作者:袁建華,趙懷鵬,叢大瑋
一:導言
作為人工智慧的重要組成部分,情感智慧包括感知、理解、表達和控制情感的能力。雖然目前存在很多用來解決大規模社交網路資料的對話生成模型,但生成具有可控情感的文字仍然是一項巨大的挑戰。為推動情感文字生的相關研究,NLPCC 2017組織了情感對話生成(ECG)評測(NLPCC2017 shared task 4)。在給定一句中文的微博原文X = (x1,x2, …,xn)和一種使用者指定的情感emo的條件下,ECG旨在生成含有和指定情感的流暢且相關的答覆Y = (y1, y2, …, yn)。例如,給定一句微博原文“我昨天丟掉了工作”,回覆“我很遺憾”是合適的。
在本文中,我們提出了一套基於Seq2Seq模型生成情感回覆的系統——“HIT-SCIR-Babbling”。在傳統Seq2Seq模型基礎上,Babbling使用微博原句的情感embedding豐富原句的表示。Babbling還融合了Learning to Start (LTS)機制,從而生成更自然的句首詞。為了以提高生成詞語主題的相關性,Babbling還採用attention機制,我們將傳統的single hop attention 過程擴充套件到multi-hopattention,透過多次attention獲得更為抽象並且與微博原文相關的表示,從而進一步提高生成質量。
二: seq2seq 模型
首先,簡單介紹下我們用於情感對話生成的seq2seq模型。
從機率學的角度上來講,seq2seq模型相當於在尋找在給定微博原文 X = (x1, x2, …, xn) 的情況下,尋找目標回覆 Y = (y1,y2, … ym)使得p(Y|X)最大,即argmaxYp(Y|X)。在對話生成的場景中,我們使用Seq2Seq模型來最大化機率p(response | post)。在學習了條件分佈後,Seq2Seq模型透過尋找在給定post的情況下使這個條件機率最大的句子來生成一個合理的回答。
典型的Seq2Seq模型由一個編碼器和一個解碼器組成,這兩者通常用RNN及其變種(LSTM,GRU等)實現。我們的編碼器和解碼器都使用了一個單向兩層的GRU。
在本框架中,解碼器每個位置利用編碼器每個隱層,形成上下文向量c。通常c的計算為
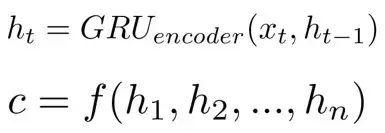
其中,ht是在t時刻的隱層狀態,c是透過隱層狀態計算得來的上下文向量。通常透過attention機制使用所有的隱層狀態來計算c。
在解碼時,透過解碼部分前文表示和前一個預測的詞來預測下一個詞yt。這樣,在t時刻解碼器的隱藏狀態可以表示為
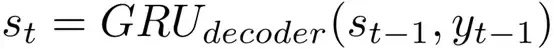
因此,在解碼部分的條件機率定義為

其中,ct是在t步中用來預測當前詞的上下文向量。
最後,在t時刻詞可以透過匹配整個詞表的可能性來計算。
僅僅透過普通的Seq2Seq模型來生成話題相關流暢的回答是一個巨大的挑戰,所以我們將幾種技術整合到基本的Seq2Seq模型中來改善生成內容的質量和情感一致性。我們的方法如圖1所示。
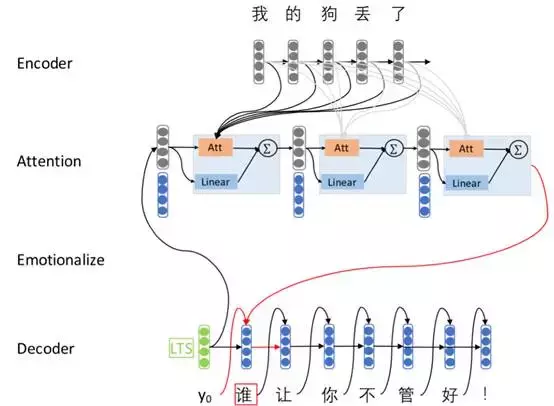
圖一:我們使用multi-hop attention,LTS和情感embeddings的Seq2Seq模型圖解
2.1 multi-hop attention
理想情況下,編碼器能將原文序列中的所有資訊都編碼成一個固定長度的上下文向量c。然而,Bahdanau 等發現了固定長度的向量c :1)可能因為丟掉了在序列開始出現的詞的資訊而不會保留所有在原文序列中出現的有用資訊;2)在解碼預測時,不能建模在原文序列出現的不同詞的不同貢獻。為解決在基本的Seq2Seq模型中出現的這些問題,他們提出了一種attention機制,所有原文序列的隱層輸出都將被使用而非最後一層隱層輸出。這種方式對於解碼器中每個時刻的上下文向量都是不同的,表示為

這裡,解碼器的第i個隱層輸出的權重aij 的計算為
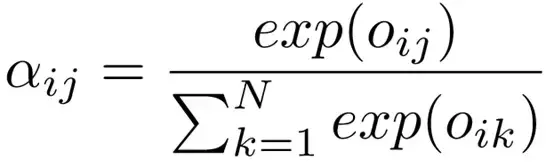

其中,a是一個非線性激勵函式,如sigmod或tanh,能夠被看作是在解碼器中的隱層狀態和編碼器中隱層輸出相似性測量。
多層的神經網路有著更強的表示能力。從這些工作中受到啟發,我們把單層的attention擴充到多層。每層挑選出更重要的上下文詞語,把前一層表示轉換為更高層更抽象的表示。透過多次的attention處理可以得到一個更好的原文表示,我們希望這有助於處理語義和情感組合的問題。
2.2 LTS:learning to start
在多數Seq2Seq模型中,起始符號通常是固定的,用於解碼器中生成的第一個詞前的詞。雖然第一個詞的初始化是一個容易被人忽略的小細節,但我們認為它是Seq2Seq模型中的重要組成部分。然而,起始符號不能區分不同的原文輸入,這會導致模型傾向於預測高頻詞。為解決這樣的問題,我們在解碼中使用Learning To Start (LTS)生成預測序列中的第一個詞。第一個詞的可能性的計算為
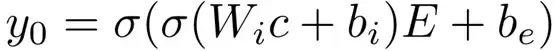
其中,c是上下文向量,這裡是編碼器的最後一層隱層狀態,Wi是在模型中學習到的權重矩陣,bi,be是偏置向量,E是解碼器的embedding矩陣,σ是非線性激勵函式。
直觀上,上述公式建立了解碼器中上下文向量和embedding 空間之間的聯絡,這使原文序列和在所有預測候選詞中的資訊相關聯。注意,第一個詞的生成僅取決於編碼器的狀態,這和原句子不同,也消除了起始符號的影響,共同減少了編碼器的資訊損失。
2.3 emotion embeddings
為使模型能生成使用者指定情感類別的回覆,我們引入情感類別embeddings。我們在attention過程中加入情感類別資訊,它直接指導上下文資訊的選擇和生成回覆的情感傾向變化。我們隨機初始化情感embedding,與模型的其他部分共同參與訓練。解碼器中的條件機率計算方式如下:

其中,et是使用者指定類別的情感embedding.
三 實驗
3.1 資料集
我們訓練模型使用的大規模資料集來自微博,包含1119207對(post, response)。資料集的統計如表1所示。我們使用Bi-LSTM給出的微博和原文的情感標籤,並且視覺化情感轉移資訊的分佈情況,如圖2所示。
表1:資料集的統計資訊

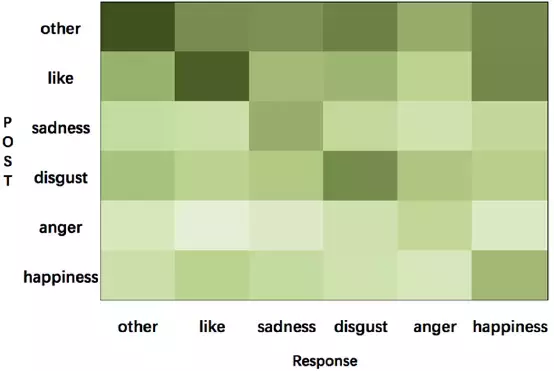
圖2:微博訓練資料上從post到response的情感轉移視覺化,顏色深度代表著每種型別轉換的比例
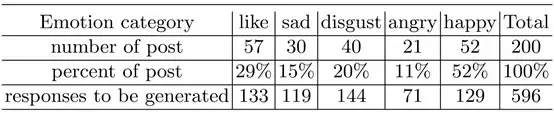
由於目前還沒有評估生成結果的標準方法,所以NLPCC 2017 Shared Task 4採用人工評估。如果回覆的內容是流暢、合適的得一分,如果回覆文字的情感和使用者指定的情感類別一致,則再加一分。因為人工評估所有的提交結果很費時費力,所以選擇200個微博原文作為最終評估集。人工評價部分的資料集統計資料如表2所示。
表2:最終評測集的統計資料
3.2 模型實現
我們編碼器和解碼器均使用隱層維度為200的雙層GRU。編碼器和解碼器使用不同的詞表,其中在post、response中詞頻不超過5的詞將會被刪除,使用UNK代替這些不常見的詞,並在post和response中新增結束符號。我們設定word embedding和emotion size大小為100。根據對post和response句子長度的分析,我們設定post和response的長度為10,batch設為64,透過取樣正態分佈(-0.1,0.1)初始化引數。我們使用sampled softmax 加速預測過程。我們的模型使用Tensorflow 0.12實現。
3.3 結果
在這一部分,我們根據生成結果對我們的模型進行定性分析。
LTS的有效性。我們比較了基本的Seq2Seq模型和使用LTS擴充套件的模型。表3中的例子顯示,使用LTS可以產生更好的第一個詞,更流利和話題相關的回答。LTS能夠改善第一個詞和整個句子的質量。
表3:基本Seq2Seq模型和LTS擴充套件生成結果的對比

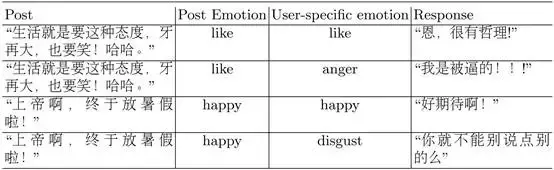
使用情感embedding帶來的情感轉變。圖2展示了訓練資料情感轉移的分佈(emotion transition)。我們可以看到回答通常使用和post相同的情感標籤。例如,帶有“like”標籤的post少見有帶有”anger”標籤的回答,反之亦然。一部分從“like”到“happiness”的轉換和從“happiness”到“like”的轉換是相似的,這表現了兩種情感是相接近的,也意味著對於情感分類器來說區分“like”和“happiness”是有一定難度的。換句話說,情感分類器的效果對情感回答生成有著很大的影響。在attention過程使用情感embedding後,Seq2Seq模型能夠生成使用者指定情感,如表4所示。在我們的模型中,attention過程中的情感embedding在情感對話生成中是至關重要的。
表4:帶有情感embedding的Seq2Seq模型生成的使用者指定情感的回答例句
四: 總結
在這項工作中,我們提出了基於神經網路的情感回覆系統HIT-SCIR-Babbling,我們在Seq2Seq結構中使用了LTS,MTA和情感embedding,並透過生成例句解釋了這些方法的有效性。
本期責任編輯: 劉一佳
本期編輯: 趙懷鵬