轉載:http://mp.weixin.qq.com/s/uWPls0qrqJKHkHfNLmaenQ
導語
Http 快取機制作為 web 效能最佳化的重要手段,對從事 Web 開發的小夥伴們來說是必須要掌握的知識,但最近我遇到了幾個快取頭設定相關的題目,發現有好幾道題答錯了,有的甚至在知道了正確答案後依然不明白其原因, 可謂相當的鬱悶呢!!為了確認下是否只是自己理解不深,我特意請教了其他幾位小夥伴,發現情況也或多或少和我類似。
為了不給大家賣關子,下面我貼出2道題,大家可以嘗試解答下:
以下為 page.html 內容:
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>page頁</title></head><body>
<img src="images/head.png" />
<a href="page.html">重新訪問page頁</a></body></html>
首次訪問該頁面,頁面中 head.png 響應頭資訊如下:
HTTP/1.1 200 OK
Cache-Control: no-cache
Content-Type: image/png
Last-Modified: Tue, 08 Nov 2016 06:59:00 GMT
Accept-Ranges: bytes
Date: Thu, 10 Nov 2016 02:48:50 GMT
Content-Length: 3534
以上2道題,如果你能全部答對(哈哈,還請仔細確認下 why,以防歪打正著),那麼恭喜你,你已對這些知識理解非常透徹了,我後面講的內容你可以忽略,否則還請繼續陪我往下嘮嘮吧!
首 先回到開篇提到很多小夥伴(包括我)在解答 Http 快取題目時栽跟頭的問題,我覺得出現這種現象的根本原因在於我們吸收的知識還不夠體系化,平時我們在學習這些知識時多半將其當作知識點來記,什麼這個快取 頭作什麼、那個快取頭作什麼用的,但實際中快取頭往往是多個之間相互配合協同工作的,有一套完整的工作體系。
今天我將按自己的理解,從系統體系化角度來講講 Http 快取頭是如何協同工作的(不正確的地方還請指正,但請不要噴我哦):
HTTP 快取體系
首先我將 Http 快取體系分為以下三個部分:
1. 快取儲存策略
用來確定 Http 響應內容是否可以被客戶端快取,以及可以被哪些客戶端快取
這個策略的作用只有一個,用於決定 Http 響應內容是否可快取到客戶端
對 於 Cache-Control 頭裡的 Public、Private、no-cache、max-age 、no-store 他們都是用來指明響應內容是否可以被客戶端儲存的,其中前4個都會快取檔案資料(關於 no-cache 應理解為“不建議使用本地快取”,其仍然會快取資料到本地),後者 no-store 則不會在客戶端快取任何響應資料。另關於 no-cache 和 max-age 有點特別,我認為它是一種混合體,下面我會講到。
通 過 Cache-Control:Public 設定我們可以將 Http 響應資料儲存到本地,但此時並不意味著後續瀏覽器會直接從快取中讀取資料並使用,為啥?因為它無法確定本地快取的資料是否可用(可能已經失效),還必須借 助一套鑑別機制來確認才行, 這就是我們下面要講到的“快取過期策略”。
2. 快取過期策略
客戶端用來確認儲存在本地的快取資料是否已過期,進而決定是否要發請求到服務端獲取資料
這個策略的作用也只有一個,那就是決定客戶端是否可直接從本地快取資料中載入資料並展示(否則就發請求到服務端獲取)
剛 上面我們已經闡述了資料快取到了本地後還需要經過判斷才能使用,那麼瀏覽器透過什麼條件來判斷呢? 答案是:Expires,Expires 指名了快取資料有效的絕對時間,告訴客戶端到了這個時間點(比照客戶端時間點)後本地快取就作廢了,在這個時間點內客戶端可以認為快取資料有效,可直接從 快取中載入展示。
不過 Http 快取頭設計並沒有想象的那麼規矩,像上面提到的 Cache-Control(這個頭是在Http1.1里加進來的)頭裡的 no-cache 和 max-age 就是特例,它們既包含快取儲存策略也包含快取過期策略,以 max-age 為例,他實際上相當於:
Cache-Control:public/private(這裡不太確定具體哪個)
Expires:當前客戶端時間 + maxAge 。
而 Cache-Control:no-cache 和 Cache-Control:max-age=0 (單位是秒)相當
這裡需要注意的是:
-
Cache-Control 中指定的快取過期策略優先順序高於 Expires,當它們同時存在的時候,後者會被覆蓋掉。
-
快取資料標記為已過期只是告訴客戶端不能再直接從本地讀取快取了,需要再發一次請求到伺服器去確認,並不等同於本地快取資料從此就沒用了,有些情況下即使過期了還是會被再次用到,具體下面會講到。
3. 快取對比策略
將快取在客戶端的資料標識發往服務端,服務端透過標識來判斷客戶端 快取資料是否仍有效,進而決定是否要重發資料。
客 戶端檢測到資料過期或瀏覽器重新整理後,往往會重新發起一個 http 請求到伺服器,伺服器此時並不急於返回資料,而是看請求頭有沒有帶標識( If-Modified-Since、If-None-Match)過來,如果判斷標識仍然有效,則返回304告訴客戶端取本地快取資料來用即可(這裡要 注意的是你必須要在首次響應時輸出相應的頭資訊(Last-Modified、ETags)到客戶端)。至此我們就明白了上面所說的本地快取資料即使被認 為過期,並不等於資料從此就沒用了的道理了。
關於 Last-Modified,這個響應頭使用要注意,可能會影響到快取過期策略,具體原因,後面我會透過解答開篇提到的2道題來作說明。
以上就是我所認識的快取策略,下面我將快取策略三要素和常用的幾個快取頭(項)結合一起,讓大家更清晰的認識到它們之間的關係:
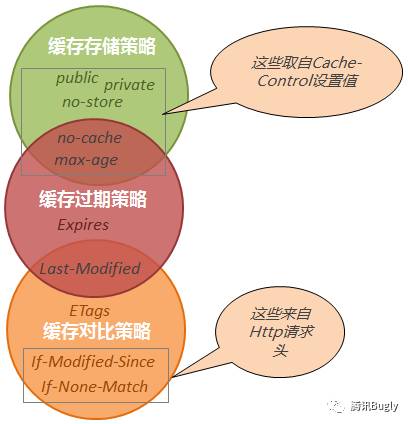
透過上圖我可以清晰的看到各快取項分別屬於哪個快取策略範疇,這其中有部分重疊,它表明這些快取項具有多重快取策略,所以實際在分析快取頭的時候,除了常規的頭外,我們還需要將這些具有雙重快取策略的項分解開來。
最後我們回到最開始提到的2道題目,我們來一起分解下:
第一道題:
HTTP/1.1 200 OK
Cache-Control: no-cache
Content-Type: image/png
Last-Modified: Tue, 08 Nov 2016 06:59:00 GMT
Accept-Ranges: bytes
Date: Thu, 10 Nov 2016 02:48:50 GMT
Content-Length: 3534
分析上述 Http 響應頭發現有以下兩項與快取相關:
Cache-Control: no-cache
Last-Modified: Tue, 08 Nov 2016 06:59:00 GMT
我們上面講到了 Cache-Control: no-cache 相當於 Cache-Control: max-age=0,且他們都是多重策略頭,我們需將其分解:
Cache-Control: no-cache 等於 Cache-Control: max-age=0,
接著 Cache-Control: max-age=0 又可分解成:
Cache-Control: public/private (不確定是二者中的哪一個)
Expires: 當前時間
最終我們得到了以下完整的快取策略三要素:
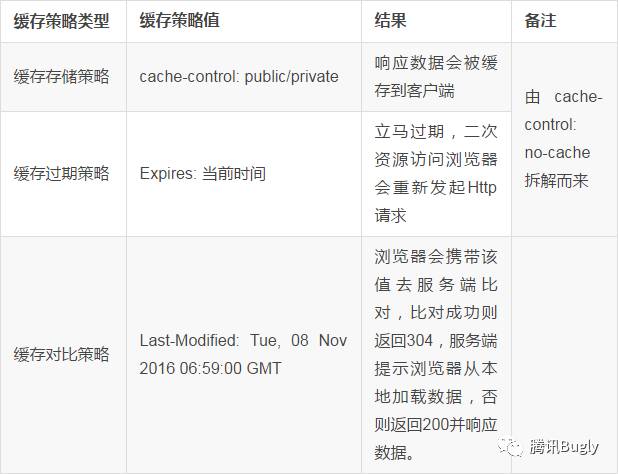
所以最終結果是:瀏覽器會再次請求服務端,並攜帶上 Last-Modified 指定的時間去伺服器對比:
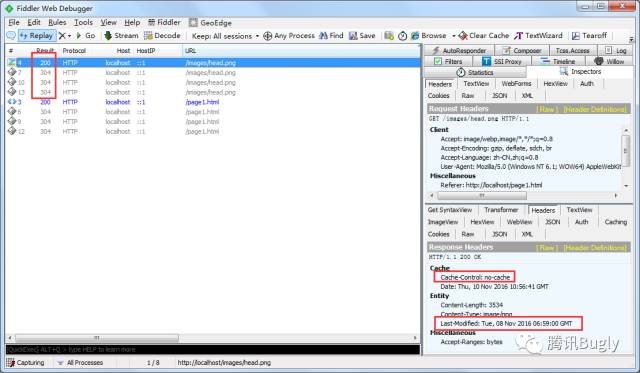
這道題本身不難,但若認為 no-cache 不會快取資料到本地,那麼你理解起來就會很矛盾,因為如果檔案資料沒有被本地快取,伺服器返回304後將會無法展示出圖片內容,但實際上它是能正常展示的。這道題很好的證明了 no-cache 也會快取資料到本地這一說法。
第二道題:
HTTP/1.1 200 OK
Cache-Control: private
Content-Type: image/png
Last-Modified: Tue, 08 Nov 2016 06:59:00 GMT
Accept-Ranges: bytes
Date: Thu, 10 Nov 2016 02:48:50 GMT
Content-Length: 3534
解題思路和上題一樣,首先先找到快取相關項:
Cache-Control: private
Last-Modified: Tue, 08 Nov 2016 06:59:00 GMT
這時我們會發現根本找不到快取過期策略項,那答案會不會和上面一樣? 一時半會也分析不出答案,那隻能實際測試下了:
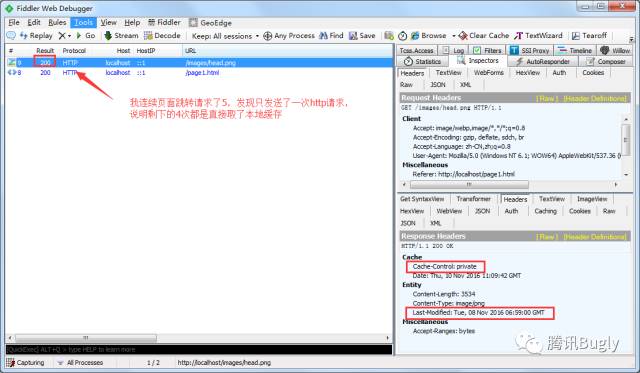
再看看 Chrome 瀏覽器下抓包:

可以看到,瀏覽器後續請求都直接取的本地快取,看來的確存在某種快取過期策略(根據我上面的快取過期策略理論,瀏覽器如果直接從本地載入快取資料,說明它 相信本地快取資料有效,那一定存在某種快取過期判斷條件)。這個問題百思不得其解,困擾了我好久,直到一次偶然的機會我在 Fiddler 響應資訊皮膚裡的 Caching 選項卡中找到了答案:
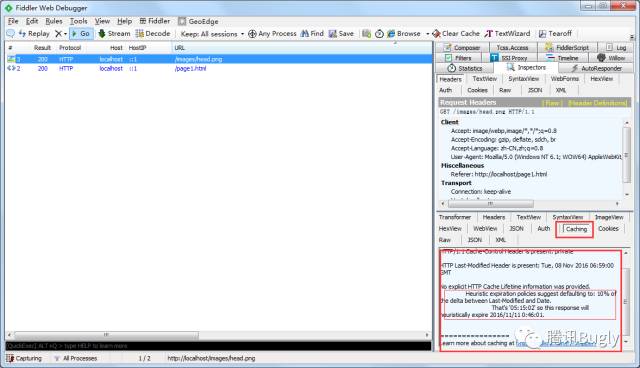
原來,在沒有提供任何瀏覽器快取過期策略的情況下,瀏覽器遵循一個啟發式快取過期策略:
根據響應頭中2個時間欄位 Date 和 Last-Modified 之間的時間差值,取其值的10%作為快取時間週期。
貼一下Caching皮膚裡的描述,英語好的同學可以精準翻譯下:
HTTP/1.1 Cache-Control Header is present: private
HTTP Last-Modified Header is present: Tue, 08 Nov 2016 06:59:00 GMT
No explicit HTTP Cache Lifetime information was provided.
Heuristic expiration policies suggest defaulting to: 10% of the delta between Last-Modified and Date.
That's '05:15:02' so this response will heuristically expire 2016/11/11 0:46:01.
最終我們得到了以下完整的快取策略三要素:
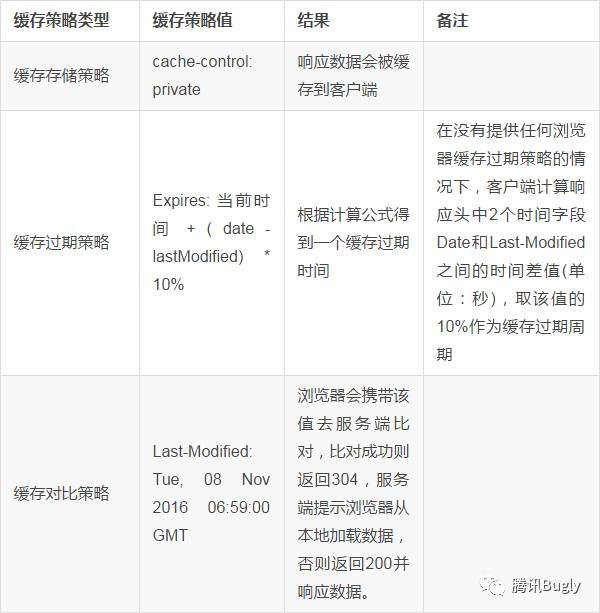
最終結果
瀏 覽器會根據 Date 和 Last-Modified 之間的時間差值快取一段時間,這段時間內會直接使用本地快取資料而不會再去請求伺服器(強制請求除外),快取過期後,會再次請求服務端,並攜帶上 Last-Modified 指定的時間去伺服器對比並根據服務端的響應狀態決定是否要從本地載入快取資料。
總結
Http 快取設定起來並不複雜,但卻容易被輕視, 今天這篇文章結合2道題目,透過分析、解剖相關快取頭,從系統化角度對 Http 快取機制做了一個較完整的剖析:Http 快取機制實際上是 Http 快取策略三個要素(緯度)相互作用的集合,所以在分析和設定 Http 報文快取頭時,只要能從中精準的分解出快取三要素,我們就能非常準確的預判到快取設定最終能達到的效果。