最近了解下Nginx的Code狀態碼,在此簡單總結下。一個http請求處理流程:
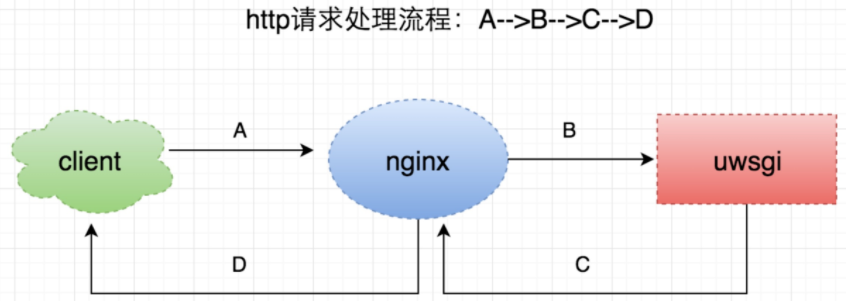
一個普通的http請求處理流程,如上圖所示:
A -> client端發起請求給nginx
B -> nginx處理後,將請求轉發到uwsgi,並等待結果
C -> uwsgi處理完請求後,返回資料給nginx
D -> nginx將處理結果返回給客戶端
每個階段都會有一個預設的超時時間,由於網路、機器負載、程式碼異常等等各種原因,如果某個階段沒有在預期的時間內正常返回,就會導致這次請求異常,進而產生不同的狀態碼。
1)504 錯誤
504主要是針對B、C階段。一般nginx配置中會有:
location / {
...
uwsgi_connect_timeout 6s;
uwsgi_send_timeout 6s;
uwsgi_read_timeout 10s;
uwsgi_buffering on;
uwsgi_buffers 80 16k;
...
}
這個代表nginx與上游伺服器(uwsgi)通訊的超時時間,也就是說,如果在這個時間內,uwsgi沒有響應,則認為這次請求超時,返回504狀態碼。
具體的日誌如下:
access_log
[16/May/2016:22:11:38 +0800] 10.4.31.56 201605162211280100040310561523 15231401463407888908 10.*.*.* 127.0.0.1:8500 "GET /api/media_article_list/?count=10&source_type=0&status=all&from_time=0&item_id=0&flag=2&_=1463407896337 HTTP/1.1" 504 **.***.com **.**.**.39, **.**.**.60 10.000 10.000 "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36" ...
error_log
2016/05/16 22:11:38 [error] 90674#0: *947302032 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 10.6.19.81, server: **.***.com, request: "GET /api/media_article_list/?count=10&source_type=0&status=all&from_time=0&item_id=0&flag=2&_=1463407896337 HTTP/1.1", upstream: "http://127.0.0.1:8500/**/**/api/media_article_list/?count=10&source_type=0&status=all&from_time=0&item_id=0&flag=2&_=1463407896337", host: "mp.toutiao.com", referrer: "https://**.***.com/articles/?source_type=0"
error_log中upstream timed out (110: Connection timed out) while reading response header from upstream,
意思是說,在規定的時間內,沒有從header中拿到資料,即uwsgi沒有返回任何資料。
Nginx 504 Gateway Time-out的含義是所請求的閘道器沒有請求到,簡單來說就是沒有請求到可以執行的PHP-CGI。Nginx 504 Gateway Time-out則是與nginx.conf的設定有關。504 Gateway Time-out問題常見於使用nginx作為web server的伺服器的網站。
一般看來, 這種情況可能是由於nginx預設的fastcgi程式響應的緩衝區太小造成的, 這將導致fastcgi程式被掛起, 如果你的fastcgi服務對這個掛起處理的不好, 那麼最後就極有可能導致504 Gateway Time-out現在的網站, 尤其某些論壇有大量的回覆和很多內容的, 一個頁面甚至有幾百K預設的fastcgi程式響應的緩衝區是8K, 我們可以設定大點在nginx.conf裡, 加入:
fastcgi_buffers 8 128k 這表示設定fastcgi緩衝區為8×128k,當然如果您在進行某一項即時的操作, 可能需要nginx的超時引數調大點, 例如設定成60秒: send_timeout 60; 只是調整了上面這兩個引數, 結果可能就是沒有再顯示那個超時! 解決辦法:調整nginx.conf的相關設定: fastcgi_connect_timeout 600; fastcgi_send_timeout 600; fastcgi_read_timeout 600; fastcgi_buffer_size 256k; fastcgi_buffers 16 256k; fastcgi_busy_buffers_size 512k; fastcgi_temp_file_write_size 512k;
2)502 錯誤
502主要針對B 、C階段。產生502的時候,對應的error_log中的內容會有好幾種:
access_log
[16/May/2016:16:39:49 +0800] 10.4.31.56 201605161639490100040310562612 2612221463387989972 10.6.19.81 127.0.0.1:88 "GET /articles/?source_type=0 HTTP/1.1" 503 **.***.com **.**.**.4, **.**.**.160 0.000 0.000 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36" "uuid=\x22w:546d345b86ca443eb44bd9bb1120e821\x22; tt_webid=15660522398; lasttag=news_culture; sessionid=f172028cc8310ba7f503adb5957eb3ea; sid_tt=f172028cc8310ba7f503adb5957eb3ea; _ga=GA1.2.354066248.1463056713; _gat=1"
error_log
2016/05/16 16:39:49 [error] 90693#0: *944980723 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 10.6.19.80, server: **.***.com, request: "GET /articles/ HTTP/1.1", upstream: "http://127.0.0.1:8500/**/**/articles/", host: "**.***.com", referrer: "http://**.***.com/new_article/"
列一下常見的幾種502對應的 error_log:
- recv() failed (104: Connection reset by peer) while reading response header from upstream
- upstream prematurely closed connection while reading response header from upstream
- connect() failed (111: Connection refused) while connecting to upstream
- ....
這些都代表,在nginx設定的超時時間內,上游uwsgi沒有給正確的響應(但是是有響應的,不然如果一直沒響應,就會變成504超時了),因此nginx這邊的狀態碼為502。
如上,access_log中出現503,為什麼?
這個是因為nginx upstream的容災機制。如果nginx有如下配置:
upstream app_backup {
server 127.0.0.1:8500 max_fails=3 fail_timeout=5s;
server 127.0.0.1:88 backup;
}
- max_fails=3 說明嘗試3次後,會認為“ server 127.0.0.1:8500” 失效,於是進入 “server 127.0.0.1:88 backup”,即訪問本機的88埠;
- nginx upstream的容災機制,預設情況下,Nginx 預設判斷失敗節點狀態以connect refuse和time out狀態為準,不過location里加了這個配置:
proxy_next_upstream error http_502; proxy_connect_timeout 1s; proxy_send_timeout 6s; proxy_read_timeout 10s; proxy_set_header Host $host;
- 這個配置是說,對於http狀態是502的情況,也會走upstream的容災機制;
- 概括一下就是,如果連續有3次(max_fails=3)狀態為502的請求,則會任務這個後端server 127.0.0.1:8500 掛掉了,在接下來的5s(fail_timeout=5s)內,就會訪問backup,即server 127.0.0.1:88 ,看下88埠對應的是什麼:
server { listen 88; access_log /var/log/nginx/failover.log; expires 1m; error_page 500 502 503 504 /500.html; location / { return 503; } location = /500.html { root /**/**/**/nginx/5xx/; } }
這個的意思就是,對於訪問88埠的請求,nginx會返回503狀態碼,同時返回/opt/tiger/ss_conf/nginx/5xx/這個路徑下的500.html檔案。
因此,access_log中看到的是503。
Nginx 502 Bad Gateway的含義是請求的PHP-CGI已經執行,但是由於某種原因(一般是讀取資源的問題)沒有執行完畢而導致PHP-CGI程式終止。Nginx 502錯誤的原因比較多,一般就是因為在代理模式下後端伺服器出現問題引起的。這些錯誤一般都不是nginx本身的問題,一定要從後端找原因!比如:php-cgi程式數不夠用、php執行時間長、或者是php-cgi程式死掉,都會出現502錯誤。502錯誤最通常的出現情況就是後端主機當機!!
一般來說Nginx 502 Bad Gateway和php-fpm.conf的設定有關,php-fpm.conf有兩個至關重要的引數,一個是"max_children",另一個是"request_terminate_timeout" ,但是這個值不是通用的,而是需要自己計算的。
計算的方式如下:
1)request_terminate_timeout
如果伺服器效能足夠好,且寬頻資源足夠充足,PHP指令碼沒有系迴圈或BUG的話你可以直接將"request_terminate_timeout"設定成0s。0s的含義是讓PHP-CGI一直執行下去而沒有時間限制。而如果你做不到這一點,也就是說你的PHP-CGI可能出現某個BUG,或者你的寬頻不夠充足或者其他的原因導致你的PHP-CGI能夠假死那麼就建議你給"request_terminate_timeout"賦一個值,這個值可以根據你伺服器的效能進行設定。一般來說效能越好你可以設定越高,20分鐘 -30分鐘都可以。由於我的伺服器PHP指令碼需要長時間執行,有的可能會超過10分鐘因此我設定了900秒,這樣不會導致PHP-CGI死掉而出現502 Bad gateway這個錯誤。
2)max_children
max_children這個值又是怎麼計算出來的呢?這個值原則上是越大越好,php-cgi的程式多了就會處理的很快,排隊的請求就會很少。設定"max_children"也需要根據伺服器的效能進行設定,一般來說一臺伺服器正常情況下每一個php-cgi所耗費的記憶體在20M左右,因此我的"max_children"我設定成40個,20M*40=800M也就是說在峰值的時候所有PHP-CGI所耗記憶體在800M以內,低於我的有效記憶體1Gb。而如果我的"max_children"設定的較小,比如5-10個,那麼 php-cgi就會“很累",處理速度也很慢,等待的時間也較長。如果長時間沒有得到處理的請求就會出現504 Gateway Time-out這個錯誤,而正在處理的很累的那幾個php-cgi如果遇到了問題就會出現502 Bad gateway這個錯誤。
=================502的解決辦法================
一般解決辦法
遇到502問題,可以優先考慮按照以下兩個步驟去解決。
1)檢視當前的PHP FastCGI程式數是否夠用:)
netstat -anpo | grep "php-cgi" | wc -l
如果實際使用的“FastCGI程式數”接近預設的“FastCGI程式數”,那麼,說明“FastCGI程式數”不夠用,需要增大。
# ps aux | grep php-cgi |wc -l
130
# netstat -anpo | grep "php-cgi" | wc -l
450
# netstat -anpo | grep "php-cgi" |more
tcp 0 0 192.168.12.201:52719 192.168.12.203:13002 ESTABLISHED 27687/php-cgi off (0.00/0/0)
tcp 0 0 192.168.12.201:52713 192.168.12.203:13002 ESTABLISHED 27685/php-cgi off (0.00/0/0)
tcp 0 0 192.168.12.201:52694 192.168.12.203:13002 ESTABLISHED 27682/php-cgi off (0.00/0/0)
tcp 0 0 192.168.12.201:52688 192.168.12.203:13002 ESTABLISHED 27681/php-cgi off (0.00/0/0)
tcp 0 0 192.168.12.201:52701 192.168.12.203:13002 ESTABLISHED 27683/php-cgi off (0.00/0/0)
重啟php服務後
# netstat -anpo | grep "php-cgi" | wc -l
46
2)部分PHP程式的執行時間超過了Nginx的等待時間,可以適當增加nginx.conf配置檔案中FastCGI的timeout時間,例如:
...... http { ...... fastcgi_connect_timeout 300; fastcgi_send_timeout 300; fastcgi_read_timeout 300; ...... } ......
php.ini中memory_limit設低了會出錯,修改了php.ini的memory_limit為128M,重啟nginx,發現好了,原來是PHP的記憶體不足了。
臨時解決辦法
Nginx提示502和504錯誤的臨時解決辦法是:調整php-fpm.conf的相關設定: <value name=”max_children”>32</value> <value name=”request_terminate_timeout”>30s</value> fast-cgi的執行指令碼時間
終級解決方案
以上解決方案只能臨時解決問題,而如果網站的訪問量確實非常非常大,而Nginx+FastCGI只能對處理瞬間或短時間內的高併發有很好的效果, 所以目前唯一的終極解決方案是:定時平滑重啟php-cgi。 1)寫一個非常簡單的指令碼: # vim /home/www/scripts/php-fpm.sh #!/bin/bash # This script run at */1 /usr/local/php/sbin/php-fpm reload 2)將指令碼新增至計劃任務:) # crontab -e */1 * * * * /home/www/scripts/php-fpm.sh 為了省事起見,也可以不寫指令碼,直接在crontab裡寫入php-fpm的平滑重啟命令。
Nginx 502錯誤情況
1))網站的訪問量大,而php-cgi的程式數偏少。 針對這種情況的502錯誤,只需增加php-cgi的程式數。具體就是修改/usr/local/php/etc/php-fpm.conf 檔案,將其中的max_children值適當增加。 這個資料要依據你的VPS或獨立伺服器的配置進行設定。一般一個php-cgi程式佔20M記憶體,你可以自己計算下,適量增多。 /usr/local/php/sbin/php-fpm restart 然後重啟一下. 2))CPU佔用率、記憶體佔用率非常高,遭到CC攻擊. 解決方法請參考:Linux VPS簡單解決CC攻擊 3)CPU佔用率不高,記憶體溢位。 檢查一下網站程式有沒有問題?一般小偷站點常常會出現記憶體溢位。 檢查一下/var/log/目錄下的日誌,看看是不是有人爆破SSH和FTP埠? SSH、FTP遭到窮舉也會佔用大量記憶體。是的話改掉SSH埠和FTP埠即可。
3)499錯誤
client傳送請求後,如果在規定的時間內(假設超時時間為500ms)沒有拿到nginx給的響應,則認為這次請求超時,會主動結束,這個時候nginx的access_log就會列印499狀態碼。
A+B+C+D > 500ms
其實這個時候,server端有可能還在處理請求,只不過client斷掉了連線,因此處理結果也無法返回給客戶端。
499如果比較多的話,可能會引起服務雪崩。
比如說,client一直在發起請求,客戶端因為某些原因處理慢了,沒有在規定時間內返回資料,client認為請求失敗,中斷這次請求,然後再重新發起請求。這樣不斷的重複,服務端的請求越來越多,機器負載變大,請求處理越來越慢,沒有辦法響應任何請求
官網總結nginx返回499的情況,是由於:
client has closed connection #客戶端主動關閉了連線。
client has closed connection #客戶端主動關閉了連線。
client has closed connection #客戶端主動關閉了連線。
解決的話,可以新增
proxy_ignore_client_abort on;
還有一種原因,確實是客戶端關閉了連線,或者連線超時。主要是因為PHP程式數太少,或php程式佔用,資源不能很快釋放,請求堆積。這種情況要解決的話,需要在程式上做優化。
499報錯即是客戶端關閉連線,這個狀態碼並不是http協議中定義的status code,而是nginx自己定義的一個狀態碼。由於伺服器處理請求較多,客戶端在有效時間內沒有得到答覆,主動關閉了連線。有人說把時間設定長一些或者使用proxy_ignore_client_abort on(讓代理服務端不要主動關閉客戶端的連線)。但是這樣也有一定的風險,會拖垮伺服器。發生這個錯誤,如果伺服器CPU和記憶體不算太高,一般是資料庫和程式的問題,資料庫處理較慢或者程式執行緒較低。結合情況調整,比如讀寫分離或者程式執行緒數調高。
4)500錯誤
伺服器內部錯誤,也就是伺服器遇到意外情況,而無法執行請求。發生錯誤,一般的幾種情況:
- web指令碼錯誤,如php語法錯誤,lua語法錯誤等。
- 訪問量大的時候,由於系統資源限制,而不能開啟過多的檔案控制程式碼
分析錯誤的原因
- 檢視nginx,php的錯誤日誌
- 如果是too many open files,修改nginx的worker_rlimit_nofile引數,使用ulimit檢視系統開啟檔案限制,修改/etc/security/limits.conf
- 如果指令碼存在問題,則需要修復指令碼錯誤,並優化程式碼
- 各種優化都做好,還是出現too many open files,那就需要考慮做負載均衡,把流量分散到不同伺服器上去
5)503錯誤
503是服務不可用的返回狀態。
由於在nginx配置中,設定了limit_req的流量限制,導致許多請求返回503錯誤程式碼,在限流的條件下,為提高使用者體驗,希望返回正常Code 200,且返回操作頻繁的資訊:
location /test {
...
limit_req zone=zone_ip_rm burst=1 nodelay;
error_page 503 =200 /dealwith_503?callback=$arg_callback;
}
location /dealwith_503{
set $ret_body '{"code": "V00006","msg": "操作太頻繁了,請坐下來喝杯茶。"}';
if ( $arg_callback != "" )
{
return 200 'try{$arg_callback($ret_body)}catch(e){}';
}
return 200 $ret_body;
}
6)400錯誤:request header or cookie too large
解決辦法:
修改nginx.conf,新增下面內容(即增加緩衝區)
[root@fvtlb01 ~]# vim /data/nginx/conf/nginx.conf
......
http
{
......
client_header_buffer_size 8k; #預設是4k(可以稍微改大,比如16K)
large_client_header_buffers 4 8k;
......
}
=================nginx日誌"110: Connection timed out"報錯=================
訪問nginx頁面,出現5xx報錯。檢視nginx日誌,發現如下報錯資訊: upstream timed out (110: Connection timed out) while reading response header from upstream 解決辦法:修改fastcgi_read_timeout的時間值,預設是60s,比如可以改成600s或3000s
................................................Nginx Code Status...............................
200:伺服器成功返回網頁 403:伺服器拒絕請求。 404:請求的網頁不存在 499:客戶端主動斷開了連線。 500:伺服器遇到錯誤,無法完成請求。 502:伺服器作為閘道器或代理,從上游伺服器收到無效響應。 503 - 服務不可用 504:伺服器作為閘道器或代理,但是沒有及時從上游伺服器收到請求。 這些狀態碼被分為五大類: 100-199 用於指定客戶端應相應的某些動作。 200-299 用於表示請求成功。 300-399 用於已經移動的檔案並且常被包含在定位頭資訊中指定新的地址資訊。 400-499 用於指出客戶端的錯誤。 (自己電腦這邊的問題) 自己電腦這邊的問題) 500-599 用於支援伺服器錯誤。 (對方的問題) 對方的問題) --------------------------------------------------------------------------------------------- 200 (成功) 伺服器已成功處理了請求。 通常,這表示伺服器提供了請求的網頁。 201 (已建立) 請求成功並且伺服器建立了新的資源。 202 (已接受) 伺服器已接受請求,但尚未處理。 203 (非授權資訊) 伺服器已成功處理了請求,但返回的資訊可能來自另一來源。 204 (無內容) 伺服器成功處理了請求,但沒有返回任何內容。 205 (重置內容) 伺服器成功處理了請求,但沒有返回任何內容。 206 (部分內容) 伺服器成功處理了部分 GET 請求。 --------------------------------------------------------------------------------------------- 300 (多種選擇) 針對請求,伺服器可執行多種操作。 伺服器可根據請求者 (user agent) 選擇一項操作,或提供操作列表供請求者選擇。 301 (永久移動) 請求的網頁已永久移動到新位置。 伺服器返回此響應(對 GET 或 HEAD 請求的響應)時,會自動將請求者轉到新位置。 302 (臨時移動) 伺服器目前從不同位置的網頁響應請求,但請求者應繼續使用原有位置來進行以後的請求。 303 (檢視其他位置) 請求者應當對不同的位置使用單獨的 GET 請求來檢索響應時,伺服器返回此程式碼。 304 (未修改) 自從上次請求後,請求的網頁未修改過。 伺服器返回此響應時,不會返回網頁內容。 305 (使用代理) 請求者只能使用代理訪問請求的網頁。 如果伺服器返回此響應,還表示請求者應使用代理。 307 (臨時重定向) 伺服器目前從不同位置的網頁響應請求,但請求者應繼續使用原有位置來進行以後的請求。 --------------------------------------------------------------------------------------------- 400 (錯誤請求) 伺服器不理解請求的語法。 401 (未授權) 請求要求身份驗證。 對於需要登入的網頁,伺服器可能返回此響應。 403 (禁止) 伺服器拒絕請求。 404 (未找到) 伺服器找不到請求的網頁。 405 (方法禁用) 禁用請求中指定的方法。 406 (不接受) 無法使用請求的內容特性響應請求的網頁。 407 (需要代理授權) 此狀態程式碼與 401(未授權)類似,但指定請求者應當授權使用代理。 408 (請求超時) 伺服器等候請求時發生超時。 409 (衝突) 伺服器在完成請求時發生衝突。 伺服器必須在響應中包含有關衝突的資訊。 410 (已刪除) 如果請求的資源已永久刪除,伺服器就會返回此響應。 411 (需要有效長度) 伺服器不接受不含有效內容長度標頭欄位的請求。 412 (未滿足前提條件) 伺服器未滿足請求者在請求中設定的其中一個前提條件。 413 (請求實體過大) 伺服器無法處理請求,因為請求實體過大,超出伺服器的處理能力。 414 (請求的 URI 過長) 請求的 URI(通常為網址)過長,伺服器無法處理。 415 (不支援的媒體型別) 請求的格式不受請求頁面的支援。 416 (請求範圍不符合要求) 如果頁面無法提供請求的範圍,則伺服器會返回此狀態程式碼。 417 (未滿足期望值) 伺服器未滿足"期望"請求標頭欄位的要求。 --------------------------------------------------------------------------------------------- 500 (伺服器內部錯誤) 伺服器遇到錯誤,無法完成請求。 501 (尚未實施) 伺服器不具備完成請求的功能。 例如,伺服器無法識別請求方法時可能會返回此程式碼。 502 (錯誤閘道器) 伺服器作為閘道器或代理,從上游伺服器收到無效響應。 503 (服務不可用) 伺服器目前無法使用(由於超載或停機維護)。 通常,這只是暫時狀態。 504 (閘道器超時) 伺服器作為閘道器或代理,但是沒有及時從上游伺服器收到請求。 505 (HTTP 版本不受支援) 伺服器不支援請求中所用的 HTTP 協議版本。
proxy_intercept_errors
當上遊伺服器響應頭回來後,可以根據響應狀態碼的值進行攔截錯誤處理,與error_page 指令相互結合。用在訪問上游伺服器出現錯誤的情況下。
如下的一個配置例項:
[root@dev ~]# cat ssl-zp.wangshibo.conf
upstream mianshi1 {
server 192.168.1.33:8080 max_fails=3 fail_timeout=10s;
#server 192.168.1.32:8080 max_fails=3 fail_timeout=10s;
}
server {
listen 443;
server_name zp.wangshibo.com;
ssl on;
### SSL log files ###
access_log logs/zrx_access.log;
error_log logs/zrx_error.log;
### SSL cert files ###
ssl_certificate ssl/wangshibo.cer;
ssl_certificate_key ssl/wangshibo.key;
ssl_session_timeout 5m;
error_page 404 301 https://zp.wangshibo.com/zrx-web/;
location /zrx-web/ {
proxy_pass http://mianshi1;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # proxy_set_header X-Forwarded-Proto https;
#proxy_set_header X-Forwarded-Proto https;
proxy_redirect off;
proxy_intercept_errors on;
}
}