新發布的根本生存裝備
不像玩殭屍毀滅的場景,也不像辯論大刀對抗獵槍,在Java的生產環境中問題是真實存在的,特別是在一個新的釋出之後(有備無患嘛)。更進一步說,比起當時 將編碼週期縮短至幾周或是幾天,甚至一天縮短多次,反而現在更容易陷入麻煩。為了避免這些麻煩,你需要完全理解新的程式碼會對你的系統產生什麼影響。是否會 對原有的系統產生破壞?是否會讓系統執行遲緩?怎麼去解決這些可能出現的問題呢?下面介紹一些工具和架構來徹底破解這些問題。
現在開發生命週期非但不會縮短,每天不斷膨脹的日誌資料 甚至可以達到GB級別的量級。讓我們說說在新發布之後的問題:如果你想及時響應,在沒有合適的工具的情況下,想要處理多資料來源多伺服器的GB量級的資料, 幾乎是不可能的。在這樣的情況下,除開重型企業內部的工具Splunk和他的SaaS中的競爭對手,如Sumo Logic, Loggly等等。我們依然有提供類似功能的其他選擇,因此我們對日誌的管理做了一個深入的分析,你可以參照這裡。
#1 建立一個可靠的日誌管理策略,能幫助你看到的不止是單獨的日誌檔案,能讓你在新發布之後快速做出相應。
我們最後發現,在新發布之後的一個有用的日誌框架就是開源的ELK stack。因為它是開源免費的,所以被特別提到。

ELK stack包括 ElasticSearch,,Logstash 和Kibana
那麼我們所說的 ELK到底是什麼呢?它是一個混合體,包括用作搜尋和效能分析的elasticsearch,用於日誌收集的Logstash和用作前端展現的 Kibana。我們已經用過有一段時間了,依靠它和Redis分析我們的Java日誌,它也有被用在開發和BI之中。現在,elasticsearch已經內建於Logstash,Kibana也是一個elasticsearch的產品,這樣能讓整合和安裝更容易。
每當一個新的釋出之後,前端會展現出我們對這個應用健康所關心的自定義指標。這些指標會實時更新,並且允許剛交付的程式碼上傳到生產環境後馬上就得到監測。
#2 搜尋,視覺化以及對多資料來源日誌的聚合,是決定你日誌管理工具選擇的第一要素。
#3 從一個開發者的角度,評估新的釋出的影響也包括BI等方面。
可供選擇的工具:
- 1.內建工具: Splunk
- 2.SaaS:Sumo Logic
- 3. SaaS:Loggly
- 4. 開源:Graylog2
- 5. 開源:Fluentd
- 6. The ELK stack (開源): Elasticsearch + Logstash + Kibana
效能監控:
釋出週期被縮短,日誌檔案越來越大,但這並不是全部。隨著使用者請求的數量急劇增長,他們都希望達到效能的峰值。如果你不努力優化,簡單的日誌記錄讓你只能看 到這麼多。這樣說來,專用應用程式效能管理工具(APM)已不再被認為是奢侈品,它已經迅速成為一種標準。從本質上說,APM意味著時間需要多長時間來執 行不同的地區程式碼並完成彙報——要達到這個,可以通過程式碼檢測,日誌監控或是包括網路/硬體指標。考慮到後臺以及使用者裝置,首先進入我腦中的兩個APM工 具分別是New Relic(最近剛IPO)以及AppDynamics。
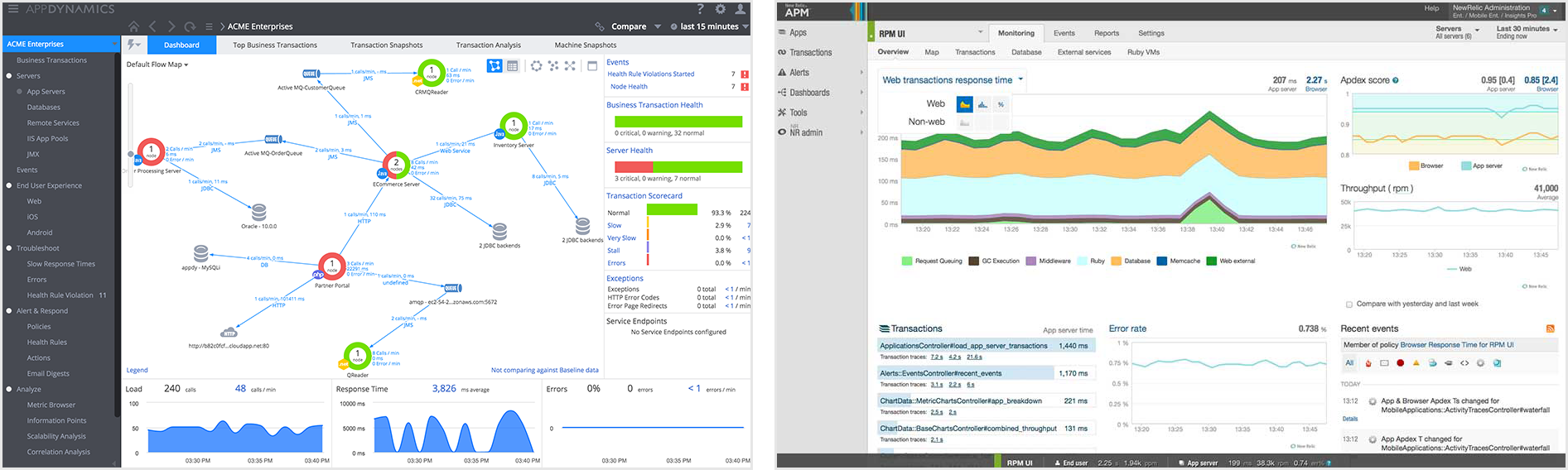 左邊為AppDynamics,右邊為New Relic的主皮膚
左邊為AppDynamics,右邊為New Relic的主皮膚
不管是初創還是成熟的公司,這兩個都能滿足不同型別的開發者。但是兩個都在走IPO,在經歷巨大的增長後,產品線越來越模糊。這個選擇不是很清晰,但是你不 能陷入誤區,即On premise = AppDynamics。相反,這是一個獨立的需求,它依賴於誰更適合你的站點(即它們提供的所有特性就是你實際上想要使用的)。看看我們最近釋出的關於二者的分析報告,點選這裡。
我們最近釋出的另外兩個工具是Ruxit(由Compuware開發)和DripStat(Chronon Systems開發),它們每一個都來自由New Relic開創的嘗試自己解決SaaS監控市場的大公司。為了深入JVM硬核內部,jClarity和Plumbr也絕對值得一試。
#4:新的釋出有可能影響你應用的效能使之執行變慢。APM工具可以提供你應用健康的總體情況。
可供選擇的工具:
新的成員:
產品除錯
發 布週期短了,日誌檔案變大了,使用者請求增多……允許犯錯誤的餘地幾乎不存在了。但當錯誤真的到來時,你需要能夠馬上解決掉。大規模的生產環境,每天可以從 成百上千個不同的程式碼處產生無數的錯誤。雖然有些錯誤時不重要的,但有些可能對你的應用產生致命的影響,並影響你所接觸不到的終端使用者。另外,為了鑑別和解決這些錯誤,你必須依賴於你的日誌或是日誌管理工具去檢視錯誤的發生,更不用說如何修復它。
有了Takipi,你能夠知道最有可能出問題且需要優化的地方,並且能得到怎麼取解決每個問題的可行的資訊。
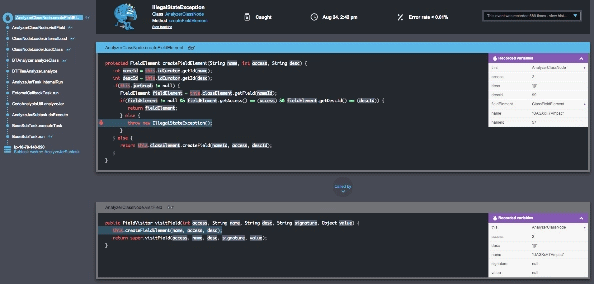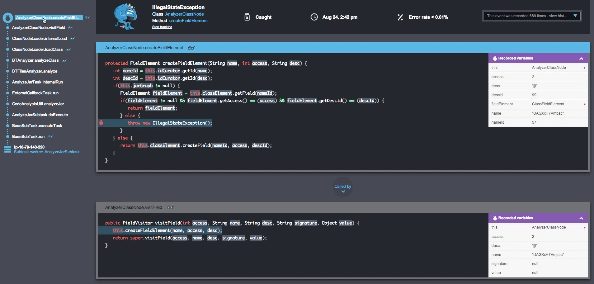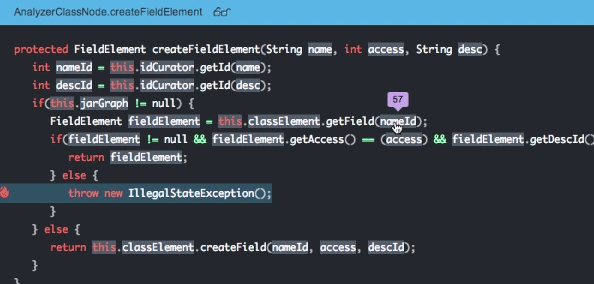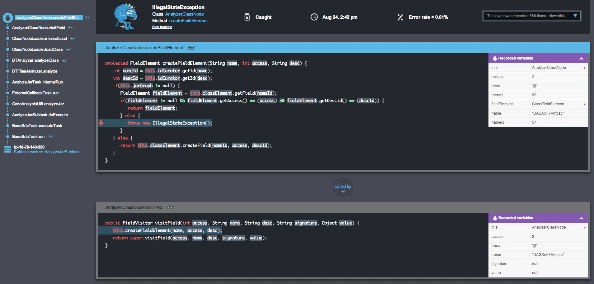
為了關注新發布後的危機,Takipi解決了三個主要問題:
1.瞭解哪些錯誤最有可能影響你——在生產中發現100%的程式碼錯誤,包括JVM異常和記錄的錯誤。使用智慧過濾以減少噪音使之專注於最重要的錯誤。超過90%的Takipi使用者報告說,在他們使用的第一天,至少在生產中找到了一個嚴重的bug。
2、在除錯上花更少的時間和精力——Takipi再現了每個錯誤並顯示出程式碼和導致它產生的變數,甚至可以跨伺服器。這消除了手動複製錯誤的必要,節省了工程時間,顯著降低時間。
3. 沒有風險的釋出——當新的版本中有錯誤,或是已經解決的錯誤又重現時,Takipi都會提醒你。
#5:運用Takipi你能很快地解決任何問題,以至於不讓你在新的釋出之後一無所知。
可選擇的工具:
從這篇文章之後,Takipi的使用時間擴充套件到了兩個月

100%發現生產中的錯誤

發現每個錯誤後面的引數

使大規模除錯變得容易
報警和追蹤
釋出週期,日誌檔案,使用者請求,零錯誤……你怎麼才能全部跟進呢?你可能認為這一類和其他的重疊了,可能你是對的,但是當所有的這些工具都有他們自己的流水 線時,你可能會意識到自己哪裡錯了——這將變得很混亂。特別是在各種意想不到的事情都可能發生的新發布後(也就是整個災難降臨)。
滿足這個的事件管理工具之一的就是PagerDuty:它能從監控工具收集報警,建立時間表來協調你的團隊,或是通過文字、郵件、簡訊或是推送通知,把每個報警發給特定的人。
#6:考慮使用一個事件管理系統來處理資訊過載。
在這裡我們真正喜歡使用的專業工具是Pingdom(也是和Pagerduty的結合)。它所做的很簡單而且有用:即對你的站點的響應時間做24*7小時的追蹤和告警。它能回答一個看起來微不足道,實則至關重要的問題:從世界各地檢測來看,當前的站點可用嗎?
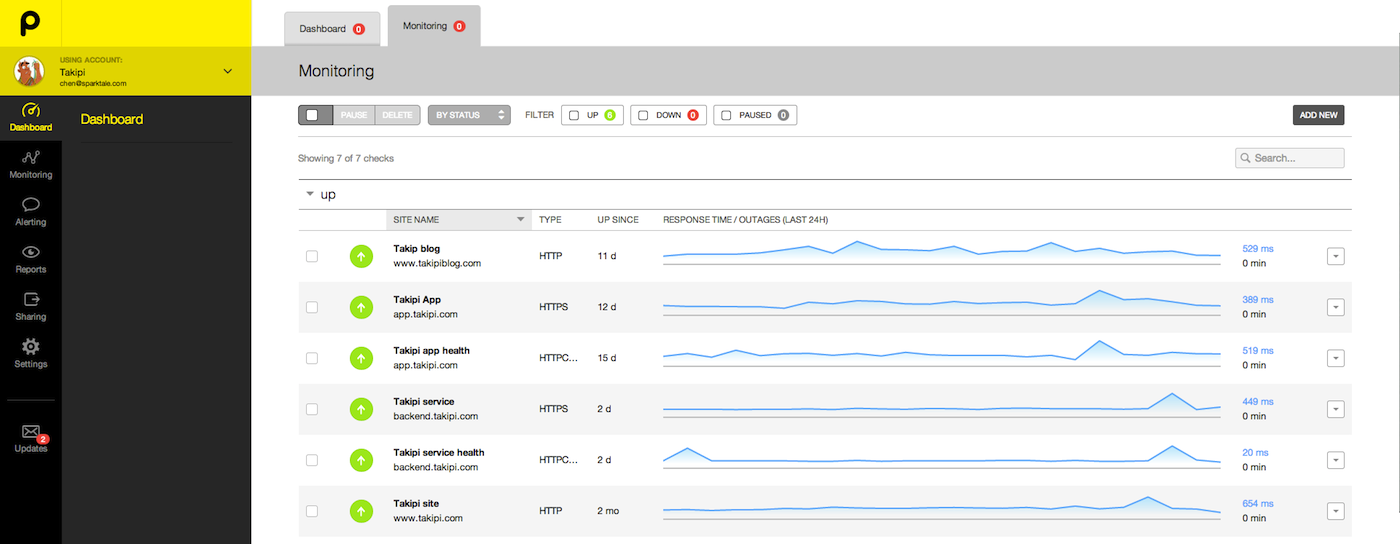
系統如上圖
另一個角度來解決資訊過載的方法,是通過對日誌分析來進行錯誤的跟蹤:管理異常和日誌錯誤的智慧展現。從多個伺服器聚合資料到一個地方,即使你的日誌事件或是其他外掛來自你的程式碼。為了更深入地錯誤追蹤,點選這篇文章可以得到更多的資訊。
#7 程式碼層的錯誤來源各種各樣,在選用追蹤工具時,應該給予特別的對待(在我們關注他們的時候就修復一些bug,哈哈)
可供選擇的工具:
總結
我們親身經歷,現代軟體開發如何影響釋出生命週期,放大如何評估新的快速部署的影響——在你部署之前,你應該完全瞭解最後更新的影響。從長遠來看,任何工具都應該擁有這五個特點:
- 縮短髮布週期
- 增加日誌檔案
- 增大使用者請求
- 減小錯誤
- 資訊的過載
最重要地是,思考一下現在你是怎麼解決這些的,哪一個花了你更多的時間。很可能就有一個工具適合解決這個問題。
原文連結: takipi 翻譯: ImportNew.com- 張 健