
有一個問題需要解決:自動分類。做好個性化商品推薦,商品整理是第一站。類目,是最為基礎的整理。我們需要將每一個商品分到一個具體的類目上去,商品數量龐大,這個過程要自動化,這就是商品自動分類問題。
我們來熱熱身吧,做幾道分類題:
“AppleiPhone6(A1586)16GB金色移動聯通電信4G手機”
【第一滴血】so easy,是一個“手機”
“snidel * S家新款王小俊日系蓬蓬裙雙層鬆緊高腰短裙裙褲現貨實拍”
【主宰分類】嗯……應該是“半身裙”,這個要分對就需要動一動腦子
“華為 HUAWEI 電源介面卡+資料線 5V/2A快充 USB帶線充電頭”
【分類如麻】這個是“充電器”,來個有點難度的
“福建特產 正宗金冠黑糖話梅糖200g 含上等梅肉 酸甜好滋味”
【無人能擋】這個……是糖果,有沒有更變態的
“美利達勇士公爵500 550 600 650 700挑戰者350可載人行李架後貨架”
【變態分類】 靠關鍵詞聯想已經不夠了,查資料後知這是一個“腳踏車配件”,哈哈,還有誰?!
“比iphone還好用的諾基亞手機的手機套”
【已經超神】這……
你看,解決這個問題並沒有看上去那麼簡單,每個商品標題中不會100%包含類目相關資訊,怎麼破?
分類1.0
我們研發的一代分類技術是比較樸素的,透過對應表+特徵庫來解決。
對應表是一個簡單的配置檔案,儲存(關鍵詞,分類)的對應關係:
“手機” ——> 手機
“牛仔褲” ——> 牛仔褲
…….
特徵詞庫是對應表的升級版(對應表plus?),維護的是(關鍵片語合,分類)的對應關係:
“AppleiPhone6” ——> 手機
“棉麻 小腳 長褲 收腰 鉛筆褲” ——> 休閒長褲
“美利達 勇士 公爵 行李架 貨架” ——> 腳踏車配件
…….
這一整套樣本資料完全由人工整理,分類1.0的程式也很簡單,執行起來嘛……,“看上去”很可靠。首先,分類1.0一切的一切都建立在人工資料基礎上,只要樣本整理的好,分的結果就好,整理的不好就……。其次,人的精力是有限的,如果要大規模標註,就需要維持大規模的運營團隊。最後,人沒有整理過的商品特徵,就沒辦法分好,bug數量處於失控狀態。
隨著資料指標的要求提升,資料集的增長,這套系統已經不堪重負。
分類2.0
因此,我們研發了新系統——分類2.0。分類2.0結合商品資訊的特徵,避免了由於特徵庫對分類帶來的干擾,同時可以保證以較高的效率完成線上分類任務。(分類2.0由我司一枚殿堂級工程師所創作,哎呀,現在回想起來,那一段時光真是令人懷念……)
分類2.0的技術要點
1.使用分詞技術對商品標題資訊分詞處理,使用分詞結果作為商品的特徵tag,用tag來描述該商品
2.過濾沒有意義的tag,保留能夠有效描述該商品的tag
3.利用互資訊計算訓練集資料中,各個分類和該分類中商品所有tag的相關度
4.預測一個新商品的類別時,計算該商品中的所有tag在每個分類中相關度值,使用分類中所有tag相關度值的和作為商品在該分類中的得分
5.得分最高的類別即為該商品的分類
以一個具體的商品處理來說清楚這個流程,:
1.基於商品庫對商品進行分詞處理&過濾無意義詞
如:黑色iphone蘋果手機新上市,分詞&過濾結果為:iphone,手機,黑色
2.利用互資訊計算各分類與其中tag的相關度:
互資訊計算公式:
I(x,y) = log(p(x|y))-log(p(x))
其中:
p(x) 代表 x在所有商品中出現的機率
p(x|y)代表x在類別y中出現的條件機率
下表為10個商品的類別及分詞結果
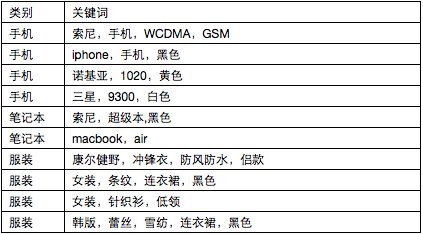
計算示例商品在上面的商品集中,手機類的互資訊
a)機率計算
p(iphone) = 0.1
p(黑色) = 0.4
p(手機) = 0.2
p(iphone |手機) = 0.25
p(手機|手機) = 0.5
p(黑色|手機) = 0.25
b)互資訊計算
I(iphone,手機) = log(p(iphone |手機))-log(p(iphone)) = -1.3863 + 2.3026 = 0.9163
I(手機,手機) = log(p(手機|手機))-log(p(手機)) = -0.6931 + 1.6094 = 0.9163
I(黑色,手機) = log(p(黑色|手機))-log(p(黑色)) = -1.3863 + 0.9163 = -0.47
c) 以此類推,可以算出iphone,手機,黑色三個關鍵詞在3個類別中分別的條件機率以及互資訊
下表為關鍵詞在各個類別中的互資訊
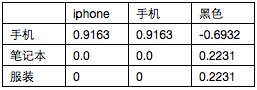
3.計算1中示例商品在各個分類中的相關度
Class(手機)= 0.9163+0.9163-0.6932=1.1394
Class(電腦)=0.0+0.0+0.2231=0.2231
Class(服裝)= 0.0+0.0+0.2231=0.2231
4.由3可以看出示例商品分類為“手機”類別
我們用這套分類2.0系統,重新處理所有商品,隨著訓練集的不斷擴充套件,準確率和召回率都在90%以上;同時也解放了運營團隊,他們不需要再每天標記什麼對應表了。
這,就是演算法的力量!一個好的演算法可以極大的提高生產力。透過演算法提升產品流程,需要很強的功力,否則就像篇頭漫畫所表達的,不好的演算法上線後,效果還可能退步。總之,演算法研究就像基礎科學,需長期投入,一旦開花,提升是極大的。