻寬和流量開銷。
壓縮方式
js、css、圖片等壓縮|伺服器端的Gzip壓縮。
js程式碼的壓縮
js程式碼壓縮的原理一般是去掉多餘的空格和回車、替換長變數名、簡化一些程式碼寫法等。有線上壓縮
HTML程式碼壓縮
不建議使用程式碼壓縮,因為會破壞程式碼結構,可以使用Gzip壓縮,當然也可以使用htmlcompressor工具,不過
轉換後一定要檢查程式碼結構。
圖片壓縮
對圖片壓縮也很有必要,一般情況下圖片在Web系統的比重都比較大。
Nginx開啟Gzip壓縮
gzip on|off; #是否開啟gzip
gzip_buffers 32 4k | 16 8k #緩衝(在記憶體中緩衝幾塊?每塊多大)
gzip_comp_level [1-9] #推薦6壓縮級別(級別越高,壓縮的越小,越浪費CPU計算資源)
gzip_disable #正則匹配UA,什麼樣的Uri不進行Gzip
gzip_min_length 200 #開始壓縮的最小長度
gzip_http_version 1.0|1.1 #開始壓縮的http協議版本
gzip_proxied #設定請求者代理伺服器,該如何快取內容
gzip_types text/plain application/xml #對那些型別的檔案用壓縮,如txt,xml,html,css
gzip_vary on | off #是否傳輸gzip壓縮標誌
#Gzip Compression
gzip on;
gzip_buffers 16 8k;
gzip_comp_level 6;
gzip_http_version 1.1;
gzip_min_length 256;
gzip_proxied any;
gzip_vary on;
gzip_types
text/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml
image/svg+xml
text/javascript application/javascript application/x-javascript
text/x-json application/json application/x-web-app-manifest+json
text/css text/plain text/x-component
font/opentype application/x-font-ttf application/vnd.ms-fontobject
image/x-icon;
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
④CDN加速(把前端的檔案,前端的資源全部放到CDN中,使用者就近訪問,從而提高訪問速度,從一定意義也解決了流量不夠用的問題)。
什麼是CDN
全稱是Content Delivery Network,即內容分發網路,把我們站點的內容分發到各個站點,儘可能避開網際網路上有可能影響資料傳輸速度和穩定性的瓶頸和環節,使內容傳輸的更快、穩定。其實就是在網路各處防止節點伺服器所構成的現有的網際網路基礎之上的一層只能虛擬網路。比如站點在北京,你在深圳訪問就會比北京訪問慢,那麼在深圳建立一個節點,那麼會請求深圳的節點,也就是真實伺服器的一個映象,快很多了。CDN系統能夠實時地根據網路流量和各個節點的連線、負載狀況以及到使用者的距離和響應時間等綜合資訊將使用者的騎牛重新導向離使用者最近的伺服器節點上。
使用CDN的優勢
本地Cache加速,提高了企業站點的訪問速度,尤其是含有大量圖片和靜態頁面的站點。
跨運營商的網路加速,保證不同網路的使用者都能得到良好的訪問質量。
遠端訪問使用者根據DNS負載均衡技術智慧自動選擇Cache伺服器
自動生成伺服器的遠端映象,遠端使用者訪問時從Cache伺服器上讀取資料,減少遠端訪問的頻寬、分擔網路流量、減輕原站點WEB伺服器負載等功能。
廣泛分佈的CDN節點加上節點之間的智慧冗餘機制,可以有效地預防黑客入侵。
CDN的工作原理
先了解一下傳統的訪問模式
使用者在瀏覽器輸入域名發起請求-->解析域名獲取伺服器IP地址-->根據IP地址找到對應的伺服器-->伺服器響應並返回資料
CDN的訪問模式
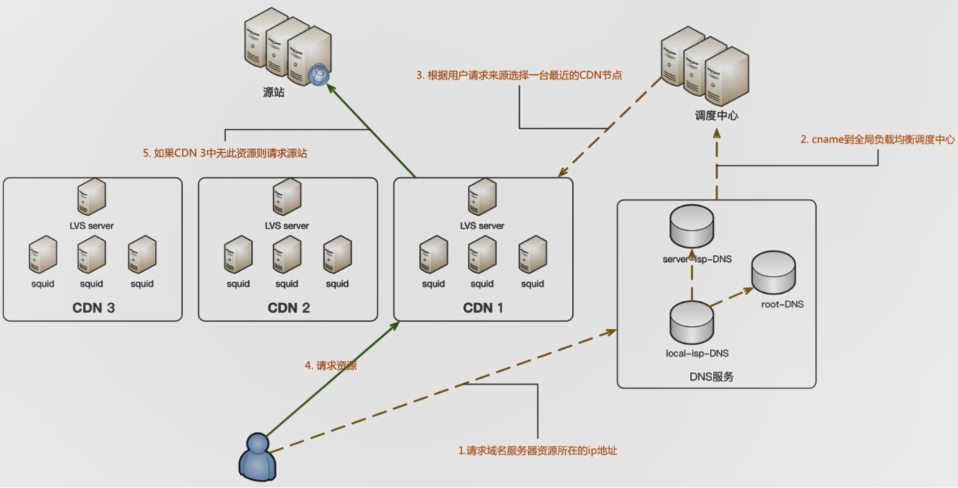
使用者發起請求-->只能DNS的解析(根據IP判斷地址位置、接入網型別、選擇路由最短和負載最輕的伺服器)-->取得快取伺服器IP-->把內容返給使用者(如果快取中有)-->向源站點發起請求-->將結果返回給使用者-->將結果儲存到快取伺服器 。
CDN的適用場景
站點或者應用當中大量靜態資源的分發,如CSS,JS等。
大檔案下載
直播網站等
比較消耗頻寬流量,CDN可以減少
CDN的實現方式
BAT等都有提供CDN服務,阿里雲、騰訊雲
可用LVS做4層負載均衡
也可以用Nginx、Apache 等做7層負載均衡和cache
使用squid或者Nginx做反向代理
⑤建立獨立的圖片伺服器(因為本身圖片伺服器比較吃I/O,為了減少I/O損耗,跟WEB伺服器分離開。還可以針對性的對圖片伺服器做優化,比如對硬碟轉數提高,CPU的計算降低,做叢集等)。
必要性
分擔WEB伺服器的I/O負載,將耗費資源的圖片服務分離出來,提高伺服器的效能和穩定性。
能夠專門對圖片伺服器進行優化,為圖片服務設定有針對性的快取方案,減少頻寬成本,提高訪問速度,比如硬碟轉數高一些;CPU的計算調低些;當然也可以做圖片伺服器叢集,提高圖片吞吐能力。
採用獨立域名
原因:同一域名下瀏覽器的併發連線數有限制,突破瀏覽器連線數的限制。
由於cookie的原因,對快取不利,大部分Web Cache都只快取不帶cookie的請求,導致每次的圖片請求都不能命中cache
獨立後的問題
如何進行圖片上傳和圖片同步
NFS共享方式,上傳到一臺伺服器進行NFS共享同步
利用FTP同步
介面方式,如七牛雲
C:服務端優化
①頁面靜態化處理(把現有的服務端的邏輯,比如PHP,請求PHP檔案的時候,把PHP的邏輯資料,要生成的要顯示的HTML內容快取成HTML程式碼,那麼速度更快,QPS也提高,對伺服器的負載壓力會減少很多)。
原因
動態指令碼通常會做邏輯運算和資料查詢,訪問量越大,伺服器器壓力越大。
訪問量大時可能會造成CPU負載過高,資料庫伺服器壓力過大,靜態化可以減低邏輯處理壓力,降低資料庫伺服器的查詢壓力
實現方式
使用Smarty快取機制生成靜態HTML快取檔案。
利用ob系列的函式。
http://www.cnblogs.com/wt645631686/p/6867923.html //簡單介紹和案例
②併發處理(如果使用者穿透了靜態化,比如我們做了靜態化,靜態化有設定過期時間,不可能永遠顯示之前的靜態資料,這樣動態的意義就不存在了。對於實時性比較高的資料,那麼做靜態化就不合理了,那麼需要穿透靜態化,繞過靜態化訪問真實資料,那麼就要做程式的併發處理,比如多執行緒多程式的非同步處理,比如做佇列的處理等等,從而提升請求響應速度,提高併發數)。
什麼是程式、執行緒、協程
程式
是計算機中程式關於某資料集合上的一次執行活動,是系統進行資源分配和排程的基本單位,是作業系統結構的基礎。也就是程式是一個執行中的程式。
程式的三態模型:多道程式系統中,程式在處理器上交替執行,狀態不斷髮生變化。因為我們的一個程式至少開啟一個程式,比如我們有三個程式,對於CPU來處理的時候,不會同時處理這三個程式,要交替處理,因為很快,所以我們感受不到是交替執行,其實是在快速切換的狀態。
①執行:當一個程式在處理機上執行的時候,則稱該程式處於執行狀態。處於此狀態的程式的數目小於等於處理器的數目,對於單處理機系統,處於執行狀態的程式只有一個。在沒有其他程式可以執行的時候(如果所有程式都在阻塞狀態)。通常會自動執行系統的空閒程式。
②就緒:當一個程式獲得了除處理機以外的所需資源,一旦得到處理機即可執行,則稱此程式處於就緒狀態。就緒程式可以按多個優先順序來劃分佇列。例如,當一個程式由於時間片用完而進入就緒狀態時,排入低優先順序佇列;當程式由I/O操作完成而進入就緒狀態時,排入高優先順序佇列。
③阻塞:也稱為等待或者睡眠狀態,一個程式正在等待某一事件發生(例如請求I/O而等待I/O完成等)而暫時停止執行,這時即使把處理機分配給程式也無法執行,故稱該程式處於阻塞狀態。
程式的五態模型:對於一個實際的系統,程式的狀態機器轉換更為複雜。
分類
新建態:對應於程式剛剛被建立時沒有被提交的狀態,並等待系統完成建立程式的所有必要資訊。
活躍就緒:是指程式在主存並且可被排程的狀態。
靜止就緒(掛起就緒):是指程式被對換到輔存時的就緒狀態,是不能被直接排程的狀態,只有當主存中沒有活躍就緒程式,或者是掛起就緒程式具有更高的優先順序,系統將把掛起就緒態程式調回主存並轉換為活躍就緒。
活躍阻塞:是指程式已在主存,一旦等待的事件產生便進入活躍就緒狀態。
靜止阻塞:程式對換到輔存時的阻塞狀態,一旦等待的事件產生便進入靜止就緒狀態。
終止態:程式已經結束,回收除程式控制塊之外的其他資源,並讓其他程式從程式控制塊中收集有關資訊。
由於使用者的併發請求,為每一個請求都建立一個程式顯然是行不通的,從系統資源開銷方面或者是相應使用者請求的效率方面來看。因此作業系統中執行緒的概念便被引進了。
執行緒
有時候被稱為輕量級的程式,是程式執行流程的最小單元。
執行緒是程式中的一個實體,是被系統獨立排程和分派的基本單位,執行緒自己不擁有系統資源,只擁有一點兒在執行中必不可少的資源,但它可與同屬一個程式的其它執行緒共享程式所擁有的全部資源。
一個執行緒可以建立和撤銷另一個執行緒,同一程式中的多個執行緒之間可以併發執行。
執行緒是程式中一個單一的順序控制流程。程式內一個相對獨立的、可排程的執行單元,是系統獨立排程和分派CPU的基本單位指執行中的程式的排程單位。
在單個程式中同時執行多個執行緒完成不同的工作,稱為多執行緒。
每一個程式都至少有一個執行緒,若程式只有一個執行緒,那就是程式本身了。
執行緒的狀態:就緒、阻塞、執行
就緒狀態:執行緒具備執行的所有條件,邏輯上可以執行,在等待處理機。
執行狀態:執行緒佔有處理機正在執行。
阻塞狀態:執行緒在等待一個事件,邏輯上不可執行。
協程
協程是一種使用者態的輕量級執行緒,協程的排程完全由使用者控制。協程擁有自己的暫存器上下文和棧。協程排程切換時,將暫存器上下文和棧儲存到其他地方, 在切回來的時候,恢復先前儲存的暫存器上下文和棧,直接操作棧則基本沒有核心切換的開銷,可以不加鎖的訪問全域性變數,所以上下文的切換非常快。協程有點兒類似輕量級的執行緒,但並不完全一樣,協程的排程由使用者控制,執行緒由作業系統控制。
執行緒與程式的區別
1:執行緒是程式內的一個執行單元,程式內至少有一個執行緒,它們共享程式的地址空間,而程式有自己獨立的地址空間。
2:程式是資源分配和擁有的單元,同一個程式內的執行緒共享程式的資源。
3:執行緒是處理器排程的基本單位,但程式不是。
4:兩者均可以併發執行。所謂併發執行指的是同時執行,但是要注意的是,這個併發執行交給處理機執行的時候,處理機是需要等待的,只不過處理機在執行的時候非常的快,因為CPU效能快,使用者感受不到,好像感覺同時執行。
5:每個獨立的執行緒有一個程式執行的入口、順序執行序列和程式的出口,但是執行緒不能夠獨立執行,必須依存在應用程式中,由應用程式提供多個執行緒執行控制。
執行緒跟協程的區別
1:一個執行緒可以多個協程,一個程式也可以單獨擁有多個協程。協程其實就是程式來程式控制的,比如我們想呼叫一個內容,我們可以從程式層面呼叫另外一個程式,是使用者操作的。
2:執行緒程式都是同步機制,而協程是非同步。
3:協程能保留上一次呼叫時的狀態,每次過程蟲入時,就相當於進入上一次呼叫的狀態。
什麼是多執行緒、多程式
多程式
同一個時間裡,同一個計算機系統中如果允許兩個或者兩個以上的程式處於執行狀態,這就是多程式。 比如我們在計算機上邊玩遊戲邊聽音樂,就是多程式。
多開一個程式,就會多分配一份資源,程式間通訊不方便,因為他們是獨立的。
多執行緒
執行緒就是把一個程式分為很多片,每一片都可以是一個獨立的流程,與多程式的區別是隻會使用一個程式的資源,執行緒間可以直接通訊。
舉例:
單程式單執行緒:一個人在一個桌子上吃飯,霸佔一個桌子。
單程式多執行緒:多個人在同一個桌子上吃飯。
多程式單執行緒:多個人每個人在自己的桌子上吃飯。
同步阻塞模型
多程式
最早的伺服器端程式都是通過多程式、多執行緒來解決併發IO的問題,一個請求建立一個程式,然後子程式進入迴圈同步阻塞地與客戶端連線進行互動,收發處理資料。
多執行緒
執行緒當中可以直接向某一個客戶端直接傳送資料。
舉例步驟:
①建立一個socket監聽
②進入while迴圈,阻塞在程式accept操作上,等待客戶端連線進入。
這就是一個阻塞的狀態。主程式在多程式模型下通過fork建立子程式出來
③多執行緒模式下可以建立子程式
④子程式/執行緒建立成功後進入while迴圈,阻塞在recv呼叫上,等待客戶端向伺服器傳送資料。
⑤收到資料後伺服器程式進行處理然後使用send向客戶端傳送響應
⑥當客戶端連線關閉時,子程式/執行緒退出並銷燬所有資源。主程式/執行緒會回收掉此子程式/執行緒。
缺點:這種模型嚴重依賴程式數量解決併發問題。啟用大量的程式會帶來額外的程式排程消耗,CPU 負載很嚴重。
非同步非阻塞模型
現在各種高併發非同步IO的伺服器程式都是基於epoll實現的,可以維持無限的連線,無需輪詢。
IO複用非同步非阻塞程式使用經典的Reactor模型,Reactor顧名思義就是反應堆的意思,它本身不處理任何資料收發。只是可以監聽一個socket控制程式碼的事件變化。
Reactor模型的四個核心操作
Add:新增一個SOCKET監聽到Reactor
Set:修改SOCKET對應的事件,可設定型別,如可讀可寫
Del:從Reactor中移除,不再監聽事件
CallBack:事件發生後調指定的函式
例子:Nginx(多執行緒Reactor),Swoole(多執行緒,多程式)
PHP併發程式設計實踐
PHP的Swoole擴充套件、訊息佇列、介面的併發請求(curl_multi_init)
③佇列處理
Kafka、ActiveMQ、ZeroMQ、RabbitMQ、Redis
D:資料庫的優化
①資料庫快取(Memcache或者Redis、MongoDB快取、Mysql自帶資料查詢快取)。
什麼是資料庫快取?
Mysql等一些常見的關係型資料庫的資料都儲存在磁碟當中嗎,在高併發場景下,業務應用對MySQL產生的增刪改查操作造成巨大的I/O壓力,這無疑對資料庫和伺服器都是較大壓力,為了解決此問題,快取資料的概念應用而生。
作用:
極大地解決資料庫伺服器的壓力、提高應用資料的響應速度
常見的快取形式:
記憶體快取(減少IO和磁碟開銷)、檔案快取
使用MySQL查詢快取
優點:極大地降低了CPU的使用率
query_cacche_type
查詢快取有0、1、2三個取值。0則不適用查詢快取。1標示始終是用查詢快取。2標示按需使用查詢快取。
query_cache_type為1時表示使用查詢快取,但是也可以在查詢的時候臨時關閉查詢快取
SELECT SQL_NO_CACHE * FROM....WHERE,這樣就可以避免使用本條語句的快取
query_cache_type為2時表示關閉查詢快取,但同樣也可以臨時使用查詢快取
SELECT SQL_CACHE * FROM...WHERE....
query_cache_size
預設情況下值為0,標示查詢快取預留的記憶體為0,則無法使用查詢快取。
可以通過語句臨時修改,當然也可以修改my.cnf 修改。
查詢快取可以看做是SQL文字和查詢結果的對映,第二次查詢的SQL和第一次查詢的SQL完全相同才會使用快取
SHOW STATUS LIKE 'Qcache_hits'; //檢視命中快取次數
如果表的結構或者資料發生改變了,查詢快取中的資料不再有效
清理快取
FLUSH QUERY CACHE; //清理查詢快取記憶體碎片
RESET QUERY CACHE; //從查詢中移出所有查詢快取
FLUSH TABLES; //關閉所有開啟的表我,同時該操作將會清空查詢快取中的內容
使用Memcache、Redis快取(兩者區別)
Redis和Memcache的效能其實相差不大,在進行選擇的時候不能通過效能,應該根據場景,比如進行持久化,必須Redis;比如複雜的資料結構模擬,那麼還要選擇Redis,因為Redis的型別多。
Redis在2.0版本後增加了自己的VM特性,突破實體記憶體的限制,Memache可以修改最大可用記憶體,採用LRU演算法。
Redis依賴客戶端實現分散式讀寫
Memcache本身沒有資料冗餘機制
Redis支援(快照和AOF持久化),依賴快照進行之九華,AOF增強了可靠性的同時,對效能有所影響。
Memcache本身不支援持久化,通常做快取提高效能
Memcache在併發場景下,用cas保證一致性,Redis事務支援比較弱,只能保證事務中的每個操作連續執行
Redis可以支援多種資料型別
Redis用於資料量較小的高效能操作和運算上,Memcache用於在動態系統中國減少資料庫負載,提升效能
②分庫分表、分割槽操作(如果做了快取,繞過了資料庫快取,量很大的話,我們需要分庫分表,做拆分,垂直和水平等)。
③讀寫分離(把一些伺服器完全分開,部分伺服器進行讀操作,部分做寫操作)。
④負載均衡
E:WEB伺服器優化
①負載均衡(用Nginx反向代理實現負載均衡,當然還有其他方法)。
②硬體優化