一. kube-proxy 和 service
kube-proxy是Kubernetes的核心元件,部署在每個Node節點上,它是實現Kubernetes Service的通訊與負載均衡機制的重要元件; kube-proxy負責為Pod建立代理服務,從apiserver獲取所有server資訊,並根據server資訊建立代理服務,實現server到Pod的請求路由和轉發,從而實現K8s層級的虛擬轉發網路。
在k8s中,提供相同服務的一組pod可以抽象成一個service,通過service提供的統一入口對外提供服務,每個service都有一個虛擬IP地址(VIP)和埠號供客戶端訪問。kube-proxy存在於各個node節點上,主要用於Service功能的實現,具體來說,就是實現叢集內的客戶端pod訪問service,或者是叢集外的主機通過NodePort等方式訪問service。在當前版本的k8s中,kube-proxy預設使用的是iptables模式,通過各個node節點上的iptables規則來實現service的負載均衡,但是隨著service數量的增大,iptables模式由於線性查詢匹配、全量更新等特點,其效能會顯著下降。從k8s的1.8版本開始,kube-proxy引入了IPVS模式,IPVS模式與iptables同樣基於Netfilter,但是採用的hash表,因此當service數量達到一定規模時,hash查表的速度優勢就會顯現出來,從而提高service的服務效能。
kube-proxy負責為Service提供cluster內部的服務發現和負載均衡,它執行在每個Node計算節點上,負責Pod網路代理, 它會定時從etcd服務獲取到service資訊來做相應的策略,維護網路規則和四層負載均衡工作。在K8s叢集中微服務的負載均衡是由Kube-proxy實現的,它是K8s叢集內部的負載均衡器,也是一個分散式代理伺服器,在K8s的每個節點上都有一個,這一設計體現了它的伸縮性優勢,需要訪問服務的節點越多,提供負載均衡能力的Kube-proxy就越多,高可用節點也隨之增多。
service是一組pod的服務抽象,相當於一組pod的LB,負責將請求分發給對應的pod。service會為這個LB提供一個IP,一般稱為cluster IP。kube-proxy的作用主要是負責service的實現,具體來說,就是實現了內部從pod到service和外部的從node port向service的訪問。
簡單來說:
-> kube-proxy其實就是管理service的訪問入口,包括叢集內Pod到Service的訪問和叢集外訪問service。
-> kube-proxy管理sevice的Endpoints,該service對外暴露一個Virtual IP,也成為Cluster IP, 叢集內通過訪問這個Cluster IP:Port就能訪問到叢集內對應的serivce下的Pod。
-> service是通過Selector選擇的一組Pods的服務抽象,其實就是一個微服務,提供了服務的LB和反向代理的能力,而kube-proxy的主要作用就是負責service的實現。
-> service另外一個重要作用是,一個服務後端的Pods可能會隨著生存滅亡而發生IP的改變,service的出現,給服務提供了一個固定的IP,而無視後端Endpoint的變化。
舉個例子,比如現在有podA,podB,podC和serviceAB。serviceAB是podA,podB的服務抽象(service)。那麼kube-proxy的作用就是可以將pod(不管是podA,podB或者podC)向serviceAB的請求,進行轉發到service所代表的一個具體pod(podA或者podB)上。請求的分配方法一般分配是採用輪詢方法進行分配。另外,kubernetes還提供了一種在node節點上暴露一個埠,從而提供從外部訪問service的方式。比如這裡使用這樣的一個manifest來建立service
apiVersion: v1
kind: Service
metadata:
labels:
name: mysql
role: service
name: mysql-service
spec:
ports:
- port: 3306
targetPort: 3306
nodePort: 30964
type: NodePort
selector:
mysql-service: "true"
上面配置的含義是在node上暴露出30964埠。當訪問node上的30964埠時,其請求會轉發到service對應的cluster IP的3306埠,並進一步轉發到pod的3306埠。
Service, Endpoints與Pod的關係
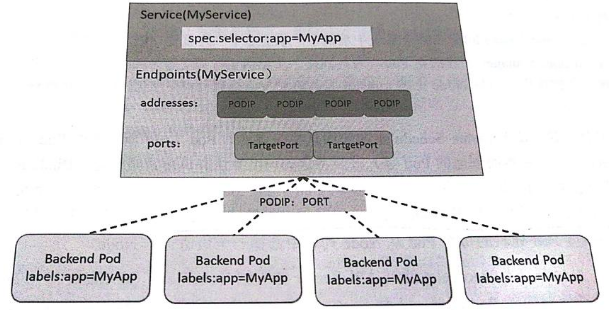
Kube-proxy程式獲取每個Service的Endpoints,實現Service的負載均衡功能
Service的負載均衡轉發規則
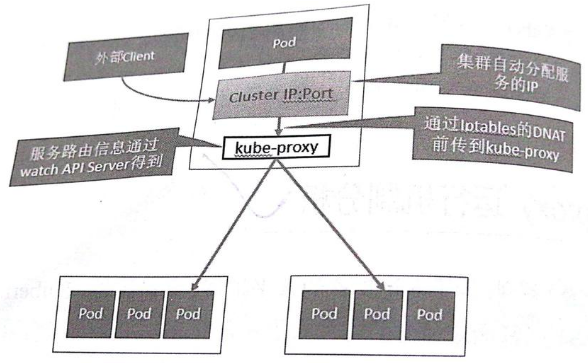
訪問Service的請求,不論是Cluster IP+TargetPort的方式;還是用Node節點IP+NodePort的方式,都被Node節點的Iptables規則重定向到Kube-proxy監聽Service服務代理埠。kube-proxy接收到Service的訪問請求後,根據負載策略,轉發到後端的Pod。
二. kubernetes服務發現
Kubernetes提供了兩種方式進行服務發現, 即環境變數和DNS, 簡單說明如下:
1) 環境變數: 當你建立一個Pod的時候,kubelet會在該Pod中注入叢集內所有Service的相關環境變數。需要注意: 要想一個Pod中注入某個Service的環境變數,則必須Service要先比該Pod建立。這一點,幾乎使得這種方式進行服務發現不可用。比如,一個ServiceName為redis-master的Service,對應的ClusterIP:Port為172.16.50.11:6379,則其對應的環境變數為:
REDIS_MASTER_SERVICE_HOST=172.16.50.11 REDIS_MASTER_SERVICE_PORT=6379 REDIS_MASTER_PORT=tcp://172.16.50.11:6379 REDIS_MASTER_PORT_6379_TCP=tcp://172.16.50.11:6379 REDIS_MASTER_PORT_6379_TCP_PROTO=tcp REDIS_MASTER_PORT_6379_TCP_PORT=6379 REDIS_MASTER_PORT_6379_TCP_ADDR=172.16.50.11
2) DNS:這是k8s官方強烈推薦的方式!!! 可以通過cluster add-on方式輕鬆的建立KubeDNS來對叢集內的Service進行服務發現。kubernetes的DNS Service內部實現框架和互動邏輯可以見如下草圖:
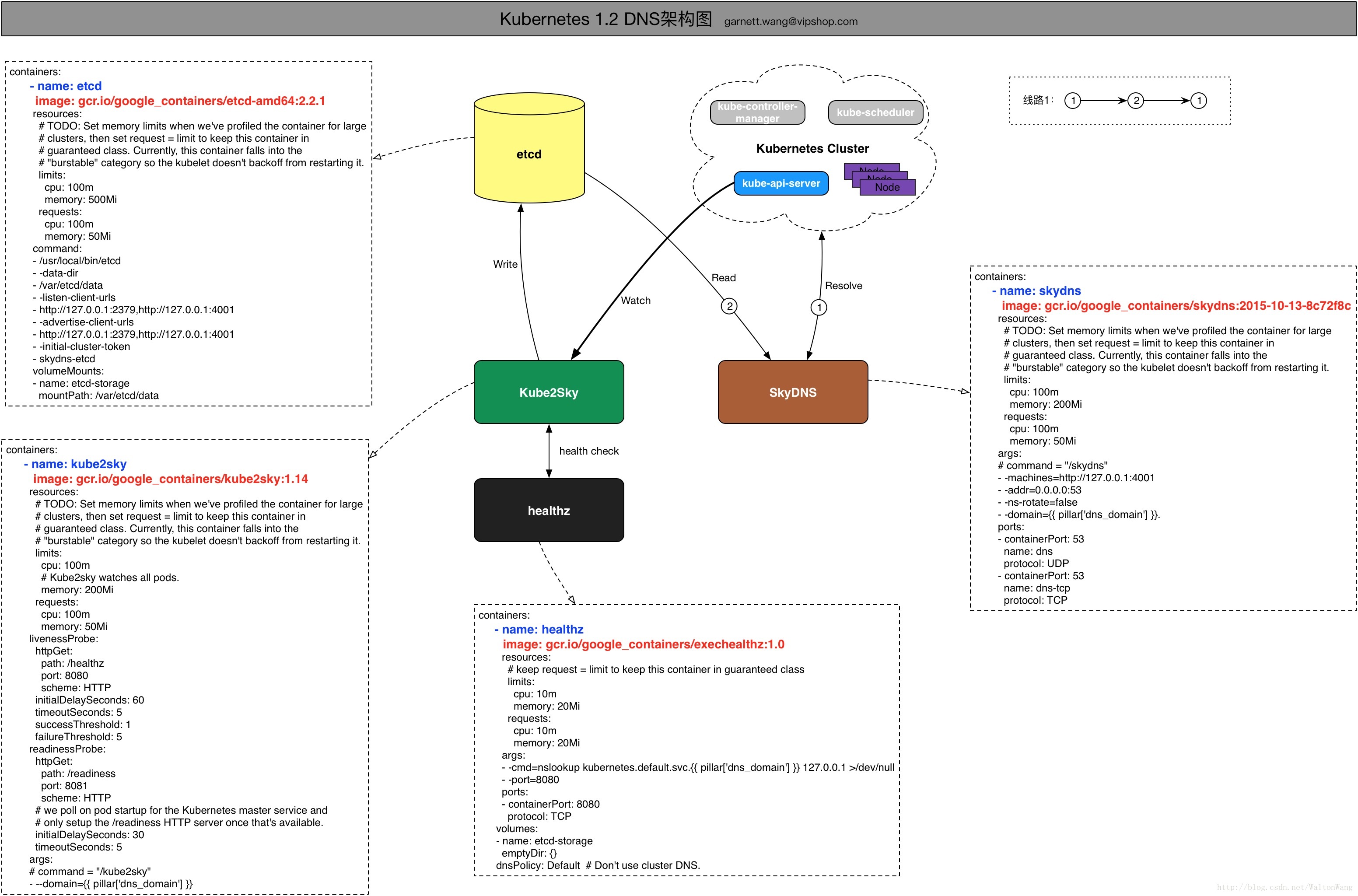
如上草圖說明:
-> 線路1:kubernetes cluster中的DNS請求被SkyDNS接受,SkyDNS配置了Backend為etcd/cluster,從etcd/cluster中讀取資料,然後封裝資料返回完成DNS query請求。
-> Kube2Sky通過watch kube-api-server對service & endpoint的資料來進行更新etcd中/v2/key/skydns/…中的資料。
再看下圖:
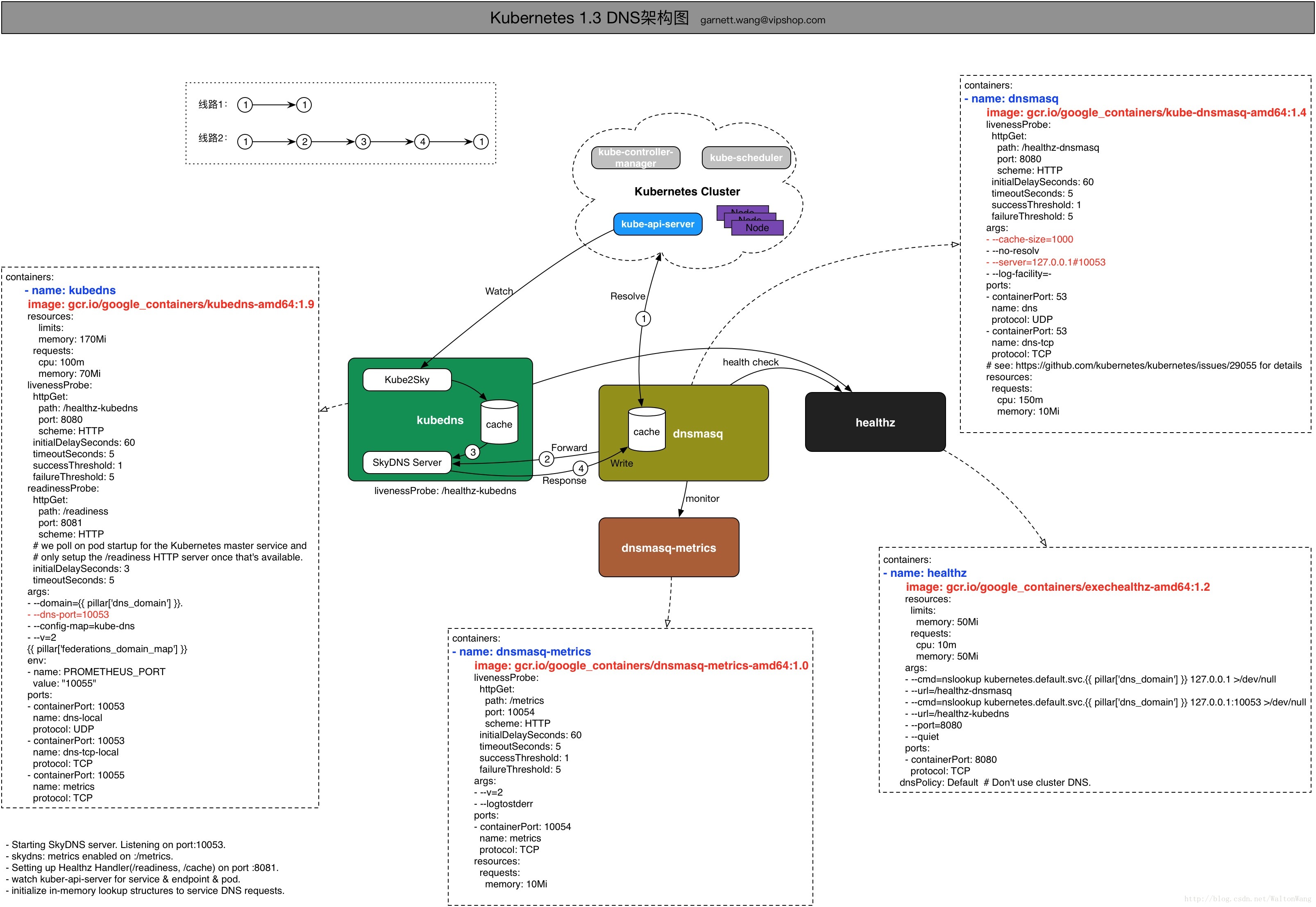
在kubernetes 1.3版本之後, KubeDNS容器就把在1.2中分開部署的SkyDNS和Kube2Sky整合在程式kube-dns中,在容器KubeDNS中部署,其啟動流程如下:
-> Starting SkyDNS server. Listening on port:10053.
-> skydns: metrics enabled on :/metrics.
-> Setting up Healthz Handler(/readiness, /cache) on port :8081.
-> watch kuber-api-server for service & endpoint & pod.
-> initialize in-memory lookup structures to service DNS requests.
說明:
-> 線路1:kubernetes cluster中的DNS請求被dnsmasq接受,dnsmasq預設配置了一個1G大小的cache,以提高效能。如果dnsmasq cache中有記錄命中,則直接有dnsmasq返回。
-> 線路2:若dnsmasq cache中無記錄命中,則forward請求到KubeDNS容器中的SkyDNS Server處理,SkyDNS從KubeDNS維護的一塊記憶體(cache)中查詢資料並進行響應。這個cache是由類似1.2中的Kube2Sky中的模組通過watch kube-api-server對service & endpoint的資料來進行更新維護。
需要注意: 在kubernetes 1.2版本中SkyDNS和Kube2Sky分別部署在兩個不同的容器中,直接由SkyDNS接受kubernetes cluster中的DNS請求;但是在kubernetes 1.3版本後, 就將SkyDNS和Kube2Sky整合到了一個程式中KubeDNS;kubernetes 1.3版本中引入了dnsmasq容器,由它接受kubernetes cluster中的DNS請求,目的就是利用dnsmasq的cache模組,提高效能;
三. kubernetes釋出(暴露)服務
kubernetes原生的,一個Service的ServiceType決定了其釋出服務的方式。
-> ClusterIP:這是k8s預設的ServiceType。通過叢集內的ClusterIP在內部發布服務。
-> NodePort:這種方式是常用的,用來對叢集外暴露Service,你可以通過訪問叢集內的每個NodeIP:NodePort的方式,訪問到對應Service後端的Endpoint。
-> LoadBalancer: 這也是用來對叢集外暴露服務的,不同的是這需要Cloud Provider的支援,比如AWS等。
-> ExternalName:這個也是在叢集內釋出服務用的,需要藉助KubeDNS(version >= 1.7)的支援,就是用KubeDNS將該service和ExternalName做一個Map,KubeDNS返回一個CNAME記錄。
四. kube-proxy 工作原理 (userspace, iptables, ipvs)
kube-proxy當前實現了三種代理模式:userspace, iptables, ipvs。其中userspace mode是v1.0及之前版本的預設模式,從v1.1版本中開始增加了iptables mode,在v1.2版本中正式替代userspace模式成為預設模式。也就是說kubernetes在v1.2版本之前是預設模式, v1.2版本之後預設模式是iptables。
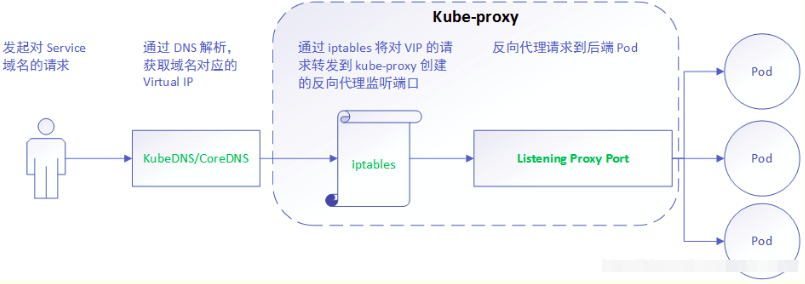
1) userspace mode: userspace是在使用者空間,通過kube-proxy來實現service的代理服務, 其原理如下:
可見,userspace這種mode最大的問題是,service的請求會先從使用者空間進入核心iptables,然後再回到使用者空間,由kube-proxy完成後端Endpoints的選擇和代理工作,這樣流量從使用者空間進出核心帶來的效能損耗是不可接受的。這也是k8s v1.0及之前版本中對kube-proxy質疑最大的一點,因此社群就開始研究iptables mode.
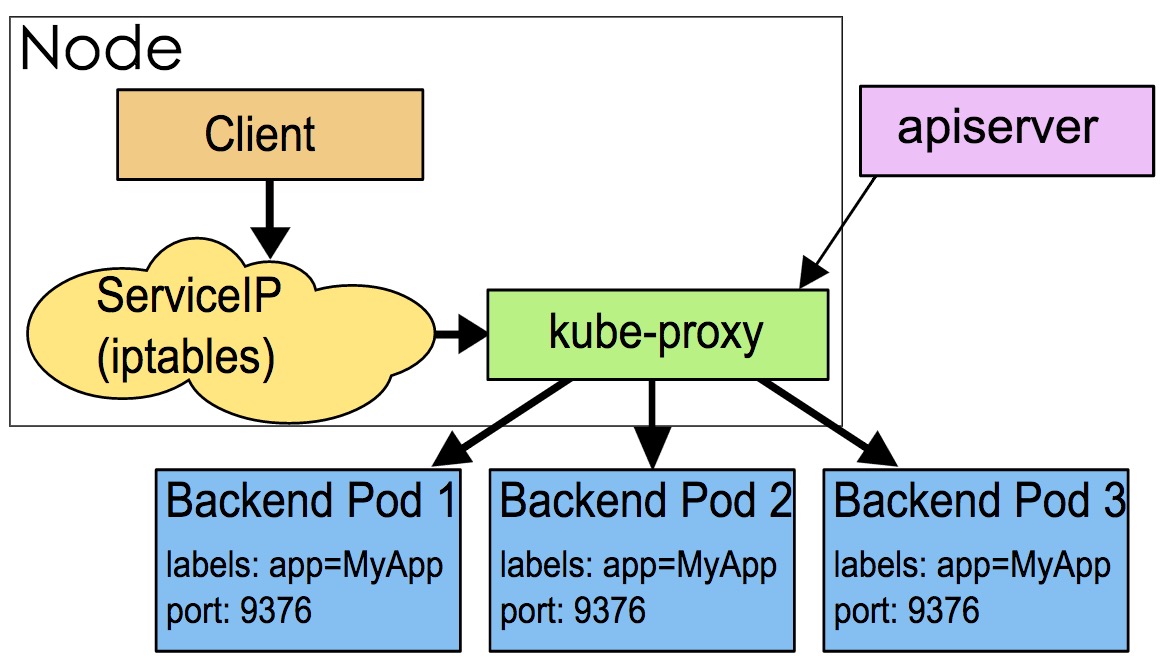
userspace這種模式下,kube-proxy 持續監聽 Service 以及 Endpoints 物件的變化;對每個 Service,它都為其在本地節點開放一個埠,作為其服務代理埠;發往該埠的請求會採用一定的策略轉發給與該服務對應的後端 Pod 實體。kube-proxy 同時會在本地節點設定 iptables 規則,配置一個 Virtual IP,把發往 Virtual IP 的請求重定向到與該 Virtual IP 對應的服務代理埠上。其工作流程大體如下:
由此分析: 該模式請求在到達 iptables 進行處理時就會進入核心,而 kube-proxy 監聽則是在使用者態, 請求就形成了從使用者態到核心態再返回到使用者態的傳遞過程, 一定程度降低了服務效能。
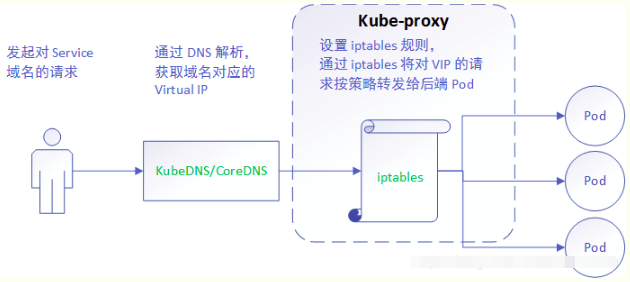
2) iptables mode, 該模式完全利用核心iptables來實現service的代理和LB, 這是K8s在v1.2及之後版本預設模式. 工作原理如下:
iptables mode因為使用iptable NAT來完成轉發,也存在不可忽視的效能損耗。另外,如果叢集中存在上萬的Service/Endpoint,那麼Node上的iptables rules將會非常龐大,效能還會再打折扣。這也導致目前大部分企業用k8s上生產時,都不會直接用kube-proxy作為服務代理,而是通過自己開發或者通過Ingress Controller來整合HAProxy, Nginx來代替kube-proxy。
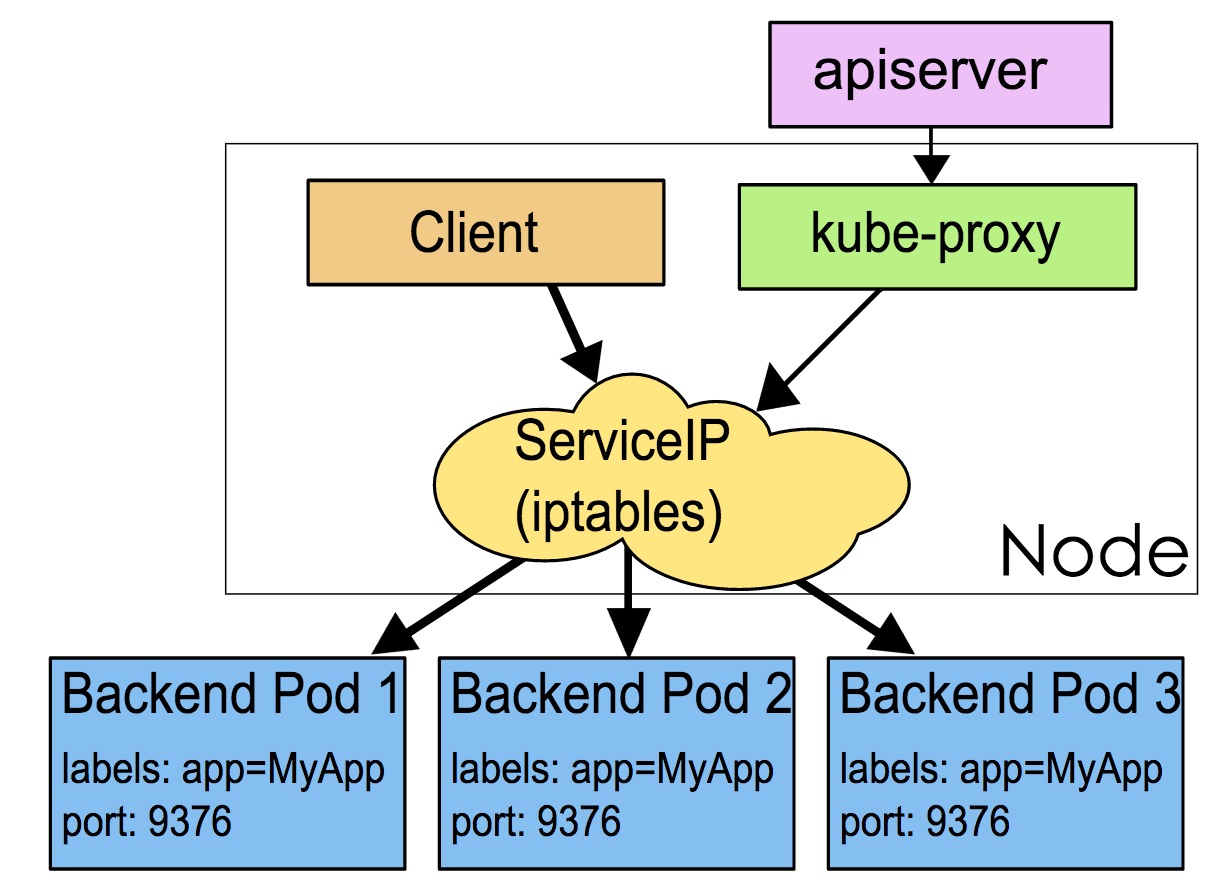
iptables 模式與 userspace 相同,kube-proxy 持續監聽 Service 以及 Endpoints 物件的變化;但它並不在本地節點開啟反向代理服務,而是把反向代理全部交給 iptables 來實現;即 iptables 直接將對 VIP 的請求轉發給後端 Pod,通過 iptables 設定轉發策略。其工作流程大體如下:
由此分析: 該模式相比 userspace 模式,克服了請求在使用者態-核心態反覆傳遞的問題,效能上有所提升,但使用 iptables NAT 來完成轉發,存在不可忽視的效能損耗,而且在大規模場景下,iptables 規則的條目會十分巨大,效能上還要再打折扣。
iptables的方式則是利用了linux的iptables的nat轉發進行實現:
apiVersion: v1
kind: Service
metadata:
labels:
name: mysql
role: service
name: mysql-service
spec:
ports:
- port: 3306
targetPort: 3306
nodePort: 30964
type: NodePort
selector:
mysql-service: "true"
mysql-service對應的nodePort暴露出來的埠為30964,對應的cluster IP(10.254.162.44)的埠為3306,進一步對應於後端的pod的埠為3306。 mysql-service後端代理了兩個pod,ip分別是192.168.125.129和192.168.125.131, 這裡先來看一下iptables:
$iptables -S -t nat ... -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING -A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000 -A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-SVC-67RL4FN6JRUPOJYM -A KUBE-SEP-ID6YWIT3F6WNZ47P -s 192.168.125.129/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ -A KUBE-SEP-ID6YWIT3F6WNZ47P -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.129:3306 -A KUBE-SEP-IN2YML2VIFH5RO2T -s 192.168.125.131/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ -A KUBE-SEP-IN2YML2VIFH5RO2T -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.131:3306 -A KUBE-SERVICES -d 10.254.162.44/32 -p tcp -m comment --comment "default/mysql-service: cluster IP" -m tcp --dport 3306 -j KUBE-SVC-67RL4FN6JRUPOJYM -A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS -A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-ID6YWIT3F6WNZ47P -A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -j KUBE-SEP-IN2YML2VIFH5RO2T
首先如果是通過node的30964埠訪問,則會進入到以下鏈:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-SVC-67RL4FN6JRUPOJYM
然後進一步跳轉到KUBE-SVC-67RL4FN6JRUPOJYM的鏈:
-A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-ID6YWIT3F6WNZ47P -A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -j KUBE-SEP-IN2YML2VIFH5RO2T
這裡利用了iptables的–probability的特性,使連線有50%的概率進入到KUBE-SEP-ID6YWIT3F6WNZ47P鏈,50%的概率進入到KUBE-SEP-IN2YML2VIFH5RO2T鏈。 KUBE-SEP-ID6YWIT3F6WNZ47P的鏈的具體作用就是將請求通過DNAT傳送到192.168.125.129的3306埠:
-A KUBE-SEP-ID6YWIT3F6WNZ47P -s 192.168.125.129/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ -A KUBE-SEP-ID6YWIT3F6WNZ47P -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.129:3306
同理KUBE-SEP-IN2YML2VIFH5RO2T的作用是通過DNAT傳送到192.168.125.131的3306埠:
-A KUBE-SEP-IN2YML2VIFH5RO2T -s 192.168.125.131/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ -A KUBE-SEP-IN2YML2VIFH5RO2T -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.131:3306
分析完nodePort的工作方式,接下里說一下clusterIP的訪問方式。 對於直接訪問cluster IP(10.254.162.44)的3306埠會直接跳轉到KUBE-SVC-67RL4FN6JRUPOJYM
-A KUBE-SERVICES -d 10.254.162.44/32 -p tcp -m comment --comment "default/mysql-service: cluster IP" -m tcp --dport 3306 -j KUBE-SVC-67RL4FN6JRUPOJYM
接下來的跳轉方式同NodePort方式。
3) ipvs mode. 在kubernetes 1.8以上的版本中,對於kube-proxy元件增加了除iptables模式和使用者模式之外還支援ipvs模式。kube-proxy ipvs 是基於 NAT 實現的,通過ipvs的NAT模式,對訪問k8s service的請求進行虛IP到POD IP的轉發。當建立一個 service 後,kubernetes 會在每個節點上建立一個網路卡,同時幫你將 Service IP(VIP) 繫結上,此時相當於每個 Node 都是一個 ds,而其他任何 Node 上的 Pod,甚至是宿主機服務(比如 kube-apiserver 的 6443)都可能成為 rs;
與iptables、userspace 模式一樣,kube-proxy 依然監聽Service以及Endpoints物件的變化, 不過它並不建立反向代理, 也不建立大量的 iptables 規則, 而是通過netlink 建立ipvs規則,並使用k8s Service與Endpoints資訊,對所在節點的ipvs規則進行定期同步; netlink 與 iptables 底層都是基於 netfilter 鉤子,但是 netlink 由於採用了 hash table 而且直接工作在核心態,在效能上比 iptables 更優。其工作流程大體如下:
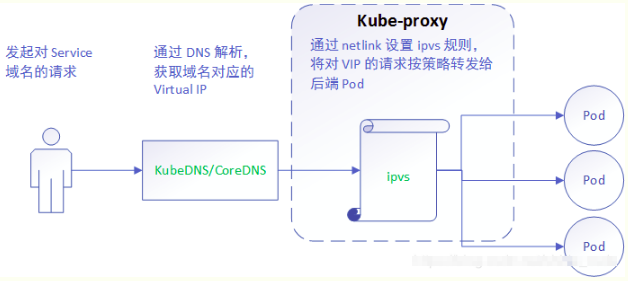
由此分析:ipvs 是目前 kube-proxy 所支援的最新代理模式,相比使用 iptables,使用 ipvs 具有更高的效能。