作為一個合格的運維人員,一定要熟悉掌握OSI七層網路和TCP/IP五層網路結構知識。
廢話不多說!下面就逐一展開對這兩個網路架構知識的說明:
一、OSI七層網路協議
OSI是Open System Interconnect的縮寫,意為開放式系統互聯。
OSI參考模型各個層次的劃分遵循下列原則:
1)根據不同層次的抽象分層
2)每層應當有一個定義明確的功能
3)每層功能的選擇應該有助於制定網路協議的國際標準。
4)各層邊界的選擇應儘量節省跨過介面的通訊量。
5)層數應足夠多,以避免不同的功能混雜在同一層中,但也不能太多,否則體系結構會過於龐大
6)同一層中的各網路節點都有相同的層次結構,具有同樣的功能。
7)同一節點內相鄰層之間通過介面(可以是邏輯介面)進行通訊。
8)七層結構中的每一層使用下一層提供的服務,並且向其上層提供服務。
9)不同節點的同等層按照協議實現對等層之間的通訊。
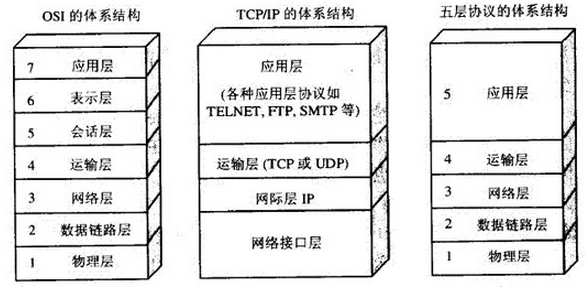
根據以上標準,OSI參考模型分為(從上到下):
物理層->資料鏈路層->網路層->傳輸層->會話層->表示層->應用層。
1)物理層涉及在通道上傳輸的原始位元流。
2)資料鏈路層的主要任務是加強物理層傳輸原始位元流的功能,使之對應的網路層顯現為一條無錯線路。傳送包把輸入資料封裝在資料幀,按順序傳送出去並處理接收方回送的確認幀。
3)網路層關係到子網的執行控制,其中一個關鍵問題是確認從源端到目的端如何選擇路由。
4)傳輸層的基本功能是從會話層接收資料而且把其分成較小的單元傳遞給網路層。
5)會話層允許不同機器上的使用者建立會話關係。
6)表示層用來完成某些特定的功能。
7)應用層包含著大量人們普遍需要的協議。
各層功能見下表:
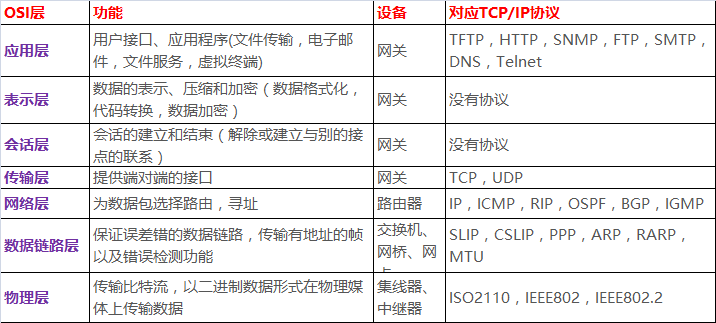
七層模型的每一層都具有清晰的特徵。基本來說:
1)第七至第四層(應用層->表示層->會話層->傳輸層)處理資料來源和資料目的地之間的端到端通訊,
2)第三至第一層(網路層->資料鏈路層->物理層)處理網路裝置間的通訊。
另外:
OSI模型的七層也可以劃分為兩組:
1)上層(層7、層6和層5,即應用層->表示層->會話層)。上層處理應用程式問題,並且通常只應用在軟體上。最高層,即應用層是與終端使用者最接近的。
2)下層(層4、層3、層2和層1,即傳輸層->網路層->資料鏈路層->物理層)。下層是處理資料傳輸的。物理層和資料鏈路層應用在硬體和軟體上。最底層,即物理層是與物理網路媒介(比如說,電線)最接近的,並且負責在媒介上傳送
第7層-應用層
定義了用於在網路中進行通訊和資料傳輸的介面 - 使用者程式;
提供標準服務,比如虛擬終端、檔案以及任務的傳輸和處 理;
應用層為作業系統或網路應用程式提供訪問網路服務的介面。應用層協議的代表包括:Telnet、FTP、HTTP、SNMP等。
第6層-表示層
掩蓋不同系統間的資料格式的不同性;
指定獨立結構的資料傳輸格式;
資料的編碼和解碼;加密和解密; 壓縮和解壓縮
這一層主要解決擁護資訊的語法表示問題。它將欲交換的資料從適合於某一使用者的抽象語法,轉換為適合於OSI系統內部使用的傳送語法。即提供格式化的表示和轉換資料服務。資料的壓縮和解壓縮, 加密和解密等工作都由表示層負責。
第5層-會話層
管理使用者會話和對話;
控制使用者間邏輯連線的建立和結束通話;
報告上一層發生的錯誤
這一層也可以稱為會晤層或對話層,在會話層及以上的高層次中,資料傳送的單位不再另外命名,而是統稱為報文。會話層不參與具體的傳輸,它提供包括訪問驗證和會話管理在內的建立和維護應用之間通訊的機制。如伺服器驗證使用者登入便是由會話層完成的。
第4層-處理資訊的傳輸層
管理網路中端到端的資訊傳送;
通過錯誤糾正和流控制機制提供可靠且有序的資料包傳送;
提供面向無連 接的資料包的傳送;
第4層的資料單元也稱作資料包(packets)。但是,當你談論TCP等具體的協議時又有特殊的叫法,TCP的資料單元稱為段 (segments)而UDP協議的資料單元稱為“資料包(datagrams)”。這個層負責獲取全部資訊,因此,它必須跟蹤資料單元碎片、亂序到達的 資料包和其它在傳輸過程中可能發生的危險。第4層為上層提供端到端(終端使用者到終端使用者)的透明的、可靠的資料傳輸服務。所為透明的傳輸是指在通訊過程中 傳輸層對上層遮蔽了通訊傳輸系統的具體細節。傳輸層協議的代表包括:TCP、UDP、SPX等。
第3層-網路層
定義網路裝置間如何傳輸資料;
根據唯一的網路裝置地址路由資料包;
提供流和擁塞控制以防止網路資源 的損耗
在 計算機網路中進行通訊的兩個計算機之間可能會經過很多個資料鏈路,也可能還要經過很多通訊子網。網路層的任務就是選擇合適的網間路由和交換結點, 確保資料及時傳送。網路層將資料鏈路層提供的幀組成資料包,包中封裝有網路層包頭,其中含有邏輯地址資訊- -源站點和目的站點地址的網路地址。如 果你在談論一個IP地址,那麼你是在處理第3層的問題,這是“資料包”問題,而不是第2層的“幀”。IP是第3層問題的一部分,此外還有一些路由協議和地 址解析協議(ARP)。有關路由的一切事情都在這第3層處理。地址解析和路由是3層的重要目的。網路層還可以實現擁塞控制、網際互連等功能。在這一層,資料的單位稱為資料包(packet)。網路層協議的代表包括:IP、IPX、RIP、OSPF等。
第2層-資料鏈路層(DataLinkLayer):
定義操作通訊連線的程式;
封裝資料包為資料幀;
監測和糾正資料包傳輸錯誤
在物理層提供位元流服務的基礎上,建立相鄰結點之間的資料鏈路,通過差錯控制提供資料幀(Frame)在通道上無差錯的傳輸,並進行各電路上的動作系列。資料鏈路層在不可靠的物理介質上提供可靠的傳輸。該層的作用包括:實體地址定址、資料的成幀、流量控制、資料的檢錯、重發等。在這一層,資料的單位稱為幀(frame)。資料鏈路層協議的代表包括:SDLC、HDLC、PPP、STP、幀中繼等。
第1層-物理層(PhysicalLayer)
定義通過網路裝置傳送資料的物理方式;
作為網路媒介和裝置間的介面;
定義光學、電氣以及機械特性。
規定通訊裝置的機械的、電氣的、功能的和過程的特性,用以建立、維護和拆除物理鏈路連線。具體地講,機械 特性規定了網路連線時所需接外掛的規格尺寸、引腳數量和排列情況等;電氣特性規定了在物理連線上傳輸bit流時線路上訊號電平的大小、阻抗匹配、傳輸速率 距離限制等;功能特性是指對各個訊號先分配確切的訊號含義,即定義了DTE和DCE之間各個線路的功能;規程特性定義了利用訊號線進行bit流傳輸的一組 操作規程,是指在物理連線的建立、維護、交換資訊是,DTE和DCE雙放在各電路上的動作系列。在這一層,資料的單位稱為位元(bit)。屬於物理層定義的典型規範代表包括:EIA/TIA RS-232、EIA/TIA RS-449、V.35、RJ-45等。
二、TCP/IP
TCP/IP(傳輸控制協議/網間網協議)是目前世界上應用最為廣泛的協議,它的流行與Internet的迅猛發展密切相關。
TCP/IP最初是為網際網路的原型ARPANET所設計的,目的是提供一整套方便實用、能應用於多種網路上的協議,事實證明TCP/IP做到了這一點,它使網路互聯變得容易起來,並且使越來越多的網路加入其中,成為Internet的事實標準。
TCP/IP協議族包含了很多功能各異的子協議。為此我們也利用上文所述的分層的方式來剖析它的結構。
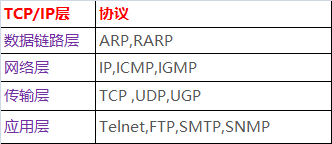
TCP/IP層次模型共分為四層:應用層->傳輸層->網路層->資料鏈路層。
各層功能見下表
TCP(Transmission Control Protocol:傳輸控制協議)和UDP(User Datagram Protocol:使用者資料包協議)協議屬於傳輸層協議。其中:
1)TCP提供IP環境下的資料可靠傳輸,它提供的服務包括資料流傳送、可靠性、有效流控、全雙工操作和多路複用。通過面向連線、端到端和可靠的資料包傳送。通俗說,它是事先為所傳送的資料開闢出連線好的通道,然後再進行資料傳送;
2)UDP則不為IP提供可靠性、流控或差錯恢復功能。一般來說,TCP對應的是可靠性要求高的應用,而UDP對應的則是可靠性要求低、傳輸經濟的應用。
應用層
應用層是所有使用者所面向的應用程式的統稱。ICP/IP協議族在這一層面有著很多協議來支援不同的應用,許多大家所熟悉的基於Internet的應用的實現就離不開這些協議。如我們進行全球資訊網(WWW)訪問用到了HTTP協議、檔案傳輸用FTP協議、電子郵件傳送用SMTP、域名的解析用DNS協議、遠端登入用Telnet協議等等,都是屬於TCP/IP應用層的;就使用者而言,看到的是由一個個軟體所構築的大多為圖形化的操作介面,而實際後臺執行的便是上述協議。
傳輸層
這一層的的功能主要是提供應用程式間的通訊,TCP/IP協議族
在這一層的協議有TCP和UDP。
網路層
TCP/IP協議族中非常關鍵的一層,主要定義了IP地址格式,從而能夠使得不同應用型別的資料在Internet上通暢地傳輸,IP協議就是一個網路層協議。
網路介面層
這是TCP/IP軟體的最低層,負責接收IP資料包並通過網路傳送之,或者從網路上接收物理幀,抽出IP資料包,交給IP層。
===============================================
TCP支援的應用協議主要有:Telnet、FTP、SMTP等;
UDP支援的應用層協議主要有:NFS(網路檔案系統)、SNMP(簡單網路管理協議)、DNS(主域名稱系統)、TFTP(通用檔案傳輸協議)等。
TCP/IP協議與低層的資料鏈路層和物理層無關,這也是TCP/IP的重要特點。
===============================================================================
TCP連線建立-斷開的過程說明(可以參考:高效運維-三次握手和四次揮手)
TCP連線的端點叫做套接字(socket)或插口,即(IP地址:埠號),每一條TCP連線唯一地被通訊兩端的兩個端點(即兩個套接字)所確定。
TCP的運輸連線有三個階段,即連線建立、資料傳送、連線釋放。
TCP連線建立的過程要使每一方能夠確定對方的存在:主動發起連線建立的應用進行叫做客戶(client),被動等待連線建立的應用程式叫做伺服器(server),連線建立的過程叫做三次握手。
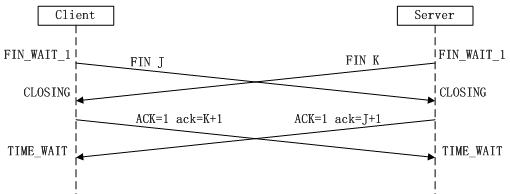
假設A為客戶,B為伺服器,A傳送一個報文給B,B發回確認,然後A再加以確認,來回共三次,成為“三次握手”。三次握手建立連線~
所謂三次握手(Three-Way Handshake)即建立TCP連線,就是指建立一個TCP連線時,需要客戶端和服務端總共傳送3個包以確認連線的建立。在socket程式設計中,這一過程由客戶端執行connect來觸發,整個流程如下圖所示:
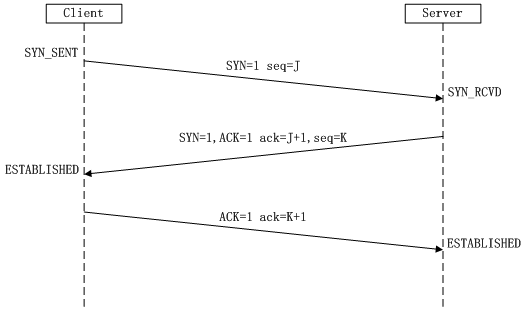
1)第一次握手:Client將標誌位SYN置為1,隨機產生一個值seq=J,並將該資料包傳送給Server,Client進入SYN_SENT狀態,等待Server確認。
2)第二次握手:Server收到資料包後由標誌位SYN=1知道Client請求建立連線,Server將標誌位SYN和ACK都置為1,ack=J+1,隨機產生一個值seq=K,並將該資料包傳送給Client以確認連線請求,Server進入SYN_RCVD狀態。
3)第三次握手:Client收到確認後,檢查ack是否為J+1,ACK是否為1,如果正確則將標誌位ACK置為1,ack=K+1,並將該資料包傳送給Server,Server檢查ack是否為K+1,ACK是否為1,如果正確則連線建立成功,Client和Server進入ESTABLISHED狀態,完成三次握手,隨後Client與Server之間可以開始傳輸資料了。
SYN攻擊解釋:
三次握手過程中,Server傳送SYN-ACK之後,收到Client的ACK之前的TCP連線稱為半連線(half-open connect),此時Server處於SYN_RCVD狀態,當收到ACK後,Server轉入ESTABLISHED狀態。SYN攻擊就是Client在短時間內偽造大量不存在的IP地址,並向Server不斷地傳送SYN包,Server回覆確認包,並等待Client的確認,由於源地址是不存在的,因此,Server需要不斷重發直至超時,這些偽造的SYN包將產時間佔用未連線佇列,導致正常的SYN請求因為佇列滿而被丟棄,從而引起網路堵塞甚至系統癱瘓。SYN攻擊時一種典型的DDOS攻擊,檢測SYN攻擊的方式非常簡單,即當Server上有大量半連線狀態且源IP地址是隨機的,則可以斷定遭到SYN攻擊了,使用如下命令可以讓之現行:
#netstat -nap | grep SYN_RECV
---------------------------------------------------
連線的釋放需要傳送四個包,因此成為“四次揮手”,四次揮手斷開連線。客戶端或伺服器都可以主動發起揮手動作。
所謂四次揮手(Four-Way Wavehand)即終止TCP連線,就是指斷開一個TCP連線時,需要客戶端和服務端總共傳送4個包以確認連線的斷開。在socket程式設計中,這一過程由客戶端或服務端任一方執行close來觸發,整個流程如下圖所示:
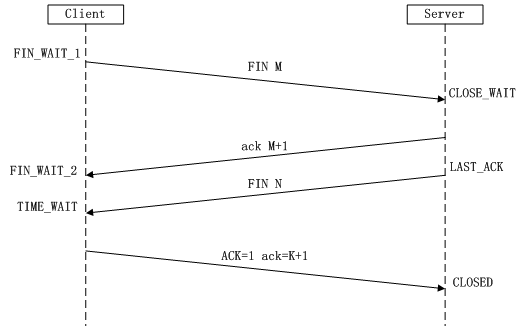
由於TCP連線時全雙工的,因此,每個方向都必須要單獨進行關閉,這一原則是當一方完成資料傳送任務後,傳送一個FIN來終止這一方向的連線,收到一個FIN只是意味著這一方向上沒有資料流動了,即不會再收到資料了,但是在這個TCP連線上仍然能夠傳送資料,直到這一方向也傳送了FIN。首先進行關閉的一方將執行主動關閉,而另一方則執行被動關閉,上圖描述的即是如此。
1)第一次揮手:Client傳送一個FIN,用來關閉Client到Server的資料傳送,Client進入FIN_WAIT_1狀態。
2)第二次揮手:Server收到FIN後,傳送一個ACK給Client,確認序號為收到序號+1(與SYN相同,一個FIN佔用一個序號),Server進入CLOSE_WAIT狀態。
3)第三次揮手:Server傳送一個FIN,用來關閉Server到Client的資料傳送,Server進入LAST_ACK狀態。
4)第四次揮手:Client收到FIN後,Client進入TIME_WAIT狀態,接著傳送一個ACK給Server,確認序號為收到序號+1,Server進入CLOSED狀態,完成四次揮手。
上面是一方主動關閉,另一方被動關閉的情況(由一方發起揮手),實際中還會出現同時發起主動關閉的情況,具體流程如下圖(同時揮手):
為什麼連線的時候是三次握手,關閉的時候卻是四次握手?
這是因為當Server端收到Client端的SYN連線請求報文後,可以直接傳送SYN+ACK報文。其中ACK報文是用來應答的,SYN報文是用來同步的。
但是關閉連線時,當Client端傳送FIN報文僅僅表示它不再傳送資料了但是還能接收資料,Server端收到FIN報文時,很可能並不會立即關閉SOCKET,所以只能先回復一個ACK報文,告訴Client端,"你發的FIN報文我收到了"。只有等到我Server端所有的報文都傳送完了,我才能傳送FIN報文,因此不能一起傳送。故需要四步握手。
----------------------------------------------------
三、OSI七層網路與TCP/IP五層網路的區別與聯絡
除了層的數量之外,開放式系統互聯(OSI)模型與TCP/IP協議有什麼區別?
開放式系統互聯模型是一個參考標準,解釋協議相互之間應該如何相互作用。TCP/IP協議是美國國防部發明的,是讓網際網路成為了目前這個樣子的標準之一。
開放式系統互聯模型中沒有清楚地描繪TCP/IP協議,但是在解釋TCP/IP協議時很容易想到開放式系統互聯模型。
兩者的主要區別如下:
1)TCP/IP協議中的應用層處理OSI模型中的第五層、第六層和第七層的功能。
2)TCP/IP協議中的傳輸層並不能總是保證在傳輸層可靠地傳輸資料包,而OSI模型可以做到。
3) TCP/IP協議還提供一項名為UDP(使用者資料包協議)的選擇。UDP不能保證可靠的資料包傳輸。
===============================================================================
先簡單對比下二層網路和三層網路的區別:
1)不同網段的ip通訊,需要經過三層網路。相同網段的ip通訊,經過二層網路;
2)二層網路僅僅通過MAC定址即可實現通訊,但僅僅是同一個衝突域內;三層網路需要通過IP路由實現跨網段的通訊,可以跨多個衝突域;
3)二層網路的組網能力非常有限,一般只是小區域網;三層網路則可以組大型的網路。
4)二層網路基本上是一個安全域,也就是說在同一個二層網路內,終端的安全性從網路上講基本上是一樣的,除非有其它特殊的安全措施;
三層網路則可以劃分出相對獨立的多個安全域。
5)很多技術相對是在二層區域網中用得多,比如DHCP、Windows提供的共享連線等,如需在三層網路上使用,則需要考慮其它裝置的支援
(比如通過DHCP中繼代理等)或通過其它的方式來實現。
=============================二層網路與三層網路的詳細對比============================
網路結構的變化過程:
a)按照物理拓撲結構分類,網路結構經歷了匯流排型、環型、星型、樹型、混合型等結構。
b)按照邏輯拓撲結構分類,網路結構經歷了二層網路架構、三層網路架構以及最近興起的大二層網路架構。
傳統的資料交換都是在OSI 參考模型的資料鏈路層發生的,也就是按照MAC 地址進行定址並進行資料轉發,並建立和維護一個MAC 地址表,
用來記錄接收到的資料包中的MAC 地址及其所對應的埠。此種型別的網路均為小範圍的二層網路。
一、二層網路的工作流程:
1)資料包接收:首先交換機接收某埠中傳輸過來的資料包,並對該資料包的原始檔進行解析,獲取其源MAC 地址,確定發放源資料包主機
2)傳輸資料包到目的MAC 地址:首先判斷目的MAC 地址是否存在,如果交換機所儲存的MAC 地址表中有此MAC 地址所對應的埠,那麼直接將資料包傳送給這個埠;如果在交換機儲存列表中找不到對應的目的MAC 地址,交換機則會對資料包進行全埠廣播,直至收到目的裝置的迴應,交換機通過此次廣播學習、記憶並建立目的MAC 地址和目的埠的對應關係,以備以後快速建立與該目的裝置的聯絡;
3)如果交換機所儲存的MAC 地址表中沒有此地址,就會將資料包廣播傳送到所有埠上,當目的終端給出迴應時,交換機又學習到了一個新的MAC 地址與埠的對應關係,並儲存在自身的MAC 地址表中。當下次傳送資料的時候就可以直接傳送到這個埠而非廣播傳送了。
以上就是交換機將一個MAC 地址新增到列表的流程,該過程迴圈往復,交換機就能夠對整個網路中存在的MAC 地址進行記憶並新增到地址列表,這就是二層(OSI 二層)交換機對MAC 地址進行建立、維護的全過程。
從上述過程不難看出,傳統的二層網路結構模式雖然執行簡便但在很大程度上限制了網路規模的擴大,由於傳統網路結構中採用的是廣播的方式來實現資料的傳輸,極易形成廣播風暴,進而造成網路的癱瘓。這就是各個計算機研究機構所面臨的“二層網路存在的天然瓶頸”,由於該瓶頸的存在,使得大規模的資料傳輸和資源共享難以實現,基於傳統的二層網路結構也很難實現區域網路規模化。
為了適應大規模網路的產生於發展,基於分層、簡化的思想,三層網路模式被成功設計推出。三層網路架構的基本思想就是將大規模、較複雜的
網路進行分層次分模組處理,為每個模組指定對應的功能,各司其職,互不干擾,大大提高了資料傳輸的速率。
二、三層網路結構的設計,顧名思義,具有三個層次:核心層、匯聚層、接入層。下面將對三個層次的作用分別進行說明。
1)核心層:在網際網路中承載著網路伺服器與各應用埠間的傳輸功能,是整個網路的支撐脊樑和資料傳輸通道,重要性不言而喻。因此,網路對於核心層要求極高,核心層必須具備資料儲存的高安全性,資料傳輸的高效性和可靠性,對資料錯誤的高容錯性,以及資料管理方面的便捷性和高適應性等效能。在核心層搭建中,裝置的採購必須嚴格按需採購,滿足上述功能需求,這就對交換機的頻寬以及資料承載能力提出了更高的要求,因為核心層一旦堵塞將造成大面積網路癱瘓,因此必須配備高效能的資料冗餘轉接裝置和防止負載過剩的均衡過剩負載的裝置,以降低各核心層交換機所需承載的資料量,以保障網路高速、安全的運轉。
2)匯聚層:連線網路的核心層和各個接入的應用層,在兩層之間承擔“媒介傳輸”的作用。每個應用接入都經過匯聚層進行資料處理,再與核心層進行有效的連線,通過匯聚層的有效整合對核心層的荷載量進行降低。根據匯聚層的作用要求,匯聚層應該具備以下功能:實施安全功能、工作組整體接入功能、虛擬網路過濾功能等。因此,匯聚層中裝置的採購必須具備三層網路的接入交換功能,同時支援虛擬網路的建立功能,從而實現不同網路間的資料隔離安全,能夠將大型網路進行分段劃分,化繁為簡。
3)接入層:接入層的物件導向主要是終端客戶,為終端客戶提供接入功能,區別於核心層和匯聚層提供各種策略的功能。接入層的主要功能是規劃同一網段中的工作站個數,提高各接入終端的頻寬。在搭建網路架構時,既要考慮網路的綜合實用性,也要考慮經濟效益,因此在接入層裝置採購時可以選擇資料鏈路層中較低端的交換機,而不是越高階越昂貴越好。
隨著近年來網際網路的應用規模急劇擴張,對資料傳輸的要求也越來越高,基於資料整合的雲端計算技術逐漸受到人們的關注。計算機網路作為當今社會各種資訊的傳輸媒介,其組成架構也即將發生重大變革。鑑於傳統三層網路VLan 隔離以及STP 收斂上的缺陷,傳統網路結構急需打破。現有研究機構開始致力於新型高效網路架構的研發與探索,結合早期的扁平化架構的原有二層網路與現有三層網路的優缺點提出了大二層網路架構。
===============================大二層網路==============================
1)為什麼需要大二層網路
傳統的三層資料中心架構結構的設計是為了應付服務客戶端-伺服器應用程式的縱貫式大流量,同時使網路管理員能夠對流量流進行管理。工程師在這些架構中採用生成樹協議(STP)來優化客戶端到伺服器的路徑和支援連線冗餘,通常將二層網路的範圍限制在網路接入層以下,避免出現大範圍的二層廣播域;
虛擬化從根本上改變了資料中心網路架構的需求,既虛擬化引入了虛擬機器動態遷移技術。從而要求網路支援大範圍的二層域。從根本上改變了傳統三層網路統治資料中心網路的局面。具體的來說,虛擬化技術的一項伴生技術—虛擬機器動態遷移(如VMware的VMotion)在資料中心得到了廣泛的應用,虛擬機器遷移要求虛擬機器遷移前後的IP和MAC地址不變,這就需要虛擬機器遷移前後的網路處於同一個二層域內部。由於客戶要求虛擬機器遷移的範圍越來越大,甚至是跨越不同地域、不同機房之間的遷移,所以使得資料中心二層網路的範圍越來越大,甚至出現了專業的大二層網路這一新領域專題。
思考兩個問題:
a)IP及MAC不變的理由?
對業務透明、業務不中斷
b)IP及MAC不變,那麼為什麼必須是二層域內?
IP不變,那麼就不能夠實現基於IP的定址(三層),那麼只能實現基於MAC的定址,既二層定址,大二層,顧名思義,此是二層網路,根據MAC地址進行定址
2)傳統的二層網路大不起來的原因
在資料中心網路中,“區域”對應VLAN的劃分。相同VLAN內的終端屬於同一廣播域,具有一致的VLAN-ID,二層連通;不同VLAN內的終端需要通過閘道器互相訪問,二層隔離,三層連通。傳統的資料中心設計,區域和VLAN的劃分粒度是比較細的,這主要取決於“需求”和“網路規模”。
傳統的資料中心主要是依據功能進行區域劃分,例如WEB、APP、DB,辦公區、業務區、內聯區、外聯區等等。不同區域之間通過閘道器和安全裝置互訪,保證不同區域的可靠性、安全性。同時,不同區域由於具有不同的功能,因此需要相互訪問資料時,只要終端之間能夠通訊即可,並不一定要求通訊雙方處於同一VLAN或二層網路。
傳統的資料中心網路技術, STP是二層網路中非常重要的一種協議。使用者構建網路時,為了保證可靠性,通常會採用冗餘裝置和冗餘鏈路,這樣就不可避免的形成環路。而二層網路處於同一個廣播域下,廣播報文在環路中會反覆持續傳送,形成廣播風暴,瞬間即可導致埠阻塞和裝置癱瘓。因此,為了防止廣播風暴,就必須防止形成環路。這樣,既要防止形成環路,又要保證可靠性,就只能將冗餘裝置和冗餘鏈路變成備份裝置和備份鏈路。即冗餘的裝置埠和鏈路在正常情況下被阻塞掉,不參與資料包文的轉發。只有當前轉發的裝置、埠、鏈路出現故障,導致網路不通的時候,冗餘的裝置埠和鏈路才會被開啟,使得網路能夠恢復正常。實現這些自動控制功能的就是STP(Spanning Tree Protocol,生成樹協議)。 由於STP的收斂效能等原因,一般情況下STP的網路規模不會超過100臺交換機。同時由於STP需要阻塞掉冗餘裝置和鏈路,也降低了網路資源的頻寬利用率。因此在實際網路規劃時,從轉發效能、利用率、可靠性等方面考慮,會盡可能控制STP網路範圍。
隨著資料大集中的發展和虛擬化技術的應用,資料中心的規模與日俱增,不僅對二層網路的區域範圍要求也越來越大,在需求和管理水平上也提出了新的挑戰。
資料中心區域規模和業務處理需求的增加,對於叢集處理的應用越來越多,叢集內的伺服器需要在一個二層VLAN下。同時,虛擬化技術的應用,在帶來業務部署的便利性和靈活性基礎上,虛擬機器的遷移問題也成為必須要考慮的問題。為了保證虛擬機器承載業務的連續性,虛擬機器遷移前後的IP地址不變,因此虛擬機器的遷移範圍需要在同一個二層VLAN下。反過來即,二層網路規模有多大,虛擬機器才能遷移有多遠。
傳統的基於STP備份裝置和鏈路方案已經不能滿足資料中心規模、頻寬的需求,並且STP協議幾秒至幾分鐘的故障收斂時間,也不能滿足資料中心的可靠性要求。因此,需要能夠有新的技術,在滿足二層網路規模的同時,也能夠充分利用冗餘裝置和鏈路,提升鏈路利用率,而且資料中心的故障收斂時間能夠降低到亞秒甚至毫秒級。
3)實現大二層網路的技術
大二層網路是針對當前最火熱的虛擬化資料中心的虛擬機器動態遷移這一特定需求而提出的概念,對於其他型別的網路並無特殊的價值和意義。
在虛擬化資料中心裡,一臺物理伺服器被虛擬化為多臺邏輯伺服器,被稱為虛擬機器VM,每個VM都可以獨立執行,有自己的OS、APP,在網路層面有自己獨立的MAC地址和IP地址。而VM動態遷移是指將VM從一個物理伺服器遷移到另一個物理伺服器,並且要保證在遷移過程中,VM的業務不能中斷。
為了實現VM動態遷移時,在網路層面要求遷移時不僅VM的IP地址不變、而且執行狀態也必須保持(例如TCP會話狀態),這就要求遷移的起始和目標位置必須在同一個二層網路域之中。
所以,為了實現VM的大範圍甚至跨地域的動態遷移,就要求把VM遷移可能涉及的所有伺服器都納入同一個二層網路域,這樣才能實現VM的大範圍無障礙遷移。這就是大二層網路的需求由來,一個真正意義的大二層網路至少要能容納1萬以上的主機,才能稱之為大二層網路。而傳統的基於VLAN+xSTP的二層網路,由於環路和廣播風暴、以及xSTP協議的效能限制等原因,通常能容納的主機數量不會超過1K,無法實現大二層網路。當前,實現大二層網路的主要技術有以下幾種:
a)網路裝置虛擬化技術
網路裝置虛擬化是將相互冗餘的兩臺或多臺物理網路裝置組合在一起,虛擬化成一臺邏輯網路裝置,在整個網路中只呈現為一個節點。例如華為的CSS框式堆疊、iStack盒式堆疊、SVF框盒堆疊技術等。
網路裝置虛擬化再配合鏈路聚合技術,就可以把原來網路的多節點、多鏈路的結構變成邏輯上單節點、單鏈路的結構,解決了二層網路中的環路問題。沒有了環路問題,就不需要xSTP,二層網路就可以範圍無限(只要虛擬網路裝置的接入能力允許),從而實現大二層網路。
b)大二層轉發技術
大二層轉發技術是通過定義新的轉發協議,改變傳統二層網路的轉發模式,將三層網路的路由轉發模式引入到二層網路中。例如TRILL、SPB等。
以TRILL為例,TRILL協議在原始以太幀外封裝一個TRILL幀頭,再封裝一個新的以太幀來實現對原始以太幀的透明傳輸,支援TRILL的交換機可通過TRILL幀頭裡的Nickname標識來進行轉發,而Nickname就像路由一樣,可通過IS-IS路由協議進行收集、同步和更新。
c)Overlay技術
Overlay技術是通過用隧道封裝的方式,將源主機發出的原始二層報文封裝後在現有網路中進行透明傳輸,從而實現主機之間的二層通訊。通過封裝和解封裝,相當於一個大二層網路疊加在現有的基礎網路之上,所以稱為Overlay技術。
Overlay技術通過隧道封裝的方式,忽略承載網路的結構和細節,可以把整個承載網路當作一臺“巨大無比的二層交換機”, 每一臺主機都是直連在“交換機”的一個埠上。而承載網路之內如何轉發都是 “交換機”內部的事情,主機完全不可見。Overlay技術主要有VXLAN、NVGRE、STT等。
4)大二層網路需要有多大、及技術選型
1. 資料中心內
大二層首先需要解決的是資料中心內部的網路擴充套件問題,通過大規模二層網路和VLAN延伸,實現虛擬機器在資料中心內部的大範圍遷移。由於資料中心內的大二層網路都要覆蓋多個接入交換機和核心交換機,主要有以下兩類技術。
a) 虛擬交換機技術
虛擬交換機技術的出發點很簡單,屬於工程派。既然二層網路的核心是環路問題,而環路問題是隨著冗餘裝置和鏈路產生的,那麼如果將相互冗餘的兩臺或多臺裝置、兩條或多條鏈路合併成一臺裝置和一條鏈路,就可以回到之前的單裝置、單鏈路情況,環路自然也就不存在了。尤其是交換機技術的發展,虛擬交換機從低端盒式裝置到高階框式裝置都已經廣泛應用,具備了相當的成熟度和穩定度。因此,虛擬交換機技術成為目前應用最廣的大二層解決方案。 虛擬交換機技術的代表是H3C公司的IRF、Cisco公司的VSS,其特點是隻需要交換機軟體升級即可支援,應用成本低,部署簡單。目前這些技術都是各廠商獨立實現和完成的,只能同一廠商的相同系列產品之間才能實施虛擬化。同時,由於高階框式交換機的效能、密度越來越高,對虛擬交換機的技術要求也越來越高,目前框式交換機的虛擬化密度最高為4:1。虛擬交換機的密度限制了二層網路的規模大約在1萬~2萬臺伺服器左右。
b) 隧道技術
隧道技術屬於技術派,出發點是借船出海。二層網路不能有環路,冗餘鏈路必須要阻塞掉,但三層網路顯然不存在這個問題,而且還可以做ECMP(等價鏈路),能否借用過來呢?通過在二層報文前插入額外的幀頭,並且採用路由計算的方式控制整網資料的轉發,不僅可以在冗餘鏈路下防止廣播風暴,而且可以做ECMP。這樣可以將二層網路的規模擴充套件到整張網路,而不會受核心交換機數量的限制。
隧道技術的代表是TRILL、SPB,都是通過借用IS-IS路由協議的計算和轉發模式,實現二層網路的大規模擴充套件。這些技術的特點是可以構建比虛擬交換機技術更大的超大規模二層網路(應用於大規模叢集計算),但尚未完全成熟,目前正在標準化過程中。同時傳統交換機不僅需要軟體升級,還需要硬體支援。
2. 跨資料中心
隨著資料中心多中心的部署,虛擬機器的跨資料中心遷移、災備,跨資料中心業務負載分擔等需求,使得二層網路的擴充套件不僅是在資料中心的邊界為止,還需要考慮跨越資料中心機房的區域,延伸到同城備份中心、遠端災備中心。
一般情況下,多資料中心之間的連線是通過路由連通的,天然是一個三層網路。而要實現通過三層網路連線的兩個二層網路互通,就必須實現“L2 over L3”。
L2oL3技術也有許多種,例如傳統的VPLS(MPLS L2VPN)技術,以及新興的Cisco OTV、H3C EVI技術,都是藉助隧道的方式,將二層資料包文封裝在三層報文中,跨越中間的三層網路,實現兩地二層資料的互通。這種隧道就像一個虛擬的橋,將多個資料中心的二層網路貫穿在一起。
也有部分虛擬化和軟體廠商提出了軟體的L2 over L3技術解決方案。例如VMware的VXLAN、微軟的NVGRE,在虛擬化層的vSwitch中將二層資料封裝在UDP、GRE報文中,在物理網路拓撲上構建一層虛擬化網路層,從而擺脫對網路裝置層的二層、三層限制。這些技術由於效能、擴充套件性等問題,也沒有得到廣泛的使用。
常見資料中心架構

full layer3網路屬於傳統的資料中心網路。伺服器閘道器部署在接入交換機上,整網通過路由協議控制拓撲和轉發路徑。這樣的網路架構的主要優勢在於技術成熟、有大量的運維經驗。網路系統穩定且便於維護。但是Full layer3網路的不足之處在於不能支援虛擬化資料中心虛擬機器的自由遷移,所以在進入雲端計算時代後,Full layer3網路逐漸被淘汰。Full layer2網路是下一代資料中心的網路模型。伺服器閘道器在核心層,整網通過TRILL或是SPB協議控制拓撲和轉發路徑。這樣的網路架構主要優勢在於能夠支援大規模的二層網路,能夠支援足夠規模的虛擬機器資源池。但是,這個網路模型的缺點也是非常明顯的。TRILL協議雖然已經標準化(SPB協議正在標準化),但是大規模的二層網路缺乏運維經驗。沒有運維經驗,也就意味著運維成本的大幅度提升,同時也會給業務系統帶來巨大的風險。
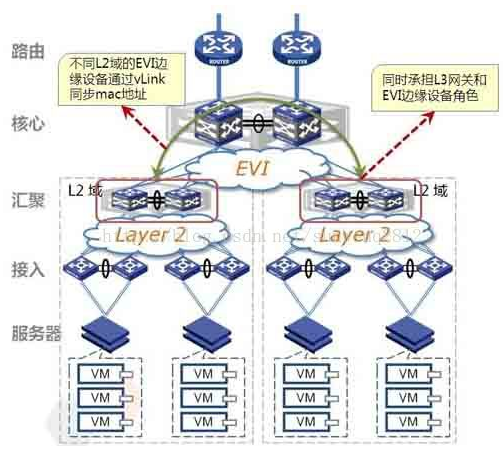
在匯聚層上部署EVI特性,通過核心與匯聚之間的IP網路建立Vlink實現二層互通。通過EVI特性將指定的多個二層域連線起來,形成一個完整的大規模二層網路。這樣就可以實現虛擬機器大規模池化功能。同時,可以避免使用TRILL或是SPB協議帶來的運維風險。
注意:常規IP包轉發過程中,源IP及目的IP保持不變,源MAC與目的MAC不斷髮生變化,既源MAC是自己的mac,目的mac是下一跳(主機或者路由器)的mac;路由器將資料轉發出去的階段,需要知道下一跳的mac地址,通過arp協議獲取,並儲存在路由器的arp表內,供下次查詢使用。