電商搜尋引擎的特點
眾所周知,標準的搜尋引擎主要分成三個大的部分,第一步是爬蟲系統,第二步是資料分析,第三步才是檢索結果。
首先,電商的搜尋引擎並沒有爬蟲系統,因為所有的資料都是結構化的,一般都是微軟的資料庫或者 Oracle 的資料庫,所以不用像百度一樣用「爬蟲」去不斷去別的網站找內容,當然,電商其實也有自己的「爬蟲」系統,一般都是抓取友商的價格,再對自己進行調整。
第二點,就是電商搜尋引擎的過濾功能其實比搜尋功能要常用。甚至大於搜尋本身。什麼是過濾功能?一般我們網站買東西的時候,搜了一個關健詞,比如尿不溼,然後所有相關品牌或者其他分類的選擇就會呈現在我們面前。對百度而言,搜什麼詞就是什麼詞,如果是新聞的話,可能在時間上會有一個過濾的選項。
第三點,電商搜尋引擎支援各種維度的排序,包括支援好評、銷量、評論、價格等屬性的排序。而且對資料的實時性的要求非常高。對一般的搜尋引擎,只有非常重要的網站,比如一些重量級的入口網站,百度的收錄是非常快的,但是對那些流量很小的網站,可能一個月才會爬一次。電商搜尋對資料的實時性要求主要體現在價格和庫存兩個方面。
電商搜尋引擎另一個特點就是不能丟品,比如我們在淘寶、天貓開了個店鋪,然後好不容易搞了一次活動,但是卻搜不到了,這是無法忍受的。除此之外,電商搜尋引擎與推薦系統和廣告系統是相互融合的,因為搜素引擎對流量的貢獻是最大的,所以大家都希望把廣告系統能跟其融合。當然,還有一點非常重要,就是要保證絕對的高可用,而且不能當機。
電商搜尋引擎的架構
因為電商搜尋引跟一般的搜尋引擎區別很大,所以在架構的設計上也獨具特色。
首先,搜尋引擎的實現方式有很多種,有谷歌、百度、搜狗這種非常大的公司,也有京東、淘寶、噹噹這樣的電商搜尋引擎,很多中小型的電商可能更喜歡用一個開源的搜尋引擎。所以總的來說,主要包括以下這幾種方式:

第一種是「Lucene+自己封裝」,只用來做檢索,然後封裝,後面所有的 ES,這兩個是完整的解決方案,而且包括索引所有的東西,只需要部署好業務邏輯,然後查詢結果就可以了。
第二種就是 Solr,這是一個高效能,採用 Java5 開發,基於 Lucene 的全文搜尋伺服器。同時對其進行了擴充套件,提供了比 Lucene 更為豐富的查詢語言,同時實現了可配置、可擴充套件並對查詢效能進行了最佳化,並且提供了一個完善的功能管理介面,是一款非常優秀的全文搜尋引擎。
第三種是 ElasticSearch,這是一個基於 Lucene 的搜尋伺服器。它提供了一個分散式多使用者能力的全文搜尋引擎,基於 RESTful web 介面。Elasticsearch 是用 Java 開發的,並作為 Apache 許可條款下的開放原始碼釋出,目前使用的也非常多。
這裡提一下,噹噹的搜尋引擎是自己實現的,。現在,新興的網際網路公司大部分都是使用第一種或者第二種,資料量比較大的一般採用第三種。
電商搜尋引擎標配模組

接下來我想講一下,如果我們自己做一個搜尋引擎的話需要實現哪些功能(上圖是電商搜尋引擎的標準模組),其實不止是電商搜尋引擎,除了通搜的搜尋引擎,其他的搜尋引擎也是使用這樣的標配。

對檢索模組而言,首先是對使用者的意圖進行分析,根據使用者的搜尋詞來進行純演算法的實現。比如使用者的搜尋詞是「黑包包」,其實使用者的本意就是買一個黑色的包,但是這個「包」可以跟別的片語合在一起,甚至在搜尋結果中會出現「包子」。所以,這就需要 query 分析系統來做,告訴檢索系統,你需要主要在服裝鞋帽中的分類去找,而不是生鮮食品類。
設計到技術層面,噹噹網使用的是 C++。如果構建一個效能好的系統,一些老一點的公司,大家都是在使用 C++ 或者是 C 語言。不止是噹噹網,其實很多公司都是使用的 C 或者 C++ 實現的搜尋引擎。
資料更新模組
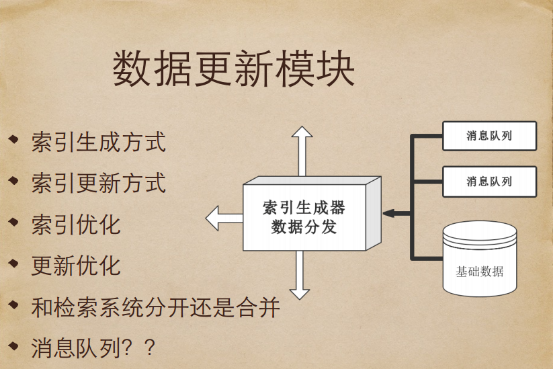
第二個模組就是資料更新模組,該模組負責生成索引。而資料中心模組主要做的事情,就是將原始的結構化資料,變成一個可供檢索系統使用的搜尋資料庫。當然,資料更新模組和檢索模組是分開還是合併呢?其實從本質上講,都是一堆程式碼,完全可以寫在一個程式裡。當然,也可以分開,透過網路往外輸入,各自都有道理。第一種是簡單粗暴型的,如果是普通電商,像生鮮電商,資料量不大,實時性、季節性很強,就可以把兩個系統用一個程式來完成。但是如果到了百萬、千萬甚至上億級別的話,就不可能部在一臺機器上了。