之前梳理了Mysql+Keepalived雙主熱備高可用操作記錄,對於mysql高可用方案,經常用到的的主要有下面三種:
一、基於主從複製的高可用方案:雙節點主從 + keepalived
一般來說,中小型規模的時候,採用這種架構是最省事的。 兩個節點可以採用簡單的一主一從模式,或者雙主模式,並且放置於同一個VLAN中,在master節點發生故障後,利用keepalived/heartbeat的高可用機制實現快速 切換到slave節點。 在這個方案裡,有幾個需要注意的地方: 採用keepalived作為高可用方案時,兩個節點最好都設定成BACKUP模式,避免因為意外情況下(比如腦裂)相互搶佔導致往兩個節點寫入相同資料而引發衝突; 1)把兩個節點的auto_increment_increment(自增步長)和auto_increment_offset(自增起始值)設成不同值。其目的是為了避免master節點意外當機時, 可能會有部分binlog未能及時複製到slave上被應用,從而會導致slave新寫入資料的自增值和原先master上衝突了,因此一開始就使其錯開;當然了,如果有合適的 容錯機制能解決主從自增ID衝突的話,也可以不這麼做; 2)slave節點伺服器配置不要太差,否則更容易導致複製延遲。作為熱備節點的slave伺服器,硬體配置不能低於master節點; 3)如果對延遲問題很敏感的話,可考慮使用MariaDB分支版本,或者直接上線MySQL 5.7最新版本,利用多執行緒複製的方式可以很大程度降低複製延遲; 4)對複製延遲特別敏感的另一個備選方案,是採用semi sync replication(就是所謂的半同步複製)或者後面會提到的PXC方案,基本上無延遲,不過事務併發性 能會有不小程度的損失,需要綜合評估再決定; 5)keepalived的檢測機制需要適當完善,不能僅僅只是檢查mysqld程式是否存活,或者MySQL服務埠是否可通,還應該進一步做資料寫入或者運算的探測,判斷響 應時間,如果超過設定的閾值,就可以啟動切換機制; 6)keepalived最終確定進行切換時,還需要判斷slave的延遲程度。需要事先定好規則,以便決定在延遲情況下,採取直接切換或等待何種策略。直接切換可能因為復 制延遲有些資料無法查詢到而重複寫入; 7)keepalived或heartbeat自身都無法解決腦裂的問題,因此在進行服務異常判斷時,可以調整判斷指令碼,通過對第三方節點補充檢測來決定是否進行切換,可降低腦 裂問題產生的風險。
雙節點主從+keepalived/heartbeat方案架構示意圖見下:
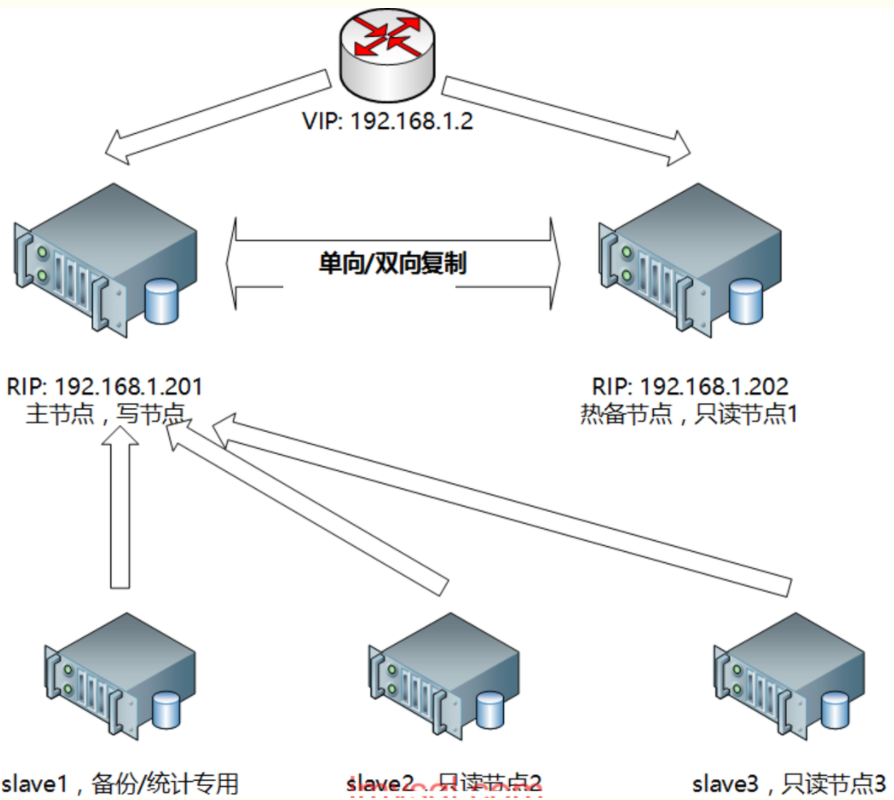
二、基於主從複製的高可用方案:多節點主從+MHA/MMM
多節點主從,可以採用一主多從,或者雙主多從的模式。 這種模式下,可以採用MHA或MMM來管理整個叢集,目前MHA應用的最多,優先推薦MHA,最新的MHA也已支援MySQL 5.6的GTID模式了,是個好訊息。 MHA的優勢很明顯: 1)開源,用Perl開發,程式碼結構清晰,二次開發容易; 2)方案成熟,故障切換時,MHA會做到較嚴格的判斷,儘量減少資料丟失,保證資料一致性; 3)提供一個通用框架,可根據自己的情況做自定義開發,尤其是判斷和切換操作步驟; 4)支援binlog server,可提高binlog傳送效率,進一步減少資料丟失風險。 不過MHA也有些限制: 1)需要在各個節點間打通ssh信任,這對某些公司安全制度來說是個挑戰,因為如果某個節點被黑客攻破的話,其他節點也會跟著遭殃; 2)自帶提供的指令碼還需要進一步補充完善,當然了,一般的使用還是夠用的。
三、基於Galera協議的高可用方案:PXC
Galera是Codership提供的多主資料同步複製機制,可以實現多個節點間的資料同步複製以及讀寫,並且可保障資料庫的服務高可用及資料一致性。 基於Galera的高可用方案主要有MariaDB Galera Cluster和Percona XtraDB Cluster(簡稱PXC),目前PXC用的會比較多一些。 mariadb的叢集原理跟PXC一樣,maridb-cluster其實就是PXC,兩者原理是一樣的。
下面重點介紹下基於PXC的mysql高可用環境部署記錄。
1、PXC介紹
Percona XtraDB Cluster(簡稱PXC叢集)提供了MySQL高可用的一種實現方法。 1)叢集是有節點組成的,推薦配置至少3個節點,但是也可以執行在2個節點上。 2)每個節點都是普通的mysql/percona伺服器,可以將現有的資料庫伺服器組成叢集,反之,也可以將叢集拆分成單獨的伺服器。 3)每個節點都包含完整的資料副本。 PXC叢集主要由兩部分組成:Percona Server with XtraDB和Write Set Replication patches(使用了Galera library,一個通用的用於事務型應用的同步、多主複製外掛)。
2、PXC特性
1)同步複製,事務要麼在所有節點提交或不提交。 2)多主複製,可以在任意節點進行寫操作。 3)在從伺服器上並行應用事件,真正意義上的並行複製。 4)節點自動配置,資料一致性,不再是非同步複製。 PXC最大的優勢:強一致性、無同步延遲
3、PXC優缺點
PXC的優點 1)服務高可用; 2)資料同步複製(併發複製),幾乎無延遲; 3)多個可同時讀寫節點,可實現寫擴充套件,不過最好事先進行分庫分表,讓各個節點分別寫不同的表或者庫,避免讓galera解決資料衝突; 4)新節點可以自動部署,部署操作簡單; 5)資料嚴格一致性,尤其適合電商類應用; 6)完全相容MySQL; 雖然PXC有這麼多好處,但也有些侷限性: 1)只支援InnoDB引擎;當前版本(5.6.20)的複製只支援InnoDB引擎,其他儲存引擎的更改不復制。然而,DDL(Data Definition Language) 語句在statement級別 被複制,並且,對mysql.*表的更改會基於此被複制。例如CREATE USER...語句會被複制,但是 INSERT INTO mysql.user...語句則不會。 (也可以通過wsrep_replicate_myisam引數開啟myisam引擎的複製,但這是一個實驗性的引數)。 2)PXC叢集一致性控制機制,事有可能被終止,原因如下:叢集允許在兩個節點上同時執行操作同一行的兩個事務,但是隻有一個能執行成功,另一個會被終止,叢集會給被終止的 客戶端返回死鎖錯誤(Error: 1213 SQLSTATE: 40001 (ER_LOCK_DEADLOCK)). 3)寫入效率取決於節點中最弱的一臺,因為PXC叢集採用的是強一致性原則,一個更改操作在所有節點都成功才算執行成功。 4)所有表都要有主鍵; 5)不支援LOCK TABLE等顯式鎖操作; 6)鎖衝突、死鎖問題相對更多; 7)不支援XA; 8)叢集吞吐量/效能取決於短板; 9)新加入節點採用SST時代價高; 10)存在寫擴大問題; 11)如果併發事務量很大的話,建議採用InfiniBand網路,降低網路延遲; 事實上,採用PXC的主要目的是解決資料的一致性問題,高可用是順帶實現的。因為PXC存在寫擴大以及短板效應,併發效率會有較大損失,類似semi sync replication機制。
4、PXC原理描述
分散式系統的CAP理論: C:一致性,所有的節點資料一致 A:可用性,一個或者多個節點失效,不影響服務請求 P:分割槽容忍性,節點間的連線失效,仍然可以處理請求 其實,任何一個分散式系統,需要滿足這三個中的兩個。 PXC會使用大概是4個埠號 3306:資料庫對外服務的埠號 4444:請求SST SST: 指資料一個鏡象傳輸 xtrabackup , rsync ,mysqldump 4567: 組成員之間進行溝通的一個埠號 4568: 傳輸IST用的。相對於SST來說的一個增量。 一些名詞介紹: WS:write set 寫資料集 IST: Incremental State Transfer 增量同步 SST:State Snapshot Transfer 全量同步 PXC環境所涉及的埠: #mysql例項埠 10Regular MySQL port, default 3306. #pxc cluster相互通訊的埠 2)Port for group communication, default 4567. It can be changed by the option: wsrep_provider_options ="gmcast.listen_addr=tcp://0.0.0.0:4010; " #用於SST傳送的埠 3)Port for State Transfer, default 4444. It can be changed by the option: wsrep_sst_receive_address=10.11.12.205:5555 #用於IST傳送的埠 4)Port for Incremental State Transfer, default port for group communication + 1 (4568). It can be changed by the option: wsrep_provider_options = "ist.recv_addr=10.11.12.206:7777; "
PXC的架構示意圖:
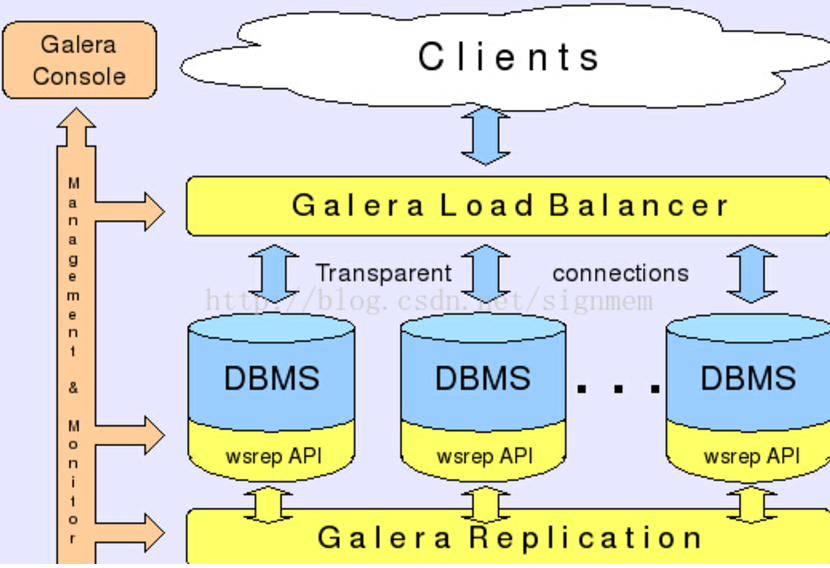
資料讀寫示意圖

---------------------------------------下面看下傳統複製流程----------------------------------
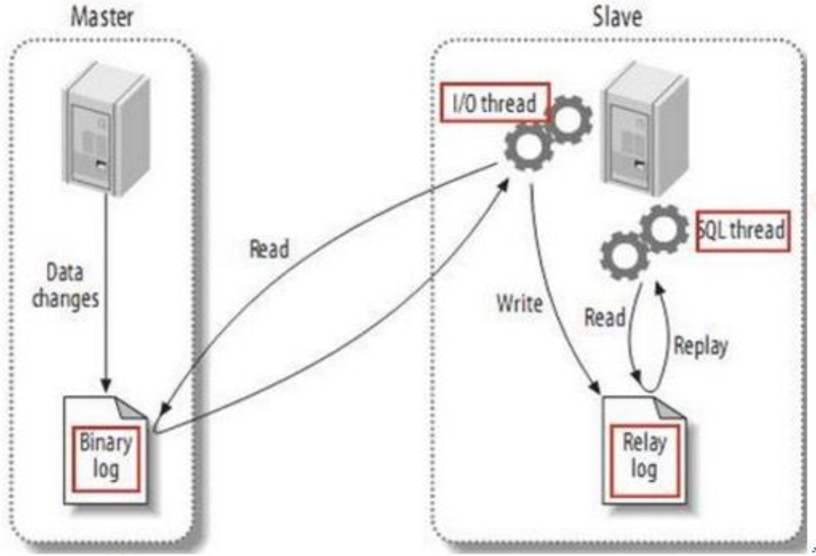
非同步複製
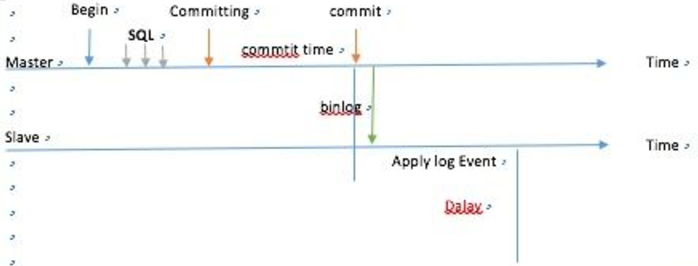
半同步 超過10秒的閥值會退化為非同步
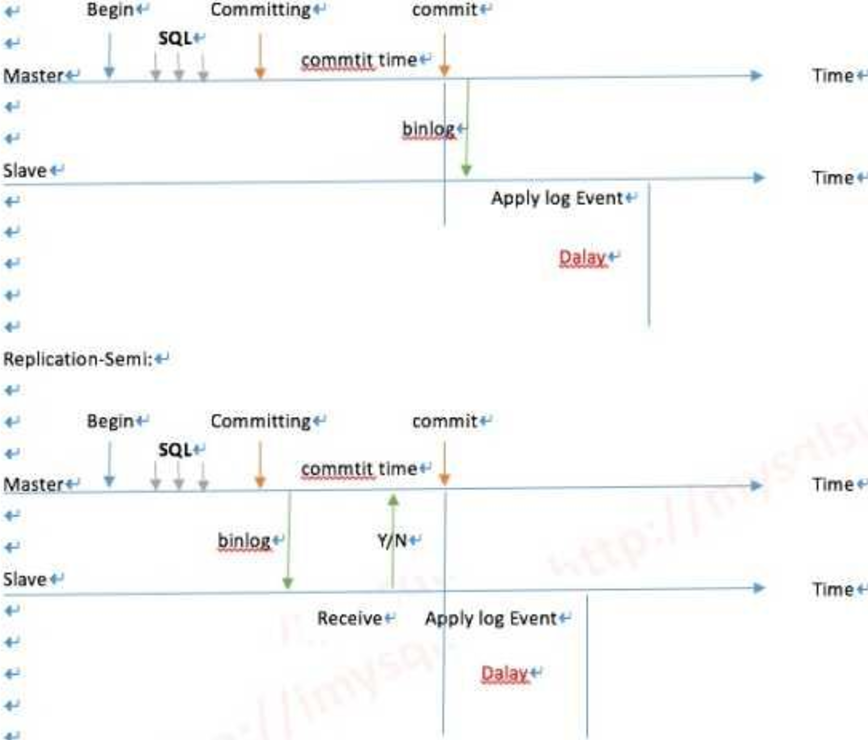
不管同步或是半同步,都存在一定的延遲,那麼PXC怎麼做到不延遲呢?
PXC最大的優勢:強一致性、無同步延遲
每一個節點都可以讀寫,WriteSet寫的集合,用箱子推給Group裡所有的成員, data page 相當於物理複製,而不是發日誌,就是一個寫的結果了。
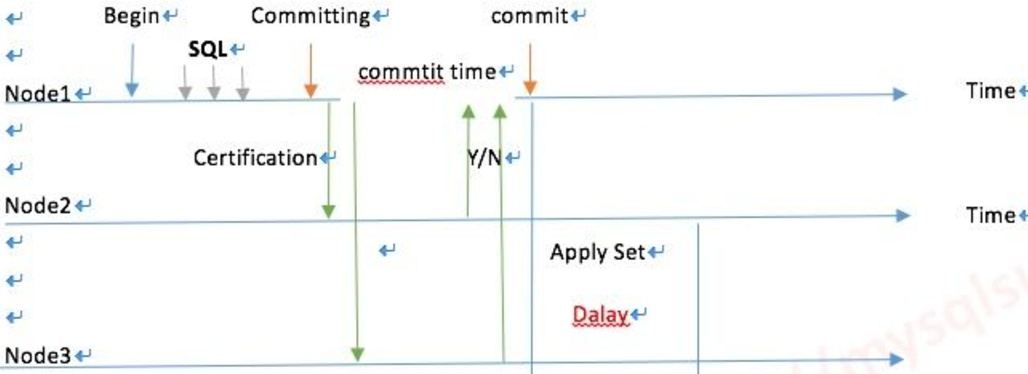

PXC原理圖
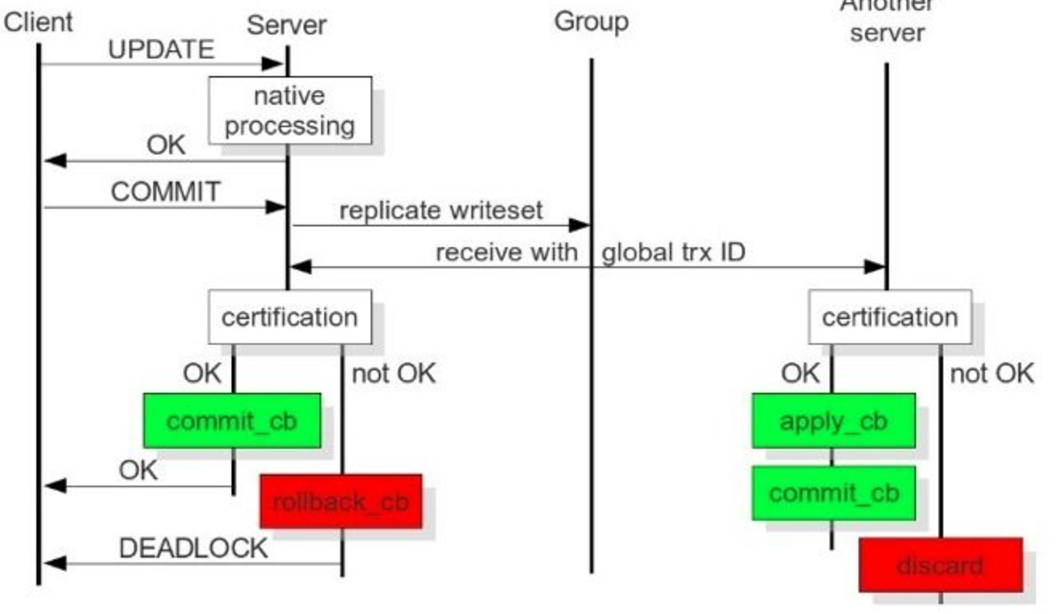
從上圖可以看出: 當client端執行dml操作時,將操作發給server,server的native程式處理請求,client端執行commit,server將複製寫資料集發給group(cluster),cluster 中每個動作對應一個GTID,其它server接收到並通過驗證(合併資料)後,執行appyl_cb動作和commit_cb動作,若驗證沒通過,則會退出處理;當前server節點驗證通 過後,執行commit_cb,並返回,若沒通過,執行rollback_cb。 只要當前節點執行了commit_cb和其它節點驗證通過後就可返回。 3306:資料庫對外服務的埠號 4444:請求SST,在新節點加入時起作用 4567:組成員之間溝通的埠 4568:傳輸IST,節點下線,重啟加入時起作用 SST:全量同步 IST:增量同步 問題:如果主節點寫入過大,apply_cb時間跟不上,怎麼處理? Wsrep_slave_threads引數配置成cpu的個數相等或是1.5倍。
使用者發起Commit,在收到Ok之前,叢集每次發起一個動作,都會有一個唯一的編號 ,也就是PXC獨有的Global Trx Id。
動作發起者是commit_cb,其它節點多了一個動作: apply_cb
上面的這些動作,是通過那個端號互動的?
4567,4568埠,IST只是在節點下線,重啟加入那一個時間有用
4444埠,只會在新節點加入進來時起作用
PXC結構裡面,如果主節點寫入過大,apply_cb 時間會不會跟不上,那麼wsrep_slave_threads引數 解決apply_cb跟不上問題 配置成和CPU的個數相等或是1.5倍
當前節點commit_cb 後就可以返回了,推過去之後,驗證通過就行了可以返回客戶端了,cb也就是commit block 提交資料塊.
5、PXC啟動和關閉過程
State Snapshot Transfer(SST),每個節點都有一份獨立的資料,當用mysql bootstrap-pxc啟動第一個節點,在第一個節點上把帳號初始化,其它節點啟動後加入進來。叢集中有哪些節點是由wsrep_cluster_address = gcomm://xxxx,,xxxx,xxx引數決定。第一個節點把自己備份一下(snapshot)傳給加入的新節點,第三個節點的死活是由前兩個節點投票決定。
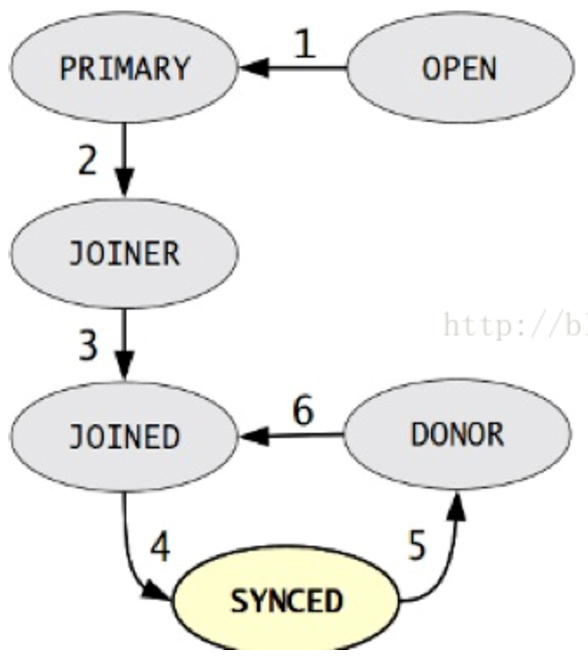
狀態機變化階段: 1)OPEN: 節點啟動成功,嘗試連線到叢集,如果失敗則根據配置退出或建立新的叢集 2)PRIMARY: 節點處於叢集PC中,嘗試從叢集中選取donor進行資料同步 3)JOINER: 節點處於等待接收/接收資料檔案狀態,資料傳輸完成後在本地載入資料 4)JOINED: 節點完成資料同步工作,嘗試保持和叢集進度一致 5)SYNCED:節點正常提供服務:資料的讀寫,叢集資料的同步,新加入節點的sst請求 6)DONOR(貢獻資料者):節點處於為新節點準備或傳輸叢集全量資料狀態,對客戶端不可用。 狀態機變化因素: 1)新節點加入叢集 2)節點故障恢復 3)節點同步失效 傳輸SST有幾種方法: 1)mysqldump 2)xtrabackup 3)rsync 比如有三個節點:node1、node2、node3 當node3停機重啟後,通過IST來同步增量資料,來完成保證與node1和node2的資料一致,IST的實現是由wsrep_provider_options="gcache.size=1G"引數決定, 一般設定為1G大,引數大小是由什麼決定的,根據停機時間,若停機一小時,需要確認1小時內產生多大的binlog來算出引數大小。 假設這三個節點都關閉了,會發生什麼呢? 全部傳SST,因為gcache資料沒了 全部關閉需要採用滾動關閉方式: 1)關閉node1,修復完後,啟動加回來; 2)關閉node2,修復完後,啟動加回來; 3)......,直到最後一個節點 4)原則要保持Group裡最少一個成員活著 資料庫關閉之後,最會儲存一個last Txid,所以啟動時,先要啟動最後一個關閉的節點,啟動順序和關閉順序剛好相反。 wsrep_recover=on引數在啟動時加入,用於從log中分析gtid。 怎樣避免關閉和啟動時資料丟失? 1)所有的節點中最少有一個線上,進行滾動重啟; 2)利用主從的概念,把一個從節點轉化成PXC裡的節點。
6、PXC注意的問題
1)腦裂:任何命令執行出現unkown command ,表示出現腦裂,叢集兩節點間4567埠連不通,無法提供對外服務。 SET GLOBAL wsrep_provider_options="pc.ignore_sb=true"; 2)併發寫:三個節點的自增起始值為1、2、3,步長都為3,解決了insert問題,但update同時對一行操作就會有問題,出現: Error: 1213 SQLSTATE: 40001,所以更新和寫入在一個節點上操作。 3)DDL:引起全域性鎖,採用:pt-online-schema-change 4)MyISAM引擎不能被複制,只支援innodb 5)pxc結構裡面必須有主鍵,如果沒有主建,有可能會造成集中每個節點的Data page裡的資料不一樣 6)不支援表級鎖,不支援lock /unlock tables 7)pxc裡只能把slow log ,query log 放到File裡 8)不支援XA事務 9)效能由叢集中效能最差的節點決定
------------------------------------------------------------------------------------------------------------
下面記錄在Centos下部署基於PXC的Mysql高可用方案操作過程
官方配置說明:https://www.percona.com/doc/percona-xtradb-cluster/5.5/howtos/centos_howto.html
1)環境描述(centos6.8版本)
node1 10.171.60.171 percona1
node2 10.44.183.73 percona2
node3 10.51.58.169 percona3
三個節點上的iptables最好關閉(否則就要開放3306、4444、4567、4568埠的訪問)、關閉selinux
2)三個node節點都要執行以下操作。
可以選擇原始碼或者yum,在此使用yum安裝。
基礎安裝
[root@percona1 ~]# yum -y groupinstall Base Compatibility libraries Debugging Tools Dial-up Networking suppport Hardware monitoring utilities Performance Tools Development tools
元件安裝
[root@percona1 ~]# yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm -y
[root@percona1 ~]# yum install Percona-XtraDB-Cluster-55 -y
3)資料庫配置
選擇一個node作為名義上的master,下面就以node1為master,只需要修改mysql的配置檔案--/etc/my.cnf
----------------以下是在node1節點上的配置----------------------
[root@percona1 ~]# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
user=mysql
# Path to Galera library
wsrep_provider=/usr/lib64/libgalera_smm.so
# Cluster connection URL contains the IPs of node#1, node#2 and node#3
wsrep_cluster_address=gcomm://10.171.60.171,10.44.183.73,10.51.58.169
# In order for Galera to work correctly binlog format should be ROW
binlog_format=ROW
# MyISAM storage engine has only experimental support
default_storage_engine=InnoDB
# This changes how InnoDB autoincrement locks are managed and is a requirement for Galera
innodb_autoinc_lock_mode=2
# Node #1 address
wsrep_node_address=10.171.60.171
# SST method
wsrep_sst_method=xtrabackup-v2
# Cluster name
wsrep_cluster_name=my_centos_cluster
# Authentication for SST method
wsrep_sst_auth="sstuser:s3cret"
啟動資料庫(三個節點都要操作):
node1的啟動方式:
[root@percona1 ~]# /etc/init.d/mysql bootstrap-pxc
.....................................................................
如果是centos7,則啟動命令如下:
[root@percona1 ~]# systemctl start mysql@bootstrap.service
.....................................................................
若是重啟的話,就先kill,然後刪除pid檔案後再執行上面的啟動命令。
配置資料庫(三個節點都要操作)
mysql> show status like 'wsrep%';
+----------------------------+--------------------------------------+
| Variable_name | Value |
+----------------------------+--------------------------------------+
.........
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
| wsrep_cert_index_size | 0 |
| wsrep_causal_reads | 0 |
| wsrep_incoming_addresses | 10.171.60.171:3306 | //叢集中目前只有一個成員的ip
| wsrep_cluster_conf_id | 1 |
| wsrep_cluster_size | 1 | //主要看這裡,目前node2和node3還沒有加入叢集,所以叢集成員目前只有一個
| wsrep_cluster_state_uuid | 5dee8d6d-455f-11e7-afd8-ca25b704d994 |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_local_bf_aborts | 0 |
| wsrep_local_index | 0 |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy <info@codership.com> |
| wsrep_provider_version | 2.12(r318911d) |
| wsrep_ready | ON |
| wsrep_thread_count | 2 |
+----------------------------+--------------------------------------+
資料庫使用者名稱密碼的設定
mysql> UPDATE mysql.user SET password=PASSWORD("Passw0rd") where user='root';
建立、授權、同步賬號
mysql> CREATE USER 'sstuser'@'localhost' IDENTIFIED BY 's3cret';
mysql> GRANT RELOAD, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'sstuser'@'localhost';
mysql> FLUSH PRIVILEGES;
................注意下面幾個察看命令...............
mysql> SHOW VARIABLES LIKE 'wsrep_cluster_address';
#如果配置了指向叢集地址,上面那個引數值,應該是你指定叢集的IP地址
# 此引數檢視是否開啟
mysql> show status like 'wsrep_ready';
# 檢視叢集的成員數
mysql> show status like 'wsrep_cluster_size';
# 這個檢視wsrep的相關引數
mysql> show status like 'wsrep%';
4)那麼node2和node3只需要配置my.cnf檔案中的wsrep_node_address這個引數,將其修改為自己的ip地址即可。
------------------------------------
node2節點的/etc/my.cnf配置
[root@percona2 ~]# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
user=mysql
# Path to Galera library
wsrep_provider=/usr/lib64/libgalera_smm.so
# Cluster connection URL contains the IPs of node#1, node#2 and node#3
wsrep_cluster_address=gcomm://10.171.60.171,10.44.183.73,10.51.58.169
# In order for Galera to work correctly binlog format should be ROW
binlog_format=ROW
# MyISAM storage engine has only experimental support
default_storage_engine=InnoDB
# This changes how InnoDB autoincrement locks are managed and is a requirement for Galera
innodb_autoinc_lock_mode=2
# Node #1 address
wsrep_node_address=10.44.183.73
# SST method
wsrep_sst_method=xtrabackup-v2
# Cluster name
wsrep_cluster_name=my_centos_cluster
# Authentication for SST method
wsrep_sst_auth="sstuser:s3cret"
----------------------------------
node3節點的/etc/my.cnf配置
[root@percona3 ~]# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
user=mysql
# Path to Galera library
wsrep_provider=/usr/lib64/libgalera_smm.so
# Cluster connection URL contains the IPs of node#1, node#2 and node#3
wsrep_cluster_address=gcomm://10.171.60.171,10.44.183.73,10.51.58.169
# In order for Galera to work correctly binlog format should be ROW
binlog_format=ROW
# MyISAM storage engine has only experimental support
default_storage_engine=InnoDB
# This changes how InnoDB autoincrement locks are managed and is a requirement for Galera
innodb_autoinc_lock_mode=2
# Node #1 address
wsrep_node_address=10.51.58.169
# SST method
wsrep_sst_method=xtrabackup-v2
# Cluster name
wsrep_cluster_name=my_centos_cluster
# Authentication for SST method
wsrep_sst_auth="sstuser:s3cret"
node2和node3的啟動方式:
[root@percona2 ~]# /etc/init.d/mysql start
..................................注意................................
-> 除了名義上的master之外,其它的node節點只需要啟動mysql即可。
-> 節點的資料庫的登陸和master節點的使用者名稱密碼一致,自動同步。所以其它的節點資料庫使用者名稱密碼無須重新設定。
也就是說,如上設定,只需要在名義上的master節點(如上的node1)上設定許可權,其它的節點配置好/etc/my.cnf後,只需要啟動mysql就行,許可權會自動同步過來。
如上的node2,node3節點,登陸mysql的許可權是和node1一樣的(即是用node1設定的許可權登陸)
.....................................................................
如果上面的node2、node3啟動mysql失敗,比如/var/lib/mysql下的err日誌報錯如下:
[ERROR] WSREP: gcs/src/gcs_group.cpp:long int gcs_group_handle_join_msg(gcs_
解決辦法:
-> 檢視節點上的iptables防火牆是否關閉;檢查到名義上的master節點上的4567埠是否連通(telnet)
-> selinux是否關閉
-> 刪除名義上的master節點上的grastate.dat後,重啟名義上的master節點的資料庫;當然當前節點上的grastate.dat也刪除並重啟資料庫
.....................................................................
5)最後進行測試
在任意一個node上,進行新增,刪除,修改操作,都會同步到其他的伺服器,是現在主主的模式,當然前提是表引擎必須是innodb,因為galera目前只支援innodb的表。
mysql> show status like 'wsrep%';
........
wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
| wsrep_cert_index_size | 2 |
| wsrep_causal_reads | 0 |
| wsrep_incoming_addresses | 10.44.183.73:3306,10.51.58.169:3306,10.171.60.171:3306 |
| wsrep_cluster_conf_id | 9 |
| wsrep_cluster_size | 3 | //叢集成員是3個
| wsrep_cluster_state_uuid | 92e43358-456d-11e7-af61-733b6b73c72c |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_local_bf_aborts | 0 |
| wsrep_local_index | 2 |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy <info@codership.com> |
| wsrep_provider_version | 2.12(r318911d) |
| wsrep_ready | ON |
| wsrep_thread_count | 2
在node3上建立一個庫
mysql> create database wangshibo;
Query OK, 1 row affected (0.02 sec)
然後在node1和node2上檢視,自動同步過來
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
| wangshibo |
+--------------------+
5 rows in set (0.00 sec)
在node1上的wangshibo庫下建立表,插入資料
mysql> use wangshibo;
Database changed
mysql> create table test(
-> id int(5));
Query OK, 0 rows affected (0.11 sec)
mysql> insert into test values(1);
Query OK, 1 row affected (0.01 sec)
mysql> insert into test values(2);
Query OK, 1 row affected (0.02 sec)
同樣,在其它的節點上檢視,也是能自動同步過來
mysql> select * from wangshibo.test;
+------+
| id |
+------+
| 1 |
| 2 |
+------+
2 rows in set (0.00 sec)